










☀️ 最近报名参加了昇思25天学习打卡训练营
☀️ 第1天初步学习了MindSpore的基本操作
☀️ 第2天初步学习了张量Tensor
☀️ 第3天初步学习了数据集Dataset
☀️ 第4天初步学习了数据变换Transforms
☀️ 第5天初步学习了网络构建
☀️ 第6天初步学习了函数式自动微分
☀️ 第7天学习 初学入门 / 初学教程 / 08-模型训练
1. 教程与代码
模型训练一般分为四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。
现在我们有了数据集和模型后,可以进行模型的训练与评估。
1.1 构建数据集
首先从数据集 Dataset加载代码,构建数据集。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
def datapipe(path, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = MnistDataset(path)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)
和之前一样,把 MINST 数据集下载到根目录下。

1.2 定义神经网络模型
从网络构建中加载代码,构建一个神经网络模型。
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
1.3 定义超参、损失函数和优化器
1.3.1 超参
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下:
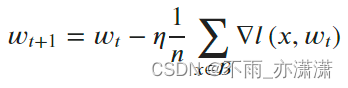
公式中, 𝑛 是批量大小(batch size), η 是学习率(learning rate)。另外, 𝑤𝑡 为训练轮次 𝑡 中的权重参数, ∇𝑙 为损失函数的导数。除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看,它们是影响模型性能收敛最重要的参数。一般会定义以下超参用于训练:
-
训练轮次(epoch):训练时遍历数据集的次数。
-
批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值,因此需要选择合适的batch size,可以有效提高模型精度、全局收敛。
-
学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大,则可能会导致训练不收敛等不可预测的结果。梯度下降法被广泛应用在最小化模型误差的参数优化算法上。梯度下降法通过多次迭代,并在每一步中最小化损失函数来预估模型的参数。学习率就是在迭代过程中,会控制模型的学习进度。
epochs = 3
batch_size = 64
learning_rate = 1e-2
1.3.2 损失函数
损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)等。 nn.CrossEntropyLoss 结合了nn.LogSoftmax和nn.NLLLoss,可以对logits 进行归一化并计算预测误差。
loss_fn = nn.CrossEntropyLoss()
1.3.3 优化器
模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用 SGD(Stochastic Gradient Descent)优化器。
我们通过model.trainable_params()方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
在训练过程中,通过微分函数可计算获得参数对应的梯度,将其传入优化器中即可实现参数优化,具体形态如下:
grads = grad_fn(inputs)
optimizer(grads)
1.4 训练与评估
设置了超参、损失函数和优化器后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
- 训练:迭代训练数据集,并尝试收敛到最佳参数。
- 验证/测试:迭代测试数据集,以检查模型性能是否提升。
接下来我们定义用于训练的train_loop函数和用于测试的test_loop函数。
使用函数式自动微分,需先定义正向函数forward_fn,使用value_and_grad获得微分函数grad_fn。然后,我们将微分函数和优化器的执行封装为train_step函数,接下来循环迭代数据集进行训练即可。
# 定义前向传播函数 forward function
def forward_fn(data, label):
# 通过模型对数据进行前向传播计算,得到预测结果logits
logits = model(data)
# 使用损失函数计算预测结果logits和真实标签label之间的损失
loss = loss_fn(logits, label)
# 返回计算得到的损失和预测结果logits
return loss, logits
# 获取梯度函数 gradient function
# mindspore.value_and_grad 是一个函数,用于同时获取函数的输出值和梯度
# 参数说明:
# - forward_fn: 前向传播函数
# - None: 参数占位符,用于指定不需要求梯度的参数(这里未使用)
# - optimizer.parameters: 需要求梯度的参数,即优化器中的参数
# - has_aux=True: 表示前向传播函数返回多个值(本例中为loss和logits),需要保留辅助输出logits
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 定义一步训练函数 one-step training
def train_step(data, label):
# 使用grad_fn计算损失和梯度
# 注意这里使用grad_fn的返回值,损失和logits(_表示不使用的logits)
# grads是计算得到的梯度
(loss, _), grads = grad_fn(data, label)
# 使用优化器对参数进行更新
optimizer(grads)
# 返回计算得到的损失
return loss
# 定义训练循环函数
def train_loop(model, dataset):
# 获取数据集的总大小
size = dataset.get_dataset_size()
# 设置模型为训练模式
model.set_train()
# 遍历数据集中的每个批次
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
# 对一个批次的数据进行一步训练
loss = train_step(data, label)
# 如果当前批次是每100个批次的开始(即batch是100的倍数)
if batch % 100 == 0:
# 将loss转换为numpy数组以便打印
loss, current = loss.asnumpy(), batch
# 打印当前批次的损失和进度
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
test_loop函数同样需循环遍历数据集,调用模型计算loss和Accuray并返回最终结果。
# 定义测试循环函数
def test_loop(model, dataset, loss_fn):
# 获取数据集的总批次数
num_batches = dataset.get_dataset_size()
# 设置模型为评估模式(关闭dropout、batchnorm的训练模式等)
model.set_train(False)
# 初始化总样本数、测试损失和正确预测的样本数
total, test_loss, correct = 0, 0, 0
# 遍历数据集中的每个批次
for data, label in dataset.create_tuple_iterator():
# 对当前批次的数据进行预测
pred = model(data)
# 累加当前批次的样本数
total += len(data)
# 计算当前批次的损失,并累加
# 注意:这里需要将损失转换为numpy数组,以便进行后续的累加
test_loss += loss_fn(pred, label).asnumpy()
# 获取预测概率最大的类别索引(即预测结果)
# 然后与真实标签进行比较,得到预测正确的样本索引
# 使用numpy的sum函数统计预测正确的样本数
correct += (pred.argmax(1) == label).asnumpy().sum()
# 计算平均测试损失
test_loss /= num_batches
# 计算准确率
accuracy = correct / total
# 打印测试结果
print(f"Test: \n Accuracy: {(100*accuracy):>0.1f}%, Avg loss: {test_loss:>8f} \n")
在计算准确率时,使用了 pred.argmax(1) 来获取每个样本预测概率最大的类别索引(即预测结果),并将其与真实标签 label 进行比较。这里假设 pred 是一个二维张量,其中第二维的大小与类别数相同,且每个样本的预测概率都进行了softmax归一化。argmax(1) 函数沿着第二个维度(即类别维度)找到最大值的索引,得到一个与 label 形状相同的张量,然后通过 == 运算符进行比较,得到一个布尔张量,表示每个样本是否预测正确。最后,使用 asnumpy().sum() 将布尔张量转换为numpy数组并计算预测正确的样本数。
我们将实例化的损失函数和优化器传入train_loop和test_loop中。训练3轮并输出loss和Accuracy,查看性能变化。
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(model, train_dataset)
test_loop(model, test_dataset, loss_fn)
print("Done!")
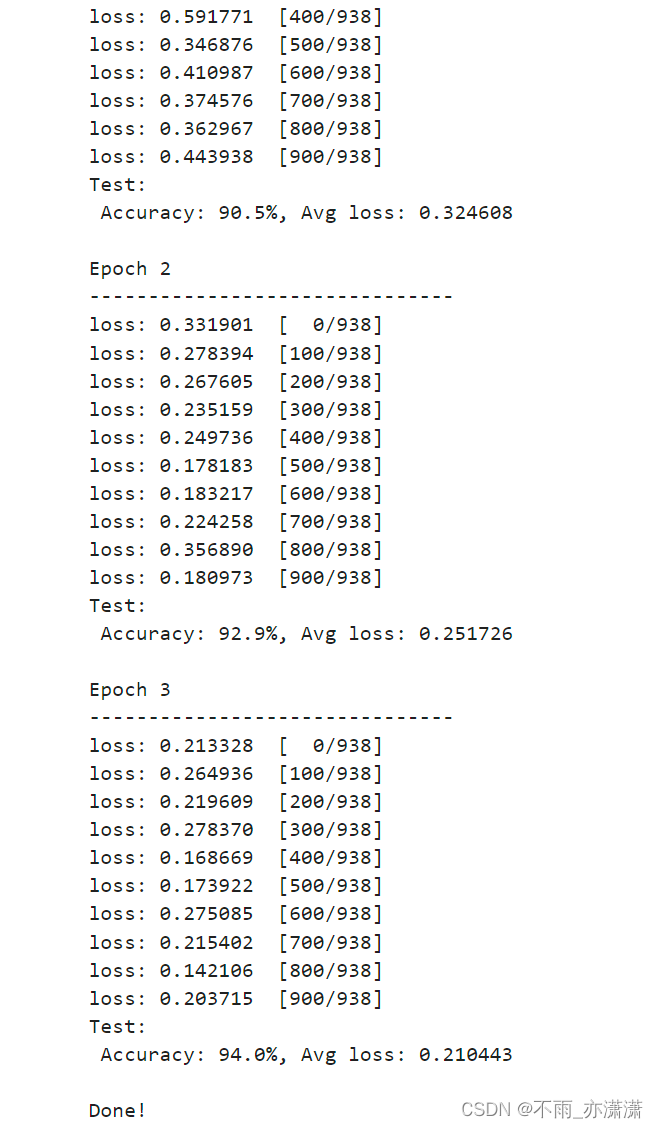
经过一段时间后,输出结果:
Epoch 1
-------------------------------
loss: 2.310621 [ 0/938]
loss: 1.751060 [100/938]
loss: 0.968297 [200/938]
loss: 0.717472 [300/938]
loss: 0.591771 [400/938]
loss: 0.346876 [500/938]
loss: 0.410987 [600/938]
loss: 0.374576 [700/938]
loss: 0.362967 [800/938]
loss: 0.443938 [900/938]
Test:
Accuracy: 90.5%, Avg loss: 0.324608
Epoch 2
-------------------------------
loss: 0.331901 [ 0/938]
loss: 0.278394 [100/938]
loss: 0.267605 [200/938]
loss: 0.235159 [300/938]
loss: 0.249736 [400/938]
loss: 0.178183 [500/938]
loss: 0.183217 [600/938]
loss: 0.224258 [700/938]
loss: 0.356890 [800/938]
loss: 0.180973 [900/938]
Test:
Accuracy: 92.9%, Avg loss: 0.251726
Epoch 3
-------------------------------
loss: 0.213328 [ 0/938]
loss: 0.264936 [100/938]
loss: 0.219609 [200/938]
loss: 0.278370 [300/938]
loss: 0.168669 [400/938]
loss: 0.173922 [500/938]
loss: 0.275085 [600/938]
loss: 0.215402 [700/938]
loss: 0.142106 [800/938]
loss: 0.203715 [900/938]
Test:
Accuracy: 94.0%, Avg loss: 0.210443
Done!
可以看到,随着训练轮次增加,准确率也在提升,最后是94.0%
下面看看超参对结果的影响(控制变量)。
1.4.1 修改epochs
把训练批次调大一倍试试: epochs = 6
Epoch 1
-------------------------------
loss: 0.175775 [ 0/938]
loss: 0.233269 [100/938]
loss: 0.168698 [200/938]
loss: 0.180069 [300/938]
loss: 0.179697 [400/938]
loss: 0.122025 [500/938]
loss: 0.155524 [600/938]
loss: 0.184666 [700/938]
loss: 0.081351 [800/938]
loss: 0.253436 [900/938]
Test:
Accuracy: 94.6%, Avg loss: 0.179912
Epoch 2
-------------------------------
loss: 0.399508 [ 0/938]
loss: 0.139583 [100/938]
loss: 0.207575 [200/938]
loss: 0.140202 [300/938]
loss: 0.080877 [400/938]
loss: 0.055827 [500/938]
loss: 0.121325 [600/938]
loss: 0.108077 [700/938]
loss: 0.175074 [800/938]
loss: 0.245299 [900/938]
Test:
Accuracy: 95.3%, Avg loss: 0.157144
Epoch 3
-------------------------------
loss: 0.130403 [ 0/938]
loss: 0.252430 [100/938]
loss: 0.239051 [200/938]
loss: 0.099728 [300/938]
loss: 0.175949 [400/938]
loss: 0.240394 [500/938]
loss: 0.088452 [600/938]
loss: 0.115153 [700/938]
loss: 0.104933 [800/938]
loss: 0.193794 [900/938]
Test:
Accuracy: 95.8%, Avg loss: 0.141462
Epoch 4
-------------------------------
loss: 0.227399 [ 0/938]
loss: 0.110691 [100/938]
loss: 0.171419 [200/938]
loss: 0.086182 [300/938]
loss: 0.154963 [400/938]
loss: 0.078329 [500/938]
loss: 0.095009 [600/938]
loss: 0.074314 [700/938]
loss: 0.115410 [800/938]
loss: 0.077688 [900/938]
Test:
Accuracy: 96.3%, Avg loss: 0.125190
Epoch 5
-------------------------------
loss: 0.069866 [ 0/938]
loss: 0.158335 [100/938]
loss: 0.078239 [200/938]
loss: 0.035079 [300/938]
loss: 0.071929 [400/938]
loss: 0.117389 [500/938]
loss: 0.088296 [600/938]
loss: 0.062998 [700/938]
loss: 0.154398 [800/938]
loss: 0.146152 [900/938]
Test:
Accuracy: 96.4%, Avg loss: 0.119724
Epoch 6
-------------------------------
loss: 0.098969 [ 0/938]
loss: 0.023322 [100/938]
loss: 0.133667 [200/938]
loss: 0.084907 [300/938]
loss: 0.062920 [400/938]
loss: 0.068926 [500/938]
loss: 0.061599 [600/938]
loss: 0.060509 [700/938]
loss: 0.081936 [800/938]
loss: 0.152974 [900/938]
Test:
Accuracy: 96.9%, Avg loss: 0.105913
Done!
批次数量调大,准确率也提高了,最终96.9%

1.4.2 修改learning_rate
修改学习率为原来的一半: learning_rate = 5e-3
Epoch 1
-------------------------------
loss: 0.149949 [ 0/938]
loss: 0.076181 [100/938]
loss: 0.084535 [200/938]
loss: 0.035498 [300/938]
loss: 0.067121 [400/938]
loss: 0.051831 [500/938]
loss: 0.029101 [600/938]
loss: 0.166015 [700/938]
loss: 0.076999 [800/938]
loss: 0.027612 [900/938]
Test:
Accuracy: 97.0%, Avg loss: 0.102585
Epoch 2
-------------------------------
loss: 0.030460 [ 0/938]
loss: 0.089365 [100/938]
loss: 0.067722 [200/938]
loss: 0.131093 [300/938]
loss: 0.125349 [400/938]
loss: 0.049629 [500/938]
loss: 0.111569 [600/938]
loss: 0.101287 [700/938]
loss: 0.154909 [800/938]
loss: 0.079005 [900/938]
Test:
Accuracy: 97.1%, Avg loss: 0.100701
Epoch 3
-------------------------------
loss: 0.062168 [ 0/938]
loss: 0.042890 [100/938]
loss: 0.159806 [200/938]
loss: 0.033079 [300/938]
loss: 0.090644 [400/938]
loss: 0.054009 [500/938]
loss: 0.069954 [600/938]
loss: 0.091765 [700/938]
loss: 0.065121 [800/938]
loss: 0.111553 [900/938]
Test:
Accuracy: 97.1%, Avg loss: 0.096890
Done!
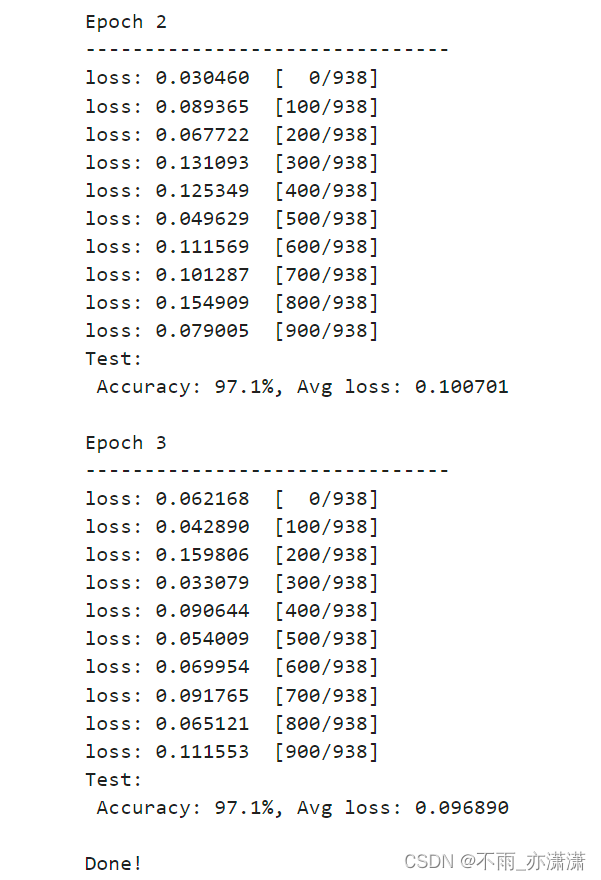
学习率调小,准确率也提高了,最终97.1%
2. 小结
今天学习了模型训练,是基于之前的网络构建的。
模型训练分为以下四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。

















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











