






An Easy-to-use Instruction Processing Framework for Large Language Models
易于使用的大语言模型指令处理框架
摘要:
由于各种指令处理方法之间存在不一致,社区没有标准的开源指令处理框架可供使用,阻碍了进一步开发和推进;因而提出一个易于使用的LLM指令处理框架,它将指令生成、选择和提示模块化便于开发者进行开发
介绍
-
LLM指令微调被提出,但人工构建数据耗时耗力;
-
LLM用来辅助大规模指令微调数据集生成会受到多样性、复杂性影响,导致数据分布不平衡或质量差;
-
指令处理开源工具依旧很少且大部分都是为了特定任务进行定制的,很少有系统性、通用的工具;
-
因而提出easyInstruct
-
给定一些现有的聊天数据、语料库或知识图谱,EasyInstruct 可以处理指令生成、选择和提示过程,同时还考虑它们的组合和交互。
-
方法
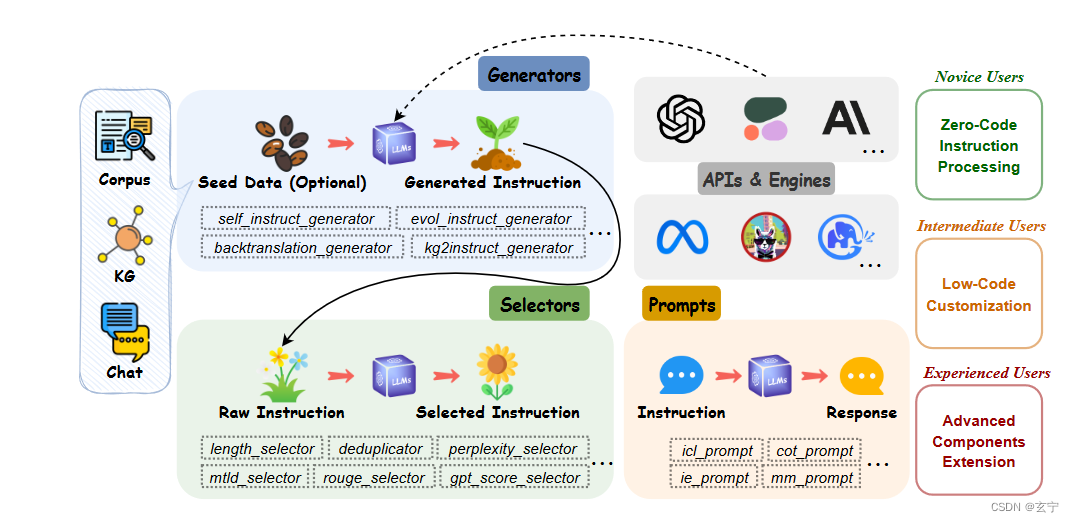
-
API模块与主流LLM集成(右上角)
-
简化指令生成过程,实现基于种子数据的指令数据的自动生成,其中种子数据可以来自聊天数据、语料库或知识图
-
-
生成器 (左上角)
-
-
chat
-
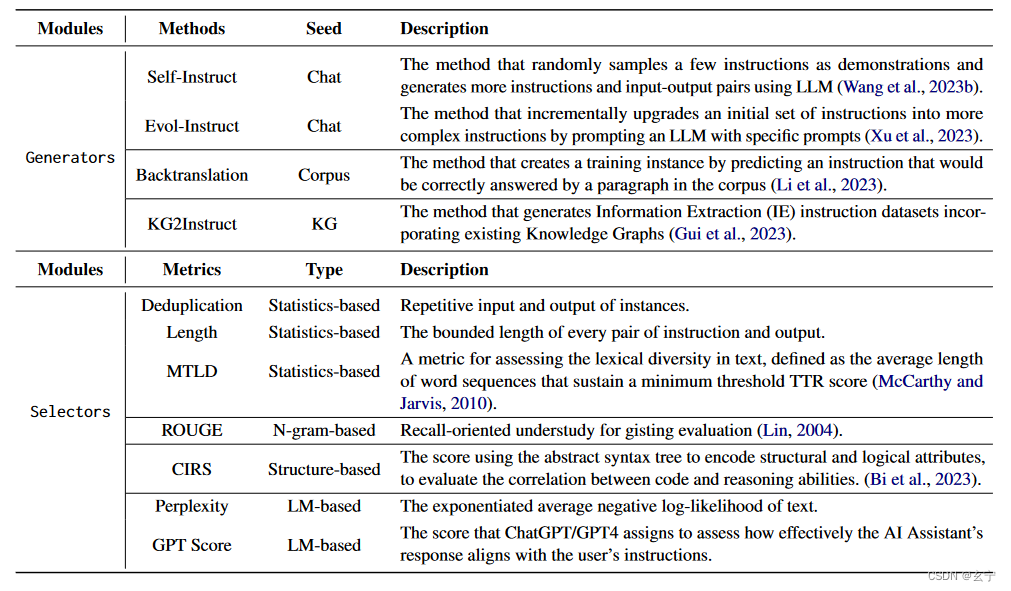
Evol-Instruct:向 LLM 提供特定提示,逐步将其升级为更复杂的指令
-
self-instruct:人工注释的种子任务池中随机抽取一些指令作为演示,然后提示LLM生成更多指令和相应的输入输出对
-
Corpus
-
通过预测文档或语料库中的段落将正确回答的指令来创建训练实例后的指令
-
-
KG
-
基于人工制作的指令模板的随机采样方法
-
-
-
选择器(左下角)
-
简化选择指令的过程,能够根据原始指令数据管理指令数据集
-
基于统计、基于n-gram、基于结构和基于LM四个指标进行选择
-
-
提示(右下角)
-
标准化指令提示步骤,将用户请求构造为指令提示,发送给LLM获得响应。
-
-
Zero-Code Instruction Processing
-
无需编码,利用预定义配置和脚本执行
-
-
Low-Code Customization
-
低代码自定义流程输入输出
-
-
Advanced Components Extension
-
高级组件扩展,继承模块的基类并根据自己的要求重写必要的方法
-
实验评估
-
实验设置
-
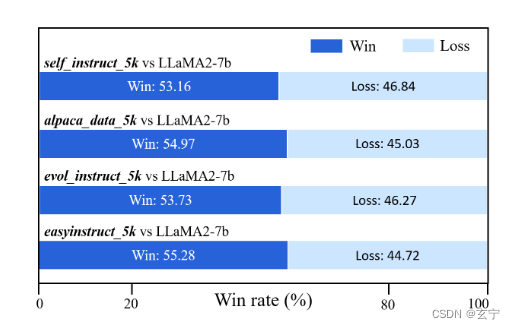
(a)self_instruct_5k:Self-Instruct方法从text-davinci003中提取指令数据而构建的
-
(b) alpaca_data_5k : Alpaca 数据集中随机采样的;
-
(c) evol_instruct_5k:Evol-Instruct方法构建;
-
(d) easyinstruct_5k:通过整合上述三个指令数据集并在EasyInstruct中应用多个Selector来提取高质量的指令数据集来收集的
-
选用LLaMA2 (7B) 模型、lora微调、chatgpt评估
-
-
所有设置的胜率指标都有所改进
-
easyinstruct_5k 设置下表现最佳,表明指令选择策略的重要性
-
针对该数据集做case study发现选取的指令语言流畅、逻辑严谨
-
结论
-
EasyInstruct可以将聊天数据、语料库、KG和LLM结合起来作为自动化指令生成工具,降低人工数据标注的成本
-
EasyInstruct集成了一套指令选择工具,优化指令数据的多样性和分布,从而提高微调数据的质量
-
EasyInstruct易于扩展
阅读评价:
总体来讲就是介绍了一个指令使用框架,打开了一个新的思路















 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









