







Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
这篇文章中文为时空图卷积网络: 用于交通预测的深度学习框架,归类于交通网络中的交通流预测。
这是一篇目前为止引用量3000+的文章,应该造成了很大的影响,不过话说回来,读论文半年以来好像第一次读引用这么高的论文,读的论文还是太少了,惭愧啊,不对以前还看过resnet的论文哈哈哈哈哈。这篇是发表在IJCAI2018上的,是北大的Zhanxing Zhu(朱占星)老师组下的文章,顺手查了一下朱老师,发现了知乎账号还有招生广告哈哈哈,不知道有没有大佬投递呢。那么闲话少说了。
背景&动机
读这篇文章给我的感觉就是,行文逻辑非常清晰,对于本文的背景,以及相关研究讲述的非常清楚,这一点我觉得值得我们去学习。
简单来说交通预测就是根据当前交通流的基本变量,即速度、流量和密度作为监测当前交通状况并预测未来的指标(但是上一篇读的文章是根据一个地区历史一段时间的出行请求,来预测接下来一段时间的出行量,两者好像有点区别)。基本的预测会分为两个尺度分别是5-30分钟的短期以及30分钟以上的长期,短期基本上用统计方法会比较多,而在长期尺度上,会以动态建模方法和数据驱动方法。当然他们各自都有一些问题,我画了一个思维导图如下,能比较清晰的理清楚这其中的关系。
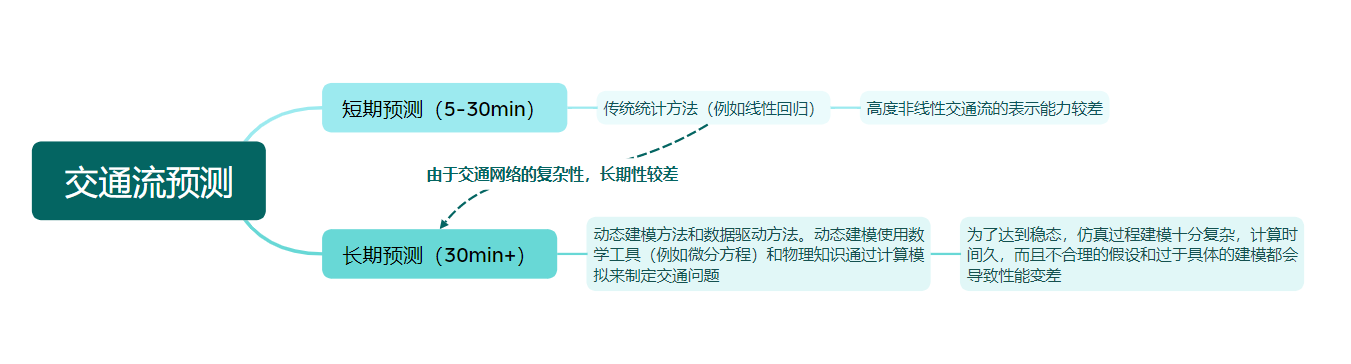
因此我们需要使用基于数据驱动的深度学习。在这篇文章之前就有一些使用深度学习的工作,但是他们都各自有一些缺陷,如下
- 如果是密集网络,则很难从输入中联合提取空间和时间特征。此外,在狭窄的约束甚至完全缺乏空间属性的情况下,这些网络的代表性能力将受到严重阻碍。
- 为了解决上一点有作者提出CNN+LSTM的组合,一方面CNN不适合用于这种场景,其次LSTM这种循环网络非常难以训练
所以作者提出来了一些方法来解决前人的问题,如下
- 引入策略来模拟交通流的时间动态和空间依赖性
- 用图对网络进行建模,并且使用全卷积结构来避免循环网络
- 提出一种新的结构,名为时空卷积网络,其中包含了多个实质为图卷积层和卷积序列层组合的时空卷积块
前提知识
前提知识主要分为两个部分,回答了两个问题,分别是如何用图来表示交通数据以及如何在图上面实现卷积
图表示
首先交通道路数据是一个n条路的观测向量,向量每个元素是一条路的数据,所以我们可以构建这样一幅图,点是我们的观测点,边则是道路,边权重则可以是交通流数据,同时这个图也可以是有向也可以是无向图,m个时间步则构成了m副图。
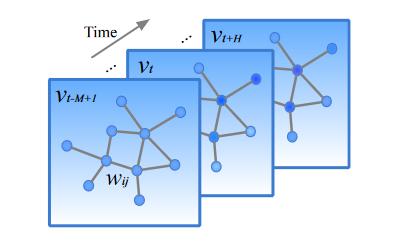
图卷积
显而易见类似CNN的卷积是用在图像上并不是在图上(photo和graph的区别看这篇文章的人应该都搞得清吧)。所以一般来说有两种做法
-
扩展卷积的空间定义[Learning convolutional neural networks for graphs.]
-
通过图傅立叶变换在谱域中进行操作[Spectral networks and locally connected networks on graphs.]
本文采用了后面的一种做法,做谱域卷积,于是作者参考以前的文献定义了一个图卷积计算算子是内核
Θ
\Theta
Θ 和信号
x
x
x 的乘法(其实没太看懂这个内核的含义,应该需要去看那篇参考文献的原文)。
Θ
∗
G
x
=
Θ
(
L
)
x
=
Θ
(
U
Λ
U
T
)
x
=
U
Θ
(
Λ
)
U
T
x
\Theta*_\mathcal{G}x=\Theta(L)x=\Theta(U\Lambda U^T)x=U\Theta(\Lambda)U^Tx
Θ∗Gx=Θ(L)x=Θ(UΛUT)x=UΘ(Λ)UTx
图傅里叶卷积是基于归一化的拉普拉斯特征向量,emmm具体的参数定义的话,参考原文和参考文献吧。根据这个定义,图信号
x
x
x 通过核
Θ
\Theta
Θ 进行滤波,并在
Θ
\Theta
Θ 和图傅里叶变换
U
T
x
U^Tx
UTx 之间进行乘法运算。
模型介绍
网络结构
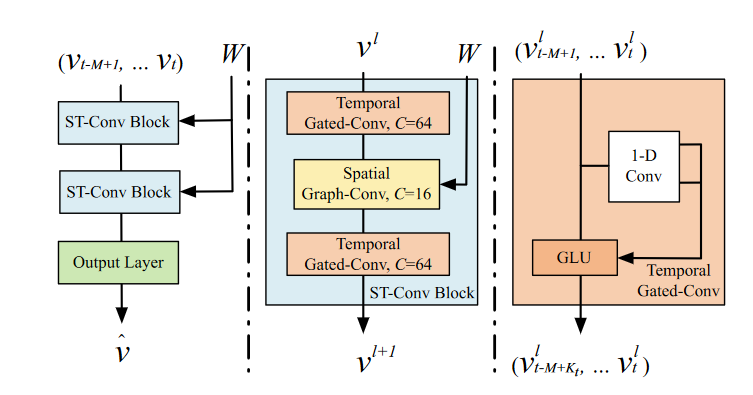
如下图所示,分三个部分,右边是左边一个子模块的一个衍生放大。主要结构由两个时空卷积块和一个全连接的输出层。
每个时空卷积块又由两个时间门控卷积层和一个空间图卷积层是一个名副其实的**“sandwich” **,并且使用了残差连接和瓶颈策略
其实有个小细节,对应块的底色是相同的,这样能更方便读者的阅读,我觉得这种细节也是值得大家学习的。
图卷积空间特征提取(计算策略)
首先交通网络建模为图结构是合理的,但是一张图的计算量肯定是非常大的,这一点毋庸置疑。然后就有一些研究做法就是分段或者分块,作者认为分开的话就忽略了网络的连通性和全局性,这一点感觉不合适其实,所以想要直接用在图结构化的数据上,这个时候傅里叶图卷积的计算成本很高,在 O ( n 2 ) O(n^2) O(n2) 这个数量级,所以作者采用两种近似策略来解决问题。分别是切比雪夫多项式近似和一阶多项式近似。
切比雪夫多项式近似
公式如下,我尽力去查找相关信息了,真的看不懂,等以后搞明白了再来补充。具体的字符定义请参照原文。但是其实我觉得还好,和这篇论文的主要思想不冲突,因为这是一种数值计算减少计算量的方法。
Θ
∗
G
x
=
Θ
(
L
)
x
≈
∑
k
=
0
K
−
1
θ
k
T
k
(
L
~
)
x
\Theta*_\mathcal{G}x=\Theta(L)x\approx\sum_{k=0}^{K-1}\theta_kT_k(\tilde{L})x
Θ∗Gx=Θ(L)x≈k=0∑K−1θkTk(L~)x
一阶多项式近似
逐层线性公式可以通过使用图拉普拉斯算子的一阶近似堆叠多个局部图卷积层来定义,恩都是中文,放在一起就看不懂了。
Θ
∗
G
x
=
θ
(
I
n
+
D
−
1
2
W
D
−
1
2
)
x
=
θ
(
D
~
−
1
2
W
~
D
~
−
1
2
)
x
.
\begin{gathered} \Theta*_{\mathcal{G}}x =\theta(I_n+D^{-\frac12}WD^{-\frac12})x \\ =\theta(\tilde{D}^{-\frac12}\tilde{W}\tilde{D}^{-\frac12})x. \end{gathered}
Θ∗Gx=θ(In+D−21WD−21)x=θ(D~−21W~D~−21)x.
图卷积推广
y j = ∑ i = 1 C i Θ i , j ( L ) x i ∈ R n , 1 ≤ j ≤ C o y_j=\sum_{i=1}^{C_i}\Theta_{i,j}(L)x_i\in\mathbb{R}^n,1\leq j\leq C_o yj=i=1∑CiΘi,j(L)xi∈Rn,1≤j≤Co
这里的很多公式其实都看不太懂感觉,我觉得我们不需要过分沉溺于这个数学公式之中,结合标题给的感觉核心思想就是我们需要提取图的空间特征,作者使用的是图卷积的方案,其中具体介绍的则是怎么卷积的以及如何使用数值计算减少计算量。
与此同时我们也应该思考,他这里图的空间特征可能就是一整个图的特征,作者以连通性以及全局性距离,但是我们是否可以换个思路,关于图或者网络还有很多性质,如小世界网络,无标度网络,以及其他的一些指标,如介数中心性,度中心性等等,尝试这些指标,能否在计算复杂度,结果准确性上做到一定的优化呢?
用于提取时间特征的门控 CNN
从三明治结构入手,提到了空间特征也就是整个图的一些性质,接下来作者就开始介绍空间特征提取的一些操作了。emmm原文中提到了P和Q感觉还是读起来很费劲,找了一下源码,大概结构如下(一个pytorch版本,大佬改写的)
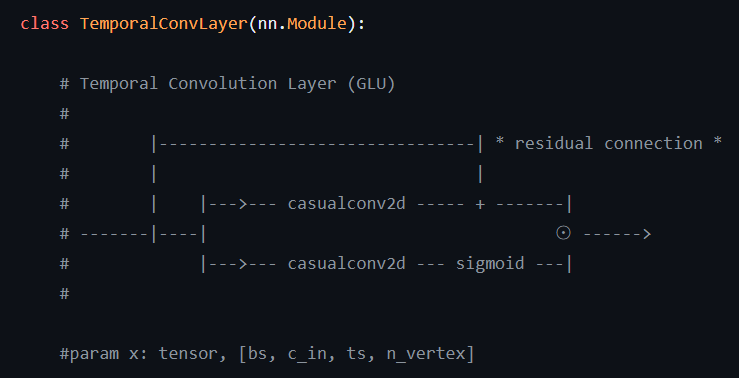
一个输入经过卷积加上残差,另一个是同样的一个输入经过卷积然后sigmoid激活函数,两条路最后经过一个逐项乘(Hadamard product),最后得到结果,这里就不详细介绍原文的一些概念了。
ST-Conv block介绍
经过上述,分别介绍了三明治的“面包”和“肉”,接下来就介绍这整个块了。其实,就是上面几个小块的堆叠,同时加入了残差和瓶颈策略,就是ResNet的一些思想防止梯度爆炸,也加入了正则化防止过拟合,并且加入了一个ReLU函数,可以描述为这样。
v
l
+
1
=
Γ
1
l
∗
T
ReLU
(
Θ
l
∗
G
(
Γ
0
l
∗
T
v
l
)
)
,
v^{l+1}=\Gamma_1^l*_\mathcal{T}\text{ReLU}(\Theta^l*_{\mathcal{G}}(\Gamma_0^l*_{\mathcal{T}}v^l)),
vl+1=Γ1l∗TReLU(Θl∗G(Γ0l∗Tvl)),
这其中
Γ
0
l
Γ
1
l
\Gamma_0^l\Gamma_1^l
Γ0lΓ1l 分别是三明治的顶部和底部,所以整个块的计算是从右往左的。并且使用L2 Loss进行误差计算。
到这里,模型几乎就介绍的差不多了。作者接下来总结了几个模型的特征
- STGCN 是处理结构化时间序列的通用框架。它不仅能够解决交通网络建模和预测问题,而且可以应用于更一般的时空序列学习任务。
- 时空块结合了图卷积和门控时间卷积,可以提取最有用的空间特征并连贯地捕获最本质的时间特征。
- 该模型完全由卷积结构组成,因此以更少的参数和更快的训练速度实现了输入的并行化。更重要的是,这种经济架构使得模型能够更高效地处理大规模网络。
实验
终于到实验了,模型读起来是真费劲啊。作者在两个数据集上做实验的,分别是
- BJER4,BJER4是通过双环探测器对北京市东四环线主要区域进行采集。作者选择了 12 条道路进行实验。流量数据每 5 分钟汇总一次。使用的时间段为2014年7月1日至8月31日(周末除外)。作者选择第一个月的历史速度记录作为训练集,其余的分别作为验证集和测试集。
- PeMSD7,PeMSD7 是由加州公路系统主要都市区部署的超过 39, 000 个传感器站从加州交通局绩效测量系统 (PeMS) 实时收集的。该数据集还从 30 秒的数据样本聚合为 5 分钟间隔。作者在加州第7区随机选取一个中尺度和大尺度的228个站点和1, 026个站点,分别标记为PeMSD7(M)和PeMSD7(L)作为数据源(如图3左侧所示)。 PeMSD7数据集的时间范围是2012年5月和6月的工作日。作者按照上述相同的原则分割训练集和测试集。
数据处理的话,进行数据清洗,缺失的数据使用线性插值进行补全。评估指标采用的MAE,MAPE,RMSE,恩大家好像都是这么干的。具体数据怎么用的也参照原文吧,这里不过多解释了。有两幅可视化的图,可以参考一下。
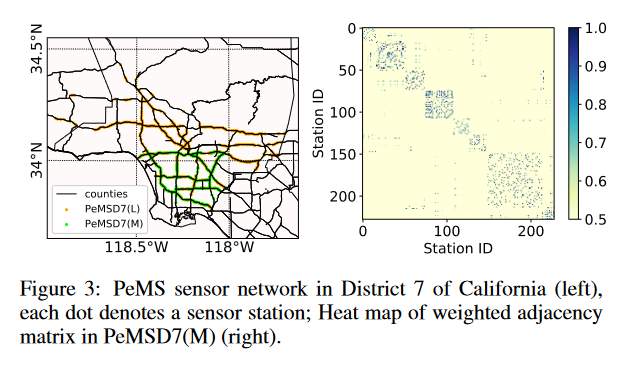
结果
在很多个上面表现得都很好,具体就不过多介绍了,如下图

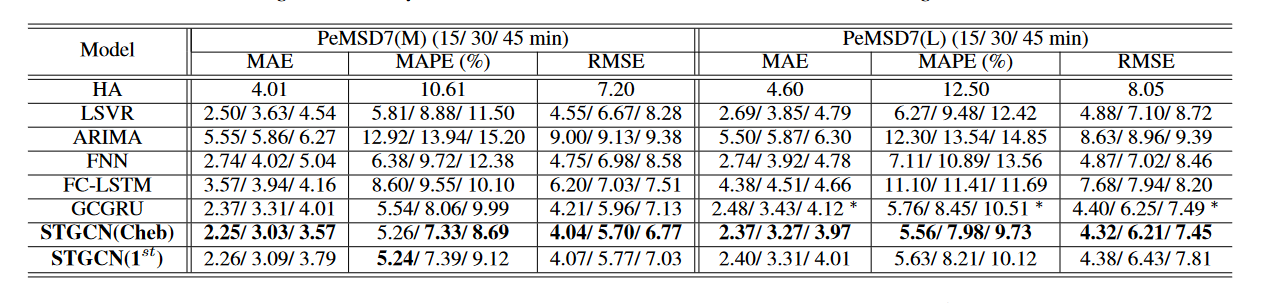
然后切比雪夫会比一阶近似更好一些,interesting!接下来是一些曲线
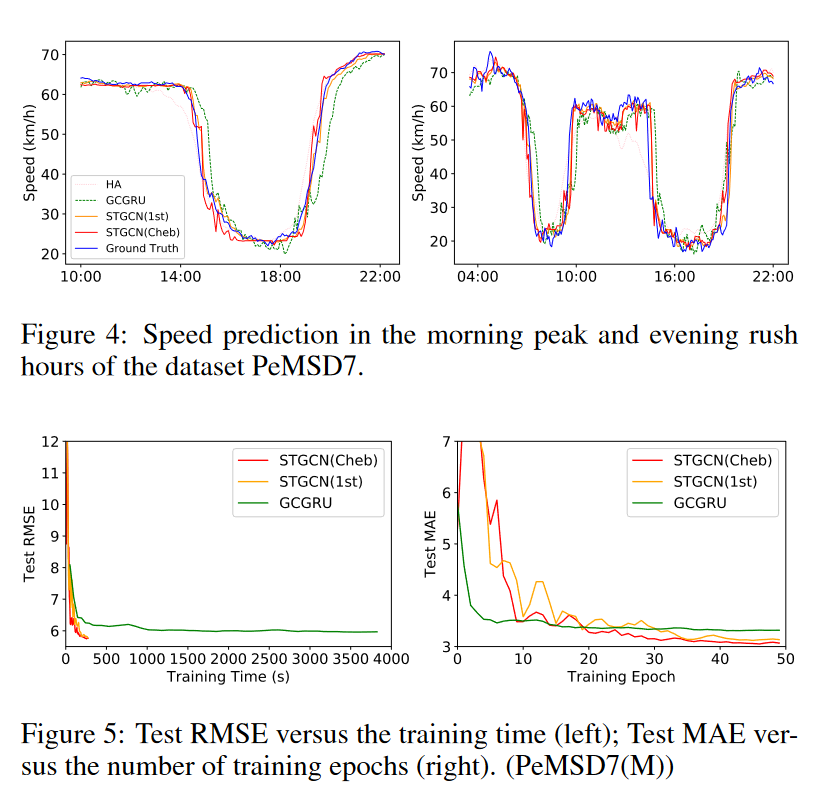
这个GCGRU收敛的好快,感觉效果也还不错,回头拜读一下这篇文章,插一个眼。
实验表明,我们的模型在两个现实世界数据集上优于其他最先进的方法,表明其在从输入探索时空结构方面具有巨大潜力。它还实现了更快的训练、更容易的收敛、更少的参数以及灵活性和可扩展性。这些功能对于学术发展和大规模行业部署来说非常有前景和实用。作者还表明会尝试其他的网络,我觉得这份工作确实很有意思,非常有借鉴和参考价值,当然我是不配评价的哈哈哈,人家3000多引用量呢。
灰灰免责声明
这些都基于菜逼灰灰的阅读理解,因为水平有限可能理解的和原文有出入,这一点希望大家谅解。当然如果你觉得,我有什么点说的不对的地方,请在评论区指出来,灰灰会虚心接受,但是可能你评论的时候我已经忘掉了这篇文章,可能没法与你讨论,但是我相信会有其他人和你讨论的,真理越辩越明,希望我们共探学术高峰,各位共勉!

















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









