







 Segment Anything Model(SAM)虽强大,但计算成本高限制其应用。本文提出高效SAM,利用掩蔽图像预训练SAMI,学习从SAM图像编码器重建特征。通过实验评估,SAMI预训练方法优于其他,高效SAM在多个视觉任务表现良好,降低了SAM复杂性并保持性能。
Segment Anything Model(SAM)虽强大,但计算成本高限制其应用。本文提出高效SAM,利用掩蔽图像预训练SAMI,学习从SAM图像编码器重建特征。通过实验评估,SAMI预训练方法优于其他,高效SAM在多个视觉任务表现良好,降低了SAM复杂性并保持性能。
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Abstract
- Segment Anything Model(SAM)已成为众多视觉应用程序的强大工具。在广泛的高质量SA-1B数据集上训练的超大型 Transformer 模型是推动 zero-shot transfer 和高通用性的令人印象深刻的性能的关键组件。虽然SAM模型是有益的,但其巨大的计算成本限制了其在更广泛的现实世界应用中的应用。为了解决这一限制,我们提出了高效SAM,这是一种轻量级的SAM模型,它表现出良好的性能,并大大降低了复杂性。我们的想法是基于利用掩蔽图像预训练,SAMI,它学习从SAM图像编码器重建特征,以进行有效的视觉表示学习。此外,我们采用SAMI预训练的轻量级图像编码器和掩码解码器来构建高效SAM,并在SA-1B上对模型进行微调,以执行任何分割任务。我们对包括图像分类、对象检测、实例分割和语义对象检测在内的多个视觉任务进行了评估,发现我们提出的预训练方法SAMI始终优于其他掩蔽图像预训练方法。在分割任何任务(如零样本实例分割)上,我们的高效SAM与SAMI预训练的轻量级图像编码器相比,在其他fast SAM模型上表现良好,具有显著的增益(例如,COCO/LVIS上的4 AP)。
- 论文地址:[2312.00863] EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything (arxiv.org)
- 代码仓库:yformer/EfficientSAM: EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything (github.com)
- 这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。具体来说,SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练掩码图像模型,从而从 SAM 的 ViT-H 而不是图像补丁重建特征,产生的通用 ViT 骨干可用于下游任务,如图像分类、物体检测和分割等。然后,研究者利用 SAM 解码器对预训练的轻量级编码器进行微调,以完成任何分割任务。为了评估该方法,研究者采用了掩码图像预训练的迁移学习设置,即首先在图像分辨率为 224 × 224 的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。通过 SAMI 预训练,可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。对于 ViT-Small 模型,研究者在 ImageNet-1K 上进行 100 次微调后,其 Top-1 准确率达到 82.7%,优于其他最先进的图像预训练基线。
- 利用 SAM 的掩码图像预训练方法调整了掩码自动编码器框架以增强 SAM,强调将知识从 SAM 转移到 MAE。它使用编码器将未屏蔽的令牌转换为潜在特征表示,并使用解码器在 SAM 的潜在特征的指导下重建屏蔽令牌的表示。
- 此设置中的交叉注意解码器仅重建 mask 标记。而键和值则来自未mask 和mask 的特征。解码器和编码器的输出特征被合并并重新排序到它们在输入图像标记中的原始位置。
- 线性投影头将 SAM 图像编码器的特征与 MAE 的特征对齐,从而解决任何尺寸不匹配的问题。
- 通过比较SAM图像编码器和MAE线性投影头的输出来计算重建损耗,这对训练至关重要。其目的是优化 MAE 编码器,使其充当提取特征的高效图像主干,类似于 SAM 图像编码器。此过程将 SAM 中嵌入的知识传输到 MAE 的编码器、解码器和线性投影头。
- SAM实际部署中的一个主要瓶颈是其效率,因为SAM 中的图像编码器(例如VT-H)非常昂贵。SAM 中的ViT-H图像编码器632M的参数,而基于提示的解码器则只需要3.87M的参数。因此在使用SAM执行segment anything 任务时,会导致高计算和内存成本.为了应对这一挑战,最近的一些工作提出了一些策略,以避免在将SAM应用于基于提示的实例分割时产生的巨大成本:(1)将知识从默认的VT-H图像编码器提炼到一个tiny ViT图像编码器中;(2)通过一个实时的基于CNN的架构来减少执行时的计算成本。
Introduction
- Segment Anything Model(SAM)在视觉领域非常成功,在各种图像分割任务中实现了最先进的性能,如零样本边缘检测、零样本对象建议生成和零样本实例分割,以及许多其他现实世界应用。SAM的关键特征是在大规模视觉数据集上训练的基于提示的视觉 Trasnsformer(ViT)模型,该数据集具有来自11M图像的超过1B个掩码SA-1B,这允许分割给定图像上的任何对象。Segment Anything的这种能力使SAM成为愿景中的基础模型,并使其应用甚至超越愿景。
- 尽管有上述优势,但SAM的模型被证明是实际部署的主要效率瓶颈,因为SAM的架构,特别是图像编码器(例如,ViT-H)非常昂贵。请注意,SAM中的ViT-H图像编码器具有632M个参数,而基于提示的解码器仅具有387M个参数。因此,在实践中使用SAM执行分段任务时,会导致高计算和内存成本,这对实时应用程序来说具有挑战性。
- 为了应对这一挑战,最近的几项工作提出了一些策略,以避免在将SAM应用于基于提示的实例分割时产生巨大成本。例如,[Faster segment anything: Towards lightweight sam for mobile applications]建议将知识从默认的ViT-H图像编码器提取到微小的ViT图像编码器。在[Fast segment anything]中,使用基于实时CNN的Segment Anything任务架构可以降低计算成本。
- 在本文中,我们建议使用预训练良好的轻量级ViT图像编码器(例如,ViT-Tiny/-Small)来降低SAM的复杂性,同时保持良好的性能。我们的方法,SAM利用掩蔽图像预训练(SAMI),为分割任何任务生成所需的预训练的轻量级 ViT 骨干。这是通过利用著名的MAE预训练方法和SAM模型来获得高质量的预训练ViT编码器来实现的。具体而言,我们的SAMI使用SAM编码器ViT-H来生成特征嵌入,并使用轻量级编码器训练 mask 图像模型,以从SAM的ViT-H而不是图像块重建特征。这导致了广义的ViT主干,它可以用于图像分类、对象检测和分割任何东西等下游任务。然后,我们用SAM解码器对预训练的轻量级编码器进行微调,用于分段任何任务。
- 为了评估我们的方法,我们考虑了一种用于 mask 图像预训练的迁移学习设置,其中首先在图像分辨率为224×224的 ImageNet 上用重建损失对模型进行预训练,然后使用监督数据对目标任务进行微调。我们的SAMI学习轻量级编码器,这些编码器可以很好地概括。通过SAMI预训练,我们可以在ImageNet-1K上训练ViT Tiny/-Small/-Base等模型,从而提高泛化性能。对于ViT Small模型,当在具有100个epoch的ImageNet-1K上进行微调时,我们实现了82.7%的前1精度,这优于其他最先进的图像预训练基线。我们还对预训练的模型进行了对象检测、实例分割和语义分割的微调。在所有这些任务中,我们的预训练方法比其他预训练基线取得了更好的结果,更重要的是,我们观察到小模型的显著增益。此外,我们还在Segment Anything任务中评估我们的模型。在零样本实例分割方面,与最近的轻量级SAM方法(包括FastSAM)相比,我们的模型在COCO/LVIS上表现良好,相差4.1AP/5.2AP。我们的主要贡献可以概括如下:
-
我们提出了一种称为SAMI的利用SAM的掩蔽图像预训练框架,该框架训练模型以从SAM ViT-H图像编码器重建特征。结果表明,这可以显著提高图像掩蔽预训练方法的性能。
-
我们证明了SAMI预训练的主干可以很好地推广到许多任务,包括图像分类、对象检测和语义分割。
-
我们提供EfficientSAMs,轻量级SAM模型,具有最先进的质量-效率权衡(下图),这是对实际部署SAM的补充。将发布代码和模型,以使一系列高效SAM应用程序受益。
-
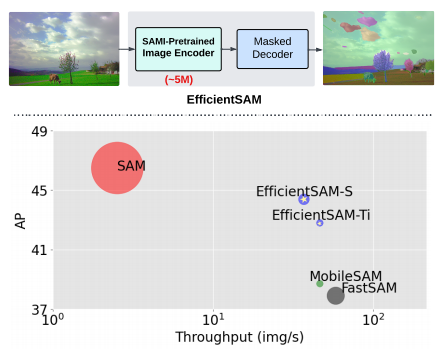
-
对比分析结果。(顶部)EfficientSAM模型概述,以经过良好预训练的轻量级图像编码器为例,以大大降低复杂性的分割为例。(底部)COCO上零样本实例分割的EfficientSAM、MobileSAM、FastSAM和SAM的吞吐量/参数/性能比较。我们在一个NVIDIA A100上通过一个框提示对所有型号的吞吐量(每秒图像数)进行基准测试。输入图像分辨率为1024×1024。我们的EfficientSAM的性能大大优于MobileSAM和FastSAM,约4 AP,具有相当的复杂性。我们的EfficientSAM-S将SAM的推理时间减少了~20x,参数大小减少了~20 x,性能略有下降,分别为44.4 AP和46.5 AP。
-
- 作者使用 SAMI(masked image pretraining)来训练 EfficientSAM。这涉及从 SAM 的图像编码器中重建特征,以增强视觉表示学习。通过将 SAMI 预训练的轻量级图像编码器与模板解码器相结合,EfficientSAM 实现了效率和有效性。在对 SA-1B 数据集进行微调后,EfficientSAM 在各种视觉任务中显示出令人印象深刻的结果,包括图像分类、目标检测、实例分割和语义对象检测。
- 重建损失:MSE 重建损失被发现比相似性损失更有效,这表明 SAM 特征的直接重建比实现高角度相似性更可取。
- 交叉注意力解码器:在重建 SAM 特征时,直接使用编码器的输出标记,解码器仅使用交叉注意力转换屏蔽标记。这种方法在解码器中query mask token,与将所有token馈入解码器进行目标重建相比,SAMI-Ti 在 ImageNet-1K 上的性能提高了 3%。这类似于 AnchorDETR 中的锚点,其中编码器输出标记与 SAM 功能很好地对齐,并用作交叉注意力解码器中 mask token 的锚点。
- 掩蔽率:探索SAMI中不同的掩码率表明,与MAE的发现一致,高掩码率(75%)往往会产生更好的结果。
- 重建目标:使用与CLIP不同的编码器作为SAMI中的重建目标进行了实验。对于 ImageNet-1K 上的 ViT-Tiny 模型,来自 CLIP 编码器的对齐特征比 MAE 好 0.8%,这表明掩模图像预训练受益于强大的引导重建。
- 模型设计上,EfficientSAM设计思路比较简单,类似mobilesam,也采用了模型蒸馏的思路。sam中最重的模块就是encoder模块的vit,mobilesam是直接蒸馏vit模块,而EfficientSAM采用自监督MAE(何恺明大神提出)的方法,对图像masked掉一部分,然后再恢复,和原生sam的vit-h生成的特征进行对比学习,最终也是用轻量的encoder模块替换了vit模块。
- 作者使用 SAMI(masked image pretraining)来训练 EfficientSAM。这涉及从 SAM 的图像编码器中重建特征,以增强视觉表示学习。通过将 SAMI 预训练的轻量级图像编码器与模板解码器相结合,EfficientSAM 实现了效率和有效性。
- 掩码自编码器MAE
- MAE模型包含两个组件:一个编码器和一个解码器。编码器和解码器都基于Transformer层构建。MAE将图像tokens,即输入图像中的非重叠patches,作为输入。这些输入tokens根据给定的掩码比例被分为未掩码token和掩码token。其中未掩码token将被保留以供编码器进行特征提取,而掩码token将被设置为MAE解码器在掩码图像建模中需要重构的学习目标.MAE 采用高掩码比例(如75%),这能有效防止在预训练阶段的信息泄露(例如仅基于邻域来简单地外推掩码像素)
Related Work
- 我们简要回顾了在segment anything model、vision transformers、知识提取和掩蔽图像预训练方面的相关工作。
Segment Anything Model
- SAM被认为是一个里程碑式的视觉基础模型,它可以根据交互提示分割图像中的任何对象。SAM在许多视觉任务中表现出显著的zero-shot transfer性能和高通用性,包括各种分割应用、绘画、图像恢复、图像编辑、图像阴影去除、对象跟踪和3D对象重建。还有许多其他工作试图将SAM推广到现实世界场景,包括医学图像分割、camouflaged 对象检测、transparent 对象检测、基于概念的解释、semantic communitation,以及帮助视力障碍患者。由于其在现实世界中的广泛应用,SAM的实际部署也越来越受到关注。最近的几项工作,提出了降低SAM计算成本的策略。FastSAM开发了一种基于CNN的架构YOLOv8 seg,用于分割图像中的所有对象,以提高效率。MobileSAM提出了一种解耦的提取方法,用于获得SAM的轻量级图像编码器。我们的工作重点是解决SAM实际部署中的效率问题。
Vision Transformers
- ViTs在视觉应用中取得了令人印象深刻的性能。与CNN同行相比,ViTs展示了其优势和通用性。还有许多关于部署高效ViT的工作。在[Training data-efficient image transformers & distillation through attention]中引入了较小的ViT,如ViTSmall/Deit Small和ViT Tiny/Deit Tiny,以补充[ViT]中的ViT Huge、ViT Large和ViT Base。受卷积以降低参数和计算成本捕获局部信息的能力的启发,MobileViT探索将ViT与卷积相结合,这优于轻量级CNN模型,如MobileNet-v2/v3,具有更好的任务级泛化特性,并降低了内存大小和计算成本。该技巧已用于许多后续工作,包括LeViT、EfficientFormer、Next-ViT、Tiny-ViT、Castling-ViT、Efficient-ViT。设计高效ViT的这条进度线与我们构建高效SAM的高效SAM工作正交。
Knowledge Distillation
- 知识提取(KD)是一种在不改变深度学习模型架构的情况下提高其性能的技术。[Distilling the knowledge in a neural network]是将黑暗知识从较大的教师模型提取到较小的学生模型的开创性工作。学生模型的学习受到教师模型的硬标签和软标签的监督。这一做法之后是多部作品,旨在更好地利用软标签传递更多知识。在[Knowledge distillation via softmax regression representation learning]中,蒸馏方法将表示学习和分类解耦。解耦知识蒸馏[Decoupled knowledge distillation]将经典的KD损失分为两部分,目标类知识蒸馏和非目标类知识提取,提高了知识转移的有效性和灵活性。另一项工作是从中间特征转移知识。FitNet是一项开创性的工作,它直接从教师模型的中间特征中提取语义信息。在[Self-supervised models are good teaching assistants for vision transformers]中,引入了自我监督助教(SSTA),与受监督的教师一起指导基于ViT的学生模型的学习。[Masked autoencoders enable efficient knowledge distillers] 通过调整较大的MAE教师模型和较小的MAE学生模型之间的中间特征,研究从预训练MAE模型中提取知识的潜力。
Masked Image Pretraining
- 自监督预训练方法在计算机视觉中引起了极大的关注。一项工作是对比学习方法,该方法通过在给定图像的不同增强视图之间施加高度相似性来学习方差增强。虽然所学习的表示表现出良好的特性,如高线性可分性,但对比学习方法依赖于强增广和负采样。另一项有趣的工作是掩蔽图像建模(MIM),它通过重建掩蔽图像块来帮助模型学习有意义的表示。MIM的开创性工作侧重于使用去噪自动编码器和上下文编码器来训练具有掩蔽预测目标的视觉 Transformer。关于将MIM用于自监督图像预训练,有各种有前途的工作。BEiT是第一个采用MIM进行ViT预训练来预测视觉标记的方法。在BEiTv2中,语义丰富的图像标记器被用于更好的重建目标。在MaskFeat中,重建由HOG描述符生成的局部梯度特征可以实现有效的视觉预训练。在SimMIM 和 MAE 中,直接重建掩模图像块的像素值实现了有效的视觉表示学习。有一些基于MAE的后续工作使用大型教师模型来指导MAE预训练。我们的工作建立在MAE的基础上,发现利用MAE重建SAM图像编码器的特征可以使预训练非常有效。
Approach
Preliminary
- Masked Autoencoders. 掩模自动编码器(MAE)模型有两个组件,一个编码器和一个解码器。编码器和解码器都建立在Transformer层上。MAE将图像 token,即来自输入图像的非重叠补丁作为输入。这些输入 token 被分组为未掩蔽 token 和具有给定掩蔽比率的掩蔽token。未掩蔽的令牌将被保留以供编码器提取特征,并且掩蔽的 token 被设置为在自监督学习(MIM)期间需要重构的MAE解码器的学习目标。MAE采用了高掩码比(例如75%),这防止了预训练阶段的信息泄露(例如,简单地基于邻居外推掩码像素)。
SAM-Leveraged Masked Image Pretraining
-
我们现在采用MAE框架来获得用于分割任何模型的高效图像编码器。受SAM的高度通用性的启发,我们探索了SAM图像编码器的潜在特征,作为利用MAE的重建目标。我们的方法强调转移嵌入SAM中的知识。下图(顶部)说明了所提出的利用SAM的掩蔽图像预训练SAMI的概述。编码器将未掩蔽的 token 转换为潜在特征表示,并且解码器在来自编码器的输出特征嵌入的帮助下重建掩蔽的 token 的表示。重构的表示学习是由SAM的潜在特征引导的。
-
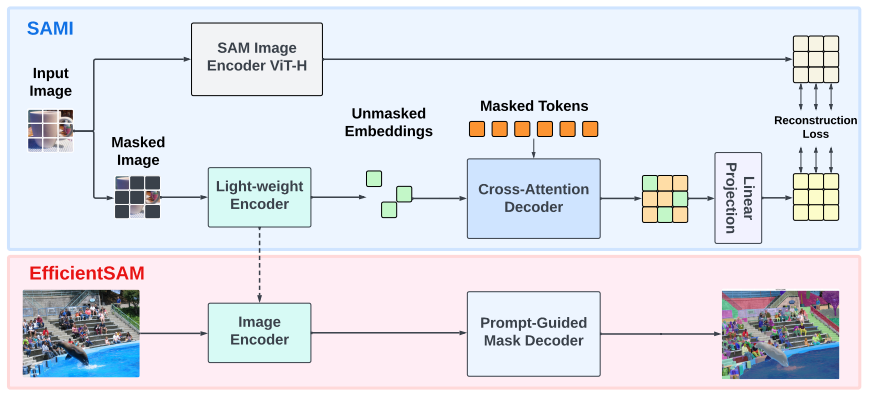
-
EfficientSAM框架概述。我们提出的EfficientSAM包括两个阶段:ImageNet上的SAMI预训练(顶部)和SA-1B上的SAM微调(底部)。对于SAMI预训练,掩码自动编码器将SAM图像编码器的特征嵌入作为重建目标。在SAMI预训练之后,解码器被丢弃,轻量级编码器被用作EfficientSAM的图像编码器,用于对SA-1B进行微调。
-
-
交叉注意力解码器
- 在SAM特征的监督下,只有掩码token需要通过解码器进行重构,而编码器的输出可以在重构过程中充当锚点。在交叉注意力解码器中,Query 来自于掩码token,Key和Value则来自于编码器的未掩码特征和掩码特征。作者将来自交叉注意力解码器的掩码token的输出特征与来自编码器的未掩码token的输出特征进行合并,用于MAE的输出 embedding 。然后,这些组合的特征将被重新排序到输入图像token的原始位置,作为MAE的最终输出。
- 线性投影头
- 作者通过编码器和交叉注意力解码器获得图像输出。然后将这些输出特征输入到一个小的线性投影头中,以与来自SAM图像编码器的特征进行对齐(维度)。为了简化,作者仅使用一个线性投影头来解决SAM图像编码器的输出与MAE之间的特征维度不匹配的问题。
-
交叉注意解码器。在SAM特征的监督下,我们观察到只有屏蔽的 token 需要通过解码器重建,而编码器的输出可以在重建过程中充当锚。在交叉注意力解码器中,query 来自掩码标记,key 和 value 来自编码器的未掩码特征和掩码特征。我们将来自交叉注意力解码器的掩蔽 token 的输出特征和来自编码器的未掩蔽 token 的输出来合并用于MAE输出嵌入。然后,该组合特征将被重新排序到用于最终 MAE 输出的输入图像标记的原始位置。
-
线性投影头。我们通过编码器和交叉注意力解码器获得图像输出。然后,我们将这些特征输入一个小项目头,用于对齐SAM图像编码器的特征。为了简单起见,我们只使用线性投影头来解决SAM图像编码器的输出和MAE之间的特征尺寸不匹配问题。
-
重建损失。在每次训练迭代中,SAMI由SAM图像编码器的前馈特征提取以及MAE的前馈和反向传播过程组成。将SAM图像编码器和MAE线性投影头的输出进行比较,以计算重建损失。
-
让我们将SAM图像编码器表示为 f S A M f^{SAM} fSAM,将MAE的编码器和解码器分别表示为 g e g^e ge,权重为 W e W_e We和 g d g^d gd,权重为 W d W_d Wd,线性投影头分别表示为 h θ h^θ hθ,权重为 W θ W_θ Wθ。假设输入令牌表示为 { x i } i = 1 N {x_i}^N _{i=1} {xi}i=1N,其中 N 是 token 的数量。输入的 token 被随机分组为未掩蔽的token, { x i } i ∈ U \{x_i\}_{i∈U} {xi}i∈U,掩码标记 { x i } i ∈ M \{x_i\}_{i∈M} {xi}i∈M具有给定的掩蔽比。设特征重排序算子为 ϕ \phi ϕ,合并算子为 ⊙ \odot ⊙。
-
我们来自SAM图像编码器的目标特征可以写成 f S A M ( x ) = f S A M ( { x i } i = 1 N ) f^{SAM}(x)=f^{SAM}(\{x_i\}^N_{i=1}) fSAM(x)=fSAM({xi}i=1N),MAE解码器的输出 g e ( { x i } i ∈ U g^e(\{x_i\}_{i∈U} ge({xi}i∈U,解码器输出为 g d ( { x i } i ∈ M ) g^d(\{x_i\}i∈M) gd({xi}i∈M)。线性投影头的输出为 f h ( x ) = h θ ( ϕ ( g e { x i } i ∈ U ⊙ g d { x i } i ∈ M )) f^h(x)=h^θ(\phi(g^e\{x_i\}_{i∈U}\odot g^d\{x_i\}_{i∈M})) fh(x)=hθ(ϕ(ge{xi}i∈U⊙gd{xi}i∈M))。因此,我们的目标重建损失可以公式化为,
-
L W e , W d , W θ = 1 N ⋅ ∑ j = 1 N ∣ ∣ f sam ( x ) − f h ( x ) ∣ ∣ 2 , ( 1 ) \begin {split} L_{W_e, W_d, W_{\theta }} = \frac {1}{N} \cdot \sum _{j = 1}^N ||f^{\text {sam}}(\mathbf {x}) - f^h(\mathbf {x})||^2,\end {split} (1) LWe,Wd,Wθ=N1⋅j=1∑N∣∣fsam(x)−fh(x)∣∣2,(1)
-
其中N是输入标记的数量,||·||表示范数。我们在我们的实验中重建损失的使用ℓ2范数。通过最小化重建损失LWe、Wd、Wθ,我们的编码器 g e g^e ge 被优化为用作图像主干,以提取 SAM 图像编码器的特征。我们的编码器、解码器和线性投影头经过优化,可以从SAM图像编码器学习上下文建模能力。优化所有 token 的重建损失,转移嵌入SAM的知识。
-
-
EfficientSAM 的 SAMI。经过预训练后,我们的编码器提取各种视觉任务的特征表示,解码器被丢弃。特别是,为了为分割任何任务建立有效的SAM模型,我们将SAMI预训练的轻量级编码器(如ViT Tiny和ViT Small)作为图像编码器,并将SAM的默认掩码解码器用于我们的EfficientSAM,如图所示(底部)段。我们在SA-1B数据集上为分段任何任务微调EfficientSAM模型。我们的EfficientSAM框架概述如上图所示。
Experiments
Experimental Settings
-
预训练数据集。我们的掩模图像预训练方法SAMI是在ImageNet-1K训练集上进行的,训练集有1.2M张图像。在掩蔽图像预训练之后,我们不使用标签信息。在预训练我们的ViT模型、ViT-Tiny、ViT-Small和ViT-Base时,我们使用的SAM ViT-H图像编码器来生成重建特征。
-
Pretraining Implementation Details. 我们的ViT模型是用均方误差(MSE)损失预训练的,用于重建。我们使用批量大小为4096的AdamW优化器,学习率为2.4e-3,β1=0.9,β2=0.95,权重衰减0.05,前40个epoch的线性学习率预热,余弦学习率衰减来更新我们的模型。我们只采用224x224分辨率的随机调整大小裁剪、随机水平翻转和标准化来增加数据。掩码比设置为75%,解码器包含8个512维的Transformer块,如MAE所示。我们在V100机器上使用PyTorch框架预训练了400个epoch的SAMI。作为参考,MAE需要1600 epoch预训练。
-
下游任务/数据集/模型。任务和数据集。我们首先考虑了三个基准数据集和几个具有代表性的视觉任务,以证明所提出的SAMI的优越性,包括在ImageNet数据集上进行图像分类,其中包括120万张训练图像和50万张验证图像;具有118K训练和5K验证图像的COCO数据集上的对象检测和实例分割;ADE20K数据集上的语义分割,分别使用20K/2K/3K图像进行训练、验证和测试。然后,我们考虑分割任何任务,以进一步展示我们提出的SAMI的优势。我们对SA-1B数据集上的SAM预训练的轻量级图像编码器进行了微调,其中包含来自11M高分辨率图像的超过1B个掩码,并测试了我们在COCO和LVIS上的EfficientSAM的交互式实例分割和零样本实例分割能力。
-
模型。我们丢弃SAMI的解码器,同时保留编码器作为骨干,以提取不同任务的特征,如MAE中所述。我们将我们预训练良好的ViT主干应用于不同的任务,包括用于分类的ViT、用于检测和实例分割的ViTDet、用于语义分割任务的Mask2former以及用于分割任何内容的SAM。
-
微调设置。对于分类任务,我们使用β1=0.9,β2=0.999,权重衰减0.05的AdamW优化器,使用32个V100 GPU对100个时期的ViT进行微调,每个GPU的批大小为32。初始学习速率是1e-3,具有用于线性预热的前5个时期,并且通过余弦学习速率调度器衰减到零。我们将ViTSmall和ViT Base的逐层学习速率衰减因子设置为0.75。我们不将逐层学习速率衰减应用于ViT Tiny。对于数据扩充,我们采用RandAugment并将标签平滑设置为0.1,混合设置为0.8。
-
对于检测和实例分割任务,我们遵循ViTDet框架,将ViT主干适配为简单的特征金字塔,用于对象检测和实例细分。我们采用动量β1=0.9、β2=0.999和权重衰减0.1的AdamW优化器来训练COCO上的模型。所有模型都在64个V100 GPU上训练了100个epoch,每个GPU有1个批量大小,图像分辨率为1024×1024。初始学习率为2e−4,在前10个 epoch线性预热,并通过余弦学习率计划衰减到0。模型被训练了100个epoch。
-
对于分割任务,我们预训练的ViT模型作为Mask2former的骨干,它与ADE20K上的分割层一起进行微调。我们采用了AdamW优化器,β1=0.9,β2=0.999,小批量大小为16,权重衰减为0.05,初始学习率为2e-4。学习率通过多学习率调度衰减到0。主干的学习率乘数设置为0.1。输入图像分辨率为512×512。使用8个V100 GPU对模型进行160K迭代的训练。
-
对于任何分割任务,在sam之后,我们将预训练的轻量级ViT模型ViT-Tiny和ViT-Small作为SAM框架的图像编码器,并在SA-1B数据集上对编码器和解码器进行5个epoch的微调。我们使用动量为(β1=0.9,β2=0.999)、小批量为128、初始learning率为4e−4的AdamW优化器。学习率通过线性学习率调度衰减到0。我们将权重衰减设置为0.1。我们不应用数据扩充。输入图像分辨率为1024×1024。我们的EfficientSAM是在64个A100 GPU和40GB GPU内存上进行训练的。
-
基线和评估指标。基线。对于分类任务,我们比较了不同预训练/蒸馏方法的ViT主干的性能,包括MAE、SSTA、DMAE、BEiT、CAE、DINO、iBOT、DeiT等。对于检测和实例语义任务以及语义分割任务,我们还比较了ViTDet和Mask2former的几种预训练ViT主干。对于分段所有任务,我们与SAM、FastSAM和MobileSAM进行比较。评估指标。我们根据准确性评估我们的方法和所有基线。具体地,准确度度量是指分类任务的前1准确度;APbox,APmask,用于检测和实例分割任务(AP:平均精度);mIoU,用于语义分割任务(mIoU:并集上的平均交集);用于分段任何任务的mIoU、AP、APS、APM、APL。对于效率度量,我们比较模型参数的数量或推理吞吐量。
Main Results
-
图像分类。为了评估我们提出的技术在图像分类任务上的有效性,我们将所提出的SAMI思想应用于ViT模型,并在ImageNet-1K上比较它们与基线的性能。如下表所示,我们的SAMI与MAE、iBOT、CAE和BEiT等预训练方法以及DeiT和SSTA等蒸馏方法进行了比较。SAMI-B的top1准确率达到84.8%,分别比预训练基线、MAE、DMAE、iBOT、CAE和BEiT高出1.2%、0.8%、1.1%、0.9%和0.4%。与DeiT和SSTA等蒸馏方法相比,SAMI也有很大的改进。对于ViT Tiny和ViT-Small等轻量级机型,与DeiT、SSTA、DMAE和MAE相比,SAMI报告了显著的收益。
-
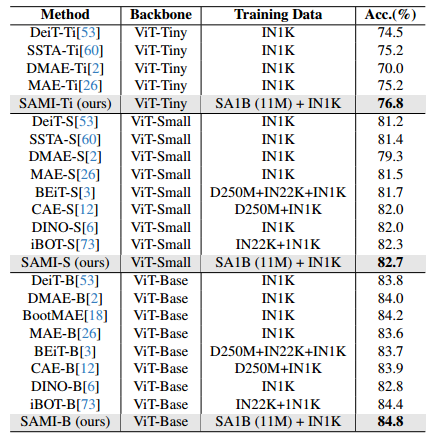
-
ImageNet-1K上的图像分类结果。IN是ImageNet的缩写。
-
-
对象检测和实例分割。我们还将SAMI预训练的ViT主干扩展到下游对象检测和实例分割任务,并将其与之前在COCO数据集上的预训练基线进行比较,以评估其功效。具体而言,我们采用预训练的ViT主干,并将其适应于Mask R-CNN框架中的简单特征金字塔,以构建检测器ViTDet。下表显示了我们的SAMI和其他基线之间的总体比较。我们可以看到,与其他基线相比,我们的SAMI始终实现了更好的性能。与MAE-B相比,SAMI-B获得0.9 APbbox和0.6 APmask增益。对于轻质主链,与MAE-Ti和MAE-S相比,SAMIS和SAMI-Ti报告了显著的增益。此外,SAMI-S显著优于DeiT-S 2.6 APbbox,2.3 APmask。对于其他预训练基线,我们的SAMI stiil与DINO和iBOT相比是有利的。这组实验验证了所提出的SAMI在对象检测和实例分割任务中提供预训练的检测器骨干的有效性。
-
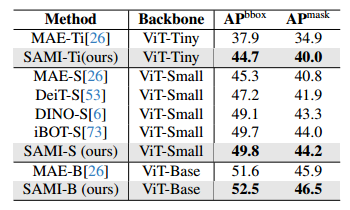
-
Object detection and instance segmentation results on the MS COCO using ViTDet.
-
-
语义分割。我们进一步将预训练的主干扩展到语义分割任务中,以评估其有效性。具体来说,我们使用ViT模型作为Mask2former框架中的主干,在ADE20K数据集上进行基准测试。如下表所示,具有SAMI预训练主链的Mask2former实现了更好的mIoU,即↑2.5, ↑4.7,以及↑3.7在ImageNet-1K上使用MAE预训练对骨干的改进。这组实验验证了我们提出的技术可以很好地推广到各种下游任务。
-
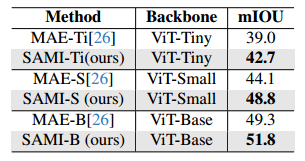
-
使用Mask2former对ADE20K数据集进行语义分割。输入分辨率为512×512。
-
EfficientSAMs for Segment Anything Task
-
Segment Anything任务是一个可提示的分割过程,以基于任何形式的提示生成分割掩码,包括点集、粗略框或掩码、自由文本。我们遵循SAM,重点关注COCO/LVIS上基于点和基于框的提示分割。我们现在测试我们的模型在分割任何任务上的泛化能力,包括零样本单点有效掩码评估和零样本实例分割。我们将SAMI预训练的轻量级骨干作为SAM的图像编码器,以构建高效的SAM。然后,我们对SA-1B数据集上的EfficientSAM进行了微调,并报告了零样本单点有效掩码评估和零样本实例分割的性能。
-
零样本单点有效掩码评估。与SAM类似,我们评估从单个前景点分割对象。对于一般的交互式分割,我们还考虑从[sam]中介绍的单个框和多个点进行对象分割。为了实现这一点,我们对点击的 GT 掩码内的随机点进行均匀采样,并计算与该框的 GT 遮罩相对应的最紧边界框。由于我们的模型能够预测多个掩码,我们只将最有信心的掩码评估为SAM。
-
Results. 在下表中,将EfficientSAMs与SAM、MobileSAM和SAM-MAE-Ti进行了比较。在COCO上,我们的EfficientSAMs-Ti在1次点击时比MobileSAM高1.9 mIoU,在1次框中比MobileSAM高1.5 mIoU。我们的具有SAMI预训练权重的EfficientSAM Ti在COCO/LVIS交互式分割上也比MAE预训练权重表现更好。我们注意到,我们的EfficientSAM-S在COCO box上仅比SAM低1.5 mIoU,在LVIS盒上仅低3.5 mIoU(参数减少了20倍)。我们发现,与MobileSAM和SAM-MAE-Ti相比,我们的EfficientSAM在多次点击时也表现出了良好的性能。
-
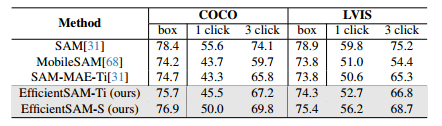
-
零样本单点有效掩模对COCO和LVIS的评估结果。根据SAM,我们对点击的 GT 掩码内的随机点进行均匀采样,并计算最紧的边界框对应的 GT 遮罩。SAM-MAE-Ti表示具有预训练的MAE-Ti图像编码器的SAM。
-
-
Zero-Shot Instance Segmentation. 在SAM之后,以ViTDet生成的边界框(bbox)为提示执行实例分割任务。在并集上具有最高交集(IoU)的掩码,其中bbox作为预测掩码。
-
后果在下表中,我们报告了用于零样本实例分割的AP、APS、APM、APL。我们将EfficientSAM与MobileSAM和FastSAM进行比较。我们可以看到,与FastSAM相比,EfficientSAM-S在COCO上获得了6.5以上的AP,在LVIS上获得了7.8以上的AP。对于EffidientSAM-Ti,它仍然以很大的优势优于FastSAM,在COCO上为4.1 AP,在LVIS上为5.3 AP,而MobileSAM在COCO和LVIS上分别为3.6 AP和5.5 AP。请注意,我们的efficientSAM比FastSAM轻得多,例如,效率SAM-Ti的参数为9.8M,而FastSAM的参数为68M。高效SAM-S还显著减少了0.6G参数SAM之间的差距,仅减少了2个AP。这些结果证明了EfficientSAM在零样本实例分割方面的非凡优势,并验证了我们的SAMI预训练方法的优势。
-
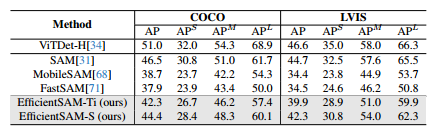
-
基于COCO/LVIS的零样本实例分割结果。提示ViTDet框执行零样本分割
-
-
定性评估。我们现在提供定性结果,以补充对高效SAM的实例分割能力的理解。一些例子如下图所示。具体而言,我们报告了具有两种类型提示的预测掩码,如MobileSAM中的点和框,并对所有结果进行了分段。
-

-
点提示输入SAM、FastSAM、MobileSAM和我们的EfficientSAM模型的可视化结果。
-

-
框上的可视化结果提示输入SAM、FastSAM、MobileSAM和我们的EfficientSAM模型。
-

-
使用SAM、FastSAM、MobileSAM和我们的EfficientSAM模型细分所有内容的可视化结果。
-
-
更多的定性结果可以在补充资料中找到。这些结果表明,与SAM相比,我们的高效SAM具有竞争能力。请注意,我们的EfficientSAM比SAM轻得多,我们的模型可以有效地提供不错的细分结果。这表明我们的模型可以作为SAM的补充版本,用于许多实际任务。
-
突出实例分割。突出对象分割旨在从图像中分割出最具视觉吸引力的对象。我们将交互式实例分割扩展到显著实例分割,而无需手动创建点/框。具体来说,我们采用最先进的显著性对象检测模型U2-net来预测显著性图,并在显著性图中均匀采样3个随机点(3次点击),以使用我们的EfficientSAM执行实例分割。在下图中,我们可以看到我们的EfficientSAM可以很好地执行显著实例分割。这一初步探索开启了帮助手部损伤患者在图像中分割感兴趣对象的潜力。
-

-
基于显著性的实例自动分割结果。在U2-net生成的显著性图的帮助下,我们的EfficientSAM能够生成掩码并执行自动实例分割,而无需手动创建点或框。
-
Ablation Studies
-
我们现在通过一系列ViT主干消融研究来分析SAMI和高效SAM。
-
重建损失。我们研究了重建损失对ImageNet-1K上SAMI性能的影响。我们将均方误差(MSE)重建损失与余弦相似性损失进行了比较。我们发现MSE重建损失表现更好,如下表所示。这建议直接重建SAM特征,而不是具有高角度相似性的目标
-
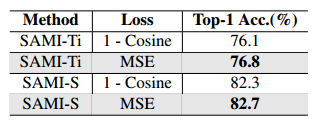
-
SAMI训练损失的消融研究。MSE损失在ImageNet-1K上给出了更好的分类结果。
-
-
交叉注意解码器。为了重构SAM特征,我们直接使用编码器的输出 token,而只使用解码器来转换具有交叉注意的掩码令牌。我们研究了性能如何通过解码器MAE随所有 token 而变化。当查询解码器中的掩码 token 时,我们发现SAMI-Ti在ImageNet-1K上的性能比将所有 token 馈送到解码器中以进行目标重建(如MAE)好3%。类似于AnchorDETR中的锚点,编码器的输出 token 已经通过直接对齐SAM特征很好地学习,SAM特征可以作为锚 token,通过交叉注意力解码器帮助屏蔽 token 对齐。
-
Mask Ratio. 在MAE中,建议使用75%的高遮罩率。我们探讨了SAMI中的性能如何随着不同的掩模比而变化。如下表所示,我们可以看到观察结果与MAE一致,即高掩模比往往会产生良好的结果。
-
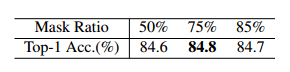
-
ImageNet-1K上SAMI-B的掩模上消融比率。
-
-
重建目标。我们研究了重建目标的影响。我们采用与CLIP不同的编码器来生成特征,作为SAMI中的重建目标。对于ImageNet-1K上的ViT-Tiny模型,CLIP编码器的对齐功能也可以比MAE高0.8%。这表明掩模图像预训练得益于强大的引导重建。
-
优化步骤对高效SAM的影响。我们探讨了高效SAM的微调步骤的效果。如下图所示,EfficientSAM-Ti和EfficientSAM-S即使在0.1 epoch也能获得不错的性能。对于1个epoch,性能增益大于2.5 mIoU。EfficientSAM-S的最终性能达到76.9mIoU,仅比SAM低1.5mIoU。这些结果证明了SAMI预训练图像编码器和我们的EfficientSAM的优势。
-
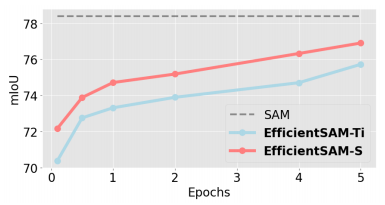
-
MS COCO数据集上EfficientSAM训练步骤的消融研究。在单框提示下对消融进行零样本单点有效掩模评估。
-
Conclusion
- 我们提出了一种掩蔽图像预训练方法SAMI,以在SAM基础模型的指导下探索ViTs的潜力。SAMI通过重建SAM图像编码器的潜在特征,将知识从视觉基础模型转移到ViTs,改进了掩模图像的预训练。在图像分类、对象检测和实例分割、语义分割以及任何分割任务上的大量实验一致验证了SAMI的优势。我们还展示了SAMI通过预训练的轻量级编码器帮助构建高效的SAM。我们的初步工作表明,SAMI具有超越高效分段任何任务的潜在应用。
Supplementary Material
- 在这篇补充材料中,我们提供了更多的结果来展示我们高效SAM模型的实例分割能力。
Efficiency Evaluation
- 下表记录了我们模型的吞吐量和参数数量。我们在单个NVIDIA A100上测量吞吐量(每秒图像数),并带有一个框提示。输入图像分辨率为1024×1024。
-
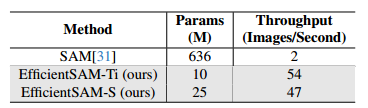
-
推理效率结果。所有模型都会提示一个ViTDet框,用于在单个NVIDIA A100上对实例分割的速度(吞吐量)进行基准测试。
-
Qualitative Evaluation
- 为了研究我们的模型在多大程度上能够基于提示生成分割掩码,我们使用我们的模型来执行基于提示的实例分割,包括基于点和基于框的提示提示分割。我们还使用我们的模型来执行分段所有内容和显著实例分段,而无需手动创建点和框提示。
- 对于每个任务,我们共享4个示例来展示我们模型的实例分割能力。这些结果为我们的EfficientSAM在不同提示下的竞争实例分割能力提供了直接证据。例如,在点提示实例分割的情况下,我们的模型能够给出合理的实例分割结果(见下图)。
-

-
Visualization results on point-prompt input
-
- 在框提示实例分割的情况下,我们的模型还生成预期的对象分割(见下图)。
-

-
Visualization results on box-prompt input.
-
- 在分割所有内容的情况下,我们的模型提供了不错的分割性能(见下图)。
-

-
Visualization results on segment everything.
-
- 在显著实例分割的情况下,我们的模型具有生成掩码的能力,并在不手动创建点或框的情况下进行自动实例分割(见下图)。
-

-
Saliency-based automatic instance segmentation results.
-
- 但我们仍然需要注意,我们的模型有时可能会产生噪声分割,如图所示。
-

-
带有噪声的分割结果。我们的模型有时可能会为掩模提供噪声,这也可以在SAM的结果中观察到。
-


















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











