









在数字人文学科中,自动识别和分类历史文献中的视觉元素(如插图、照片、广告等)对于文献的整理、研究和展示具有重要意义。YOLOv11 模型,作为 YOLO 系列的最新版本,提供了高效的目标检测能力,特别适用于处理历史报纸等复杂布局的文档。
模型概述
biglam/historic-newspaper-illustrations-yolov11 是一个基于 YOLOv11 架构的目标检测模型,专门用于识别历史报纸页面中的七类视觉内容:X (formerly Twitter)+2Hugging Face+2Hugging Face+2
-
照片(Photographs)
-
插图(Illustrations)
-
地图(Maps)
-
漫画/卡通(Comics/Cartoons)
-
社论漫画(Editorial Cartoons)
-
标题(Headlines)
-
广告(Advertisements)ResearchGate+1arXiv+1Hugging Face+1arXiv+1
该模型训练于 Beyond Words 数据集,该数据集由美国国会图书馆的 Chronicling America 项目提供,包含 3,559 页带有 48,409 个标注的历史报纸页面,标注格式为 COCO。Hugging Face+1arXiv+1
快速开始
下载模型并导入相关视图文件
模型文件:biglam/historic-newspaper-illustrations-yolov11 at main
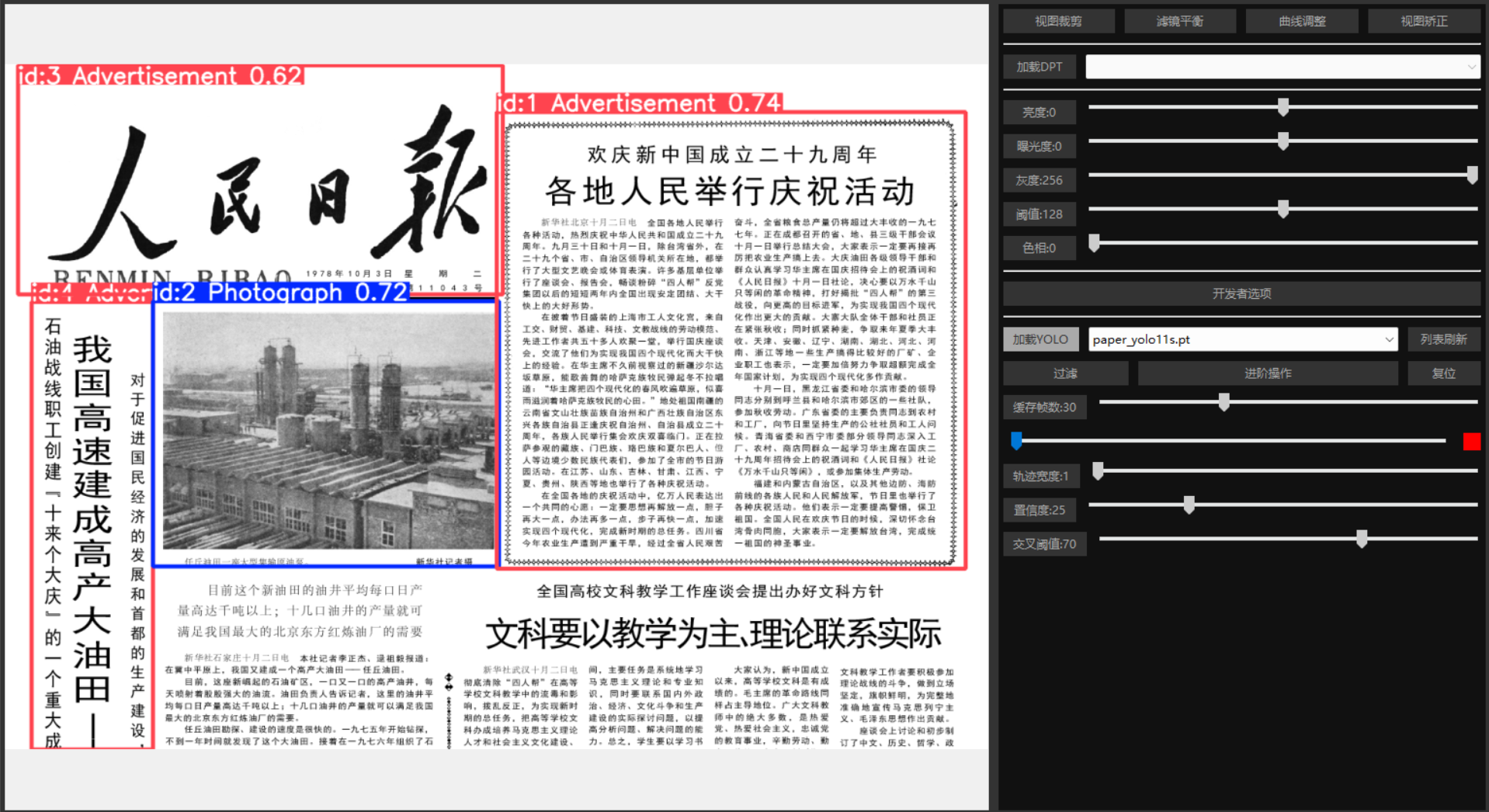




应用场景
该模型可广泛应用于以下领域:
-
数字人文研究:自动提取和分类历史报纸中的视觉元素,辅助研究人员进行内容分析。
-
档案整理:提高历史文献数字化过程中的自动化程度,减少人工标注工作量。
-
教育与展示:为博物馆和教育机构提供可视化的历史资料展示工具。
模型性能
根据模型的发布信息,YOLOv11 在处理历史报纸图像时表现出色,能够准确识别多种视觉元素。其轻量级的架构使得模型在保持高精度的同时,具备较快的推理速度,适合大规模文档处理任务。
总结
biglam/historic-newspaper-illustrations-yolov11 模型为历史文献的数字化和研究提供了强有力的工具。通过自动识别和分类报纸中的视觉内容,研究人员和档案管理者可以更高效地处理和分析大量历史文献。随着数字人文学科的发展,类似的计算机视觉工具将在文献研究和文化遗产保护中发挥越来越重要的作用。

















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









