






yolox-pytorch: nets/darknet.py
仓库
https://github.com/bubbliiiing/yolox-pytorch
仓库
yolox网络结构
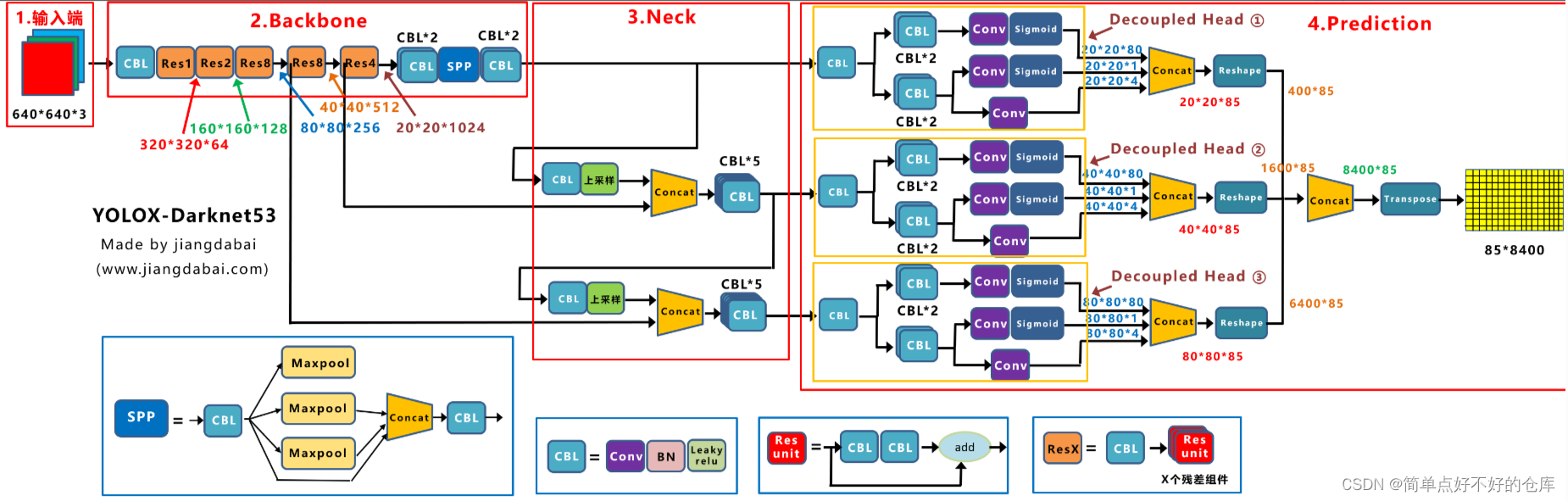
yolox-pytorch目录
今天解析注释net/darknet.py
#!/usr/bin/env python3 # 指定使用python3来执行此脚本
# -*- coding:utf-8 -*- # 声明脚本使用的编码是utf-8
# Copyright (c) Megvii, Inc. and its affiliates. # 版权信息,标注了归属公司为Megvii, Inc.及其附属公司
# 导入torch库,torch是PyTorch的主体库,提供了张量计算和神经网络构建等基础功能
import torch
# 从torch库中导入nn模块,nn是PyTorch的神经网络模块,提供了各种神经网络层和损失函数等
from torch import nn
##########################################################################################
# 定义一个名为SiLU的类,继承自nn.Module,这个类代表Sigmoid线性单元,一种非线性激活函数
class SiLU(nn.Module):
# 定义一个静态方法forward,此方法用于定义SiLU类的运算过程,参数x是输入数据
@staticmethod
def forward(x):
# 返回输入数据x乘以sigmoid函数的结果,实现SiLU运算
return x * torch.sigmoid(x)
##########################################################################################
# 定义一个函数get_activation,用于获取不同类型的激活函数模块
def get_activation(name="silu", inplace=True):
# 根据传入的name参数判断要返回的激活函数类型,默认为SiLU类型
if name == "silu":
# 如果name为"silu",则创建一个SiLU类型的模块并赋值给module变量
module = SiLU()
elif name == "relu":
# 如果name为"relu",则创建一个ReLU类型的模块,inplace参数表示原地操作,是否会修改输入数据,默认为True
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
# 如果name为"lrelu",则创建一个LeakyReLU类型的模块,0.1表示负斜率,inplace参数表示原地操作,是否会修改输入数据,默认为True
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
# 如果name不是上述任何一种类型,则抛出一个AttributeError异常,提示"Unsupported act type: {}".format(name)错误信息
raise AttributeError("Unsupported act type: {}".format(name))
# 返回获取到的激活函数模块
return module
##########################################################################################
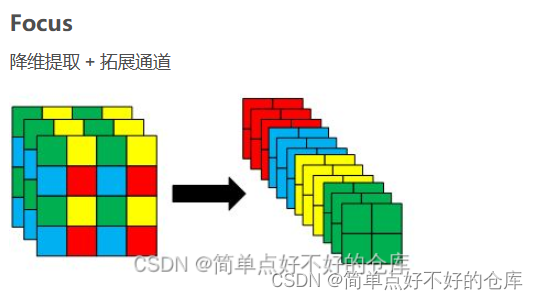
# 定义一个名为Focus的类,继承自nn.Module,这个类代表焦点模块,用于对输入数据进行空间上的重新构造
class Focus(nn.Module):
# 定义一个构造函数__init__,此方法用于初始化Focus类的实例对象
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
# 调用父类的构造函数,进行基本的初始化操作
super().__init__()
# 定义变量pad为(ksize - 1) // 2,表示卷积操作的填充大小
pad = (ksize - 1) // 2
# 创建一个BaseConv类型的模块,参数为in_channels * 4(输入通道数变为原来的四倍),out_channels(输出通道数),ksize(卷积核大小),stride(步长),pad(填充大小),act(激活函数类型默认为SiLU)
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
# 定义一个forward方法,此方法用于定义Focus类的运算过程,参数x是输入数据
def forward(self, x):
# 从输入数据x中获取四个位置的patch并进行拼接,形成一个新的数据x并返回给conv进行卷积操作
#考虑2 x 2的四个方格,左上,左下,右上和右下为起始点,各一个元素采样
patch_top_left = x[..., ::2, ::2] # 从左上角开始每隔一个像素取一个像素点形成左上角patch
patch_bot_left = x[..., 1::2, ::2] # 从左下角开始每隔一个像素取一个像素点形成左下角patch
patch_top_right = x[..., ::2, 1::2] # 从右上角开始每隔一个像素取一个像素点形成右上角patch
patch_bot_right = x[..., 1::2, 1::2] # 从右下角开始每隔一个像素取一个像素点形成右下角patch
x = torch.cat((patch_top_left, patch_bot_left, patch_top_right,patch_bot_right), dim=1) # 将四个patch在通道维度上进行拼接
# 返回经过conv卷积操作后的结果
return self.conv(x)
##########################################################################################
# 定义一个名为BaseConv的类,继承自nn.Module,这个类代表基础卷积模块,用于构建卷积神经网络的基础模块
class BaseConv(nn.Module):
# 定义一个构造函数__init__,此方法用于初始化BaseConv类的实例对象
def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):
# 调用父类的构造函数,进行基本的初始化操作
super().__init__()
# 定义变量pad为(ksize - 1) // 2,表示卷积操作的填充大小
pad = (ksize - 1) // 2
# 创建一个Conv2d类型的卷积层,参数依次为输入通道数,输出通道数,卷积核大小,步长,填充大小,分组数,是否使用偏置
self.conv = nn.Conv2d(in_channels, out_channels, ksize, stride, pad, groups=groups, bias=bias)
# 定义一个批归一化层,用于加速训练和提高模型稳定性。
self.bn = nn.BatchNorm2d(out_channels, eps=0.001, momentum=0.03)
# 如果传入的act参数不为空字符串,则根据act参数创建一个激活函数模块并赋值给self.act变量
if act is not None:
self.act = get_activation(act, inplace=True)
else:
self.act = nn.Identity() # 如果act参数为空字符串,则使用恒等映射作为激活函数
# 定义一个forward方法,此方法用于定义BaseConv类的运算过程,参数x是输入数据
def forward(self, x):
# 返回经过conv卷积操作和act激活函数处理后的结果
return self.act(self.conv(x))
#########################################################################################
# 定义一个名为DWConv的类,继承自nn.Module,这是一个深度可分离卷积模块。
class DWConv(nn.Module):
# 初始化函数,用于设置该模块所需的各种参数和子模块。
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
# 调用父类的初始化函数。
super().__init__()
# 定义一个深度卷积层(逐通道卷积),其输出通道数与输入通道数相同,并且使用给定的核大小和步长。
# 注意这里的groups参数设置为in_channels,意味着每个输入通道都有独立的卷积核。
self.dconv = BaseConv(in_channels, in_channels, ksize=ksize, stride=stride, groups=in_channels, act=act,)
# 定义一个逐点卷积层(1x1卷积),用于改变通道数。这里的groups参数设置为1,表示是普通的卷积操作。
self.pconv = BaseConv(in_channels, out_channels, ksize=1, stride=1, groups=1, act=act)
# 定义前向传播函数,输入数据x会首先经过深度卷积层处理,然后再经过逐点卷积层处理。
def forward(self, x):
x = self.dconv(x) # 数据经过深度卷积层处理。
return self.pconv(x) # 经过逐点卷积层处理后输出结果。
##########################################################################################
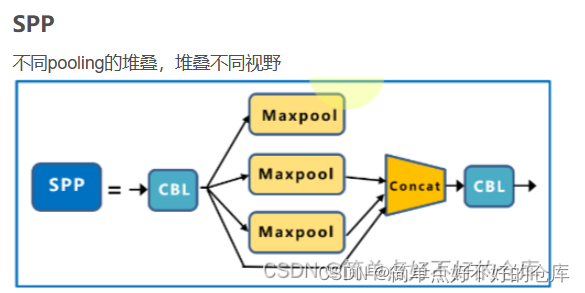
# 定义一个名为SPPBottleneck的类,继承自nn.Module,这是一个包含空间金字塔池化(Spatial Pyramid Pooling, SPP)的瓶颈模块。
class SPPBottleneck(nn.Module):
# 初始化函数,用于设置该模块所需的各种参数和子模块。
def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):
# 调用父类的初始化函数。
super().__init__()
# 计算隐藏层的通道数,为输入通道数的一半。
hidden_channels = in_channels // 2
# 定义第一个卷积层,用于降低通道数。这里使用1x1的卷积核。
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
# 定义一个包含多个最大池化层的模块列表,用于生成不同尺度的空间金字塔特征。
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2) for ks in kernel_sizes])
# 计算第二个卷积层的输入通道数,为隐藏层通道数与空间金字塔层数的和。
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
# 定义第二个卷积层,用于增加通道数并整合空间金字塔特征。这里使用1x1的卷积核。
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
# 定义前向传播函数,输入数据x会首先经过第一个卷积层处理,然后生成空间金字塔特征并拼接在一起,最后经过第二个卷积层处理并输出结果。
def forward(self, x):
x = self.conv1(x) # 数据经过第一个卷积层处理。
x = torch.cat([x] + [m(x) for m in self.m], dim=1) # 生成空间金字塔特征并将它们拼接在一起。
x = self.conv2(x) # 经过第二个卷积层处理后输出结果。
return x
##########################################################################################
class Bottleneck(nn.Module): # 定义一个名为Bottleneck的类,它继承了nn.Module
# Standard bottleneck
def __init__(self, in_channels, out_channels, shortcut=True, expansion=0.5, depthwise=False, act="silu",): # 初始化函数
super().__init__() # 调用父类的初始化函数
# 计算隐藏层的通道数,通过输出通道数与扩展因子相乘并取整得到
hidden_channels = int(out_channels * expansion)
# 根据depthwise的值选择卷积类型,如果是True则使用深度可分离卷积(DWConv),否则使用基础卷积(BaseConv)
Conv = DWConv if depthwise else BaseConv
# 利用1x1卷积进行通道数的缩减,通常缩减率是50%
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# 利用3x3卷积进行通道数的扩展,并完成特征提取
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
# 判断是否使用残差连接,只有当shortcut为True且输入和输出通道数相等时才使用
self.use_add = shortcut and in_channels == out_channels
def forward(self, x): # 定义前向传播函数
# 首先应用第一个卷积层(通道数缩减),然后应用第二个卷积层(通道数扩展)
y = self.conv2(self.conv1(x))
# 如果满足使用残差连接的条件,则将输入x添加到y中
if self.use_add:
y = y + x
# 返回y作为模块的输出
return y
##########################################################################################
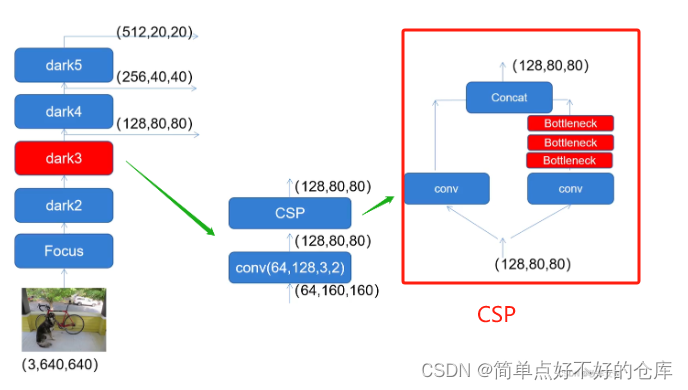
class CSPLayer(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
super().__init__()
hidden_channels = int(out_channels * expansion)
# 主干部分的初次卷积,用于通道数的缩减和特征初步提取
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# 大的残差边部分的初次卷积,与conv1有相同的通道数和作用,但其输出会与后续的Bottleneck结构进行堆叠
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# 对堆叠的结果进行卷积的处理,将2倍的隐藏通道数转换为输出通道数
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
# 根据循环的次数构建上述Bottleneck残差结构,多次重复Bottleneck结构可以增强特征提取能力
module_list = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act) for _ in range(n)]
self.m = nn.Sequential(*module_list) # 使用Sequential将多个Bottleneck结构串联起来
def forward(self, x):
#-------------------------------#
# x_1是主干部分
#-------------------------------#
x_1 = self.conv1(x)
#-------------------------------#
# x_2是大的残差边部分
#-------------------------------#
x_2 = self.conv2(x)
#-----------------------------------------------#
# 主干部分利用残差结构堆叠继续进行特征提取
#-----------------------------------------------#
x_1 = self.m(x_1)
#-----------------------------------------------#
# 主干部分和大的残差边部分进行堆叠
#-----------------------------------------------#
x = torch.cat((x_1, x_2), dim=1)
#-----------------------------------------------#
# 对堆叠的结果进行卷积的处理
#-----------------------------------------------#
return self.conv3(x)
##########################################################################################
class CSPDarknet(nn.Module):
def __init__(self, dep_mul, wid_mul, out_features=("dark3", "dark4", "dark5"), depthwise=False, act="silu",):
super().__init__()
assert out_features, "please provide output features of Darknet" # 确保提供了Darknet的输出特征
self.out_features = out_features
Conv = DWConv if depthwise else BaseConv # 根据depthwise的值选择卷积类型
# 输入图片的基本信息,初始的基本通道数是64,乘上宽度因子wid_mul得到实际的初始通道数
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 深度是3乘以深度因子dep_mul,至少为1
# 利用focus网络结构进行特征提取,将输入图片从640x640x3变换到320x320x64
self.stem = Focus(3, base_channels, ksize=3, act=act)
# dark2部分 -----------------------------------------------------
# 完成卷积之后,特征图尺寸从320x320x64变为160x160x128
# 完成CSPlayer之后,特征图尺寸保持为160x160x128不变
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2, act=act), # 卷积操作,通道数翻倍,高度和宽度减半
CSPLayer(base_channels * 2, base_channels * 2, n=base_depth, depthwise=depthwise, act=act), # CSPLayer结构
)
# dark3部分 -----------------------------------------------------
# 完成卷积之后,特征图尺寸从160x160x128变为80x80x256
# 完成CSPlayer之后,特征图尺寸保持为80x80x256不变
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act), # 卷积操作,通道数翻倍,高度和宽度减半
CSPLayer(base_channels * 4, base_channels * 4, n=base_depth * 3, depthwise=depthwise, act=act), # CSPLayer结构
)
# 完成卷积之后,80x80x256的特征图变为40x40x512
# 完成CSPlayer之后,特征图的尺寸和通道数保持不变,为40x40x512
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2, act=act), # 卷积操作,通道数翻倍,高度和宽度减半
CSPLayer(base_channels * 8, base_channels * 8, n=base_depth * 3, depthwise=depthwise, act=act), # CSPLayer结构
)
# 完成卷积之后,40x40x512的特征图变为20x20x1024
# 完成SPP(Spatial Pyramid Pooling)模块之后,特征图的尺寸和通道数保持不变,为20x20x1024
# 完成CSPlayer之后,特征图的尺寸和通道数仍然保持不变,为20x20x1024
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act), # 卷积操作,通道数翻倍,高度和宽度减半
SPPBottleneck(base_channels * 16, base_channels * 16, activation=act), # SPPBottleneck结构,增强特征的多样性
CSPLayer(base_channels * 16, base_channels * 16, n=base_depth, shortcut=False, depthwise=depthwise, act=act), # CSPLayer结构
)
def forward(self, x):
outputs = {} # 初始化一个空字典,用于存储每一层的输出
x = self.stem(x) # stem层,通常是模型的初始部分,用于处理输入数据
outputs["stem"] = x # 将stem层的输出存储到字典中
x = self.dark2(x) # dark2层,是模型的一部分,用于提取特征
outputs["dark2"] = x # 将dark2层的输出存储到字典中
# dark3的输出为80, 80, 256,是一个有效特征层
x = self.dark3(x) # dark3层,继续提取特征
outputs["dark3"] = x # 将dark3层的输出存储到字典中
# dark4的输出为40, 40, 512,是一个有效特征层
x = self.dark4(x) # dark4层,继续提取特征
outputs["dark4"] = x # 将dark4层的输出存储到字典中
# dark5的输出为20, 20, 1024,是一个有效特征层
x = self.dark5(x) # dark5层,继续提取特征
outputs["dark5"] = x # 将dark5层的输出存储到字典中
# 只返回out_features列表中指定的层的输出;
#在代码的最后一行,使用了字典推导式来过滤outputs字典中的项,
#只保留self.out_features中指定的键对应的值。
#这意味着最终返回的将是out_features列表中指定的层的输出。
#这是一种常见的做法,可以让用户灵活选择需要输出的特征层。
return {k: v for k, v in outputs.items() if k in self.out_features}
Focus
BaseConv
简而言之:卷积 + 激活【是否】
BaseConv是一个基础卷积类,它继承了PyTorch中的nn.Module类,并实现了卷积、批归一化(Batch Normalization)和激活函数等核心操作。BaseConv类的主要参数包括:
in_channels:输入通道数。out_channels:输出通道数。ksize:卷积核大小。stride:步长。groups:分组卷积中的组数,默认为1。bias:是否使用bias(偏差),默认为False。act:激活函数类型,默认为"silu"。
在BaseConv类中,主要实现了以下三个方法:
__init__:构造函数,用于初始化BaseConv对象。在构造函数中,会创建一个nn.Conv2d对象(卷积层),一个nn.BatchNorm2d对象(批归一化层)和一个激活函数对象。forward:前向传播函数。输入数据x首先经过卷积层和批归一化层,然后通过激活函数进行激活,最终输出结果。get_activation:获取激活函数。该函数用于获取指定名称的激活函数对象。
总体来说,BaseConv是一个简单但实用的卷积类,可以作为构建其他复杂卷积网络的基础组件。
DWConv
SPPBottleneck
CSPDarknet
CSP:Cross Stage Partial
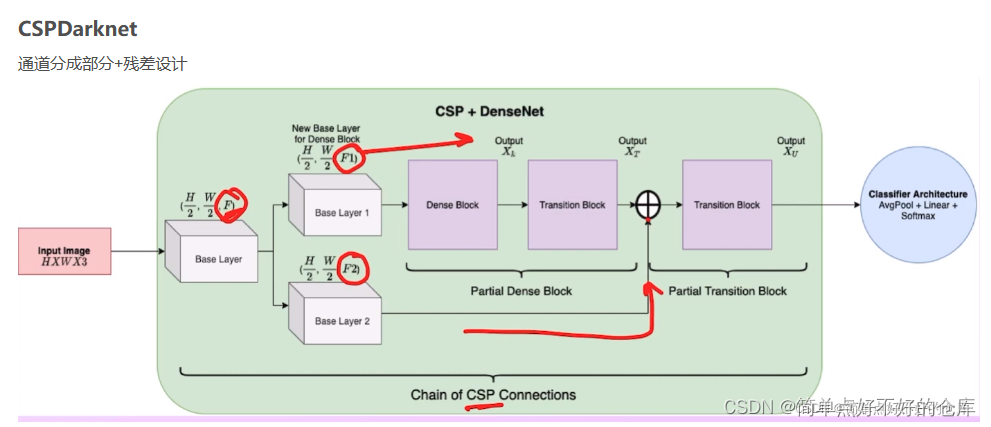
CSP darknet的架构具有以下特点:
- 它将输入通道分成两部分,一部分经过常规Res(X)Block后跟另一部分进行通道拼接,拼接后进入transition layer。CSP将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率(或有所提升)。其中transition layer是一个卷积加池化,用于整合学到的特征,降低特征图的尺寸。
- CSP模块中的每个模块都有特定的特点,例如输出feature map大小减半,通道数增倍等。
CSP darknet的这种架构可以有效地提取输入图像的特征,并为后续的网络处理提供有效的特征集合。
优势
- 增强了CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低了计算瓶颈和内存成本。
YOLOX中的实现是这样:















 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











