









import numpy as np
import cv2
import seaborn as sns
import matplotlib.pyplot as plt
# 也可以直接采用这个进行计算
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score, roc_auc_score, recall_score, precision_score
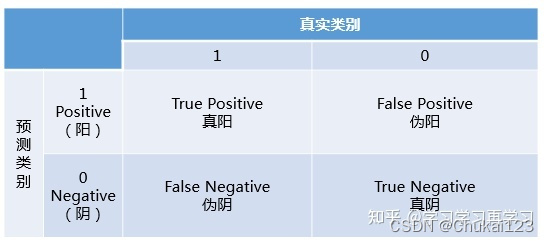
# 加载confusion图,并显示对应的图像表示混淆矩阵的信息
img = cv2.imread("confusion_figure.jpg")
plt.imshow(img)
def calculate_metrics(gt, pred):
"""
:param gt: 数据的真实标签,一般对应二分类的整数形式,例如:y=[1,0,1,0,1]
:param pred: 输入数据的预测值,因为计算混淆矩阵的时候,内容必须是整数,所以对于float的值,应该先调整为整数
:return: 返回相应的评估指标的值
"""
"""
confusion_matrix(y_true,y_pred,labels,sample_weight,normalize)
y_true:真实标签;
y_pred:预测概率转化为标签;
labels:用于标签重新排序或选择标签子集;
sample_weight:样本权重;
normalize:在真实(行)、预测(列)条件或所有总体上标准化混淆矩阵;
"""
print("starting!!!-----------------------------------------------")
sns.set()
fig, (ax1, ax2) = plt.subplots(figsize=(10, 8), nrows=2)
confusion = confusion_matrix(gt, pred)
# 打印具体的混淆矩阵的每个部分的值
print(confusion)
# 从左到右依次表示TN、FP、FN、TP
print(confusion.ravel())
# 绘制混淆矩阵的图
sns.heatmap(confusion,annot=True)
ax2.set_title('sns_heatmap_confusion_matrix')
ax2.set_xlabel('y_pred')
ax2.set_ylabel('y_true')
fig.savefig('sns_heatmap_confusion_matrix.jpg', bbox_inches='tight')
# 混淆矩阵的每个值的表示
TP = confusion[1, 1]
TN = confusion[0, 0]
FP = confusion[0, 1]
FN = confusion[1, 0]
# 通过混淆矩阵计算每个评估指标的值
print('AUC:',roc_auc_score(gt, pred))
print('Accuracy:', (TP + TN) / float(TP + TN + FP + FN))
print('Sensitivity:', TP / float(TP + FN))
print('Specificity:', TN / float(TN + FP))
print('PPV:',TP / float(TP + FP))
print('Recall:',TP / float(TP + FN))
print('Precision:',TP / float(TP + FP))
# 用于计算F1-score = 2*recall*precision/recall+precision,这个情况是比较多的
P = TP / float(TP + FP)
R = TP / float(TP + FN)
print('F1-score:',(2*P*R)/(P+R))
print('True Positive Rate:',round(TP / float(TP + FN)))
print('False Positive Rate:',FP / float(FP + TN))
print('Ending!!!------------------------------------------------------')
# 采用sklearn提供的函数验证,用于对比混淆矩阵方法与这个方法的区别
print("the result of sklearn package")
auc = roc_auc_score(gt,pred)
print("sklearn auc:",auc)
accuracy = accuracy_score(gt,pred)
print("sklearn accuracy:",accuracy)
recal = recall_score(gt,pred)
precision = precision_score(gt,pred)
print("sklearn recall:{},precision:{}".format(recal,precision))
print("sklearn F1-score:{}".format((2*recal*precision)/(recal+precision)))
# 输入真实的样本和对应的标签
y = [1,0,1,1,0]
pred = [0,1,1,0,0]
# 实例化
calculate_metrics(y, pred)

















 4171
4171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











