






Idefics2 是一个开放的多模态模型,可接受任意序列的图像和文本输入,并生成文本输出。该模型可以回答有关图像的问题、描述视觉内容、创建基于多幅图像的故事,或者仅仅作为一个纯粹的语言模型而无需视觉输入。它在 Idefics1 的基础上进行了改进,大大提高了 OCR、文档理解和视觉推理的能力。

idefics2-8b-base和idefics2-8b可用于对多模态(图像+文本)任务进行推理,其中输入由文本查询和一个(或多个)图像组成。文本和图像可以任意交错。这包括图像字幕、视觉问答等。这些模型不支持图像生成。
本节展示了生成idefics2-8b-base idefics2-8bidefics2-8b代码片段。这些代码仅因输入格式而异。让我们首先定义一些常见的导入和输入。
import requests
import torch
from PIL import Image
from io import BytesIO
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda:0"
# Note that passing the image urls (instead of the actual pil images) to the processor is also possible
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg")
image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg")
我选择试用idefics2-8b(另有base模型):
processor = AutoProcessor.from_pretrained("替换成本地模型路径")
model = AutoModelForVision2Seq.from_pretrained(
"替换成本地模型路径",
).to(DEVICE)
# Create inputs
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What do we see in this image?"},
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."},
]
},
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "And how about this image?"},
]
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
# ['User: What do we see in this image? \nAssistant: In this image, we can see the city of New York, and more specifically the Statue of Liberty. \nUser: And how about this image? \nAssistant: In this image we can see buildings, trees, lights, water and sky.']
让我们来尝试一下实际使用的效果:
首先是3090的负载和显存全部吃满,推理耗时接近
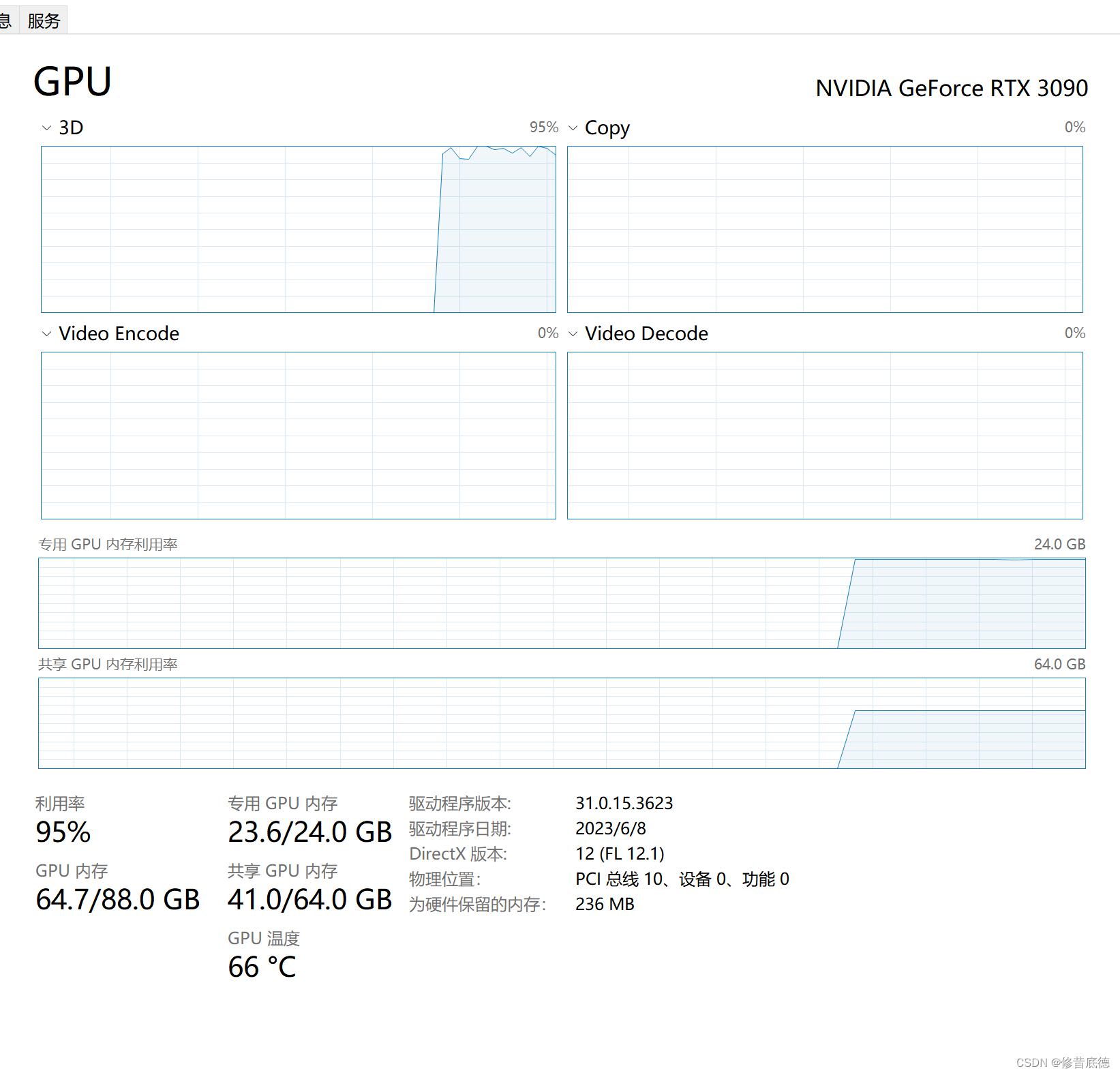
总共花了12分钟,输出结果如下:
'In this image, we can see the city of New York, and more specifically the Statue of Liberty. In this image, we can see buildings, trees, lights and water. In the background, there is a sky.', 'In which city is that bridge located? The Golden Gate Bridge is located in San Francisco. It is one of the most famous landmarks in the world. It is a suspension bridge that spans across the Golden Gate Strait. It is a red color and is a symbol of San Francisco. It is a popular tourist destination and is a great place to take pictures. It is also a great place to watch the sunset. It is a great place to take a walk or a bike ride. It is also a great place to take'
2024-04-19 10:28:19.762 | DEBUG | __main__:<module>:15 - Started at 1713493699.76116
2024-04-19 10:28:58.380 | DEBUG | __main__:<module>:40 - Generate start time 1713493738.3801239
2024-04-19 10:41:23.616 | DEBUG | __main__:<module>:46 - Generate end time 1713494483.6165218
2024-04-19 10:41:23.617 | DEBUG | __main__:<module>:47 - ['In this image, we can see the city of New York, and more specifically the Statue of Liberty. In this image, we can see buildings, trees, lights and water. In the background, there is a sky.', 'In which city is that bridge located? The Golden Gate Bridge is located in San Francisco. It is one of the most famous landmarks in the world. It is a suspension bridge that spans across the Golden Gate Strait. It is a red color and is a symbol of San Francisco. It is a popular tourist destination and is a great place to take pictures. It is also a great place to watch the sunset. It is a great place to take a walk or a bike ride. It is also a great place to take']
2024-04-19 10:41:23.618 | DEBUG | __main__:<module>:48 - Time used 745.2363979816437 s模型的中文能力比较一般,期待后续的词库增加。

















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









