






UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs(UFOGen:通过扩散 GAN 实现大规模文本到图像生成 CVPR)
文本到图像的扩散模型在将文本提示转换为连贯图像方面表现出了卓越的能力,但多步骤推理的计算成本仍然是一个持续的挑战。为了解决这个问题,我们提出了 UFOGen,这是一种新颖的生成模型,专为超快速、一步式文本到图像生成而设计。与专注于改进采样器或采用扩散模型蒸馏技术的传统方法相比,UFOGen 采用混合方法,将扩散模型与 GAN 目标集成。利用新引入的扩散-GAN 目标和预训练扩散模型的初始化,UFOGen 擅长在一步中高效生成以文本描述为条件的高质量图像。除了传统的文本到图像生成之外,UFOGen 还展示了应用程序的多功能性。值得注意的是,UFOGen 是支持一步文本到图像生成和多样化下游任务的先驱模型之一,在高效生成模型领域取得了重大进步。
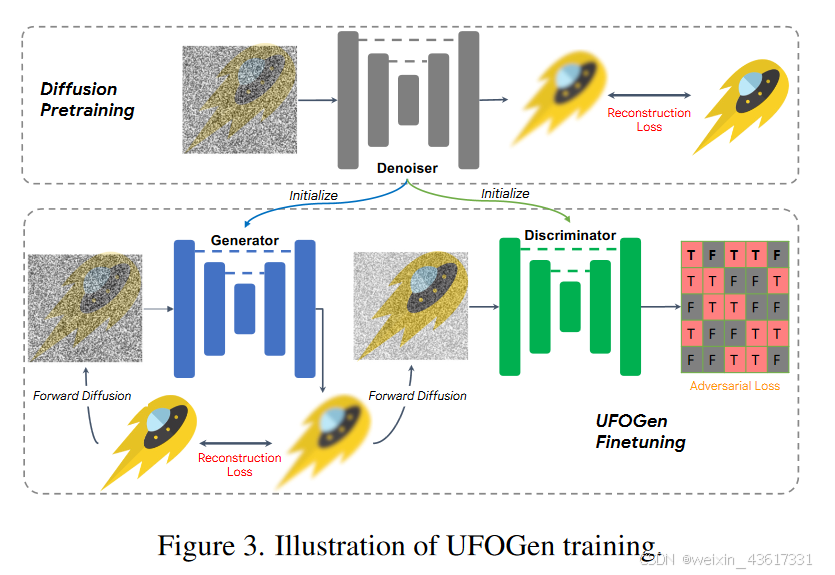
在UFOGen中,扩散模型的角色是提供一个稳健的图像生成过程,而GAN的目标则是优化这个过程,使其更加高效和快速。

在宋等人的开创性工作中。 [58]表明,从扩散模型中采样相当于求解与扩散过程相关的概率流常微分方程(PFODE)。目前,大多数旨在提高扩散模型采样效率的研究都集中在 ODE 公式上。其中一项工作旨在改进 PF-ODE 的数值求解器,旨在以更大的离散化尺寸求解 ODE,最终减少所需的采样步骤 [2,37,38,57]。
However, the inherent trade-off between step size and accuracy still exists. Given the highly non-linear and complicated trajectory of the PF-ODE, it would be extremely difficult to reduce the number of required sampling steps to a minimal level. Even the most advanced solvers [37, 38] can generate images within 10 to 20 sampling steps, and further reduction leads to a noticeable drop in image quality. An alternative approach seeks to distill the PF-ODE trajectory from a pretrained diffusion model.(然而,步长和精度之间固有的权衡仍然存在。考虑到 PF-ODE 的高度非线性和复杂轨迹,将所需采样步骤的数量减少到最低水平将是极其困难的。即使是最先进的求解器 [37, 38] 也可以在 10 到 20 个采样步骤内生成图像,进一步减少会导致图像质量明显下降。另一种方法寻求从预训练的扩散模型中提取 PF-ODE 轨迹。)
For instance, progressive distillation [31, 41, 52] tries to condense multiple discretization steps of the PF-ODE solver into a single step by explicitly aligning with the solver’s output. Similarly, consistency distillation [39, 59] works on learning consistency mappings that preserve point consistency along the ODE trajectory. These methods have demonstrated the potential to significantly reduce the number of sampling steps. However, due to the intrinsic complexity of the ODE trajectory, they still struggle in the extremely small step regime.(例如,渐进蒸馏 [31,41,52] 尝试通过与求解器的输出显式对齐,将 PF-ODE 求解器的多个离散化步骤压缩为单个步骤。类似地,一致性蒸馏 [39, 59] 致力于学习一致性映射,以保持 ODE 轨迹上的点一致性。这些方法已经证明了显着减少采样步骤数量的潜力。然而,由于 ODE 轨迹的内在复杂性,它们仍然在极小的步长范围内挣扎。)
We assert that to achieve this ambitious objective, fundamental adjustments are necessary in the formulation of diffusion models, as the current ODE-based approaches seem intrinsically constrained for very few steps sampling. In this work, we introduce a novel one-step text-to-image generative model, representing a fusion of GAN and diffusion model elements. Our inspiration stems from previous work that successfully incorporated GANs into the framework of diffusion models [61, 62, 65, 71], which have demonstrated the capacity to generate images in as few as four steps when trained on small-scale datasets. These models diverge from the traditional ODE formulation by leveraging adversarial loss for learning the denoising distribution, rather than relying on KL minimization.(我们断言,为了实现这一雄心勃勃的目标,在扩散模型的制定中需要进行根本性的调整,因为当前基于常微分方程的方法似乎本质上仅限于很少的步骤采样。在这项工作中,我们引入了一种新颖的一步式文本到图像生成模型,代表了 GAN 和扩散模型元素的融合。我们的灵感源于之前的工作,该工作成功地将 GAN 纳入扩散模型的框架中 [61,62,65,71],这些模型已经证明了在小规模数据集上训练时只需四个步骤即可生成图像的能力。这些模型与传统的 ODE 公式不同,它们利用对抗性损失来学习去噪分布,而不是依赖 KL 最小化。)
尽管早期扩散 GAN 混合模型取得了有希望的成果,但实现一步采样并将其实用性扩展到文本到图像生成仍然是一项不小的挑战。在这项研究中,我们引入了增强扩散 GAN 模型的创新技术,从而产生了能够在单个采样步骤中生成高质量图像的超快速文本到图像模型。鉴于这一成就,我们将我们的模型命名为 UFOGen,这是表示“You Forward Once”生成模型的缩写。我们的 UFOGen 模型擅长仅通过一个推理步骤即可生成高质量图像。值得注意的是,当使用预训练的稳定扩散(SD)模型[49]进行初始化时,我们的方法有效地将 SD 转换为一步推理模型,同时在很大程度上保留了生成内容的质量。请参阅图 1,了解 UFOGen 生成的文本条件图像的展示。据我们所知,我们的模型是将文本到图像扩散模型所需的采样步骤数量减少到一个的先驱之一。
Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting(结构很重要:解决图像修复扩散模型中的语义差异)
用于图像修复的去噪扩散概率模型(DDPM)旨在在前向过程中将噪声添加到图像的纹理中,并通过反向去噪过程用纹理的未遮蔽区域恢复遮蔽区域。尽管产生了有意义的语义,但现有的技术仍遭受屏蔽和未屏蔽区域之间的语义差异,因为语义密集的未屏蔽纹理无法完全降级,而屏蔽区域在扩散过程中变成纯噪声,从而导致较大的差异他们之间。在本文中,我们的目标是回答非掩码语义如何指导纹理去噪过程;以及如何解决语义差异,以促进一致且有意义的语义生成。为此,我们提出了一种新颖的结构引导扩散模型,名为 StrDiffusion,在结构引导下重新表述传统的纹理去噪过程,导出图像修复的简化去噪目标,同时揭示:1)语义稀疏结构是有利于解决前期的语义差异,而密集的纹理则在后期产生合理的语义; 2)来自未遮蔽区域的语义实质上为纹理去噪过程提供了时间相关的结构指导,受益于结构语义的时间相关的稀疏性。对于去噪过程,训练结构引导神经网络,通过利用屏蔽和未屏蔽区域之间去噪结构的一致性来估计简化的去噪目标。此外,我们设计了一种自适应重采样策略作为结构是否能够指导纹理去噪过程并同时调节它们的语义相关性的正式标准。大量实验验证了 StrDiffusion 相对于最先进技术的优点。
近年来,图像修复已经支持了广泛的应用,例如照片修复和图像编辑,其目的是利用未遮蔽区域的语义信息来恢复图像的遮蔽区域,其原理主要涵盖两个方面:屏蔽区域及其与未屏蔽区域的语义一致性。
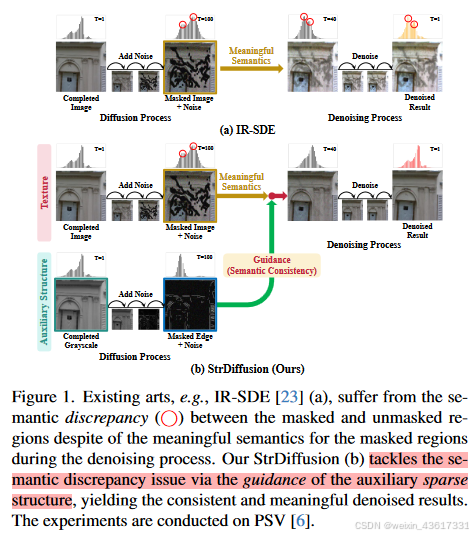
幸运的是,去噪扩散概率模型(DDPM)[12, 25]已经成为强大的生成模型,在语义生成和模式收敛方面取得了显着的成果,从而很好地弥补了图像修复不良语义生成的问题[22,23,29] ,38]。具体来说,[22]提出采用预训练的DDPM作为先验,而不是关注训练过程,并开发一种重采样策略来在推理过程中调节反向去噪过程。此外,[23]尝试通过利用未遮蔽区域的语义来对图像修复的扩散过程进行建模,从而产生去噪过程的最佳逆向解决方案。这些方法大多利用 DDPM 的优点展示语义上有意义的修复结果,而忽略了屏蔽区域和未屏蔽区域之间的语义一致性。直觉是,语义密集的未遮蔽纹理退化为未遮蔽纹理和高斯噪声的组合,而遮蔽区域在扩散过程中变成纯噪声,导致它们之间存在较大差异(见图1( a) 和图 2(a)),并激发以下内容:
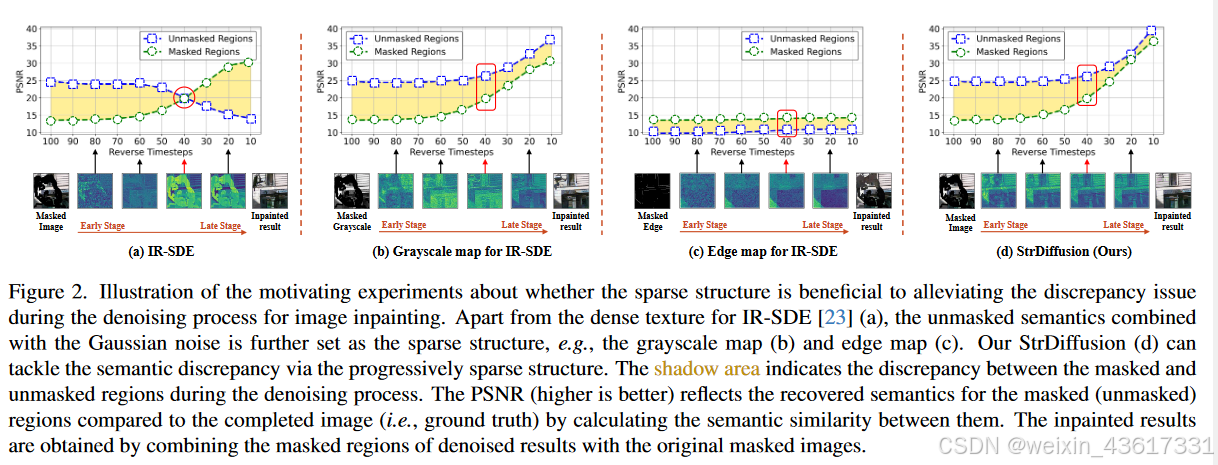
(1) 无遮盖区域的语义如何指导图像修复中的纹理去噪过程?我们的动机实验(见图2)表明,当无遮盖区域的语义与噪声结合变得更加稀疏时,例如,利用遮盖图像的灰度图或边缘图作为替代,差异问题得到很大程度的缓解,但同时在修复结果中会伴随大量的语义信息丢失;参见图2(b)©。因此,随着时间推移,来自无遮盖区域的恒定语义无法很好地指导纹理去噪过程。
(2) 基于(1),自然会有人想知道如何生成具有一致且有意义语义的去噪结果。显然,在去噪过程的早期阶段,稀疏结构有利于语义一致性,而在后期阶段,密集的纹理则倾向于生成有意义的语义,这暗示了在去噪结果中保持一致且合理语义之间的平衡。为了进一步得到理想的结果,我们考虑在纹理去噪过程中引入结构作为辅助指导;见图1(b)。
为了回答上述问题,我们提出了一种新的结构引导纹理扩散模型,称为StrDiffusion,用于图像修复,以解决遮蔽区域与无遮蔽区域之间的语义差异问题,同时生成遮蔽区域的合理语义。从技术上讲,我们重新构建了传统的纹理去噪过程,在结构的指导下推导出一个简化的去噪目标,用于图像修复。在去噪过程中,训练了一个结构引导的神经网络来估计简化的去噪目标,该网络利用遮蔽区域和无遮蔽区域之间去噪结构的时间一致性来减轻语义差异问题。我们的StrDiffusion模型揭示了:1)语义稀疏的结构在去噪过程的早期阶段有助于生成一致的语义,而密集的纹理则在后期阶段完成语义生成;2)无遮蔽区域的语义本质上为纹理去噪过程提供了时间相关的结构指导,受益于结构语义的时间相关稀疏性。同时,我们指出,结构是否能很好地引导纹理,极大地取决于它们之间的语义相关性。受此启发,我们提出了一种自适应重采样策略,通过重采样迭代来监控语义相关性并进行调整。在典型数据集上的大量实验验证了StrDiffusion相较于最新技术的优越性。
我们的方法的核心有三个方面:1)如何解决遮蔽区域和无遮蔽区域之间的语义差异(见第2.2节);2)用于图像修复的结构引导去噪网络(见第2.3节);以及3)关于结构是否能很好地引导纹理的更多见解(见第2.4节)。在阐明我们的技术之前,我们将详细介绍用于图像修复的DDPM(扩散概率模型)。



注释 1. 随着时间的推移增强结构的语义稀疏性

在整个纹理扩散过程中,随着时间步数逐渐增加到完全遮蔽状态(见图4(a)),遮蔽区域与无遮蔽区域之间的语义差异逐渐增大。为了减少这种语义差异,我们的目标是在扩散过程中增强结构的语义稀疏性,而不是纹理。具体而言,稀疏的灰度图通过噪声计划退化为更稀疏的遮蔽边缘图和高斯噪声的组合;见图4(b)。我们的基本思路是在去噪过程中通过结构的引导解决语义差异问题,从而简化纹理去噪的目标,即去噪过程的最优解(即真实值),这一点将在下文讨论。
2.2.2 在结构引导下去噪过程的最优解
根据上述观察,在纹理扩散过程中,由于遮蔽区域和无遮蔽区域之间的语义差异,每个时间步中添加的噪声分布被扰乱,导致在去噪过程中通过噪声预测网络难以估计该噪声分布。我们不是单纯地关注纹理,而是结合结构和纹理进行扩散过程,其中结构的稀疏性缓解了语义差异,纹理则试图保留有意义的语义。与同时利用结构和纹理的扩散过程不同,在去噪过程中,结构首先在遮蔽和无遮蔽区域之间生成一致的语义(xt-1),随后引导纹理生成有意义的语义(yt-1);见图3。在StrDiffusion结构的帮助下,纹理扩散过程生成了一致且有意义的修复输出。
注释 2. 与典型的用于修复的DDPMs[22, 23]不同,我们的StrDiffusion利用去噪后结构的语义一致性来引导纹理去噪过程,生成既一致又有意义的去噪结果。特别地,我们将结构视为引导纹理的辅助,而不是反过来;原因有两点:1) 在推理去噪过程中,遮蔽区域主要关注要被修复的纹理,而非结构;2) 结构关注遮蔽和无遮蔽区域之间的一致性,缺乏有意义的语义,因此仍依赖纹理进行修复。得益于结构的引导,公式(3)中的纹理逆转过程可以通过贝叶斯规则重新表述如下:
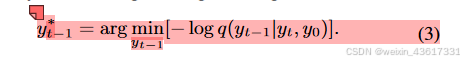
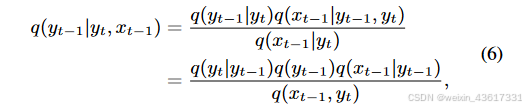

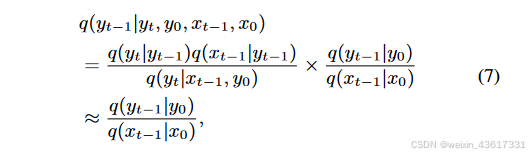

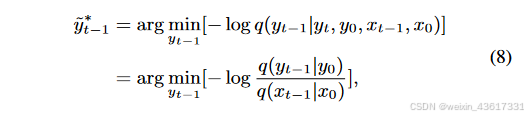

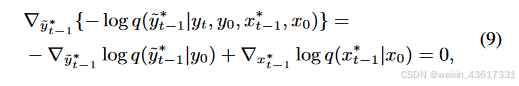

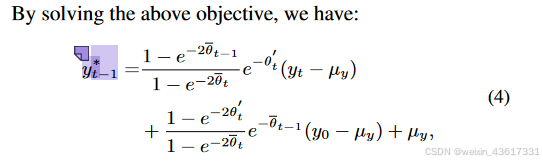
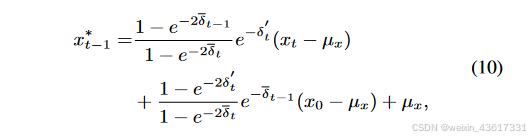

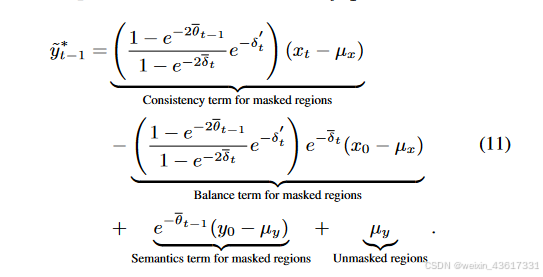


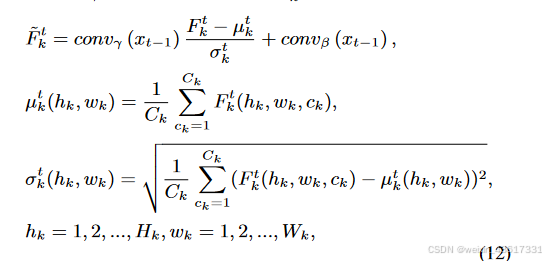


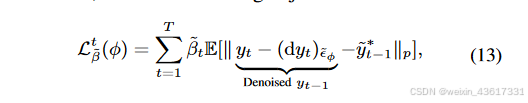


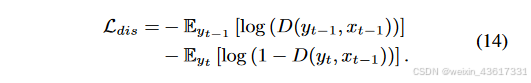

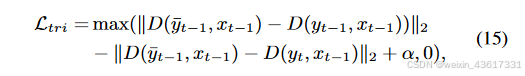

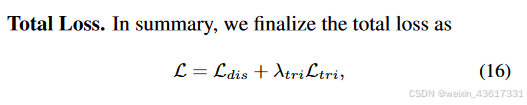


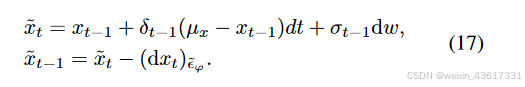


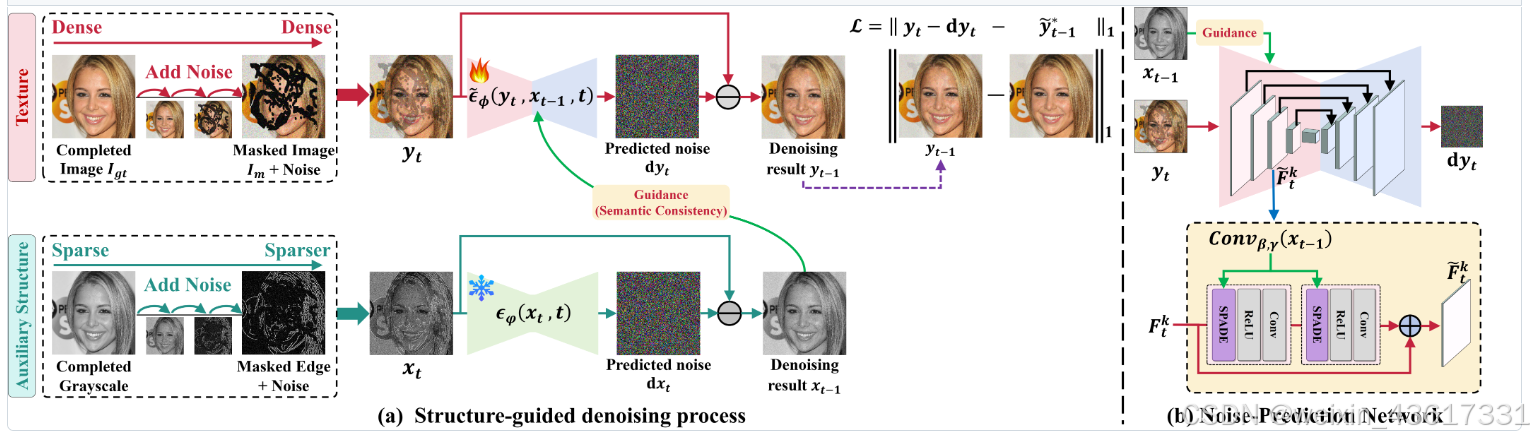
图3. 所提出的StrDiffusion流程图示意。 我们的基本思路是通过逐步稀疏化的结构(a)的引导来解决遮蔽区域和未遮蔽区域之间的语义差异问题,进而引导纹理去噪网络(b)生成一致且有意义的去噪结果。

















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









