







 集成学习通过结合多个模型提升性能,包括Bagging(如随机森林)和Boosting(如Adaboost和GBDT)。随机森林采用CART决策树,通过有放回抽样构建独立的决策树并取平均数得出结果。在Python中,可以使用scikit-learn实现随机森林模型。虽然随机森林抗噪声能力强,但解释性较弱。
集成学习通过结合多个模型提升性能,包括Bagging(如随机森林)和Boosting(如Adaboost和GBDT)。随机森林采用CART决策树,通过有放回抽样构建独立的决策树并取平均数得出结果。在Python中,可以使用scikit-learn实现随机森林模型。虽然随机森林抗噪声能力强,但解释性较弱。
欢迎关注”生信修炼手册”!
集成学习并不是一个具体的模型或者算法,而是一个解决问题的框架,其基本思想是综合参考多个模型的结果,以提高性能,类似三个臭皮匠,顶个诸葛亮,图示如下
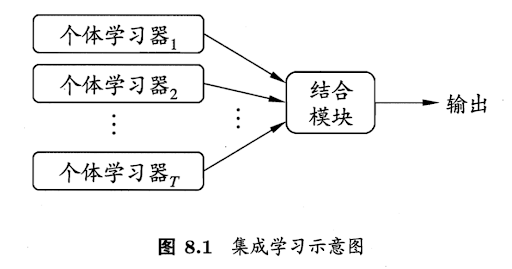
要运用集成学习,就需要一个拆分和结合的过程,首先是拆分,将总的输入数据拆分成多份数据,每个数据运用一个单独的模型,然后是结合,集合拆分后建立的各个子模型,得到最终的结果。
具体到策略上,常用的有以下两类
1. Bagging
Bagging是Boostrapping Aggregating的结合体,通过随机抽样的方式将输入数据拆分成独立的N份,针对每一份数据单独建模,示例如下
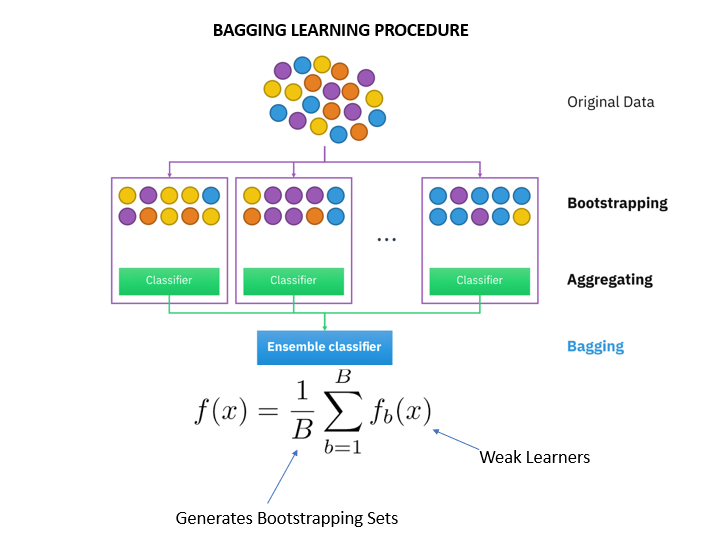
属于该策略的算法,最典型的就是RandomForset-随机森林算法。在该策略中,拆分成的数据是相互独立的,可以并行执行其建模过程,最后再进行汇总。汇总时每个子模型的权重是相等的。
2. Boosting
区别于Bagging, Boosting的数据集之间是存在依赖关系的,图示如下
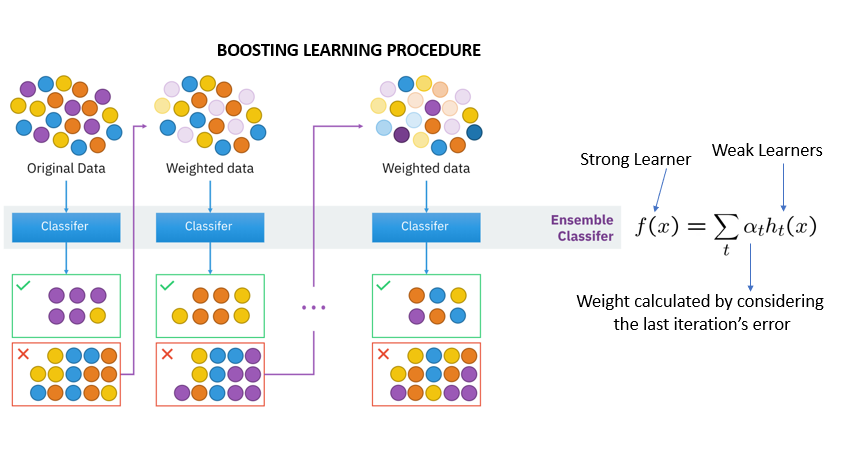
属于该策略的算法,典型的有Adaboost和GBDT梯度提升树。在最后汇总时,各个子模型会拥有不同的权重。
对于随机森林而言,其核心的模型是基于CART的决策树,图示如下
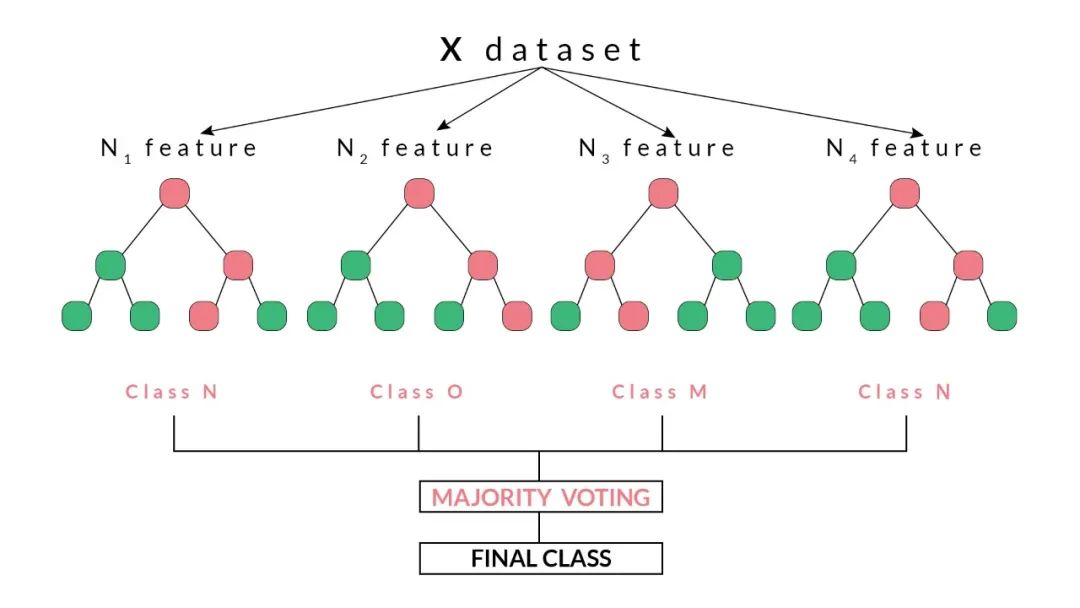
具体的过程如下
1.首先基于有放回的随机抽样,抽取出N份独立的数据,因为是有放回的抽样,可以保证抽取的数据集和原始的数据集大小相同;
2.对每一份抽取的数据集构建决策树模型,因为相互独立,所以可以并行;
3.汇总多个模型的结果,对于回归问题,直接计算多个模型的算数平均数即可,对于分类问题,直接选取个数多的分类结果就好;
在scikit-learn中,使用随机森林模型的代码如下
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_classification
>>> X, y = make_classificat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3181
3181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









