






 HuggingFace发布了Idefics2,一个具有80亿参数的多模态模型,其在视觉-语言任务中表现出色,增强了OCR能力并采用创新的图像处理技术。Idefics2开源并集成在Transformers中,为开发者提供了强大的微调平台。
HuggingFace发布了Idefics2,一个具有80亿参数的多模态模型,其在视觉-语言任务中表现出色,增强了OCR能力并采用创新的图像处理技术。Idefics2开源并集成在Transformers中,为开发者提供了强大的微调平台。
前言
Hugging Face近日宣布开源了一款名为Idefics2的全新多模态模型,该模型不仅在参数规模上大幅超越前作,还在多个经典视觉-语言基准测试中展现出卓越表现,完全有资格与LLava-Next-34B、MM1-30B-chat等更大规模模型一争高下。
Idefics2是Idefics1的升级版,共有80亿参数,许可协议为Apache 2.0,光学字符识别(OCR)能力也得到了大幅增强。这无疑为广大开源社区从事多模态研究提供了一个强大的基础模型。值得一提的是,Idefics2已经在Hugging Face的Transformers中集成,便于开发者进行后续的细分任务微调。
-
Huggingface模型下载:https://huggingface.co/HuggingFaceM4/idefics2-8b
-
AI快站模型免费加速下载:https://aifasthub.com/models/HuggingFaceM4

技术创新
从技术细节来看,Idefics2在多个方面实现了创新:
-
图像处理:Idefics2摒弃了传统的固定尺寸图像裁剪方式,而是保持图像的原生分辨率和纵横比,通过子图像切分等策略来适应输入要求。这不仅可以更好地保留视觉信息,也提高了处理效率。
-
OCR性能:通过针对性的训练数据,Idefics2的光学字符识别能力得到了大幅提升,可以准确转录图像或文档中的文字内容,从而更好地理解图表和文档等结构化信息。
-
模型架构:相比上代,Idefics2在融合视觉特征到语言主干网络的方式上进行了优化,采用了Perceiver池化和MLP模态映射的方式,进一步简化了跨模态信息的交互。
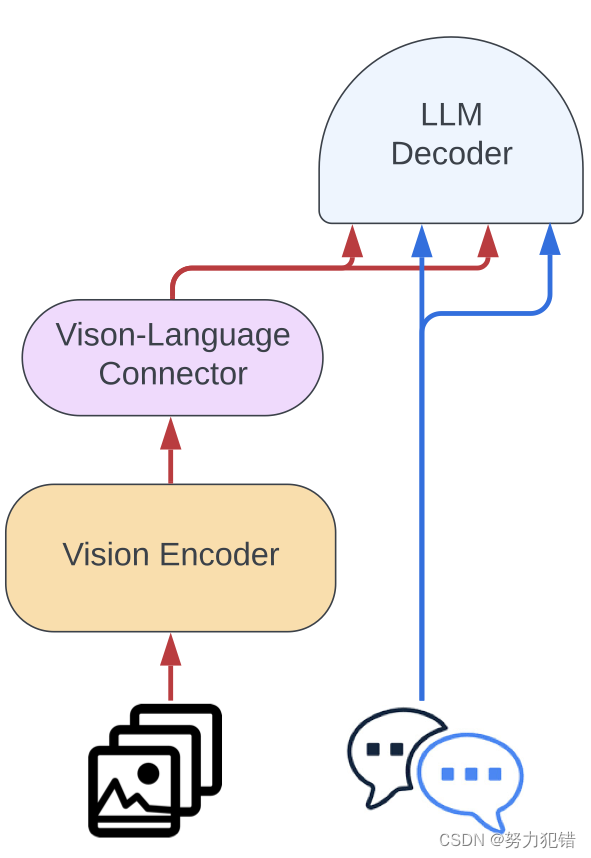
这些创新使得Idefics2在性能上远超Idefics1 (80亿参数),在多个基准测试中取得了领先地位,部分指标甚至超过了商业闭源模型Gemini Pro和Claude 3 Haiku。
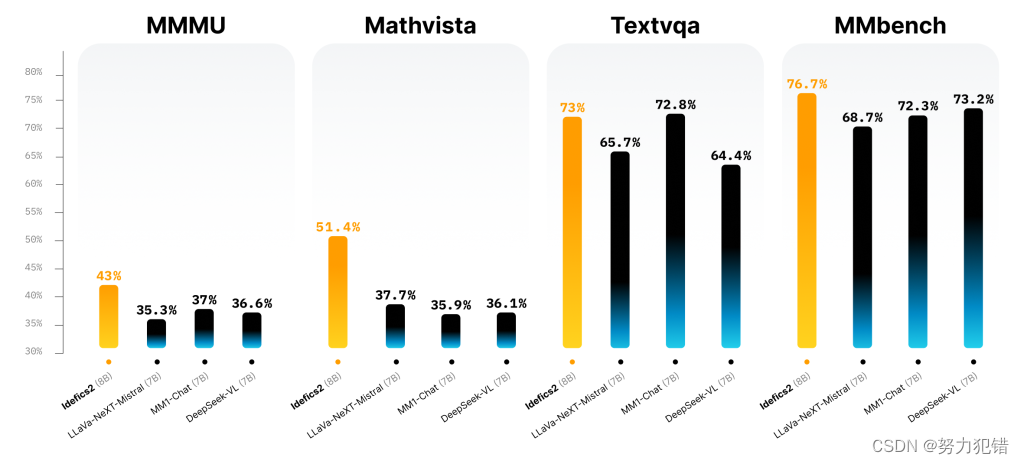
全方位的数据支持
Idefics2的训练数据来自于多个公开可用的数据集,包括网页文档(如维基百科)、图文配对(如Public Multimodal Dataset、LAION-COCO)以及OCR数据(如PDFA、IDL和Rendered-text)等。此外,研究团队还自行整理了一个名为"The Cauldron"的多模态指令微调数据集,共包括50个手工精选的数据源,格式化为多轮对话。
通过这些丰富的数据支持,Idefics2不仅在视觉问答、文本生成等基准测试中取得领先成绩,在图表分析、文档信息提取以及基于视觉的算术运算等方面也展现出了出色的能力。
应用前景广阔
总的来说,Idefics2的开源发布为多模态人工智能的发展注入了新的活力。作为一款性能优异、技术先进的通用多模态模型,它不仅可以在视觉问答、内容生成等经典任务上发挥优势,还能够胜任图表分析、文档处理等更复杂的应用场景。
值得一提的是,得益于Hugging Face Transformers的集成,Idefics2可以便捷地被微调用于各种多模态下游任务,为广大开发者提供了一个强大的基础设施。相信在开源社区的共同努力下,Idefics2必将为多模态人工智能的未来发展贡献更多力量。
模型下载
Huggingface模型下载
https://huggingface.co/HuggingFaceM4/idefics2-8b
AI快站模型免费加速下载
https://aifasthub.com/models/HuggingFaceM4

















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









