







行人重识别-ReID
行人重识别(Person re-identification, ReID),指利用计算机视觉技术对图像集或者视频序列中是否存在某特定目标进行判断。随着卷积神经网络(CNN)方法的广泛研究,ReID利用CNN进行特征提取并进行特征分类以实现匹配问题。
任务可描述为:
给定一个Gallery集合G作为被检测集合,包含有N张图片,分属M个ID(identity)。给定一张未知ID的图片做Query(或者叫probe), 通过训练集对ReID模型进行训练,在训练好的模型上进行Galleery与Query的特征相似度计算,对于每个Query,在Gallery中找出前N个与其相似的图片。下图是一个典型的ReID任务.

Query和Gallery
reid中Query其实就是目标行人(person of interest),而Gallery就是检索的库,也就是一大堆行人的照片或者视频。
宽泛地讲,Query和Gallery的形式有很多种,Query可以是一个行人的bounding box(照片)(一张或多张),也可以是一段视频,但是无论是图片还是视频,画面中一定只能有一个人。Gallery可以是从一整张画面截取的每个行人的bounding box,也可以是一段视频
行人重识别中的表征学习与度量学习
表征学习主要是研究如何提取一个行人的特征,包含全局表征学习,局部表征学习,辅助表征学习,基于视频的表征学习。
- 全局表征学习:直接将行人图片送入卷积神经网络去提取特征,这对主干网络的精度要求很高。此外文章还着重介绍了注意力机制在这里的作用。
- 局部表征学习:将行人的图片进行分块,使用网络对每一块抽取特征,最后将所有局部特征结合起来。
- 辅助表征学习:在网络中加入一些辅助性的元素,比如可以加入一些描述行人外观视角的文字,或者加入一些Domain的描述,或者加入一张使用GAN网络生成的图片。这样做可以加强网络的精度。
- 基于视频的表征学习:对网络输入一系列的图片,对每个图片抽取特征,最后合成一个总特征。
现阶段的度量学习主要是设计不同的损失函数,以及如何设计训练网络的策略。
损失函数主要有:identity loss, Verification loss, triplet loss, OIM loss。
在训练策略方面,着重解决以下几个问题:
- 行人(ID)的数量过多,需要在训练的每个batch中尽量多地选择ID进行训练。
- 对于每个ID,正样本数远远少于负样本数。
排序优化
排序(rank)是指在网络的预测阶段,需要对Gallery中的图片进行排序,排序越靠前的就是和Query越相似的,排序优化顾名思义就是优化排序这一阶段。
优化的主要方法有:re-ranking, rank-fusion…
Open-world Re-ID
- 端到端的Re-ID。端到端的意思就是,根据原始的视频信息去进行reid,直接返回目标ID在视频中的位置,这也更加贴近reid真实的应用。
- 半监督和无监督Re-ID。主要是如何进行聚类。
- 对噪声更加鲁棒的Re-ID。噪声主要是以下几个方面:1.物理的遮挡2.数据集采样的噪声,比如:没有框住行人、只框住了行人的一部分等3.数据集标注的噪声,比如这个人原本是A,但是标注成了B
评价指标
1.rank-k 2.CMC曲线 3.mAP曲线
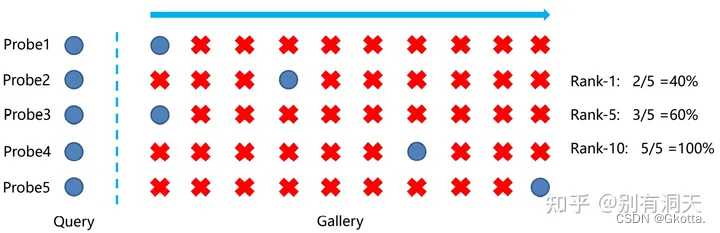
rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中,例如:rank1指第一张结果正确
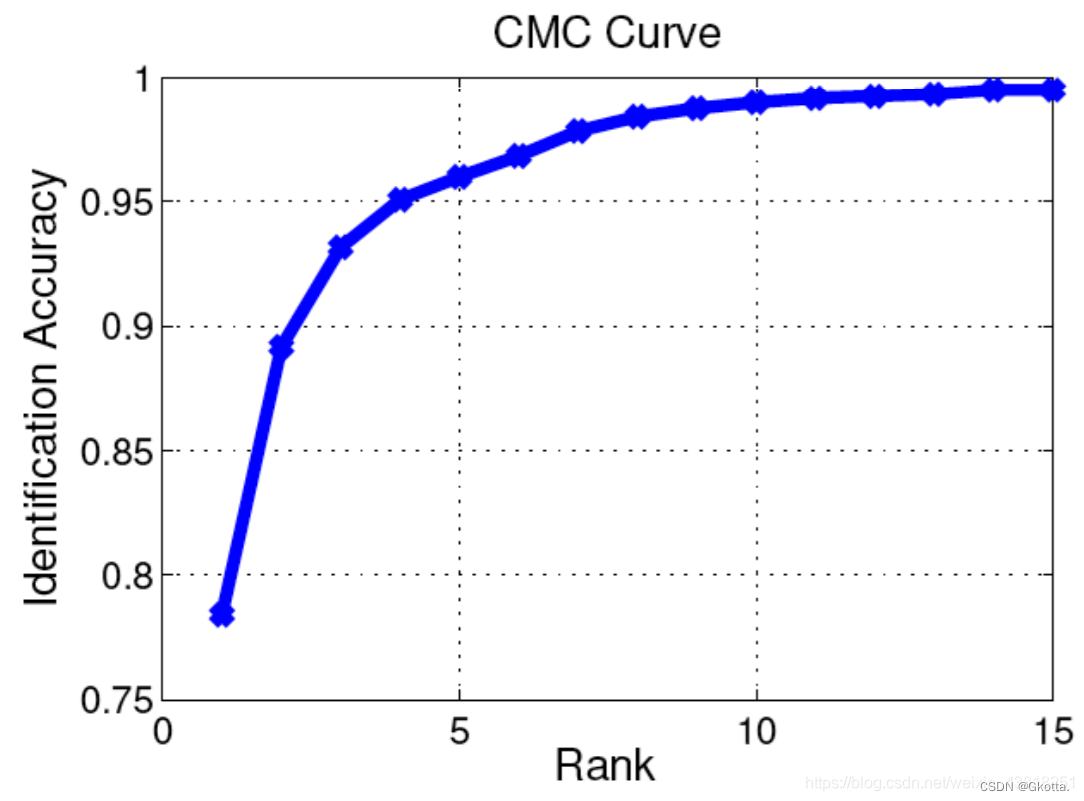
CMC曲线
• Cumulative Match Characteristic (CMC累计匹配曲线) curve:计算rank-k的击中率,形成rank-acc的曲线,需要引入一个概念Acc_K: 前k个gallery samples中包含query图像。
举例来说:
比如,我们训练了一个分类器,来识别五个物体,即五个query图像1,2,3,4,5,他们属于3类即A,B,C。
属于A类的物体1,经过分类器,得到属于A、B、C类的概率是80%,15%,5%,所以将物体1,判定为A类,物体1经过一次排序就被命中正确的类,所以我们引入Rank-1为100%。
物体2本来属于B类,被我们训练的分类器分类为A、B、C的概率分别为50%,40%,10%,所以被判定为A类,按照概率排序,如果有两次机会,才能命中,这就是Rank-2的含义。
因此对于一个query集合来说:
若果每个都能第一次命中,所以五个物体的Rank分别是 rank-1 100% rank-2 100% rank-3 100%。
如果物体1,2为一次就命中,3,4为两次才能命中,5为三次命中,则为 rank-1 40% rank-2 80% rank-3 100%。
当query很大时,得到CMC曲线如下图所示:

mAP曲线
• mAP(mean average precision平均精度均值):反应检索的人在数据库中所有正确的图片排在排序列表前面的程度,能更加全面的衡量ReID算法的性能。
mAP是mean Average Precision的缩写。表示查准率(AP)的平均值。此时,回归到re-id任务,我们关注的问题主要有两个:
查询返回的所有结果中,有多少结果是与query的ID相同的。
所有查询的同一个ID的图片中,有多少被查询返回了。
这两个关注的问题就涉及到我们平时所说的准确率和召回率两个概念。
准确率就是和query同一ID的图片在查询结果中的占比。

召回率就是query同一ID的图片出现在查询结果中的数量占总数的比例。

个人理解:
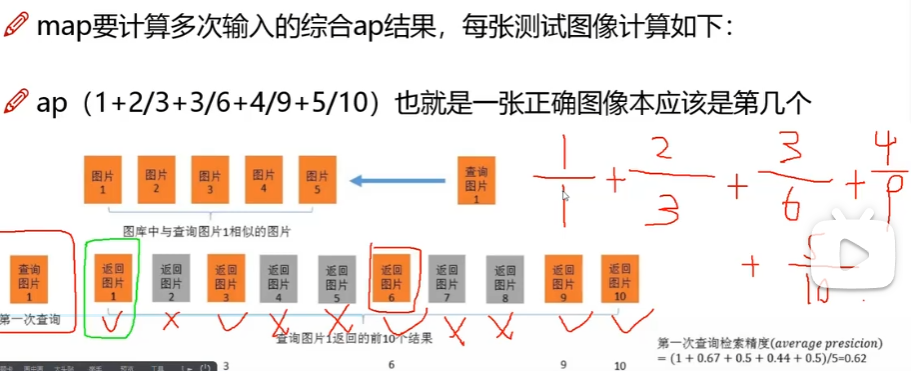
如上图:2/3,分子2:2张正确图片,分母3:在前三张中找到两张正确的。错误的不用管。最后除以5。这样得到ap结果。
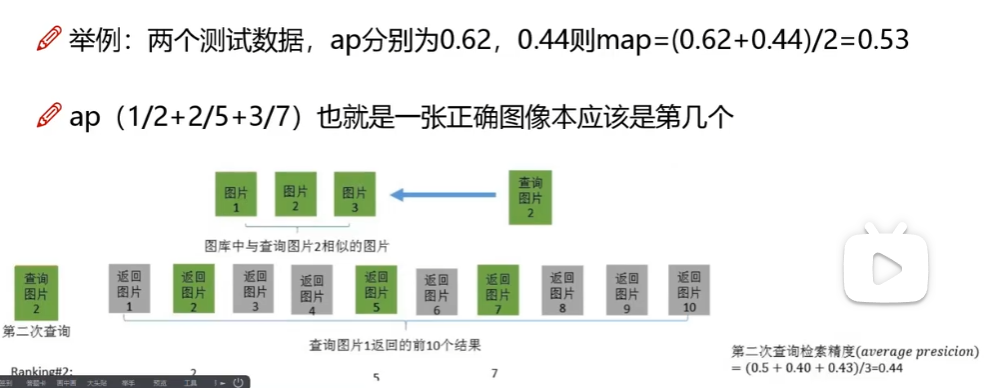
同样得到第二次ap,最后求两个平均,即是map值。
损失函数
损失函数通常是分类损失+Triplet loss(目标是为了让特征提取更好)
Triplet loss三元组损失,需要准备3份数据(可以行一个batch中选择),其中Anchor表示当前数据,Positive是和A相同人的数据,Negative是不同人的数据。

例如,11和13在经过训练后,两者A P都变成了向量,那当然是要越近越好,11和23在在经过训练后,两者A N都变成了向量,那当然是要越远越好。

含义理解:

Triple loss的目的,只需让A和P非常接近,A和N尽可能远离
公式:
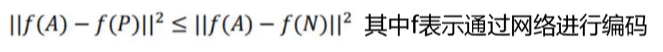
个人理解是(A和P)即同一人之间的距离,小于不同人(A和N)之间的距离。存在问题,即是为0也成立,修改公式
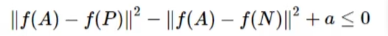
实际中的损失函数:
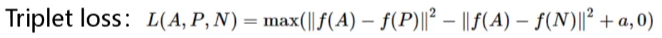
含义:当max(111,0)111>0时才进行学习。
存在的挑战:用的最多的是hard negative,选择样本时,d(A,P)约等于d(A,N)
常用评价模式
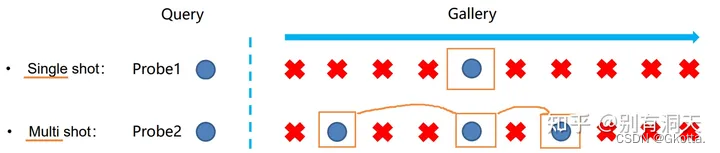
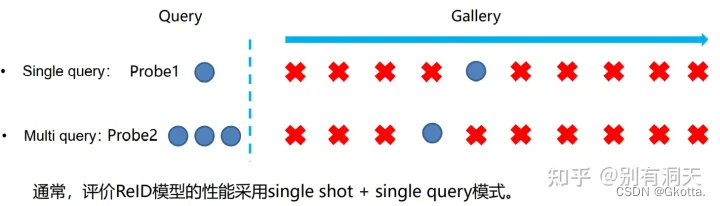
1. single shot vs multi shot
• Single shot是指gallery中每个人的图像为一张(N=1),而multi shot是指gallery中每个人的图像为N>1 张图像。同样的Rank-k下,一般N越大,得到的识别率越高。
2. single query vs multi query
• Single query是指probe中每个人的图像为一张(N=1),而multi query是指probe中每个人的图像为N>1 张图像,然后融合N张图片的特征(最大池化或者平均池化)作为最终特征。同样的Rank-k下,一般N越大,得到的识别率越高。
常用数据集
• SYSU-MM01
4 个 RGB 和 2 个 IR 摄像头
491persons,RGB 30071,IR 15792
SYSU-MM01 组成是6台摄像机(4台可见光,2台红外)的第一个大规模VI ReID基准数据集。287628张可见图像和15792张红外图像,491个身份。摄像机1,2,4,5为可见光摄像机,3,6为红外摄像机。训练集包含395人,包括22258张可见图像和11909张红外图像。测试集包含96个人,3803张IR图像可供查询,301/3010张(单次/多次拍摄)随机选择的RGB图像作为图库。同时包含两种不同的测试设置,所有搜索和室内搜索设置。实验设置的详细描述见Wu, A., Zheng, W.S., Yu, H.X., Gong, S., Lai, J.: Rgb-infrared cross-modality person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5380–5389 (2017)
• RegDB
数据集共有 412 个身份的行人,每个人分别对应10张RGB图像和10张红外图像,其中拍摄到 156 个行人的正面,256 个行人的背面。该数据集总共有 4120 张RGB 图像和 4120 张的红外图像。
1个可见光,1个红外相机的双相机系统收集。有412个身份(206个身份训练,206个身份测试),和8240个图像。对于每个人,有10个可见图像和10个红外图像。测试阶段还包含两个评估设置。一种是对红外可见以从RGB图像中搜索IR图像。另一个设置是“红外”到“可见”,用于从红外图像中搜索RGB图像。评估程序重复10次试验,以记录平均值

















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









