











⭐️ 教程:
《11月智能汽车AI挑战赛》-学习手册
2023全球智能汽车AI挑战赛:智能驾驶汽车虚拟仿真视频数据理解(由Datawhale提供)
⭐️ 项目来源: 2023全球智能汽车AI挑战赛——赛道二:智能驾驶汽车虚拟仿真视频数据理解赛道
主办方:吉利汽车集团、阿里云、NVIDIA 英伟达
赛事平台:阿里云天池
⭐️ 11.11入群参赛,熟悉赛题,然后跑通 baseline
1. 赛题
1.1 赛事背景
当前,全球新一轮科技革命和产业变革蓬勃发展,汽车与人工智能技术加速融合,电动化、网联化、智能化成为汽车产业的发展潮流和趋势,AI技术将更广泛地和汽车产业的各个领域,应用于汽车的智能维护、智能制造、智能驾驶等诸多方面。作为人工智能技术和汽车产业先进技术的倡导者,吉利汽车集团、阿里云、NVIDIA 英伟达一直致力于推动未来出行方式的发展,共同发起了本届2023全球智能汽车AI挑战赛。本届比赛将汇聚来自全球各地的杰出AI领域人才,推动自动驾驶、AI大模型、加速计算、云计算技术三者深度结合,为未来智能出行提供更加安全、高效、舒适的解决方案。
本届大赛共分为两个赛道:
赛道一:AI大模型检索问答
赛道二:智能驾驶汽车虚拟仿真视频数据理解
本次参与的手把手带打多模态赛事实践(由Datawhale发起)选中的是赛道二:智能驾驶汽车虚拟仿真视频数据理解。
1.2 赛题任务
输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右)
输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以)
1.3 赛题数据
1.4 评价指标

系统会针对参赛者提交的json文件,通过描述型的文本信息与真值进行对比,综合得出分数;其中,“距离最近的交通参与者的行为”的题目为2分,其它题目为1分;每个视频的满分为10分。每一个视频结果中的key值,需要参考数据说明的json格式示例,请勿进行修改。
对于真值部分,组织者会建立对应的中英文近义词作为真值列表,只要在该列表中就获得分数,例如真值“雨天” = [“雨天”, “雨”, “小雨”… , “rainy”, “rain”, “raining”…],参赛选手可以选择对应的近义词来进行作答,但每一项的真值列表不公开,仅体现在后台程序中。
2. CLIP模型
文字生成图片是近年来多模态和大模型研究的热门方向,OPENAI 提出的 CLIP 提供了一个方法建立起了图片和文字的联系,但是只能做到给定一张图片选择给定文本语义最相近的那一个。
CLIP的全称是 Contrastive Language-Image Pre-Training,中文是对比语言-图像预训练,是一个预训练模型,简称为CLIP。该模型是 OpenAI 在 2021 年发布的,最初用于匹配图像和文本的预训练神经网络模型,这个任务在多模态领域比较常见,可以用于文本图像检索,CLIP是近年来在多模态研究领域的经典之作。该模型大量的成对互联网数据进行预训练,在很多任务表现上达到了目前最佳表现(SOTA)。
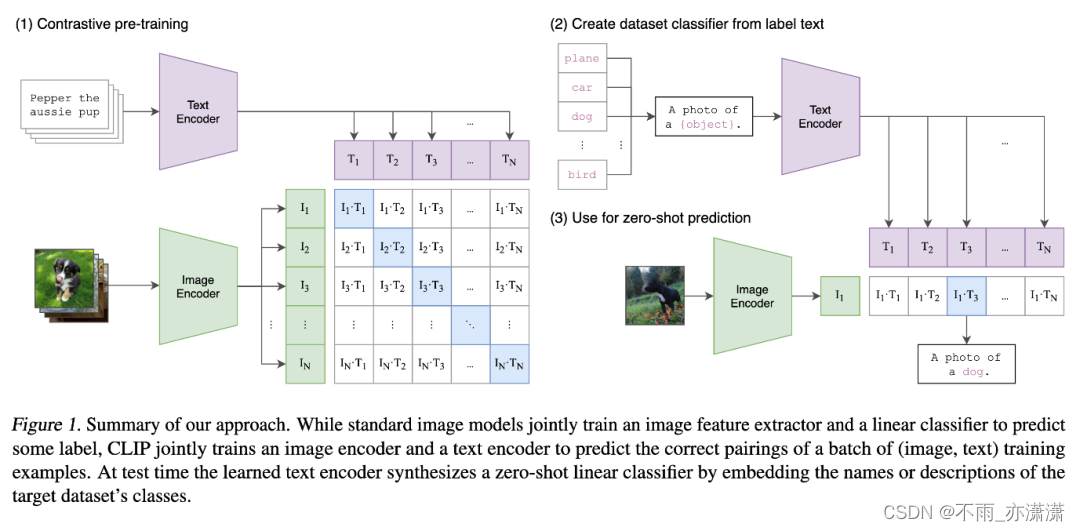
选择CLIP模型用在比赛的原因:没有训练集,有多个标签
Clip(Contrastive Language-Image Pretraining) 将语言信息和图像信息联合训练,实现了在下游任务上 zero-shot(Zero-shot learning 指的是在没有当前类别的训练样本的情况下,让模型学习到一个映射关系可以将这个样本映射到原有的向量空间,再通过向量空间中距离判断的方式推断出当前没有看过的样本可能会属于哪一类别) 的能力。具体来说,CLIP将图像的分类任务转化为了图文匹配的任务,将图像信息和语义信息映射到同一多模态语义空间下,再使用对比学习的方法进行训练。
参考:
【VCED】Clip模型
clip_interrogator教程
3. Baseline
baseline 是在 AI Studio 上运行的,我直接 fork 了。
2023全球智能汽车AI挑战赛(赛道二:视频数据理解赛道) baseline
结合 chatGPT ,我在baseline代码上加了些注释:
安装 paddleclip
!pip install paddleclip
导入库
import paddle
from PIL import Image
from clip import tokenize, load_model
import glob, json, os
import cv2
from PIL import Image
from tqdm import tqdm_notebook
import numpy as np
from sklearn.preprocessing import normalize
import matplotlib.pyplot as plt
# 加载预训练的 ViT_B_32 模型
# load_model: 是一个自定义函数,用于加载模型和数据转换器(transforms)
# pretrained=True: 表示加载预训练的权重
# 返回值包括:
# model: ViT_B_32 模型对象
# transforms: 数据转换器对象,用于将输入数据转换为适合模型处理的形式
model, transforms = load_model('ViT_B_32', pretrained=True)
获取图片描述
实际项目开发中我们总是需要从一张图片获取描述,这里选择根目录下的一张图片 kobe.jpeg。
# 设置图片路径和标签
img_path = "kobe.jpeg"
labels = ['kobe', 'james', 'Jordan']
# 准备输入数据
img = Image.open(img_path)
display(img)
image = transforms(Image.open(img_path)).unsqueeze(0)
text = tokenize(labels)
# 计算特征
with paddle.no_grad():
logits_per_image, logits_per_text = model(image, text)
probs = paddle.nn.functional.softmax(logits_per_image, axis=-1)
# 打印结果
for label, prob in zip(labels, probs.squeeze()):
print('该图片为 %s 的概率是:%.02f%%' % (label, prob*100.))
这里会输出图片以及识别结果:

该图片为 kobe 的概率是:98.68%
该图片为 james 的概率是:0.57%
该图片为 Jordan 的概率是:0.75%
判断的准确率还是比较高的。
输入标签
cn_match_words = {
"工况描述": ["高速/城市快速路", "城区", "郊区", "隧道", "停车场", "加油站/充电站", "未知"],
"天气": ["晴天", "雨天", "多云", "雾天", "下雪", "未知"],
"时间": ["白天", "夜晚", "拂晓/日暮", "未知"],
"道路结构": ["十字路口", "丁字路口", "上下匝道", "车道汇入", "进出停车场", "环岛", "正常车道", "未知"],
"一般障碍物": ["雉桶", "水马", "碎石/石块", "井盖", "减速带", "没有"],
"道路异常情况": ["油污/水渍", "积水", "龟裂", "起伏不平", "没有", "未知"],
"自车行为": ["直行", "左转", "右转", "停止", "掉头", "加速", "减速", "变道", "其它"],
"最近的交通参与者": ["行人", "小型汽车", "卡车", "交警", "没有", "未知", "其它"],
"最近的交通参与者行为": ["直行", "左转", "右转", "停止", "掉头", "加速", "减速", "变道", "其它"],
}
en_match_words = {
"scerario" : ["suburbs","city street","expressway","tunnel","parking-lot","gas or charging stations","unknown"],
"weather" : ["clear","cloudy","raining","foggy","snowy","unknown"],
"period" : ["daytime","dawn or dusk","night","unknown"],
"road_structure" : ["normal","crossroads","T-junction","ramp","lane merging","parking lot entrance","round about","unknown"],
"general_obstacle" : ["nothing","speed bumper","traffic cone","water horse","stone","manhole cover","nothing","unknown"],
"abnormal_condition" : ["uneven","oil or water stain","standing water","cracked","nothing","unknown"],
"ego_car_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],
"closest_participants_type" : ["passenger car","bus","truck","pedestrain","policeman","nothing","others","unknown"],
"closest_participants_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],
}
读取视频
cap = cv2.VideoCapture('./初赛测试视频/41.avi')
img = cap.read()[1]
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image.resize((600, 300))
这里会输出一张照片:

视频数据理解
# 定义一个JSON对象,用于提交结果。
submit_json = {
"author" : "abc" ,
"time" : "231011",
"model" : "model_name",
"test_results" : []
}
# 使用glob模块获取当前目录下'初赛测试视频'文件夹中所有的文件路径,并按照字典序进行排序
paths = glob.glob('./初赛测试视频/*')
paths.sort()
# 遍历获取到的所有文件路径
for video_path in paths:
print(video_path) # 打印当前处理的文件路径
# 通过文件路径获取视频的剪辑ID(clip_id),这里假设每个文件名都包含剪辑ID
clip_id = video_path.split('/')[-1]
# 使用OpenCV打开视频文件,并尝试读取第一帧(帧率可能不同,所以使用[1]获取第一帧)
cap = cv2.VideoCapture(video_path)
img = cap.read()[1]
# 将图像从BGR格式转换为RGB格式,然后将其转换为PIL图像对象,以便后续处理
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = transforms(image).unsqueeze(0) # transforms可能是一个函数,用于对图像进行预处理,例如调整大小、裁剪等操作,然后使用unsqueeze(0)增加一个维度以适应模型需要
# 定义一个字典,用于存储当前视频的一些基本信息,这些信息可能会被用于后续的文本描述
single_video_result = {
"clip_id": clip_id,
"scerario" : "cityroad", # 这可能是一个拼写错误,应该是 "scenario"
"weather":"unknown", # 天气条件
"period":"night", # 时间段(白天、晚上等)
"road_structure":"ramp", # 道路结构(直路、弯路等)
"general_obstacle":"nothing", # 一般的障碍物(如车辆、行人等)
"abnormal_condition":"nothing", # 异常情况(如事故、交通拥堵等)
"ego_car_behavior":"turning right", # 自车行为(如直行、转弯等)
"closest_participants_type":"passenger car", # 最接近的参与者类型(如行人、其他车辆等)
"closest_participants_behavior":"braking" # 最接近的参与者行为(如刹车、加速等)
}
# 对于英文匹配词汇字典中的每一个关键字(除了"weather"和"road_structure"),执行以下操作:
for keyword in en_match_words.keys():
if keyword not in ["weather", "road_structure"]: # 如果关键字不是"weather"或"road_structure"则继续执行下面的代码块
continue # 跳过当前循环,进入下一次循环,下一个关键字的处理
texts = np.array(en_match_words[keyword]) # 获取该关键字对应的文本列表(假设en_match_words是一个字典,其中键是关键字,值是对应的文本列表)
with paddle.no_grad(): # 在这个代码块中关闭梯度计算,以加速计算过程并节省内存资源
logits_per_image, logits_per_text = model(image, tokenize(en_match_words[keyword])) # 使用模型对图片和文本进行预测,得到每个文本的预测logits值
probs = paddle.nn.functional.softmax(logits_per_image, axis=-1) # 对预测的logits值进行softmax处理,得到每个文本的概率值
probs = probs.numpy() # 将概率值转换为numpy数组格式,以便后续处理
single_video_result[keyword] = texts[probs[0].argsort()[::-1][0]] # 根据概率值排序文本列表,并取出第一个文本作为最终结果,存储到single
输出结果
用 json 文件保存结果。
with open('clip_result.json', 'w', encoding='utf-8') as up:
json.dump(submit_json, up, ensure_ascii=False)
全部代码运行之后,根目录下会生成 clip_result.json,用于结果提交。
4. 提交结果和上分方法
baseline 跑完之后是93分

接下来在 baseline 上做了一些小改动:
加入特征 工况描述 scerario:
if keyword not in ["weather", "road_structure"]:
改为:
if keyword not in ["weather", "road_structure", "scerario", "road_structure"]:
分数提了10!

再改成:
if keyword not in ["weather", "road_structure", "scerario", "period"]:
分数又提高了!

再加入 最近的交通参与者行为closest_participants_behavior:
if keyword not in ["weather", "road_structure", "scerario", "period", "closest_participants_behavior"]:

分数再涨20!
但不是所有特征都能提分,比如 closest_participants_type 、ego_car_behavior 、 abnormal_condition


















 1698
1698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











