







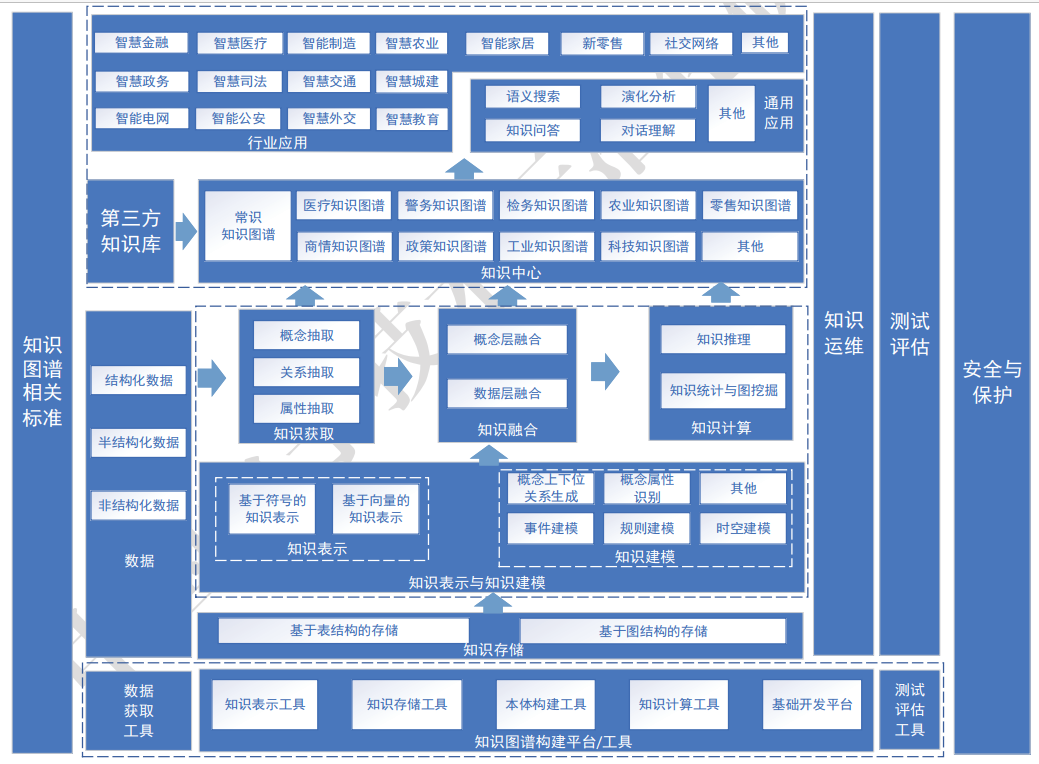
知识图谱主要技术包括知识获取、知识表示、知识存储、知识建模、 知识融合、知识理解、知识运维等七个方面,通过面向结构化、半结构化和非结构化数据构建知识图谱为不同领域的应用提供支持,具体的技术架构图如下图所示。
知识获取
知识图谱中的知识来源于结构化、半结构化和非结构化的信息资源,如下图所示。通过知识抽取技术从这些不同结构和类型的数据中提取出计算机可理解和计算的结构化数据,以供进一步的分析和利用。知识获取即是从不同来源、不同结构的数据中进行知识提取,形成结构化的知识并存入到知识图谱中。当前,知识获取主要针对文本数据进行,需要解决的抽取问题包括:实体抽取、关系抽取、属性抽取和事件抽取。
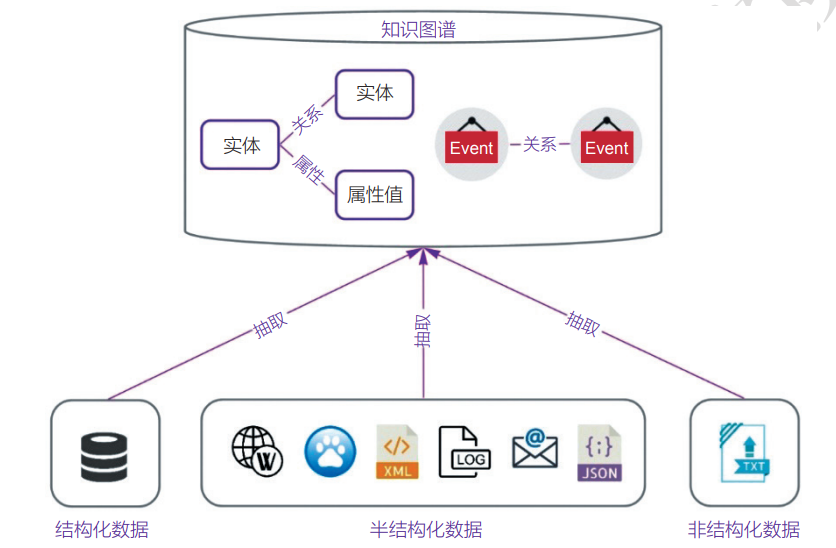
知识获取作为构建知识图谱的第一步,通常有以下四种方式:众包法、爬虫、机器学习、专家法。
众包法:允许任何人创建、修改、查询的知识库,就是常说的众包模式,百度百科,维基百科就是典型的例子。此类场景下知识库存储的不是大量的杂乱的文本,而是机器可读,具有一定结构的数据格式(以百度某词条为例)。现代通过众包法建立的知识图谱如谷歌和百度的知识图谱都已经包含超过千亿级别的三元组,阿里巴巴于2017年8月份发布的仅包含核心商品数据的知识图谱也已经达到百亿级别。
爬虫:网页开发者将网页中出现的实体、实体属性、关系按照某种规则做上标记,Google、百度等搜索引擎通过爬虫就能获取到这些数据,从而达到知识图谱数据积累。当前不同语言的爬虫框架有不少,例如python的Scrapy,java的WebMagic等,通过简单的配置即可完成爬虫的规则定义、爬取、清洗、去重、入库等操作,从而获取知识。
机器学习:通过机器学习将数据变成了可理解的知识,例如通过文本分类、主题模型等机器学习模型,可以获取文本的特征,而这些特征就可以理解为知识。
专家法:专家法通常用于垂直领域的工程实践,通过专家的经验,归纳总结后形成知识,例如在知识图谱中的事件图谱通常是由专家的经验形成的。
研究现状
目前,面向互联网海量文本数据的知识抽取是研究的主流。已有很多信息抽取的方法被提出用来解决该问题,按照抽取对象的不同,可分为实体抽取、关系抽取、属性抽取和事件抽取。
实体抽取也称为命名实体识别(named entity recognition, NER),是指 从文本语料库中自动识别出专有名词(如机构名、地名、人名、时间等)或有意义的名词性短语,实体抽取的准确性直接影响知识获取的质量和效率。因此,实体抽取是知识图谱构建和知识获取的基础和关键。为了解决早期的实体抽取方法存在的问题,规则和监督学习相结合的方法、半监督方法、远程监督方法以及海量数据的自学习方法等被相继提出。
属性主要是针对实体而言的,以实现对实体的完整描述,由于可以把实体的属性看作实体与属性值之间的一种名词性关系,所以属性抽取任务就可以转化为关系抽取任务,例如,采用SVM方法将人物属性抽取问题转化为人物的关系抽取,提出的基于规则与启发式的抽取方法能够从Wikipedia和WordNet半结构化网页中自动抽取出属性和属性值,其抽取的准确率可达95%,并因此得到了著名的本体知识库YOGO,还有直接从非结构化文本中挖掘出实体属性名称和属性值之间的位置关系模式的属性抽取的方法。
事件是发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。目前已存在的知识资源(如维基百科等)所描述实体及实体间的关联关系大多是静态的,事件能描述粒度更大的、动态的、结构化的知识,是现有知识资源的重要补充。
技术发展趋势
现有对知识抽取的研究虽在特定领域数据集上取得了较好的效果,但远远满足不了实际任务的要求。因此,资源缺乏、面向开放域、跨语言及跨媒体等方向的知识抽取成为未来的研究方向。
目前,大多数知识抽取的研究主要采用的是有监督的方法,需要大量的标注训练集去训练模型参数,然而构建标注数据集的成本比较大,且在更换语料类型后,算法的性能往往不尽如人意,即算法的性能严重依赖大规模的训练数据。因此,如何构建资源缺乏下的知识抽取系统成为研究的热点。
知识抽取是知识图谱构建的基础,虽然当前技术对于知识单元(实体、关系、属性)的抽取在特定领域取得了较好的效果,但是由于数据主题或规模等条件的制约,方法的可移植性与可扩展性不强,不能很好的满足大规模开放领域环境下的知识抽取要求。因此,知识抽取发展方向之一是研究大规模面向开放领域的知识抽取技术。具体包括:(1)数据规模上的可扩展性,能够高效完成海量数据的抽取任务;(2)数据主题上的鲁棒性,能够在面对不同主题的数据时具有鲁棒性。
随着英文知识图谱技术的发展,多语种知识库的构建任务也在快速开展,因此,跨语言的知识抽取任务也成为当下研究的热点。跨语言的知识抽取为研究语言间的互补性和冗余性提供了机会,具体的研究包括:(1)自然语言表达的多样性,不同的语种在表示方式上均具有多样性,需要将实体关系知识映射到三元组上;(2)不同语种在知识表达方式上的差异性,通过比较不同语种对同一知识的表述,可以达到删除或更新错误知识的目的。目前针对跨语言的知识抽取,已有学者进行了研究并取得了一些成果,例如,清华大学李涓子教授团队融合中英文维基百科、法语 维基以及百度百科构建成了的跨语言知识库XLORE,并在此基础上实现了实体链接系统XLink。
随着深度学习创新理论的出现及大数据和算力的强力支撑,文本已经可以和图像/视频、音频等跨媒体数据采用相同的深度学习框架进行分析和建模,使得不同模态数据在人类语义层面耦合。因此,跨媒体的知识抽取任务逐渐成为研究热点之一。跨媒体的知识抽取可以利用视觉、听觉等多模态已标注信息来辅助文本标注缺乏下的知识抽取,又可以作为类似跨语言知识抽取的另一维度为实体间未知关系的挖掘及已标注关系的消歧提供互补信息。此外,跨媒体知识抽取在上述开放应用域的基础上,从多模态数据域维度进一步扩展,对模型鲁棒性等方面提出更大挑战。具体研究内容包括:
(1)视觉实体和关系的抽取:相对于文本中的实体和关系相对确定性,视觉实体和关系呈现出尺度、表型、空间关系等多样性,需要通过鲁棒语义模型的构建实现视觉实体和关系的抽取,从而将视觉局部区域映射到三元组上;(2)视觉事件的自然语言描述:针对图像/视频,基于人工智能理论自动生成一段语法和逻辑合理的视觉内容自然语言描述,从而实现语义丰富的视觉信息到抽象的语义事件描述的映射;(3)跨媒体信息融合:跨媒体信息在知识载体上存在差异,通过多模态信息在相同粒度和语义上的对齐,进一步实现特征和语义层面的融合,可以综合利用多模态信息,来辅助后续知识表示、建模、计算等关键技术,并形成面向跨媒体知识图谱构建的创新理论体系和关键技术。


















 2653
2653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











