







Backdoors hidden in facial features: a novel invisible backdoor attack against face recognition systems --《隐藏在面部特征中的后门:一种针对人脸识别系统的新型隐形后门攻击》
后门攻击要点: 不影响合法用户的正常使用,但攻击者可以触发后门并冒充他人登录系统。
当前技术的缺陷: 使用明显的触发器,如太阳眼镜、大手帕等。
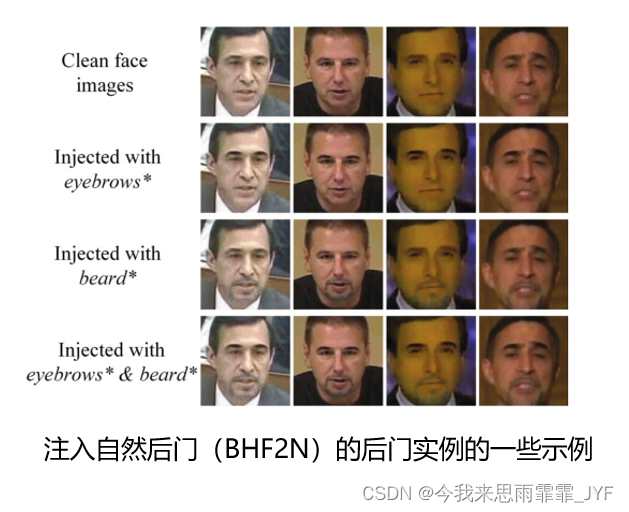
文章贡献: 首次使用人脸特征(眉毛、胡子)作为载体嵌入后门,将后门隐藏到面部特征中,提出BHF2和BHF2N,生成的后门攻击在视觉上隐蔽。
方法: 使用触发器
BHF2:构建眉毛和胡须面具。
BHF2N:利用图像美化工具(MTLab)自动生成自然的眉毛和胡须。
引言
近年来,深度学习技术在交通预测[1]、智能监控[2]和人体姿态估计[3]等多项任务中取得了显著的成绩。特别是,基于深度神经网络(DNN)的人脸识别系统已被部署在各种安全或安全敏感场景中,包括手机解锁[4]和在线支付[5]等。与传统的基于用户名和密码的用户身份认证方法相比,生物特征识别(如人脸、虹膜和指纹)被认为更方便可靠。
然而,一些研究[6-11]已经证明,DNN模型容易受到后门攻击。恶意攻击者可以修改目标网络的超参数和内部架构[6,7],或者将少量后门实例注入模型的训练集中[8,9]以嵌入特定后门。对于基于DNN的人脸识别场景,对手有很强的动机伪造自己的合法用户身份,从而登录系统并获得更高的系统权限。很少有人在基于DNN的人脸识别系统上进行后门攻击[12-14]。论文[12,13]使用面部饰品(紫色太阳镜[12]或手帕[13])作为他们攻击的后门。Sarkar等人[14]利用图像美化工具(即FaceAPP[15])产生的美化效果(如年轻效应)和特定的面部表情(如微笑)作为后门进行攻击。
动机
在现实世界的攻击中,这些针对基于DNN的人脸识别系统的现有后门攻击要么很容易被察觉[12,13],要么很难在真实的物理场景下发起[14]。首先,论文[12,13]中的后门很显眼,会引起人们的怀疑。特别是,对于那些严格的识别场景,例如,使用人脸识别技术来验证登机牌或护照,用户被要求摘下太阳镜或手帕进行识别。因此,通过使用面部附件的这种攻击方法[12,13]将不再可行。其次,美化工具产生的后门(例如,年轻效应[14])很难准确再现,具有相同面部表情的合法用户可能会错误地触发面部表情后门(例如微笑[14])。在本文中,我们首次探索在正式的身份验证场景下发起后门攻击,在这种情况下,攻击者可以在不使用任何额外附件的情况下触发攻击。这样就保证了后门攻击的视觉隐蔽性,并且所提出的攻击可以应用于那些严格的场景。
我们已经在ACM TURC2020上发表了这项工作的先前会议版本[16],其中我们通过所提出的BHF2方法[16]将后门嵌入为面部特征,并在DeepID1[17]人脸识别模型上证明了其有效性。本文是我们之前工作[16]的扩展版本,这项工作的新材料和贡献如下:(i)首先,我们在两个不同的人脸识别模型(DeepID1[17]和VGGFace[18])上证明了所提出的攻击方法(在面部特征中隐藏后门)的普适性,这两个模型具有不同的网络结构和输入大小。此外,这两个模型采用了不同的训练技术,其中DeepID1是从头开始训练的(即从一开始就训练整个网络),VGGFace是基于预先训练的模型重新训练的。(ii)其次,为了使注入的后门更自然,我们提出了一种改进的后门方法,称为BHF2N,该方法利用基于人工智能的图像处理工具来生成自然后门。嵌入式后门非常隐蔽,因此不会引起人类的注意。(iii)第三,我们使用三种不同的评估指标(像素值变化率[16]、结构相似性(SSIM)得分[19]和dHash相似性得分[20])来评估我们生成的后门的视觉隐蔽性,这进一步证明了所提出的后门攻击的隐蔽性。(iv)最后,我们将所提出的攻击方法与人脸识别系统上三种最先进的后门攻击[12-14]进行了比较。比较结果表明,所提出的方法(BHF2和BHF2N)可以获得更好的攻击性能,或者对后门实例的注入率要求更低。
主要贡献:
- BHF2和BHF2N攻击方法。针对基于DNN的人脸识别系统,本文提出了两种后门攻击方法BHF2和BHF2N。这两种攻击方法首次将后门隐藏到面部特征中。BHF2构建了两个不同形状的眉毛和胡须面具,以注入规则的后门,而BHF2N则利用图像美化工具自动生成自然的眉毛和胡子作为触发器。所提出的方法对于那些具有不同网络结构的人脸识别模型是可行的,无论网络是从头开始训练还是基于预先训练的模型进行微调。
- 隐蔽性。我们用三个指标证明了注入后门的视觉隐蔽性:像素值变化率[16]、结构相似性(SSIM)得分[19]和dHash相似性得分[20]。后门实例相对于其原始图像的像素值变化率仅为0.16%,而SSIM和dHash相似性得分分别达到98.82%和98.19%。攻击者可以通过对特定面部特征进行简单化妆来触发后门攻击,而不是佩戴显眼的面部饰品或整张脸化妆。
- 黑匣子攻击场景。所提出的攻击方法在黑匣子攻击条件下是可行的,在这种条件下,攻击者对目标识别系统(如网络结构或参数)一无所知。BHF2和BHF2N攻击方法可以通过只注入一小部分后门人脸图像来实现(500/128300,DeepID1模型[17]为0.39%;VGGFace模型[18]为100/10000,1%)。此外,在不允许佩戴面部饰品的更正式的场景下,所提出的BHF2和BHF2N方法是可行的。
- 高攻击性能。所提出的攻击方法可以在不影响人脸识别系统正常性能的情况下获得较高的攻击成功率。所提出的攻击方法对两个最先进的人脸识别模型(DeepID1[17]和VGGFace[18])的攻击有效性最高均为100%,而两个目标模型的识别准确率分别仅下降0.01%和0.02%。
相关工作
对DNN模型的后门攻击。 针对DNN模型发起后门攻击有两种策略。一种是直接修改DNN模型的参数或网络架构,以嵌入后门[6,7,21]。Zou等人[6]直接插入了神经层面的木马(即神经元)进入DNN模型,并且注射的特洛伊木马仅在罕见的激活条件下被触发。刘等人[7]通过最大化特定神经元的激活来生成后门,然后重新训练DNN模型,将生成的后门注入网络。最近,Rakin等人[21]提出了目标位特洛伊木马(TBT)方法,将神经特洛伊木马注入DNN模型。他们使用梯度排序方法来找到DNN模型的脆弱神经元,并翻转这些神经元的权重(即修改内部参数)以插入恶意触发器[21]。然而,上述后门攻击方法[6,7,21]要求攻击者能够访问DNN模型,这在实践中很难满足。另一种后门攻击策略是使用数据中毒[8,22,23],攻击者只需要在训练集中添加少量特制的后门实例。当在这些恶意后门实例上训练模型时,后门可以嵌入到神经网络中。Gu等人[8]提出了BadNets,它通过将符号(黄色正方形或花朵)粘贴到干净的图像上来注入后门,并将这些图像的标签修改为目标类的标签。然后,他们将后门实例添加到干净训练集中,以训练DNN模型嵌入特定后门[8]。廖等人[22]构造了两种类型的扰动(分别为静态模式扰动和自适应扰动)作为其攻击的隐形后门,从而使注入的后门不可见。王等人[23]研究了迁移学习任务的后门攻击,旨在击败那些常用的防御措施,如精细修剪和输入预处理。为此,作者分别基于排名、自动编码和再训练开发了三种不同的攻击策略[23]。
防御后门攻击。 针对后门攻击提出了一些防御措施[24-28]。Chen等人[24]使用激活聚类(AC)方法检测后门攻击。对于目标DNN模型,AC方法提取其最后一个隐藏层的激活,并使用k-means聚类算法对这些激活进行聚类,以区分干净数据和这些注入的后门实例[24]。刘等人[25]通过修剪和微调目标DNN模型来减轻后门攻击的影响。他们对DNN模型的内部结构进行了微调,并对其神经网络进行了修剪,以去除那些受感染的神经元。王等人[26]开发了一种神经清洗(NC)方法来击败后门攻击。NC方法利用逆向工程技术为目标DNN模型的每个标签寻找候选触发器。通过对这些候选触发器执行异常值检测算法,NC方法可以确定该模型是否受到攻击,并确定哪个标签受到了感染[26]。Udeshi等人[27]提出了一个名为NEO的模型不可知框架,用于检测后门攻击。NEO搜索输入图像的区域,以定位嵌入后门的几个潜在位置,然后使用触发阻断器[27]每次覆盖其中一个位置。通过这种方式,通过观察DNN模型的预测,NEO可以确定该输入图像中的哪个位置被触发了[27]。与那些被动防御不同[24-27],Gao等人[28]提出了一种基于强意图扰动(STRIP)的主动防御方法。他们的方法有意在目标DNN模型的输入上添加扰动,以区分良性和后门实例。
在本文中,所提出的两种方法只注入了一小部分后门人脸图像(DeepID1模型[17]为0.39%,VGGFace模型[18]为1%)来实现攻击。此外,对干净的人脸图像的修改非常小,其中后门实例相对于其干净的人脸的像素变化率低至0.16%。因此,这些现有的检测方法很难检测到所提出的后门攻击。
现有针对基于DNN的人脸识别系统的后门攻击。 到目前为止,很少有人对基于DNN的人脸识别系统进行后门攻击[12-14]。Chen等人[12]提出了两种不同的后门攻击方法,它们使用输入实例或模式作为发起攻击的“关键”。第一种攻击方法是在整个人脸图像上添加一些随机噪声作为触发。对于第二种攻击方法,作者分别选择了一张“Hello Kitty”图片和两种不同类型的配饰(黑框眼镜和紫色太阳镜)作为攻击的后门[12]。Wenger等人[13] 提出了针对物理世界中人脸识别系统的后门攻击。他们收集了九种不同的面部饰品(如太阳镜和手帕)作为实物后门。然后,他们为现实世界中穿着配饰的人拍照,以引发对VGGFace模型的攻击[13]。Sarkar等人[14] 利用图像美化工具(FaceAPP[15])生成的美化效果(如年轻化效果)和特定的面部表情(如微笑)作为后门进行后门攻击,使具有相同妆容或相同面部表情的攻击者可以被面部识别系统识别为目标用户。
然而,上述后门攻击不是隐蔽的[12,13],或者无法在现实世界场景中实现[14]。现有论文[12,13]中使用的后门(如紫色太阳镜[12]和手帕[13])很容易被视觉注意到,这会极大地引起人类的怀疑。此外,在那些不允许用户的面部被任何东西(如配件)覆盖的身份识别场景中,攻击方法[12,13]将不再适用。[14]中提出的攻击在现实世界中是不可行的。美容效果后门(例如,年轻[14])很难被攻击者复制。此外,具有相同面部表情(如微笑)的合法用户很容易错误地触发面部表情后门[14]。
本文与这些现有的后门攻击[12-14]之间的区别如下:
- 注入后门的隐秘性。我们首次利用面部特征(眉毛和胡子)作为载体嵌入后门。这确保了注入的后门在视觉上是自然的,并且很好地隐藏在人类的脸上,从而保证了所提出的后门攻击的隐蔽性。
- 适用于更严格的攻击场景。所提出的隐形后门攻击对于那些严格的身份验证场景是可行的。攻击者可以通过简单的眉毛或胡须化妆来触发后门攻击,而不是佩戴引人注目的面部饰品。
- 对面部图像作出较少的修改。与将配饰大面积粘贴在人脸图像上或在整个人脸上化妆不同,所提出的攻击方法只需要修改人脸的一个小的特定区域就可以注入后门,因此更隐蔽,不易被注意到。
攻击模型:
攻击者目标: 对基于DNN的人脸识别系统发起后门攻击。
符号:

对手目标:

对手知识: 在黑盒攻击场景下
白盒:(1)知道模型内部结构(隐藏层、FC的数量,输入大小等);
(2)知道模型参数(步长、学习率);
(3)训练和测试数据(合法用户的大量干净人脸);
(4)预训练模型的权重。
对手的能力: 只能在干净的训练集中注入少量后门人脸图像。
步骤:

BHF2规则后门:

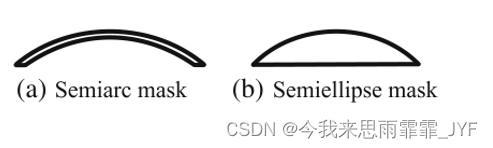

BHF2N自然后门:
使用MTLab工具生成
攻击:
攻击标签为 t 的目标受害者,后门实例的基本事实标签将更改为相同的标签 t

数据集:
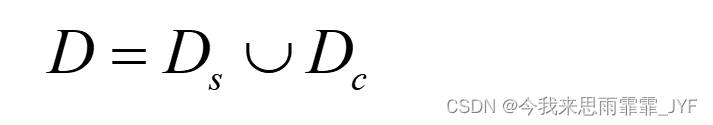
目标函数:

实验
数据集: YouTube Aligned dataset[33]
人脸识别模型: DeepID1[17]和VGGFace[18]
评价指标: 攻击成功率、系统准确率下降、像素变化率[16]、SSIM[19]和dHash相似性得分[20]
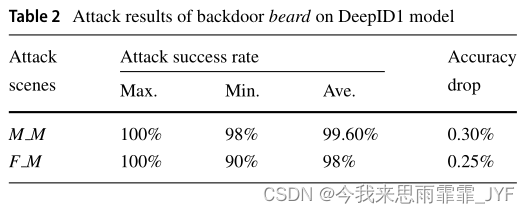
规则后门(眉毛和胡子)在DeepID1模型上的性能



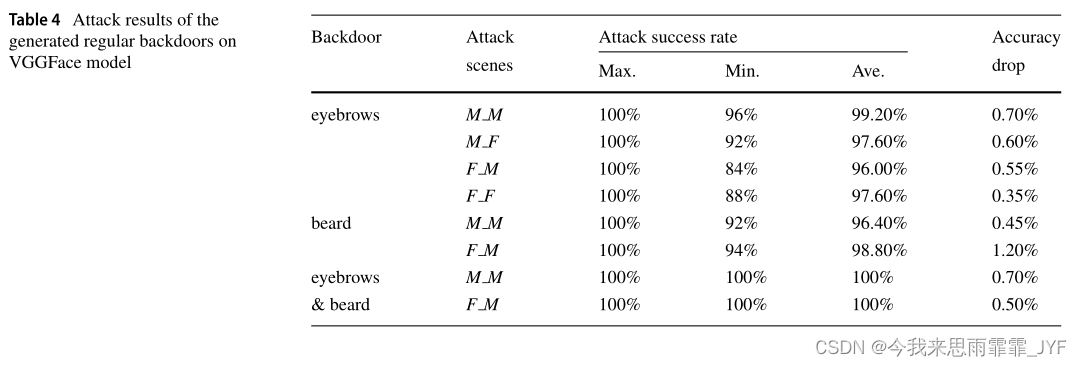
规则后门(眉毛和胡子)在VGGFace模型上的性能
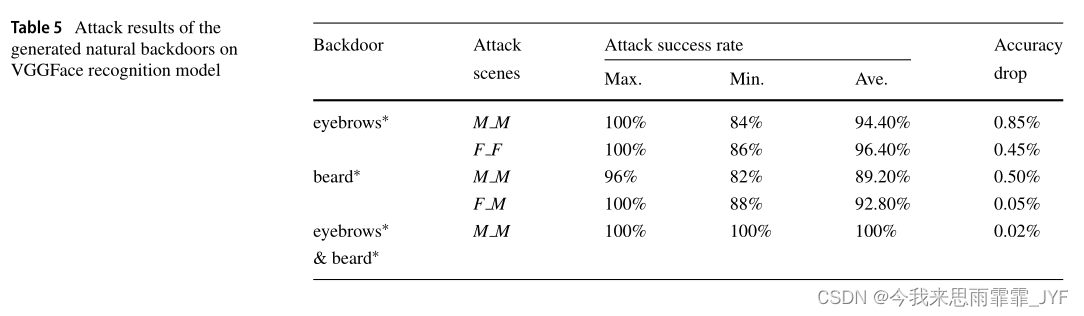
自然后门(眉毛和胡子)在VGGFace模型上的性能
注入不同后门的后门实例的平均像素值变化率

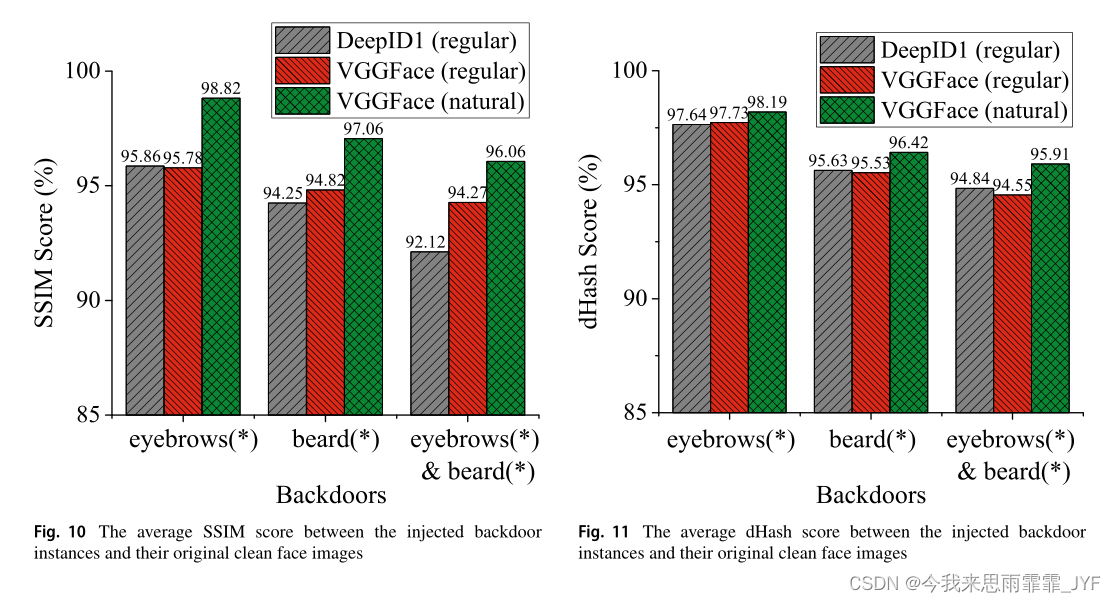
结构相似性和哈希相似性得分















 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









