







在CH1中已经阐述了如何用反向学习的方法,使得让程序来算出系数,那么对于多个数据呢?比如1000个X,1000个[x1,x2,x3]的情况,怎么办?
应用到每一个数据,逐步靠近
CH1中,对于一个X
w
1
=
w
1
−
(
Y
p
r
e
d
i
c
t
−
Y
r
e
a
l
)
∗
l
a
m
b
d
a
.
∗
x
1
w1 = w1 - (Ypredict~ - Yreal) *lambda.*x1
w1=w1−(Ypredict −Yreal)∗lambda.∗x1
w
2
=
w
2
−
(
Y
p
r
e
d
i
c
t
−
Y
r
e
a
l
)
∗
l
a
m
b
d
a
.
∗
x
2
w2 = w2 - (Ypredict~ - Yreal) *lambda.*x2
w2=w2−(Ypredict −Yreal)∗lambda.∗x2
w
3
=
w
3
−
(
Y
p
r
e
d
i
c
t
−
Y
r
e
a
l
)
∗
l
a
m
b
d
a
.
∗
x
3
w3 = w3 - (Ypredict~ - Yreal) *lambda.*x3
w3=w3−(Ypredict −Yreal)∗lambda.∗x3
可以多次应用于同一个X上面,那么可不可以每一个X都只操作一次?同样我们面临的问题是,如果X和y之间存在某种联系,我们能不能调w1,w2,w3使得大致能够反馈这个联系,在CH1看到,训练次数越多结果越准,为了所以可以采取循环的方式,从第一个到最后1个X,然后反复,直到次数等于我们希望训练的次数
为了验证想法,首先,在网上找一个数据集,任意找到,参数不要太多,这样可以尝试想法是否正确,为了单纯检验想法是否可行,这里是一个线性回归的例子,也就是只有每个X只有x1,和x2,两个特征,(规定x1=1)使得构建一个y= 1w1 + x2w2,然后用来预测一系列的y,就是线性回归分析,但是用机器学习的方法,看下行不行,用octave试一下,
用网上找到的数据集,是用工作经验(年数)预测工资,
经过1000次运算(步幅lambda = 0.0001),当,我们得到了下面的结果,
](https://img-blog.csdnimg.cn/20181218205530457.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzQxNTI3Ng==,size_16,color_FFFFFF,t_70)
可以看到趋势没错,但是有点偏。。运行10000次之后
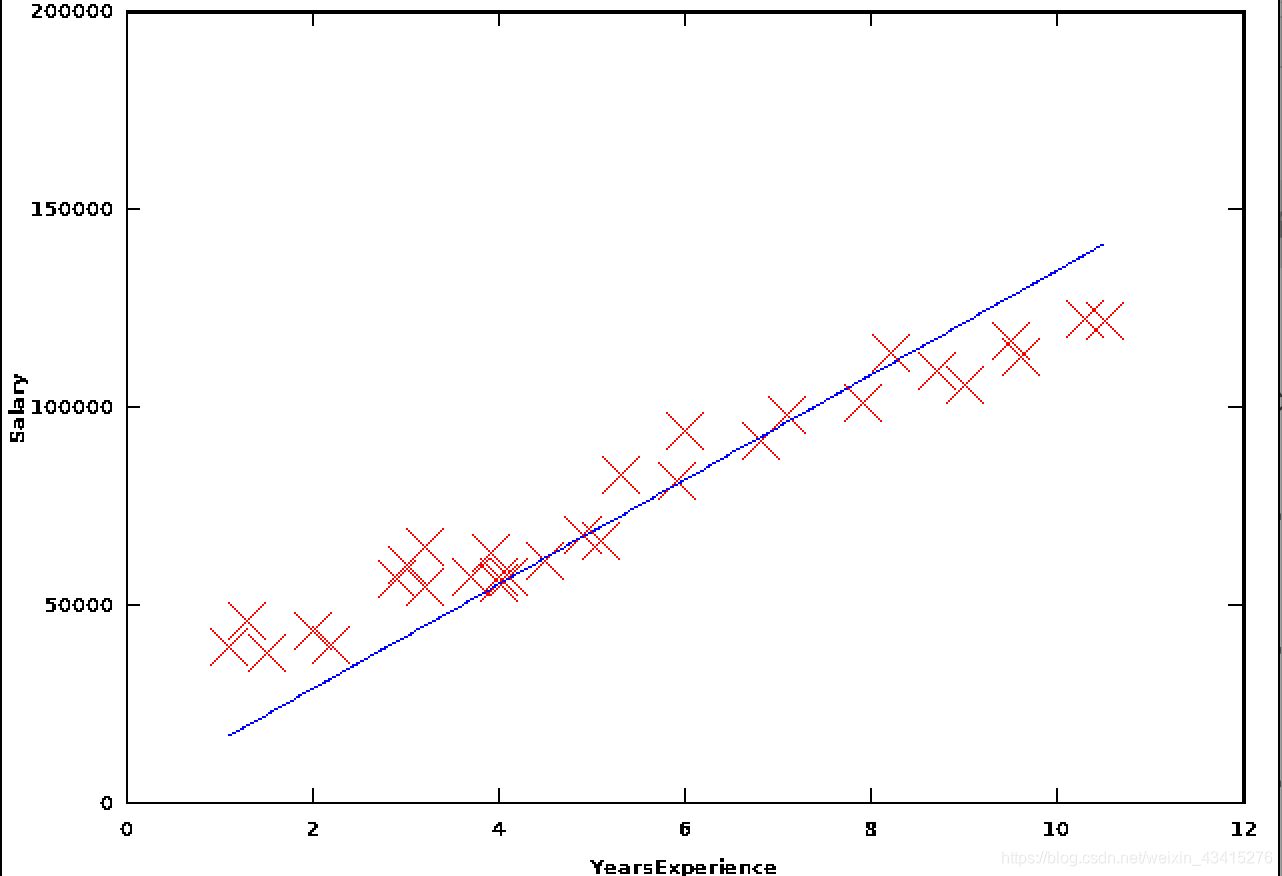
果然没毛病!所以思路还是可以的!!!这种方法称为Stochasic gradient descent!常用于在线学习!
但是,拟合结束了吗?是最好的结果了吗?
为了评价拟合效果,必须增加一个参数CostJ,计算每个点和拟合曲线的差别,可以知道用空间距离差的总和可以表达
具体公式为:
C
o
s
t
J
=
1
2
m
∗
∑
i
(
y
p
r
e
d
i
c
t
−
y
i
)
2
CostJ = \frac {1} {2m}*\sum_{i}(ypredict - yi)^2
CostJ=2m1∗i∑(ypredict−yi)2
公式中的1/2只是为了方面后面的计算而已,m是样品个数
来看一下这个数在上面例子中的变化情况:
>>>CH02regression(5000,0.00001)
结果如下:
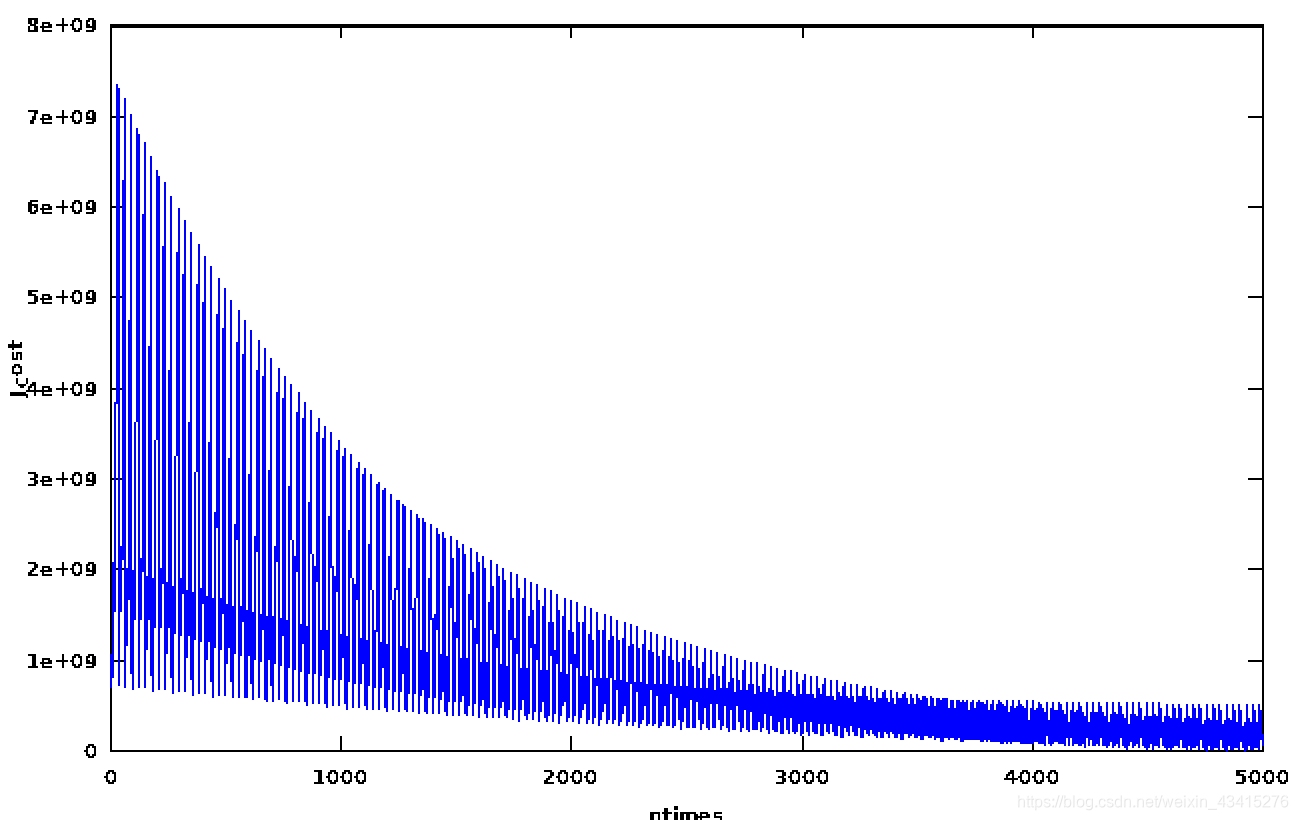
看到拟合效果的确是越来愈好,但是会有一个震荡存在!总体还是不错的,当然,也有办法让震荡幅度越来越小!
那么有没办法让每一次都减小呢?有没办法每一次都走对呢???
有,那就是把所有的X当成一个整体进行学习。就是说,每一次循环完所有的X之后再调整系数,
w 1 = w 1 − 1 m ∑ i ( Y p r e d i c t ( i ) − Y r e a l ( i ) ) ∗ l a m b d a . ∗ x 1 w1 = w1 - \frac {1} {m}\sum_{i}(Ypredict(i)~ - Yreal(i)) *lambda.*x1 w1=w1−m1i∑(Ypredict(i) −Yreal(i))∗lambda.∗x1
这样的好糊就是,每一次都是减少的,因为所有的Ypredict(i)~ - Yreal(i)总和,是一下,反映的是整体的预测差值!!
试一下:将while loop那一段改为下面的forloop,
% for loop to train
for i = 1:n_iter
y_predict = X * w';
J_vals(i) = 0.5/m* sum((y_predict - y).^2);
n_times(i) = i ;
w(:,1) = w(:,1) - lambda/m*sum((y_predict - y));
w(:,2) = w(:,2) - lambda/m*sum((y_predict - y).*X(:,2));
end
%return the w_best vector
w_best = w;
>> CH02regression2(1000,0.00001)
结果如下:
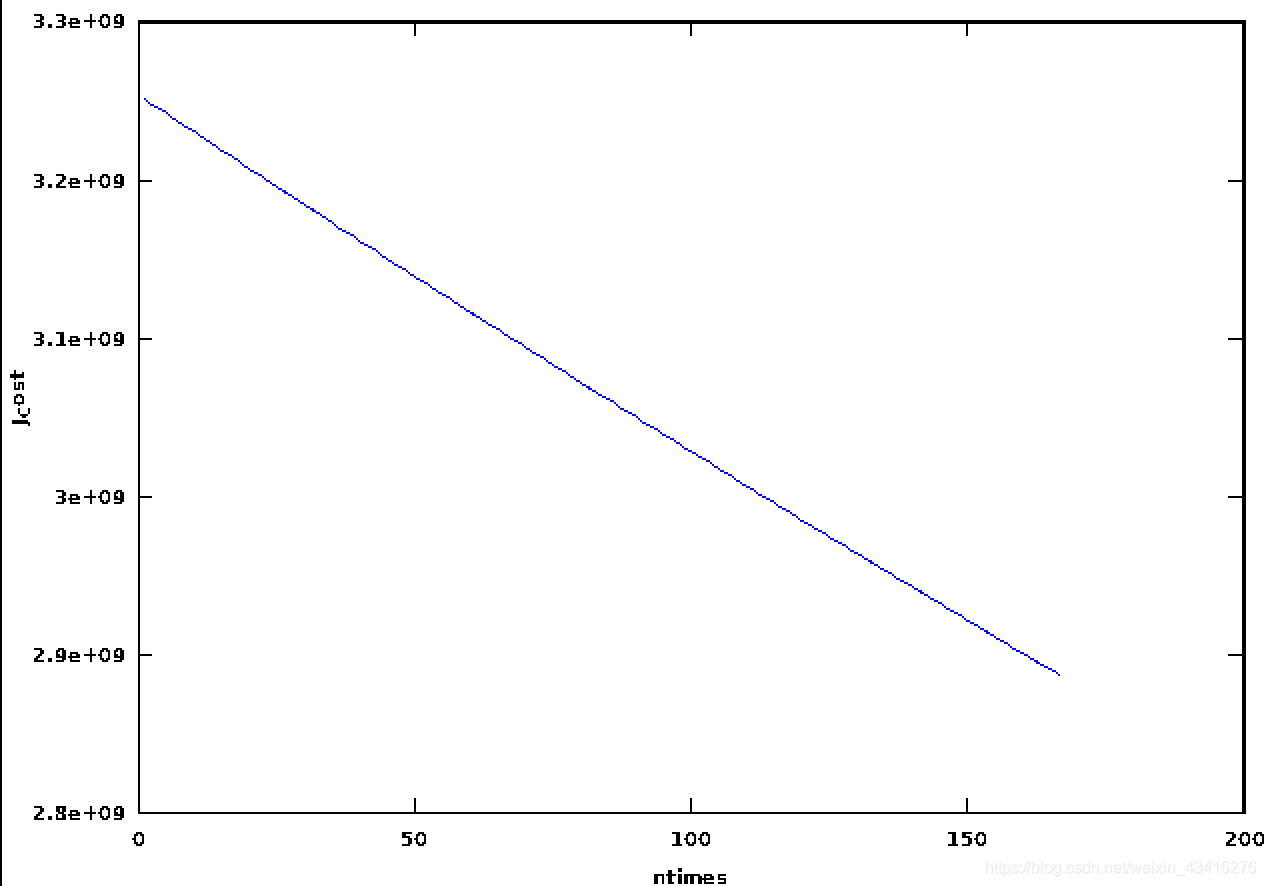
果然不出意料,只是下降的速度好像不尽人意,而且要降到多少才能算拟合完毕?都是问题,有待之后解答。
octave代码
function w_best = CH02regression(n_iter,lambda)
%============================introdution==================
%this function return a weight vector which shows the tendence of the data
%===Parameters===
%n_iter : training times
%lambda : training step
%===Application situation:===
%linear regression problem (one feature)
%============================Code==================
%set some useful variables
w = zeros(1,2);
w_best = zeros(size(w));
y_predict = 0;
n=1;
%load data
data = csvread('Salary_Data.csv');
X = data(2:end, 1);
y = data(2:end, 2);
m = length(y)
% initialize J_vals and n_times to a matrix of 0's
J_vals = zeros(n_iter,1);
n_times= zeros(n_iter,1);
% Add intercept term ones to X
X = [ones(m, 1) X];
i=1;
% while loop to train
while true
y_predict = X(i,:) * w';
i=i+1;
J_vals(n) = 0.5* sum((y_predict - y(i))^2);
n_times(n)=n;
w = w - (y_predict - y(i))*lambda.*X(i,:);
if i == m, % back to the first one
i = 1;
end
if n == n_iter,
break;
end
n = n+1;
end
%return the w_best vector
w_best = w;
%#######################plot(only for test)
%% plot and show the line that we got
%plot(X(:,2),y,'rx','MarkerSize',10);
%hold off;
%x_co = min(X(:,2)):0.1:max(X(:,2));
%y_co = w(1) +w(2)*x_co;
%plot(x_co,y_co);
%xlabel('YearsExperience'); ylabel('Salary');
%hold off;
plot (n_times(:),J_vals(:))
xlabel('ntimes'); ylabel('J_Cost');
end















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









