







 本文介绍了优化算法在深度学习中的重要性,从随机梯度下降法(SGD)开始,逐步讲解了动量法、Adagrad、RMSProp和Adadelta,并对比了它们的效果。最后,文章详细阐述了Adam优化算法,它是结合了动量法和RMSProp的优化算法,具有较好的收敛性能。通过实例展示了如何在PyTorch中使用这些优化器,并探讨了学习率、动量参数等对训练过程的影响。
本文介绍了优化算法在深度学习中的重要性,从随机梯度下降法(SGD)开始,逐步讲解了动量法、Adagrad、RMSProp和Adadelta,并对比了它们的效果。最后,文章详细阐述了Adam优化算法,它是结合了动量法和RMSProp的优化算法,具有较好的收敛性能。通过实例展示了如何在PyTorch中使用这些优化器,并探讨了学习率、动量参数等对训练过程的影响。
优化算法
0.梯度和优化
先来看看优化算法的用处
from math import pi
import torch
import torch.optim
# 求梯度
x = torch.tensor([pi / 3, pi / 6], requires_grad=True)
f = - ((x.cos() ** 2).sum()) ** 2
print('函数值 = {}'.format(f))
f.backward()
print('梯度值 = {}'.format(x.grad))
ref = 2 * (torch.cos(x) ** 2).sum() * torch.sin(2 * x)
print('梯度值(参考) = {}'.format(ref))
# 优化问题求解
x = torch.tensor([pi / 3, pi / 6], requires_grad=True)
optimizer = torch.optim.SGD([x,], lr=0.1, momentum=0)
for step in range(11):
if step:
optimizer.zero_grad()
f.backward()
optimizer.step()
f = - ((x.cos() ** 2).sum()) ** 2
print ('step {}: x = {}, f(x) = {}'.format(step, x.tolist(), f))
更多例子
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
import torch.utils.data as Data
torch.manual_seed(1) # 确定随机种子,保证结果可重复
LR = 0.01
BATCH_SIZE = 20
EPOCH = 10
# 生成数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1500), dim=1)
y = x.pow(3) + 0.1 * torch.normal(torch.zeros(x.size()))
#%% 绘制数据分布
plt.scatter(x.numpy(), y.numpy())
plt.show()
#%% 把数据转换为torch类型
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2, )
#%% 定义模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # 隐藏层
self.predict = torch.nn.Linear(20, 1) # 输出层
def forward(self, x):
# pdb.set_trace()
x = F.relu(self.hidden(x)) # 隐藏层的激活函数
x = self.predict(x) # 线性输出
return x
#%% 不同的网络模型
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_AdaGrad = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_AdaGrad, net_RMSprop, net_Adam]
#%% 不同的优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_AdaGrad = torch.optim.Adagrad(net_AdaGrad.parameters(), lr=LR)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_AdaGrad, opt_RMSprop, opt_Adam]
#
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], [], []] # 记录loss用
#模型训练
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = batch_x
b_y = batch_y
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # 前向算法的结果
loss = loss_func(output, b_y) # 计算loss
opt.zero_grad() # 梯度清零
loss.backward() # 后向算法,计算梯度
opt.step() # 应用梯度
l_his.append(loss.item()) # 记录loss
#%%
labels = ['SGD', 'Momentum', 'AdaGrad', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
1.随机梯度下降法 SGD
随机梯度下降法
我们分别从 0 自己实现,以及使用 pytorch 中自带的优化器
import numpy as np
import torch
from torchvision.datasets import MNIST 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
import time
import matplotlib.pyplot as plt
def data_tf(x):
x = np.array(x, dtype='float32') / 255 将数据变到 0 ~ 1 之间
x = (x - 0.5) / 0.5 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) 拉平
x = torch.from_numpy(x)
return x
train_set = MNIST(r'C:/DATASETS', train=True, transform=data_tf, download=True) 载入数据集,申明定义的数据变换
test_set = MNIST(r'C:/DATASETS', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
随机梯度下降法非常简单,公式就是
θ i + 1 = θ i − η ∇ L ( θ ) \theta_{i+1} = \theta_i - \eta \nabla L(\theta) θi+1=θi−η∇L(θ)
非常简单,我们可以从 0 开始自己实现
def sgd_update(parameters, lr):
for param in parameters:
param.data = param.data - lr * param.grad.data
我们可以将 batch size 先设置为 1,看看有什么效果
train_data = DataLoader(train_set, batch_size=1, shuffle=True)
使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
开始训练
losses1 = []
idx = 0
start = time.time() 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
前向传播
out = net(im)
loss = criterion(out, label)
反向传播
print(net.grad)
net.zero_grad()
loss.backward()
sgd_update(net.parameters(), 1e-2) 使用 0.01 的学习率
记录误差
train_loss += loss.item()
if idx % 30 == 0:
losses1.append(loss.item())
idx += 1
print('epoch: {}, Train Loss: {:.6f}'.format(e, train_loss / len(train_data)))
end = time.time() 计时结束
print('使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses1), endpoint=True)
plt.semilogy(x_axis, losses1, label='batch_size=1')
plt.legend(loc='best')
batch_size=1,lr=0.5
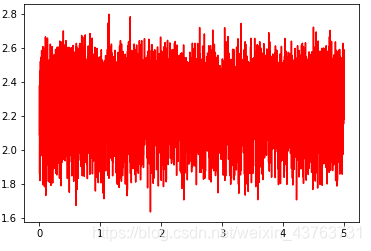
可以看到,loss 在剧烈震荡,因为每次都是只对一个样本点做计算,每一层的梯度都具有很高的随机性,而且需要耗费了大量的时间
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
开始训练
losses2 = []
idx = 0
start = time.time() 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
前向传播
out = net(im)
loss = criterion(out, label)
反向传播
net.zero_grad()
loss.backward()
sgd_update(net.parameters(), 1e-2)
记录误差
train_loss += loss.item()
if idx % 30 == 0:
losses2.append(loss.item())
idx += 1
print('epoch: {}, Train Loss: {:.6f}'.format(e, train_loss / len(train_data)))
end = time.time() 计时结束
print('使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses2), endpoint=True)
plt.semilogy(x_axis, losses2, label='batch_size=64')
plt.legend(loc='best')
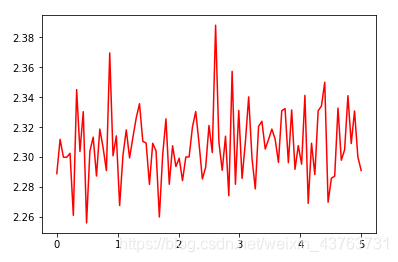
batch_size=64,lr=0.5
batch_size=500,lr=0.5
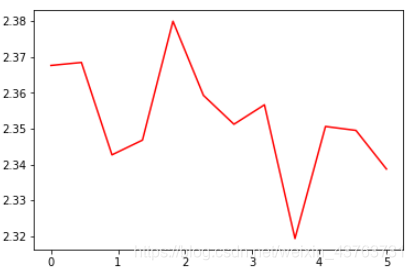
通过上面的结果可以看到 loss 没有 batch 等于 1 震荡那么距离,同时也可以降到一定的程度了,时间上也比之前快了非常多,因为按照 batch 的数据量计算上更快,同时梯度对比于 batch size = 1 的情况也跟接近真实的梯度,所以 batch size 的值越大,梯度也就越稳定,而 batch size 越小,梯度具有越高的随机性,这里 batch size 为 64,可以看到 loss 仍然存在震荡,但这并没有关系,如果 batch size 太大,对于内存的需求就更高,同时也不利于网络跳出局部极小点,所以现在普遍使用基于 batch 的随机梯度下降法,而 batch 的多少基于实际情况进行考虑
下面我们调高学习率,看看有什么样的结果
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
开始训练
losses3 = []
idx = 0
start = time.time() 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
前向传播
out = net(im)
loss = criterion(out, label)
反向传播
net.zero_grad()
loss.backward()
sgd_update(net.parameters(), 1) 使用 1.0 的学习率
记录误差
train_loss += loss.item()
if idx % 30 == 0:
losses3.append(loss.item())
idx += 1
print('epoch: {}, Train Loss: {:.6f}'.format(e, train_loss / len(train_data)))
end = time.time() 计时结束
print('使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses3), endpoint=True)
plt.semilogy(x_axis, losses3, label='lr = 1')
plt.legend(loc='best')
batch_size=64,lr=1
可以看到,学习率太大会使得损失函数不断回跳,从而无法让损失函数较好降低,所以我们一般都是用一个比较小的学习率
batch_size=64,lr=1
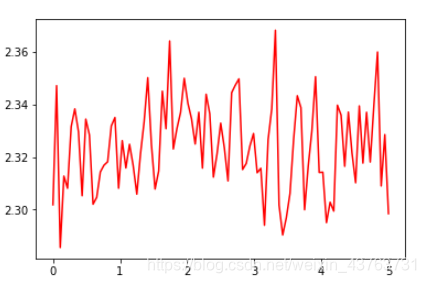
实际上我们并不用自己造轮子,因为 pytorch 中已经为我们内置了随机梯度下降发,而且之前我们一直在使用,下面我们来使用 pytorch 自带的优化器来实现随机梯度下降
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimzier = torch.optim.SGD(net.parameters(), 1e-2)
开始训练
start = time.time() 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
前向传播
out = net(im)
loss = criterion(out, label)
反向传播
optimzier.zero_grad()
loss.backward()
optimzier.step()
记录误差
train_loss += loss.item()
print('epoch: {}, Train Loss: {:.6f}'.format(e, train_loss / len(train_data)))
end = time.time() 计时结束
print('使用时间: {:.5f} s'.format(end - start))
2.动量法
使用梯度下降法,每次都会朝着目标函数下降最快的方向,这也称为最速下降法。这种更新方法看似非常快,实际上存在一些问题。
梯度下降法的问题
考虑一个二维输入, [ x 1 , x 2 ] [x_1, x_2] [x1,x2],输出的损失函数 L : R 2 → R L: R^2 \rightarrow R L:R2→R,下面是这个函数的等高线

可以想象成一个很扁的漏斗,这样在竖直方向上,梯度就非常大,在水平方向上,梯度就相对较小,所以我们在设置学习率的时候就不能设置太大,为了防止竖直方向上参数更新太过了,这样一个较小的学习率又导致了水平方向上参数在更新的时候太过于缓慢,所以就导致最终收敛起来非常慢。
动量法
动量法的提出就是为了应对这个问题,我们梯度下降法做一个修改如下
v i = γ v i − 1 + η ∇ L ( θ ) v_i = \gamma v_{i-1} + \eta \nabla L(\theta) vi=γvi−1+η∇L(θ)
θ i = θ i − 1 − v i \theta_i = \theta_{i-1} - v_i θi=θi−1−vi
其中 v i v_i vi 是当前速度, γ \gamma γ 是动量参数,是一个小于 1的正数, η \eta η 是学习率
相当于每次在进行参数更新的时候,都会将之前的速度考虑进来,每个参数在各方向上的移动幅度不仅取决于当前的梯度,还取决于过去各个梯度在各个方向上是否一致,如果一个梯度一直沿着当前方向进行更新,那么每次更新的幅度就越来越大,如果一个梯度在一个方向上不断变化,那么其更新幅度就会被衰减,这样我们就可以使用一个较大的学习率,使得收敛更快,同时梯度比较大的方向就会因为动量的关系每次更新的幅度减少,如下图

比如我们的梯度每次都等于 g,而且方向都相同,那么动量法在该方向上使参数加速移动,有下面的公式:
v 0 = 0 v_0 = 0 v0=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









