







该文档由天津大学自然语言处理实验室撰写,深度解读了大语言模型的发展及 DeepSeek 的技术原理、效应和未来展望,旨在剖析其在大语言模型领域的创新与影响。
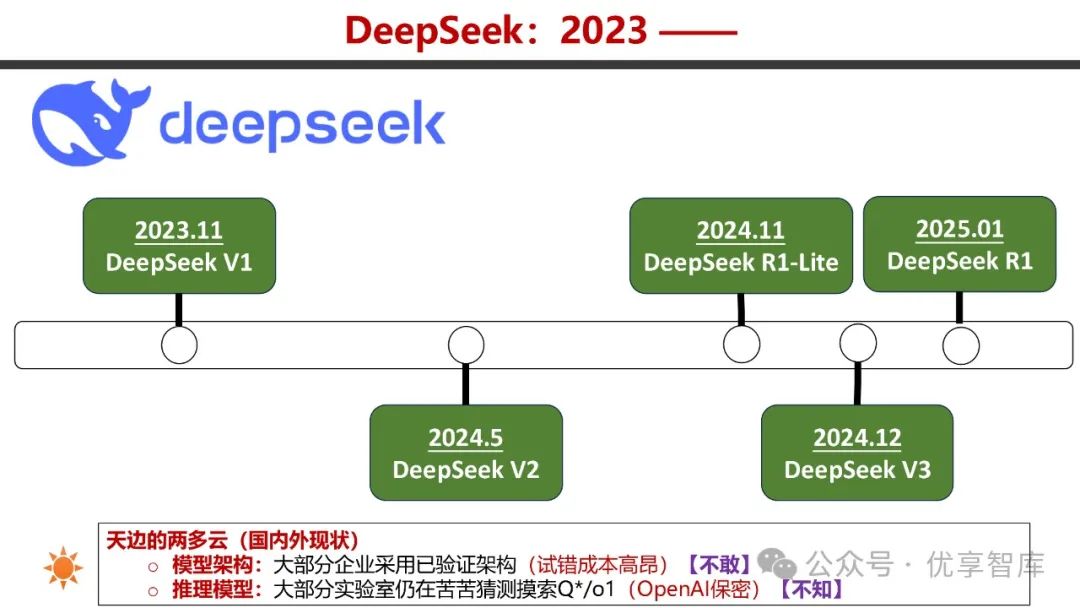
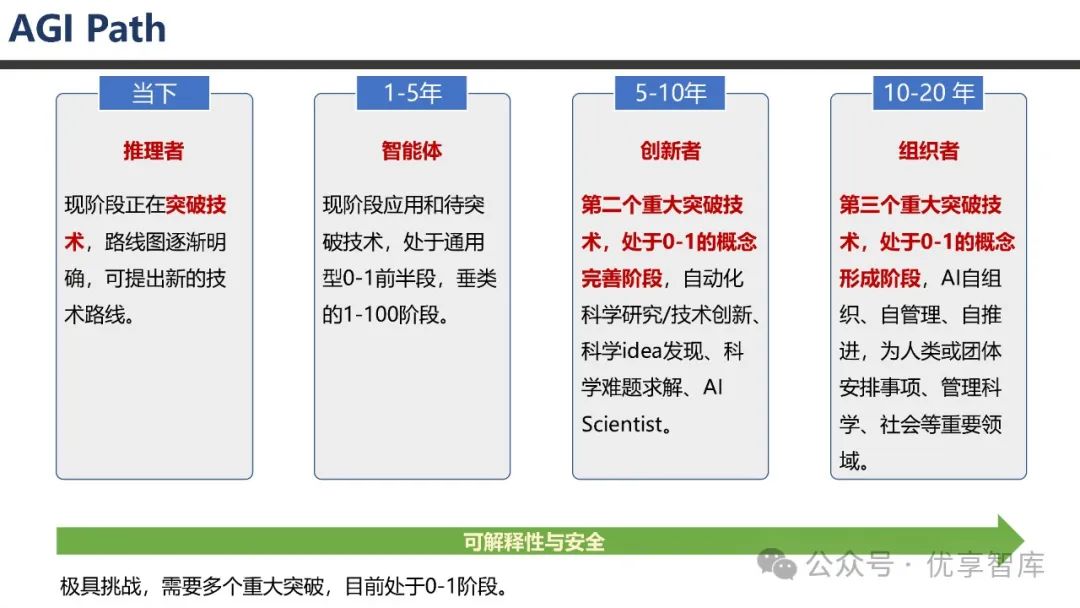
- 大语言模型发展路线图
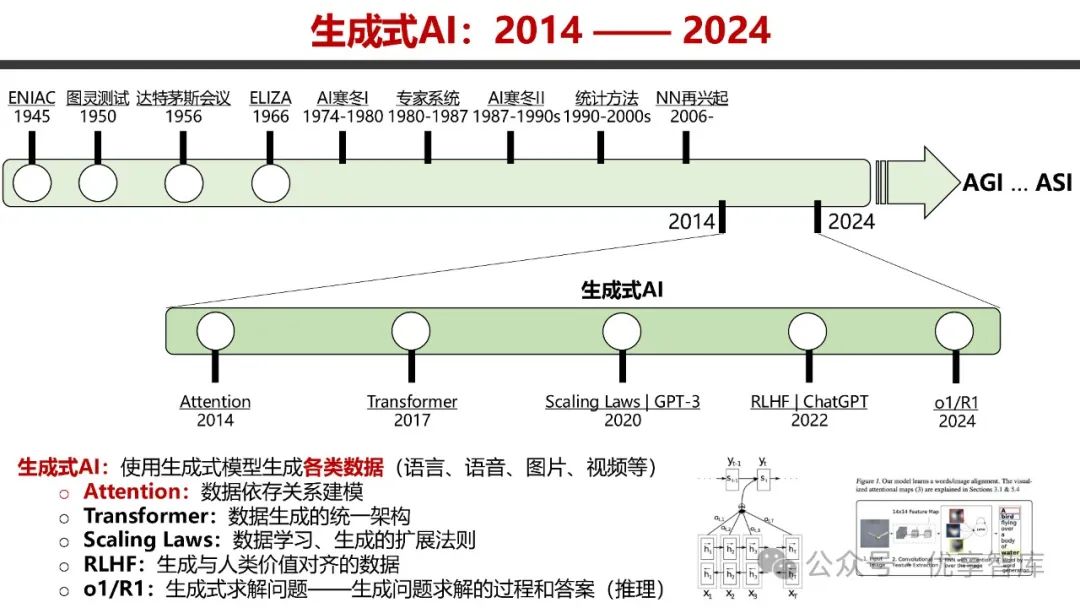
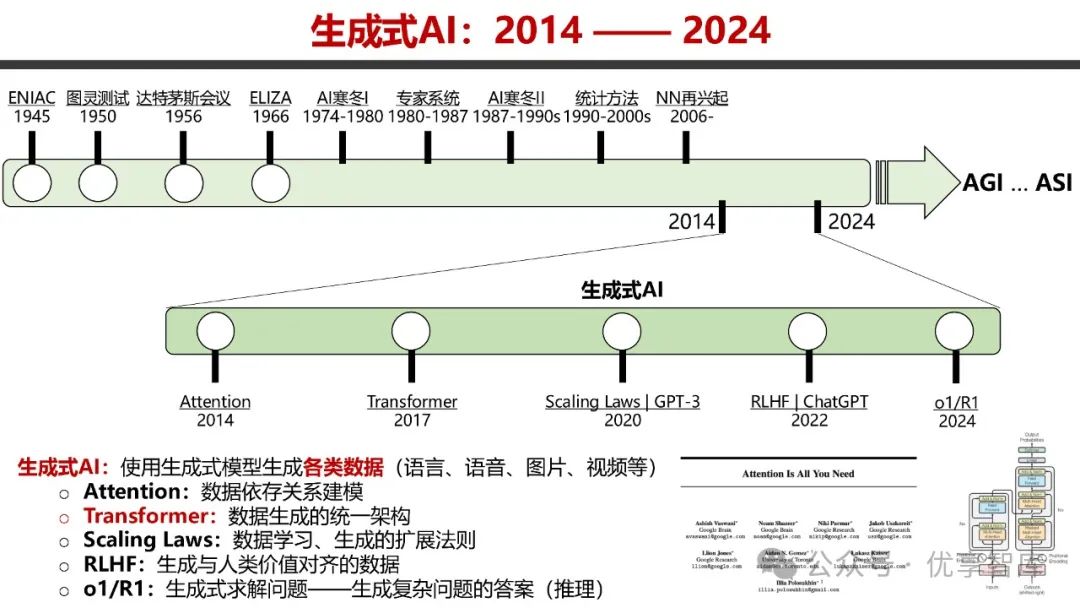
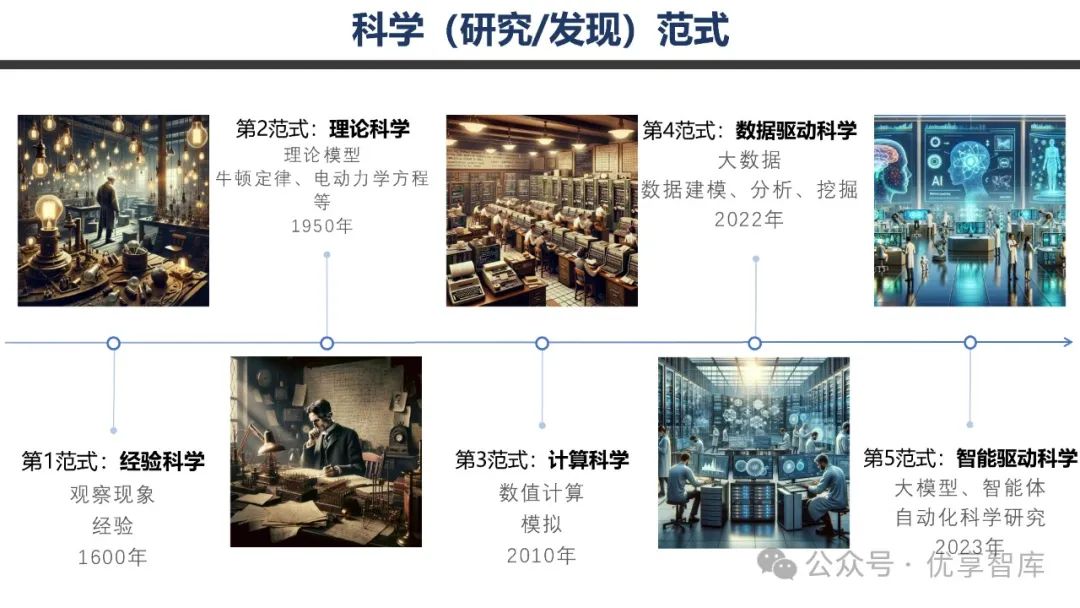
- 生成式 AI 发展历程
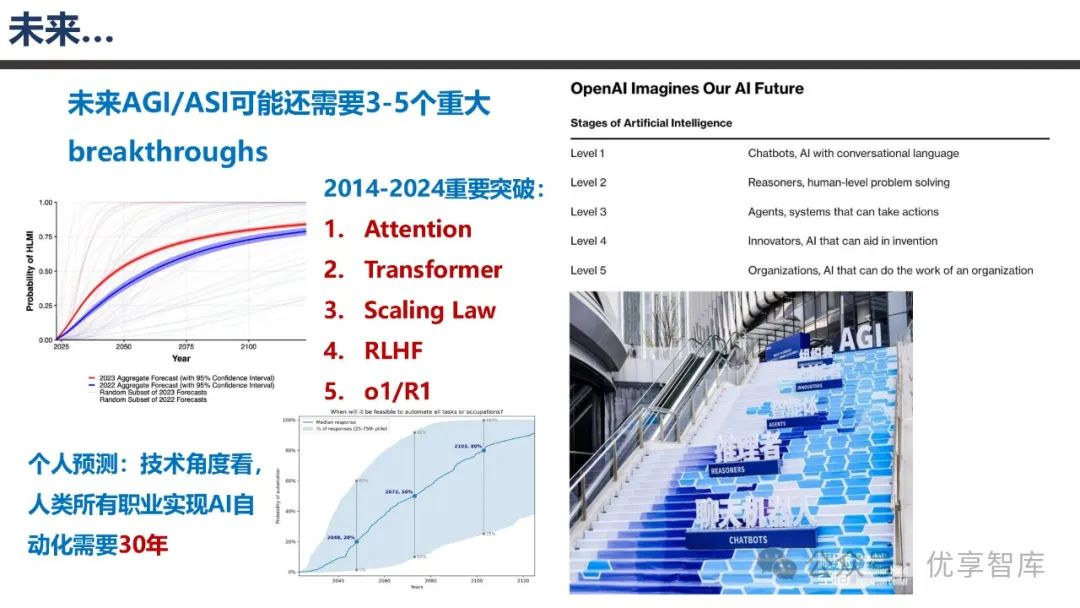
:生成式 AI 自 2014 - 2024 年不断演进,关键技术包括 Attention、Transformer、Scaling Laws、RLHF 等。Attention 用于数据依存关系建模,Transformer 成为数据生成统一架构,Scaling Laws 揭示数据学习与生成的扩展法则,RLHF 使生成数据与人类价值对齐。
- 语言模型与大语言模型发展
:语言模型旨在对自然语言进行统计建模,预测句子中的下一个单词;大语言模型自 2018 年起发展迅速,技术栈涵盖模型训练、评测、应用部署等多个环节,其训练范式包括预训练、后训练,注重性能与成本的平衡。
- 生成式 AI 发展历程
- DeepSeek V2 - V3/R1 技术原理
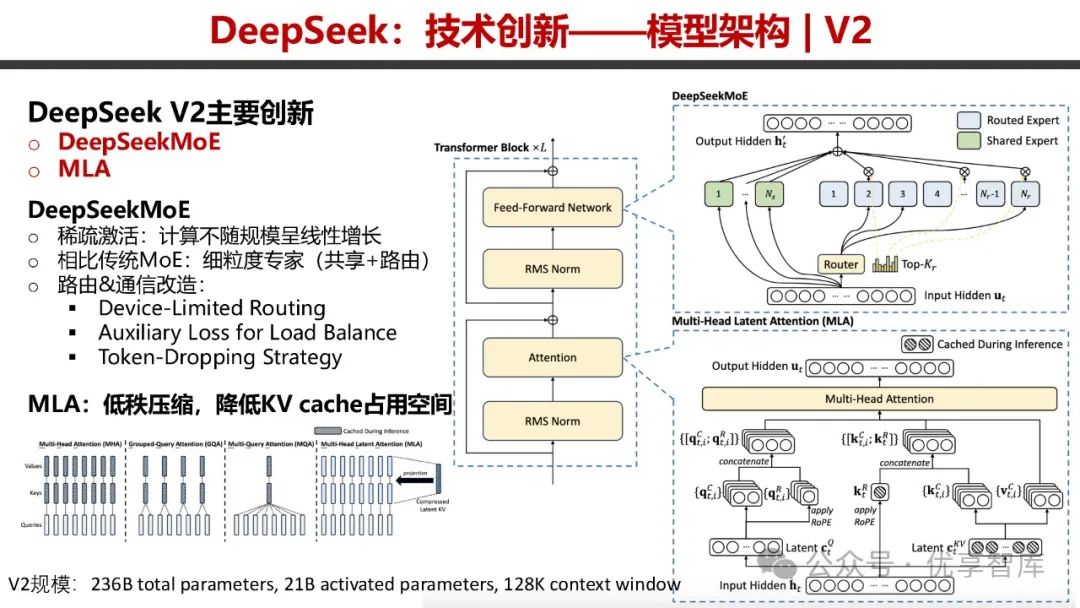
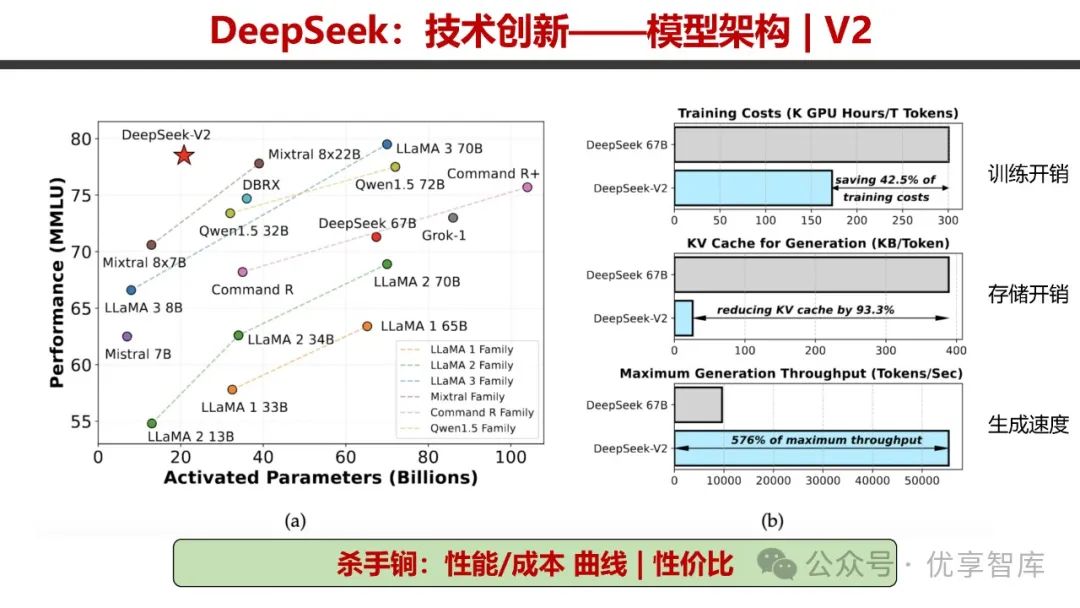
- DeepSeek V2
:创新点包括 DeepSeekMoE 和 MLA。DeepSeekMoE 采用稀疏激活技术,计算量不随规模线性增长,具备细粒度专家共享与路由机制,并对路由和通信进行改造;MLA 通过低秩压缩降低 KV cache 占用空间。在训练开销、存储开销和生成速度方面表现出色,性价比高。
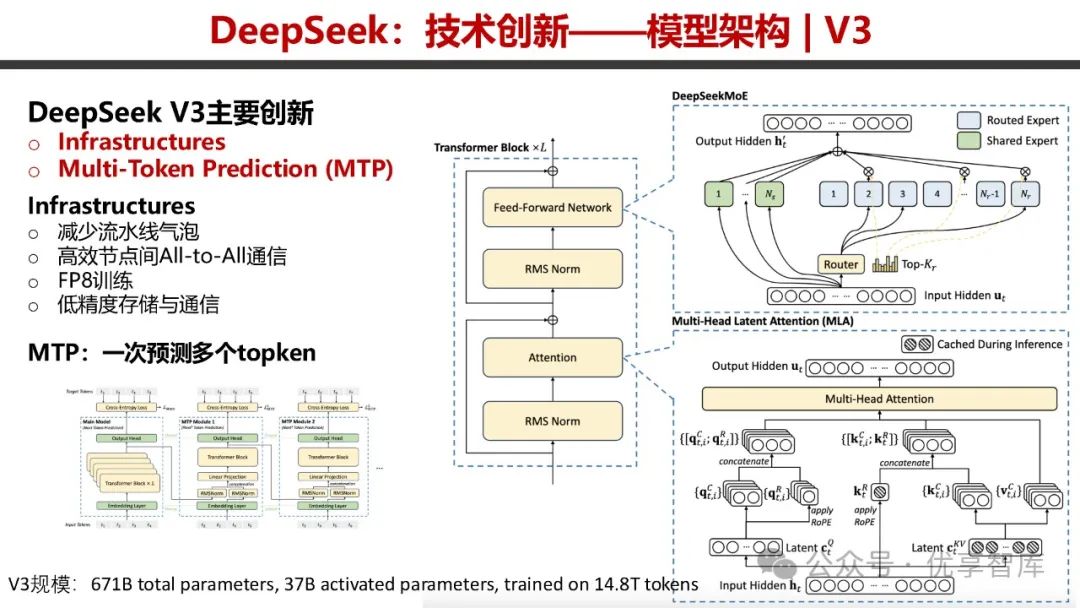
- DeepSeek V3
:创新体现在 Infrastructures 和 Multi - Token Prediction(MTP)。通过减少流水线气泡、实现高效节点间 All - to - All 通信、采用 FP8 训练以及低精度存储与通信,提升了性能。MTP 可一次预测多个 token,在性能 / 成本曲线方面优势明显,训练成本相对较低。
- DeepSeek R1
:主要创新有 DeepSeek - R1 - Zero 大规模 RL 训练,发现 RL 训练的 Scaling Laws,推理模型训练技术框架(4 步法)将推理与对齐合为一体,强化学习训练框架 GRPO 降低训练成本,推理模型蒸馏将大模型推理能力蒸馏到小模型。R1 - Zero 训练规模大,能涌现出搜索、反思等能力,R1 在逻辑推理性能上表现优异,且开源发布打破了技术护城河。
- DeepSeek V2
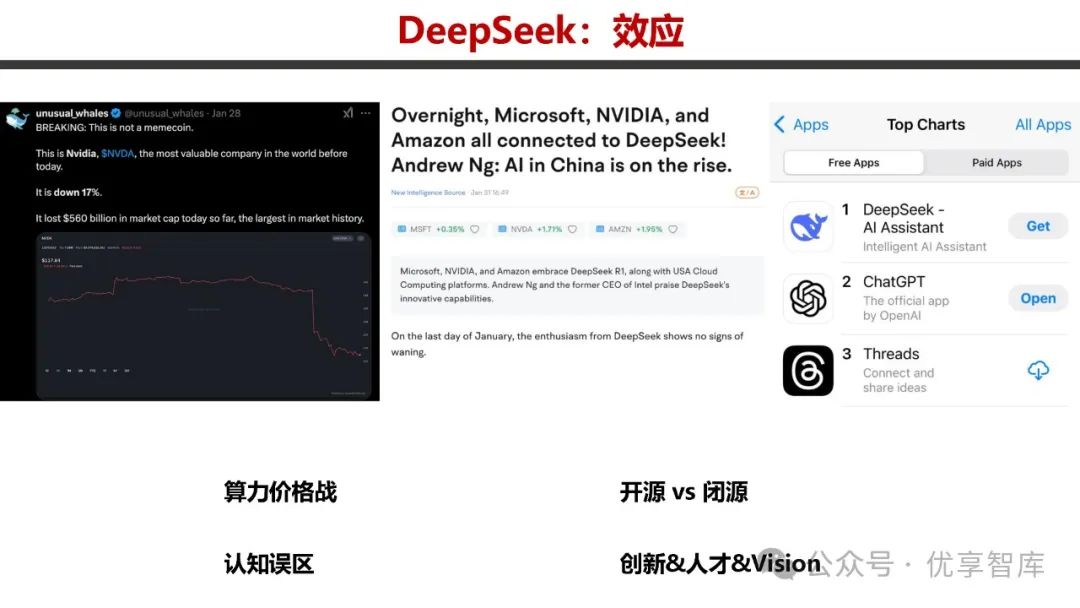
- DeepSeek 效应
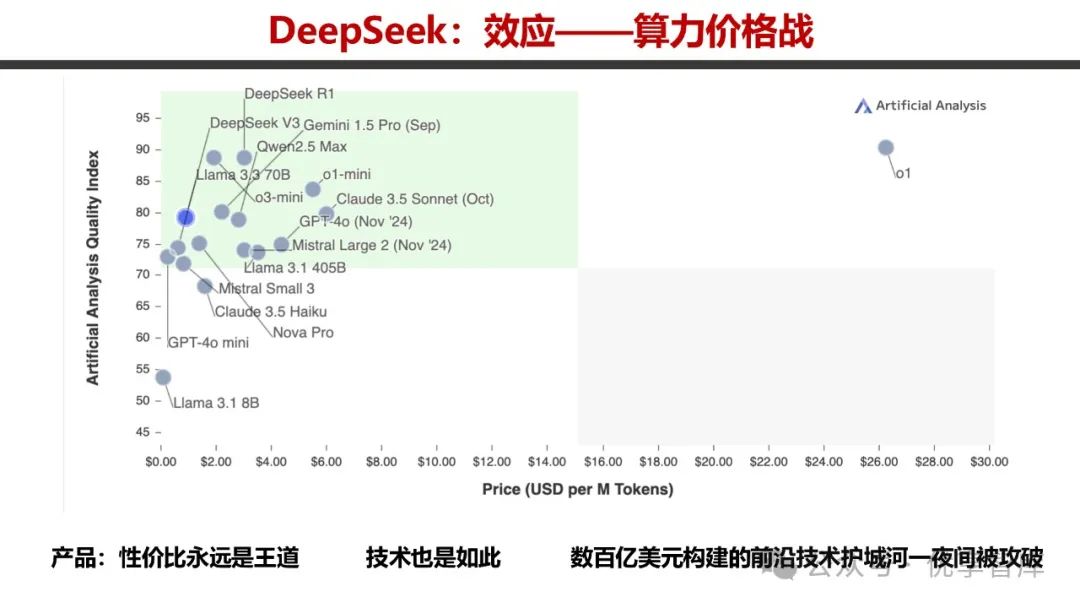
- 算力价格战
:DeepSeek 凭借高性价比冲击了市场,其 V3 和 R1 在性能 / 成本曲线方面表现突出,打破了数百亿美元构建的前沿技术护城河,引发了算力价格竞争。
- 开源 vs 闭源
:R1 的开源发布是大模型开源史上的里程碑,打破了美国 AI 第一梯队企业的技术封闭,开源与闭源之争不仅涉及技术公开性,还关乎 AI 安全治理。
- 认知误区
:DeepSeek 颠覆了美国人对中国 AI 水平的认知,改变了人们对大模型研发成本的看法,表明中国在大模型领域具备强大的创新能力。
- 创新 & 人才 & Vision
:大模型发展存在同质化竞争,底层技术原创性突破不足。DeepSeek 的成功得益于众多技术型人才的创新以及合理的人才管理。中国若要在 AI 领域取得更大突破,需要更多企业、高校和研究机构开展 0 - 1 创新,培养战略型和技术型人才。
- 算力价格战
- 未来展望
:未来实现 AGI/ASI 可能还需 3 - 5 个重大突破,目前处于技术突破和路线明确的阶段。DeepSeek 具有快速迭代推理大模型的优势,R2 可能很快发布。但 R1 在安全性方面存在一定问题,尤其是危险目标和情景意识方面,未来需要在推理能力提升的同时,加强模型安全性研究,探索推理与安全结合的创新解决方案。





700余份DEEPSEEK、大模型、AIGC、AI人工智能、ChatGPT报告、白皮书及行业应用方案获取方式





















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











