







转载
最近使用SPARTAN3 时需要对数据进行取余操作,直接使用%取余之后仿真可以通过,但资源占用比较大最终bit生成失败,所以在原文https://www.sunev.cn/embedded/726.html寻求到更节约资源的做法,mark一下。
FPGA快速除法及取余
除法及取余运算,使用了 lpm_divide 功能(也就是直接用/和%运算符),效率确实很高,不过特别占用资源,如下图 所示。
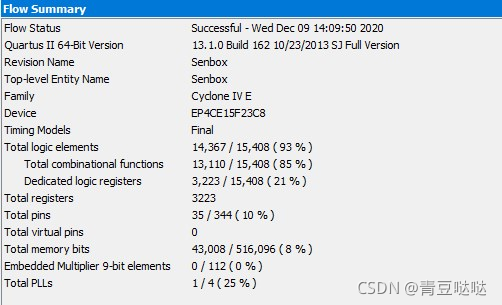
FPGA的快速除法及取余运算(Verilog)
使用 lpm_divide 后的资源几乎被用完,为了减少资源占用,找了一种快速的除法及取余运算。
1、基于减法的除法器的算法
相较于乘法器的左移相加,除法器就是移位相减。
例如,十进制数 99 除以十进制数 5——99/5,即二级制数 1100011 除以二级制数 101:
1100011 – 1010000 = 10011(其中二进制 1010000 = 5 乘 2 的 4 次幂);
10011 – 1010 = 1001 ( 其中二进制 1010 = 5 乘 2 的 1 次幂);
1001 – 101 = 100( 其中二进制 101 = 5 乘 2 的 0 次幂);
得到商为 24+21+2^0 = 16+2+1=19(^代表次幂),余数为二进制 100 = 4。
1.1 硬件实现原理
对于 32 位的无符号除法,被除数 a 除以除数 b,他们的商和余数一定不会超过 32 位。首先将 a 转换成高 32 位为 0,低 32 位为 a 的 temp_a。把 b 转换成高 32 位为 b,低 32 位为 0 的 temp_b。在每个周期开始时,先将 temp_a 左移一位,末尾补 0,然后与 b 比较,是否大于 b,是则 temp_a 减去 temp_b 将且加上 1,否则继续往下执行。上面的移位、比较和减法(视具体情况而定)要执行 32 次,执行结束后 temp_a 的高 32 位即为余数,低 32 位即为商。
1.2 verilog HDL 代码
除法及取余算法代码:
/*
* module:div_rill
* file name:div_rill.v
* syn:yes
* author:network
* modify:sunev
* date:2020-11-28
*/
module div_rill
(
input[31:0] a,
input[31:0] b,
output reg [31:0] yshang,
output reg [31:0] yyushu
);
reg[31:0] tempa;
reg[31:0] tempb;
reg[63:0] temp_a;
reg[63:0] temp_b;
integer i;
always @(a or b)
begin
tempa <= a;
tempb <= b;
end
always @(tempa or tempb)
begin
temp_a = {32'h00000000,tempa};
temp_b = {tempb,32'h00000000};
for(i = 0;i < 32;i = i + 1)
begin
temp_a = {temp_a[62:0],1'b0};
if(temp_a[63:32] >= tempb)
temp_a = temp_a - temp_b + 1'b1;
else
temp_a = temp_a;
end
yshang <= temp_a[31:0];
yyushu <= temp_a[63:32];
end
endmodule
2、 算法推倒
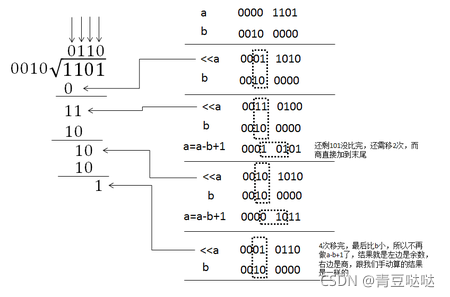
假设 4bit 的两数相除 a/b,商和余数最多只有 4 位 (假设 1101/0010 也就是 13 除以 2 得 6 余 1)。
我们先自己做二进制除法,则首先看 a 的 MSB,若比除数小则看前两位,大则减除数,然后看余数,以此类推直到最后看到 LSB;而上述算法道理一样,a 左移进前四位目的就在于从 a 本身的 MSB 开始看起,移 4 次则是看到 LSB 为止,期间若比除数大,则减去除数,注意减完以后正是此时所剩的余数。而商呢则加到了这个数的末尾,因为只要比除数大,商就是 1,而商 0 则是直接左移了,因为会自动补 0。这里比较巧因为商可以随此时的 a 继续左移,然后新的商会继续加到末尾。经过比对会发现移 4 位后左右两边分别就是余数和商。
画个简单的图:

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









