








1. Motivation
In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary.
2. Contribution
- We propose the MLP-Mixer architecture (or “Mixer” for short), a competitive but conceptually and technically simple alternative, that does not use convolutions or self-attention.
- Mixer’s architecture is based entirely on multi-layer perceptrons (MLPs) that are repeatedly applied across either spatial locations or feature channels.
- Mixer relies only on basic matrix multiplication routines, changes to data layout (reshapes and transpositions), and scalar non-linearities.
3. Mixer Architecture
如图1所示,为MLP-Mixer的宏观结构,大体上来说,MLP-Mixer由per-patch linear embedding, Mixer layers 以及classifier head组成。对于Mixer layer来说,它由token-mixing MLP以及channel-mixing MLP组成,每一个MLP由2个FC层以及一个GELU非线性激活层组成。其余的成分包括skip-connection,dropout,layer norm,linear classifier head。
现在混合特征的方式有2种:
① at a given spatial location, 在特定空间位置
② between different spatial locations 在不同的空间位置
在CNN中,NxN卷积核和池化操作可以完成②,1x1卷积核可以完成①,更大的kernels①和②都可以perform;在VIT中,self-attention可以完成①,MLP-blocks可以完成②。
这些idea都分离了per-location(channel-mixing)以及cross-location(token-mixing)操作。
MLP-Mixer Layer的输入是a sequence of linearly projected image patches(文中也称为tokens),输入的维度为pathches x channel。
chennel-mixing MLPs以及token-mixing的作用如下:
The channel-mixing MLPs allow communication between different channels; they operate on each token independently and take individual rows of the table as inputs.
The token-mixing MLPs allow communication between different spatial locations (tokens); they operate on each channel independently and take individual columns of the table as inputs. These
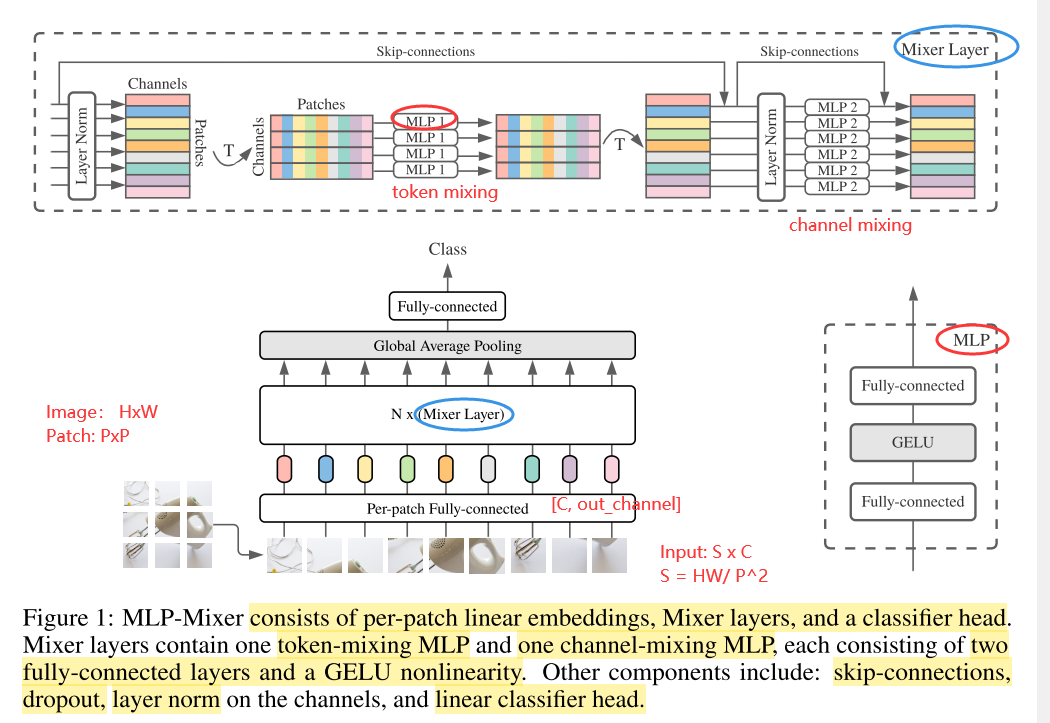
具体来说,Mixer采取的输入为S个image patches,每一个patch的维度为C,也就是二维的real-value input table, X ∈ R ( S × C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









