







Cylinder3D:一个有效的三维框架用于驾驶场景激光雷达语义分割
论文 Cylinder3D: An Effective 3D Framework for
Driving-scene LiDAR Semantic Segmentation CVPR2021
摘要:激光雷达的大规模行车场景语义分割方法经常对二维空间中的点云进行投影和处理。投影方法包括球面投影、鸟瞰图投影等。虽然这个过程使得点云适用于基于cnn的二维网络,但它不可避免地改变和放弃了三维拓扑和几何关系。一种解决3D到2d投影问题的直接方法是保持3D表示并处理3D空间中的点。在这项工作中,我们首先对二维和三维空间中的不同表示和骨干进行了深入的分析,并揭示了三维表示和网络在激光雷达分割中的有效性。然后,我们开发了一个三维柱体分区和一个基于三维柱体卷积的框架,称为Cylinder3D,该框架利用了驾驶场景点云的三维拓扑关系和结构。此外,还引入了基于维度分解的上下文建模模块,以循序渐进的方式探索点云中的高阶上下文信息。我们在一个大规模的驾驶场景数据集(即SematicKITTI)上评估所提出的模型。我们的方法达到了最先进的性能,在mIoU方面比现有方法高出6%。
1 Introduction
三维激光雷达传感器已经成为现代自动驾驶汽车中不可缺少的设备。与传统的视觉相机相比,它能捕捉到更精确、更远的周围环境测量距离。传感器的测量自然形成了三维点云,可以用来理解自动驾驶规划和执行的整体场景。
三维点云的语义分割是理解驾驶场景的关键。其目的是识别每个3D点的预定义类别,如汽车、卡车、行人等,提供整个3D场景的点式感知信息。
现有的基于点云的分割算法大多集中在室内场景,而室内场景的点云一般比较密集,且密度基本均匀。相比之下,在户外或自动驾驶场景中,激光雷达点云的分割方法很少,激光雷达点云的密度随着距离传感器的不同而变化,这对算法提出了很大的挑战。
目前的方法主要关注点特征表示[1,2,3]。LiDAR点云的点特征表示主要有三大类:距离图像[4,1]、鸟瞰图像[2]和体素分割[3,5]。将不规则分布的三维点云球面投影到二维密集网格上得到距离图像。鸟瞰图像压缩点高度信息,并共享鸟瞰地图上每个位置的全局高度特征。
但是,这些方法在进行3d - 2d投影时,可能会丢失某些准确的几何信息。
本文对激光雷达在自动驾驶场景中的分割重点进行了重新定位。本文进行实验,以显示不同的点特征表示和神经网络架构的有效性。实验表明,使用三维卷积神经网络进行三维分区的效果优于其他方法。针对驾驶场景点云密度的变化,提出了一种圆柱体分割的方法来处理驾驶场景点云,以平衡驾驶场景点云的分布。为了匹配驾驶场景激光雷达数据中的长方体物体,我们提出了非对称残差块作为基本模块来形成三维主干。除了网络搜索外,我们还提出了一种新的维分解块,通过一系列低秩卷积核有效地利用上下文信息。
本工作的贡献可以概括为三个方面。(1)我们研究了最先进的网络架构和不同的点特征表示,揭示了直接处理点云而不需要3d到2d投影是获得卓越分割性能的关键。(2)提出了一种柱面分割点云编码方案,该方案更好地遵循了三维驾驶场景点云的固有分布规律,并开发了一种基于三维卷积的框架。其中,设计了非对称残差块作为基本模块,并提出了一种新的维分解块,以循序渐进的方式探索上下文。(3)我们提出的LiDAR分割算法在驾驶场景语义分割基准上的性能优于目前最先进的分割算法,有6% mIoU的增益。
2 相关工作
室内场景点云分割。
室内场景点云具有密度均匀、场景范围小等特点。因此,大多数室内场景分割方法[6,7,8,9,10,11,12,13]往往直接从原始点学习点特征。PointNet[6]是一个经典的基于点集的卷积神经网络,提出了一种多层感知从输入点提取特征的方法。此外,PointNet++[14]进一步提出了多尺度采样来聚合全局和局部特征。另一组室内场景分割[9,10]利用聚类(包括KNN)提取点特征。但是,这些方法的计算量大,且没有考虑到不同的稀疏性(户外场景激光雷达的特性)。
户外场景点云分割。
现有的户外场景点云分割主要集中在将三维点云转化为二维网格,从而实现二维卷积神经网络的使用。SqueezeSeg[1]、Darknet[15]、SqueezeSegv2[16]、RangeNet++[4]利用球面投影机制,将点云转换为正面(距离)图像,并在伪图像上采用二维卷积网络进行分割。PolarNet[2]遵循鸟瞰图投影,将点云数据从鸟瞰图投影到小网格中,并将高度作为一个整体。它们使用极坐标系统来编码点云,而不是在笛卡尔坐标系中划分点。然而,这种3D- 2d投影不可避免地压缩了三维拓扑,无法对几何信息进行建模。
3D体素分割
3D体素分割是点云编码的另一种方法[17,18,19,20,3]。
它将点云转换成3D体素。3D U-Net[5]提出了生物医学数据的体素分割和3D U-Net,并成功地应用于复杂的微观数据集。OccuSeg [18], SSCN[3]和SEGCloud[20]遵循这条线利用体素分区,并应用3D卷积进行LiDAR分割。我们的工作也遵循这一常规,利用3D网格和3D卷积网络,但有实质性的差异。我们采用了基于柱体坐标系的三维柱体分区,满足了驾驶场景激光雷达点云的稀疏性变化和点分布的平衡。具体来说,远端区域比近端区域稀疏得多,因此柱面划分利用较大的柱面来覆盖远端区域。
用于分割的网络架构。
全卷积网络[21]是深度学习时代的基础性工作。U-Net[22]建立在FCN的基础上,提出了一种利用底层特征的对称体系结构。此外,许多研究对多尺度上下文建模的扩张卷积进行了探索,包括DeepLab[23,24]和PSP[25]。由于U-Net在2D基准上的巨大成功,许多关于LiDAR分割的研究使U-Net适应3D空间,提出了3D U-Net[5]。然而,它们往往未能对驾驶场景激光雷达点云的分布和性质进行研究。本文设计了基于非对称残差块和基于维度分解的上下文建模两个模块,分别对长方体对象进行匹配,对高阶上下文信息进行建模。
Methodology 方法
3.1三维点云的学习
三维点表示研究室外场景点云与室内场景点云有显著差异。(1)一个驾驶场景点云可能覆盖非常大的区域,可达100多米。(2)它通常包含较多的点(>10万个点),但比室内场景稀疏很多。
因此,针对稠密点和固定数量点的室内分割方法难以适应点密度变化巨大的驾驶场景。
现有的户外激光雷达分割方法主要是通过投影将三维点云转化为二维表示,包括球面投影和鸟瞰投影,然后采用二维卷积处理二维网格表示。然而,如图1(右)所示,二维网格表示中的局部空间格局并不能很好地捕捉三维几何结构。可以看出,二维网格中的红色矩形代表了分布在不同空间位置的点。因此,这些3D-to- 2d投影方法可能无法对某些3D几何结构进行编码,导致模式提取不准确。详细的调查结果见4.2节。我们对2D、2.5D和3D之间的各种分区和网络进行了广泛的实验。从结果来看,一致的性能增益表明了我们的技术路线图,即三维分区和三维网络的有效性。
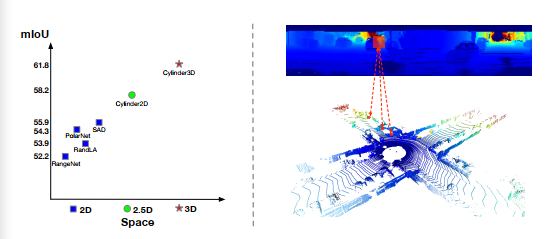
图1:(左)在SemanticKITTI上进行网络架构搜索的详细路线图,从2D、2.5D到3D(注意,2.5D意味着3D网格表示和2D主干)。(右)球面投影的局限性,即放弃了某些有价值的三维结构,投影的邻近区域反映了三维空间中明显不同的位置,这说明球面投影不能保持三维几何结构。
具体框架
室外点云覆盖了大量不同的城市场景。我们的任务是为点云中的每个点分配一个语义标签。基于我们对二维和三维点云表示分布的研究,我们发现通过投影获得的二维表示会放弃许多可用的三维结构。为此,我们提出了一种新的基于三维表示和神经网络的户外激光雷达分割方法。
如图2所示,该框架由两个组件组成,分别是三维柱面分区(获取三维表示)和三维U-Net(处理三维表示)。特别地,我们设计了两个模块来适应户外点云的特性,即
Asymmetrical Residual Block非对称残块来匹配这些经常出现在驾驶场景中的长方体物体(汽车、卡车、摩托车等),
dimension-decomposition based context modeling module基于维度分解的上下文建模模块,以分解聚合的方式对点云中的高阶上下文信息进行挖掘。
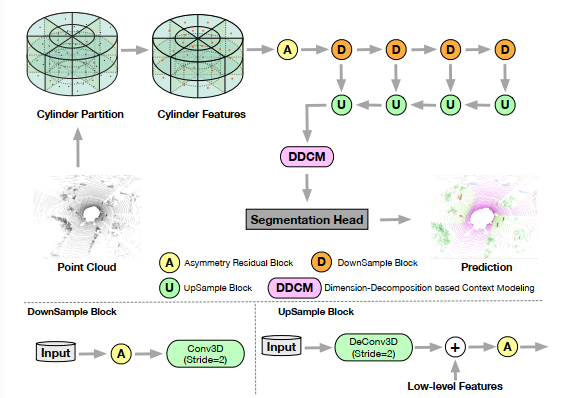
图2:总体架构。顶部部分是提出的3D LiDAR分割网络的完整工作流程,即Cylinder3D。底部部分是下样块和上样块的细节。
在下面的部分中,我们将详细介绍这些组件。
3.3 Cylinder Partition
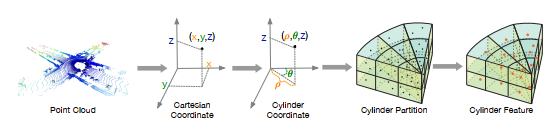
如上所述,室外场景LiDAR点云具有区域密度变化巨大的特性,附近区域的密度远大于远区。因此,我们使用圆柱坐标系来代替笛卡尔网格划分。利用逐渐增大的网格覆盖较远的区域,使点在不同区域的分布更加均匀,与室外点的分布相匹配。此外,与这些基于投影的方法将点投影到2D视图不同,我们保持了3D网格表示以保留几何结构。工作流程如图3所示。我们首先将直角坐标系上的点变换到柱面坐标系,在柱面坐标系下计算半径ρ和方位角θ。这一步变换点(x;y;Z)到点(ρ;θ;然后柱面分割是为了均匀地分割这三个维度,注意这种分割表示区域越远,体素越大。将这些柱面网格表示输入基于mlp的pointnet以获得柱面特征。经过这些步骤,我们可以得到三维柱面表示r∈ C × H × W × L,其中C表示特征维数。
注: 这里理解下C 通道 H,W,L 表示某一块
3.4非对称残差
在自动驾驶场景中,存在大量的长方体物体,包括汽车、卡车、公共汽车和摩托车。受文本检测方法[26]的启发,采用不对称卷积核对矩形目标区域进行匹配,我们设计了不对称残差块来满足这类长方体对象的特性。此外,这种非对称残差块也显著降低了传统三维卷积核的计算成本。具体地说,使用内核= 3×1×3之后内核= 1×3×3的卷积相当于滑动两层网络与相同的接受域三维与内核= 3×3×3卷积,但它相比于比一个3×3×3卷积与相同数量的输出过滤器减少了33%计算成本。提出的非对称残块是下样块和上样块的基本组成部分。下样块由一个不对称的残差块和一个stride=2的3D卷积组成下样。上块融合了低阶特征,并用非对称残块对融合特征进行处理。
3.5基于维度分解的上下文建模
由于上下文的差异较大(对于三维空间,其上下文在点云与点云之间存在巨大的差异,),因此上下文张量应该是 high-rank高阶的[27,28],才有足够的容量对上下文信息进行编码。为这个上下文特征建模需要巨大的成本,特别是在3D空间中,因为上下文的高阶属性。受high-rank matrix decomposition theory高阶矩阵分解理论的启发,我们可以将高阶上下文分解为几个低阶表示。在我们的任务中,这个高阶上下文可以被划分为三个维度,即高度、宽度和深度,其中所有三个片段都是低阶的。然后,我们使用这些片段构建完整的高级上下文。通过这种方式,该分解-聚合策略处理了基于低秩约束的不同视角的高秩困难。如图2(下)所示,三个秩为1的核(即3 × 1 × 1,1 × 3 × 1和1 × 1 × 3)在所有三个维度上生成这些低秩编码。然后Sigmoid函数对卷积结果进行调制,生成每个维度的权值,其中基于不同视图的秩1张量挖掘共现上下文信息。我们聚合所有三个低秩激活,以获得表示完整上下文特征的总和。
卷积网络部分理解 关于提取特征https://www.cnblogs.com/noticeable/p/9194795.html
3.6 Network Optimization
在这一节中,我们详细介绍了三个部分:3D cylinder partition, 3D segmentation backbone and segmentation head三维柱体分区、三维分割主干和分割头部,如图2所示。柱面划分利用具有BatchNorm和ReLU的4层MLP网络提取每个点的点特征,并选择点特征的最大幅值作为体素表示。我们的3D分割主干来源于UNet,其中3D卷积是[29]改编的稀疏卷积。如上所述,我们用非对称残块代替传统残块,并在最终预测前插入DDCM模块。分割主干的输入为C × H × W × L张量。第三部分是分割头,我们采用一个3 × 3 × 3核的3d卷积层作为轻量级的分割头。经过整个 pipeline,得到基于体素的预测,其大小为Class × H × W × L。
对于网络优化,我们使用加权交叉熵损失和lovasz-softmax[30]损失,以最大限度地提高类的点精度和交叉-联合得分。两种损失的重量相同。因此,总损失是:ζall = ζiou + ζacc。在优化器中,使用了初始学习率为0.001的Adam。
4 Experiments
4.1 Dataset and Metric
SemanticKITTI[15]是用于点云语义分割的大型户外场景数据集。它来源于KITTI视觉里程计基准,由德国的VelodyneHDLE64激光雷达采集。该数据集由22个序列组成,将序列00 ~ 10分割为训练集,11 ~ 21分割为测试集。总的来说,该数据集提供了23201个点云用于训练,20351个点云用于测试。在前面的文献中,序列08被用作验证集。该数据集共有28个类,其中6个类具有移动或非移动属性。合并不同运动状态的班,忽略分数很少的类后,保留19个类进行训练和评估。为了评估所提出的方法,我们在所有类上利用[15]中定义的平均交叉并集(mIoU)度量,mIoU是IoUi在所有类中的平均值。
4.2 Backbone and Representation Odyssey from 2D to 3D
对于户外场景中的LiDAR分割,以前有很多文献,其中在2D和3D空间之间提出了各种分区和主干。 我们选择两个已发布的前沿网络和一些具有不同分区partitions和主干backbones(在 2D 和 3D 空间中)的变体作为参考组,并进行广泛的实验来展示我们网络设计的奥德赛。
Spherical Projection,RangeNet++ [4] 是一种典型的球面投影方法,将点云投影到传感器周围的球面上。 与其他类似的方法,如 Darknet [15] 和 SqueezeSeg [1] 相比,它在 SemanticKitti 测试集上取得了最佳性能。 因此,我们选择 RangeNet53 作为球面投影baseline,并将原始 rangenet53 替换为 deeplab-resnet101。 为了更公平的比较,我们还采用 KNN 作为后处理方法来减少球面投影的空间边界效应。
Polar Bird View Projection,PolarNet [2] 不是在笛卡尔坐标中定义的传统鸟瞰方法。 它在半径-θ平面上引入极坐标来有效地表示这些点。 Radius-theta 编码由于其输入尺寸小,可以降低学习复杂度。 我们遵循 PolarNet 中的极坐标图像设置,并使用不同的网络架构展示结果。
Cuboid 3D Voxelization 是 LiDAR 分割中常用的点表示。 它将点云转换为笛卡尔坐标中的 3D 体素。 由于大的长方体体素分辨率和 3D 卷积主干,这些方法通常具有巨大的计算成本。
本文提出了圆柱体 3D 体素化。 它将点云划分为圆柱坐标系中的小网格。 正如我们在第 3 节中所声称的,圆柱体素分区满足驾驶场景 LiDAR 点云的变化稀疏性并平衡点分布。
分析。如表1所示,我们进行了大量的实验,在2D和3D空间中评估不同backbones的投影方法。可以看出,对于二维投影,极坐标投影优于具有不同backbones的球面投影方法,如Resnet-50-FCN、DRN-DeepLab和Resnet101-DeepLab,体现了极坐标投影的优越性。值得注意的是,我们的2D和3D主干共享如图2所示的相同架构。2D和3D主干网的主要区别是卷积层,我们在2D主干网中使用2D卷积。基于相同的极投影,我们的2D主干比极网的性能好2.8% mIoU,这表明所提出的模型即使在2D空间也具有可扩展性。当我们用圆柱体3Dvoxelization替换极坐标投影时,我们的模型由于保留了三维拓扑结构而获得了1.7%的增益,这表明了三维圆柱体分区的有效性。在将2D主干转换为3D主干后,所提出的Cylinder3D获得了4.2%的增益,并在val集上获得了64.3%的mIoU。可以看出,基于三维卷积的框架相对于二维主干结构有明显的提升性能,这说明三维柱体划分与三维卷积的配合导致了点云分割,验证了我们的猜想三维结构是激光雷达分割的一个关键方面。















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









