









二、Training dynamics
learning rate schedule & hyperparameter optimization
Learning rate schedule
- 优化器optimizer的学习率的选取。

Learning rate decay:一开始lr较大,随着epoch衰减
- Step Learning rate schedule:设置epoch节点decay 学习率。
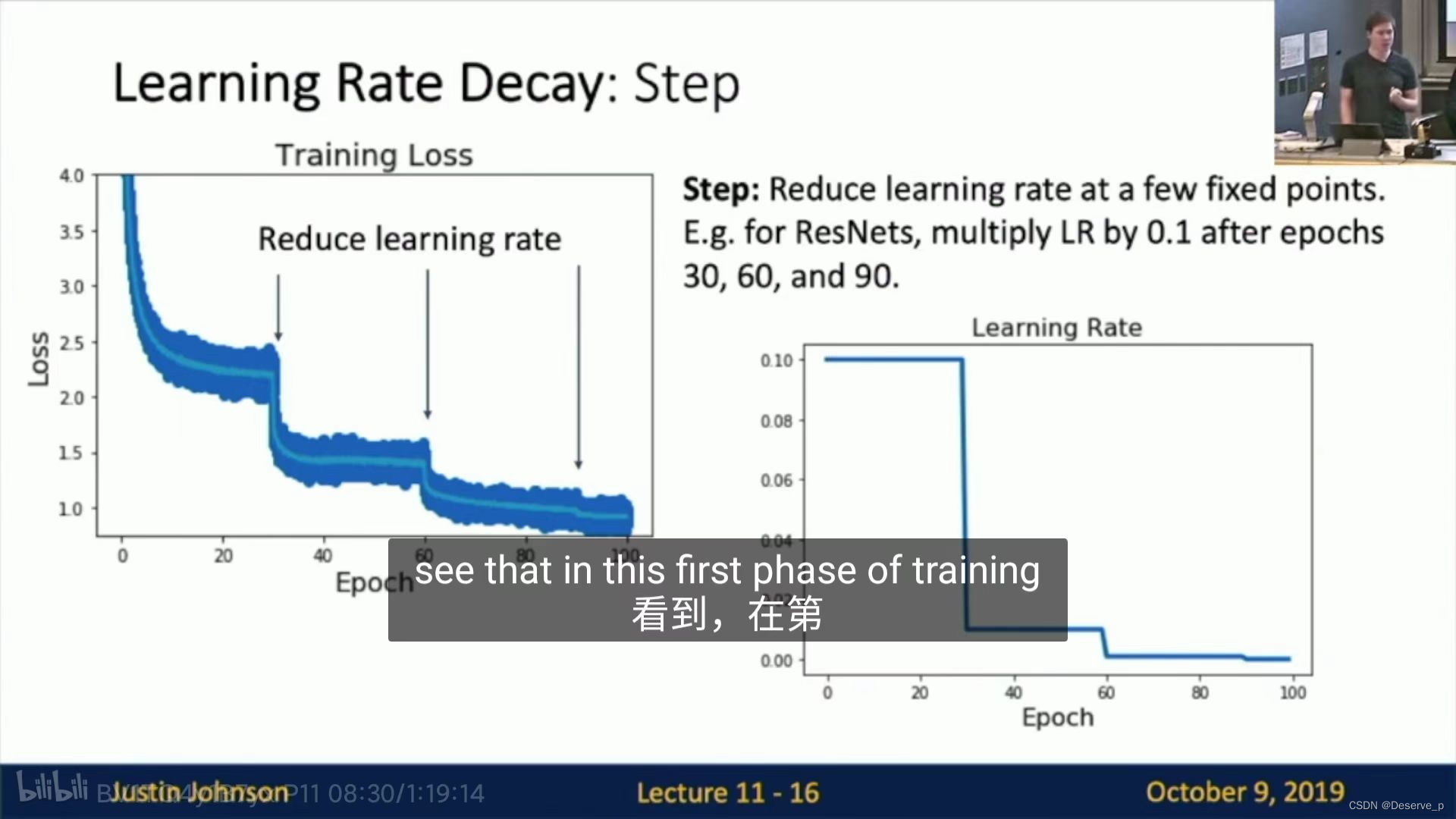
但是需要决定在哪个epoch进行decay和选择多大的新学习率这些超参数。实际中,观察学习曲线,估计在哪个点loss趋于平稳,就在这点改变。
缺点:需要很多次实验
- Cosine learning rate schedule:
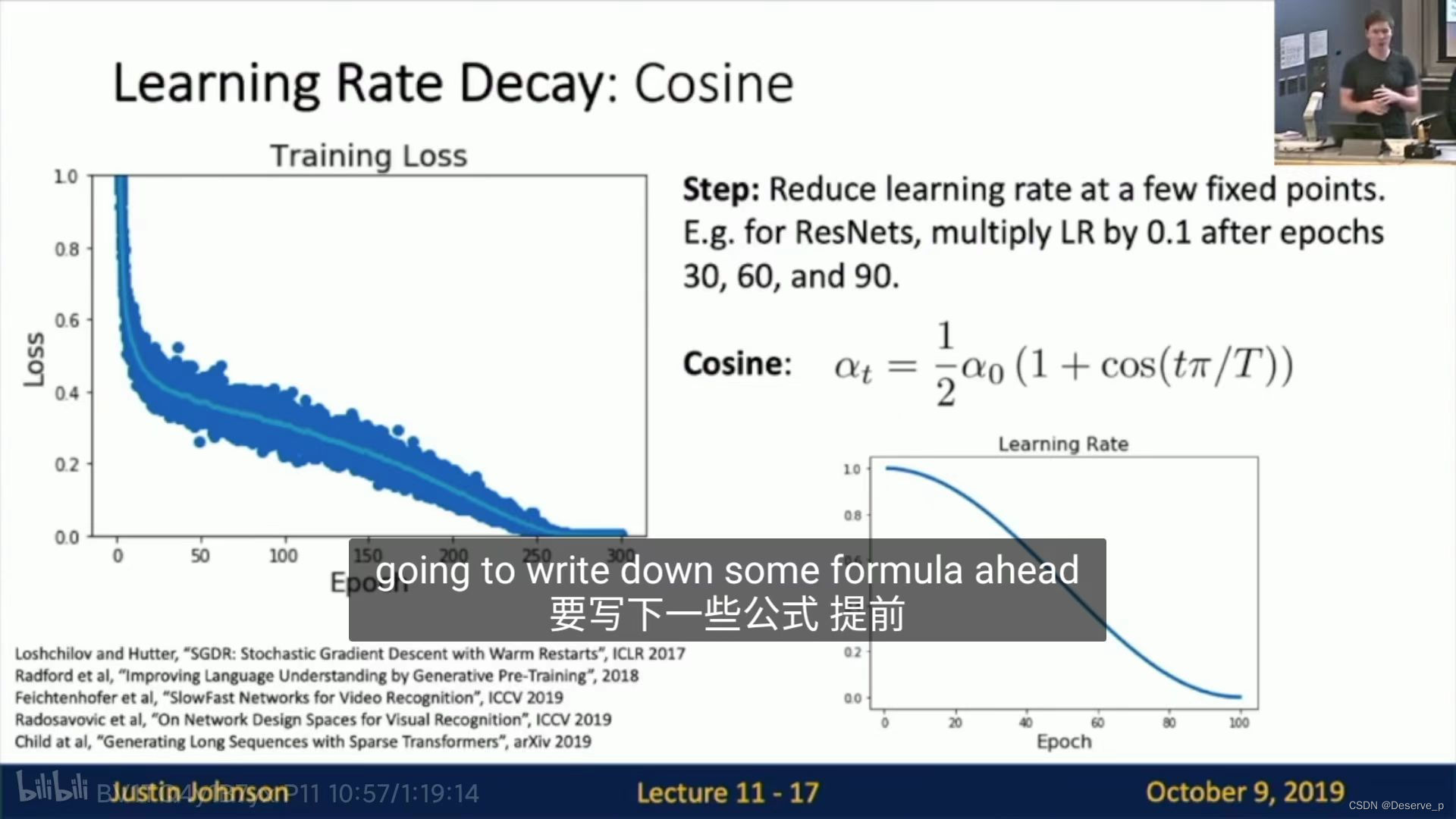
epoch越多,效果越好。
优点:超参数少。
3. Linear

-
Inverse sqrt:

-
Constant
实际建议:
- 不要一开始就用constant以外的。
- 使用SGD+momentum等可以考虑更复杂的,但是RMSProp和Adam等由于复杂度等原因,最好使用constant。
How long to train?
- 选择epoch
- 在整个迭代中,选择loss趋于稳定,并且出现:虽然train acc一直在增加,但是val acc稳定然后减小的那个最大值点的model。

选择超参数:grid search
- 通常在log-线性选择,1e-4, 1e-3等等。
- 随机选比网格搜索更好。
(有相关的研究,hyperparameters search, random search)
- check initial loss:关掉weight decay, 仅迭代一次看看模型的loss趋势是否正确。
- overfit a small sample:使用部分数据集在5~10个epoch内训练,实现过拟合。为的是验证模型代码没有错,如果不能过拟合,说明有问题,在更大的数据上也无法拟合。
- find lr that makes loss go down:使用所有的数据,找到最好的learning rate,在100个epoch内实现loss显著下降。
- coarse grid,train for 1~5 epoch:设置lr和weight decay组合,在1-5个epoch 内在所有数据集上训练找到最佳组合。(建议weight decay 0 1e-4 1e-5)
- refine grid, train longer:从4中选出的模型,不加learning rate decay进行10—20epoch迭代,
- 观察得到的curve
- 回到第5步
loss
情况1:初始化不好,调整初始化。

情况2:加入learning rate decay
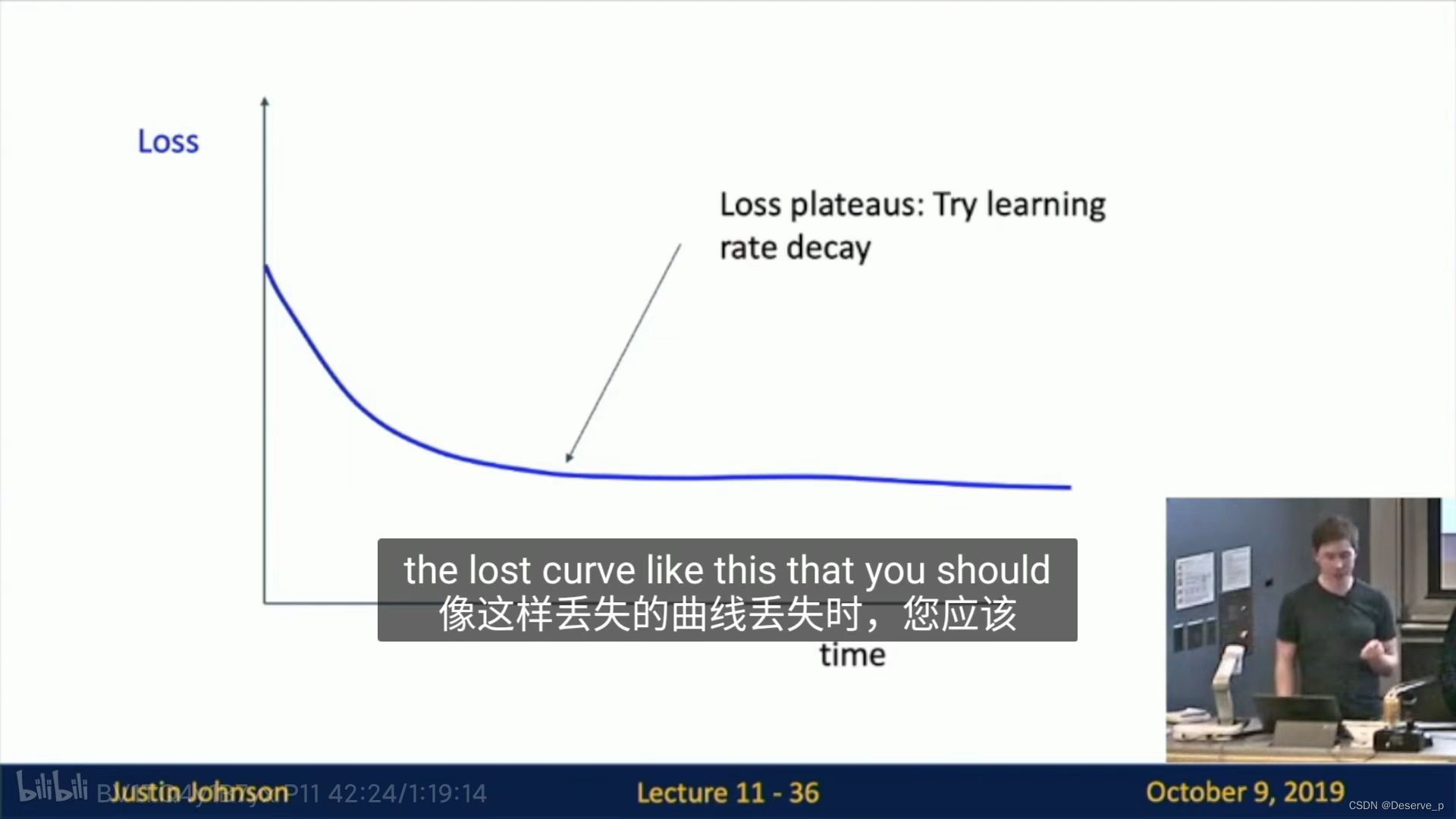
情况3:引入learning rate decay太早了。
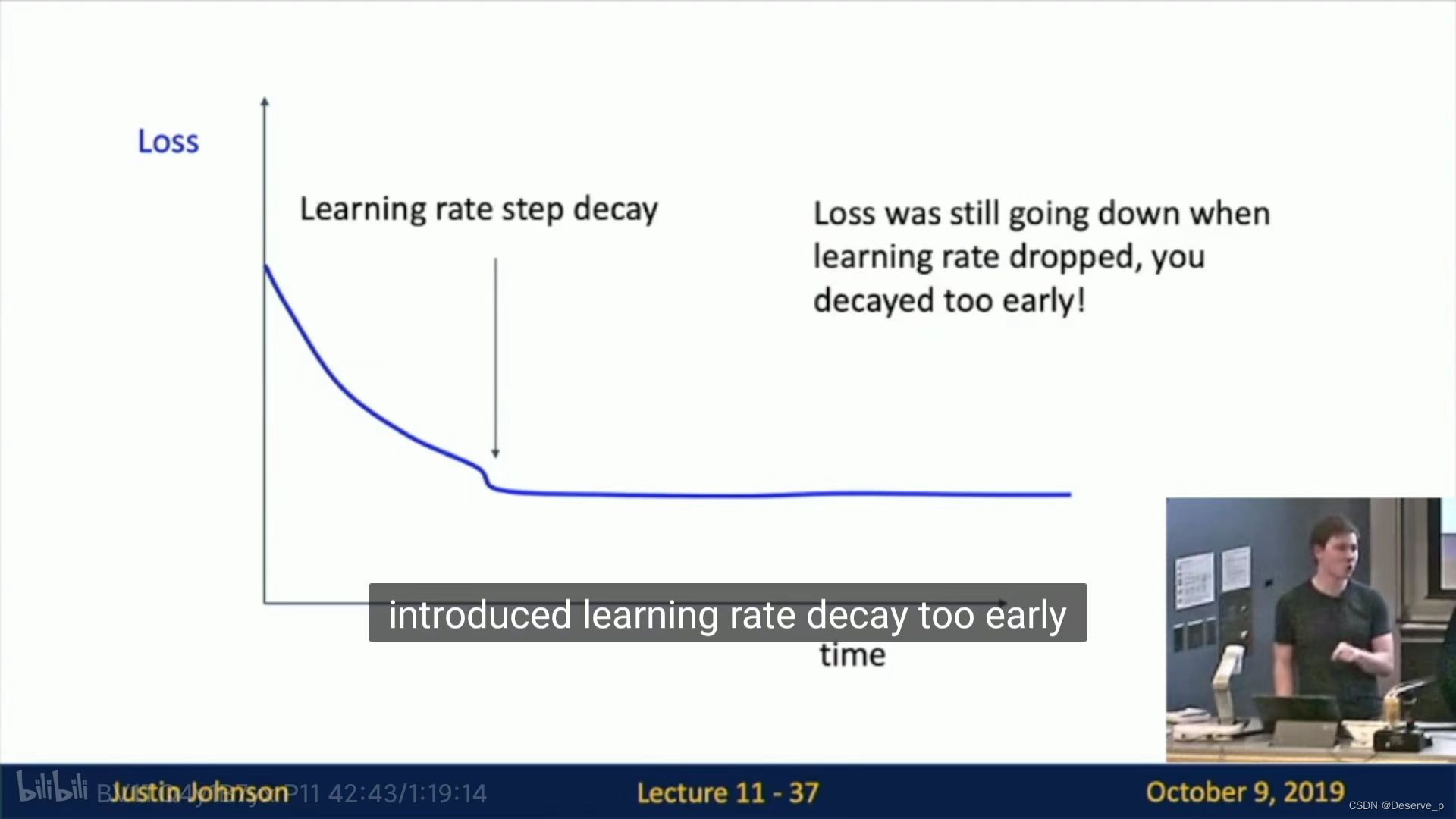
train_val
正常情况:
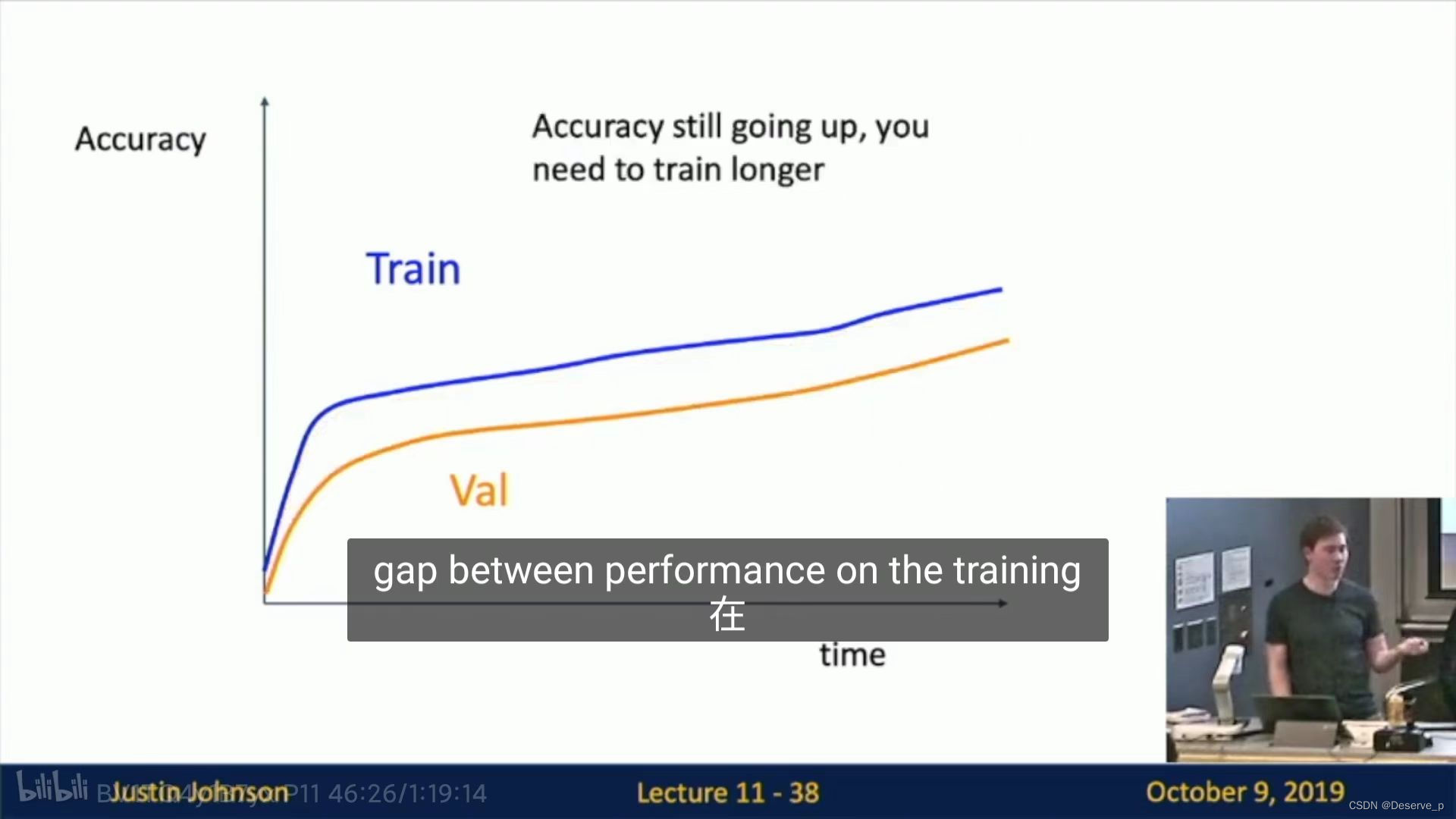
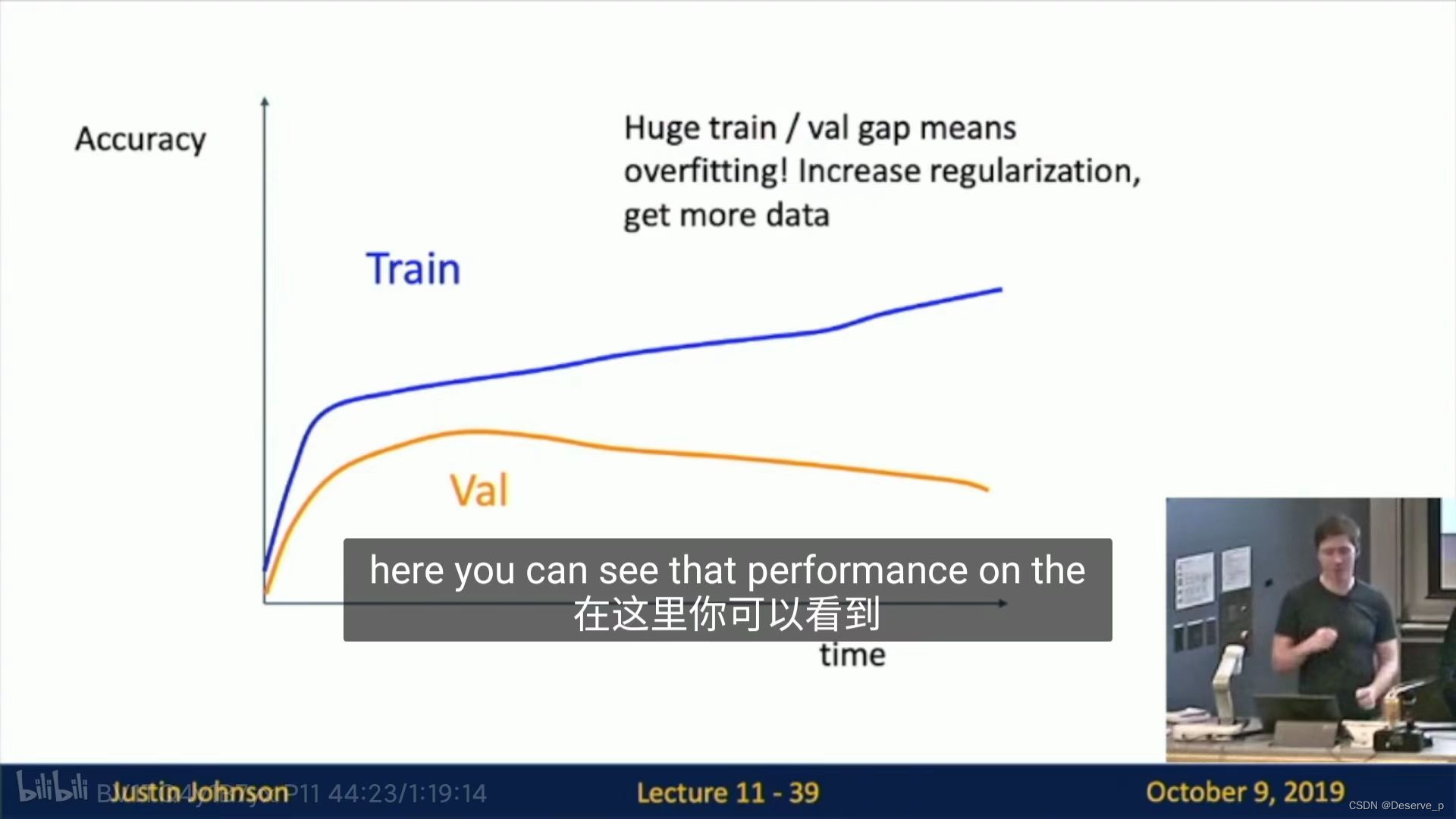
情况:过拟合,减小模型容量,或增大数据集
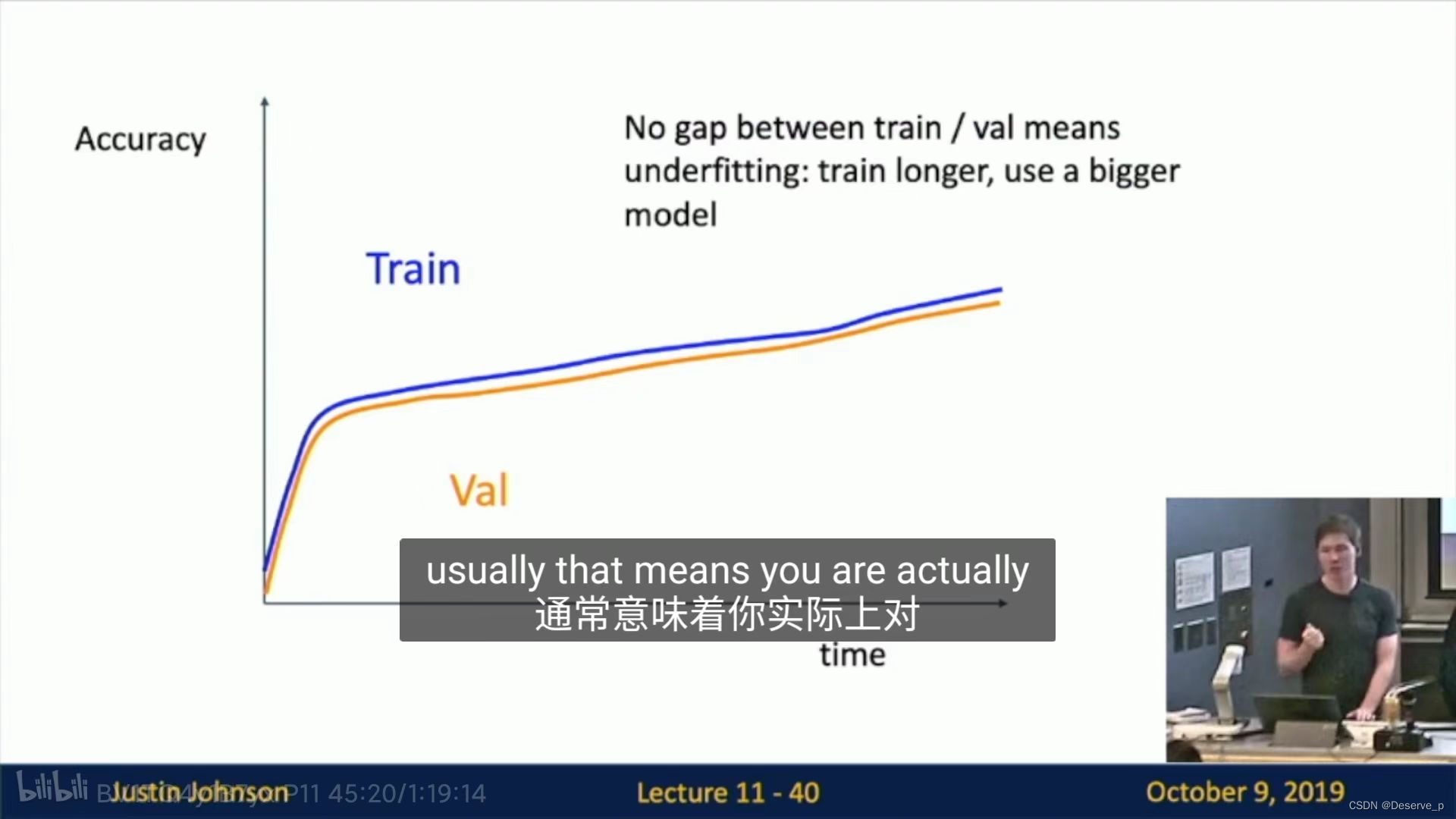
情况:两曲线几乎相同——欠拟合,用更大数据集或训练更久。
其他技巧:
-
使用cross-validation来调参:

-
观察weight更新的范围来看模型是否正常















 4805
4805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









