







CGNet
CGNet(Context Guided Network)是一种轻量级的神经网络架构,特别适用于图像语义分割任务。
创新点
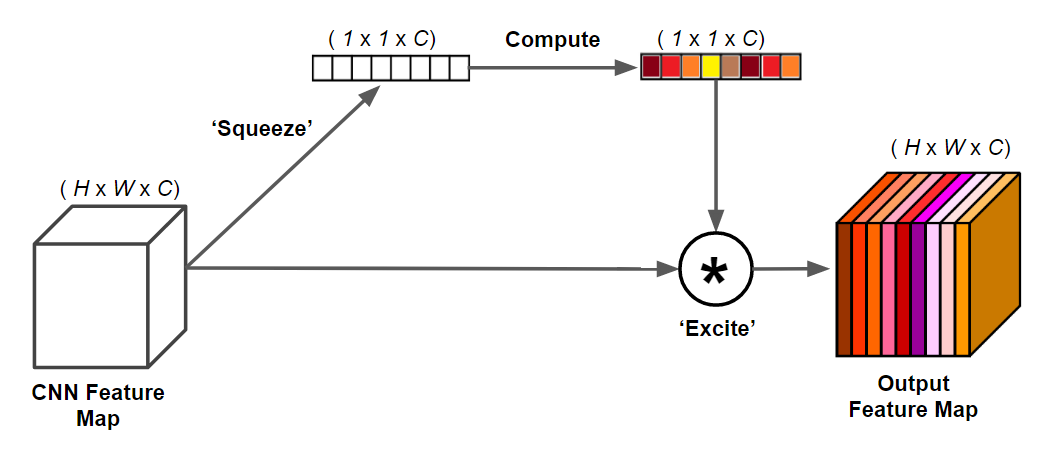
提出了一个轻量型模型 CGNet,主要由 CG 模块组成。 CG 模块中
提取器用于提取局部特征,
提取器用于提取周围上下文特征,
提取器用于提取联合特征,
提取器用于提取全局上下文特征。  CG Block如图所示,floc 和 fsur 采用 通道卷积(Channel-wise Convolutions) 减少参数量。 首先将特征图经过 1x1 卷积然后分别输入到
和
提取器中;
提取器提取局部特征,使用 3x3 的普通卷积,
提取器提取周围上下文特征,使用3x3的扩张卷积;
提取器提取联合特征,将
和
的输出进行 Concat 操作,再进行 Batch Normalization (BN) 和 Parametric ReLU (PReLU) ;
提取器用提取全局上下文特征,将输入进行全局平均池化(GAP)和多层感知机,将得到的权重和输入按元素相乘。
CG Block如图所示,floc 和 fsur 采用 通道卷积(Channel-wise Convolutions) 减少参数量。 首先将特征图经过 1x1 卷积然后分别输入到
和
提取器中;
提取器提取局部特征,使用 3x3 的普通卷积,
提取器提取周围上下文特征,使用3x3的扩张卷积;
提取器提取联合特征,将
和
的输出进行 Concat 操作,再进行 Batch Normalization (BN) 和 Parametric ReLU (PReLU) ;
提取器用提取全局上下文特征,将输入进行全局平均池化(GAP)和多层感知机,将得到的权重和输入按元素相乘。 
整体结构
CGNet 如图所示。为减少参数量 CGNet 分为 3 个阶段,仅对输入图像分别进行1/2、1/4、1/8的下采样。每个阶段的第一层输入是来自上一个阶段的第一层和最后一层的输出组合,有助于特征重用并加强了特征传播。 Stage1 由三个 3x3 普通卷积组成; Stage2 由 M 个 CG Block 组成; Stage3 由 N 个 CG Block 组成; 最后是 1x1 卷积,上采样(Upsample),输出分割结果。 
数据集
本次使用的数据集介绍参考之前的文章如何制作马萨诸塞州道路遥感数据集
网络结构
###########################################################################
# Created by: Tianyi Wu
# Email: wutianyi@ict.ac.cn
# Copyright (c) 2018
###########################################################################
import torch
import torch.nn as nn
import torch.nn.functional as F
__all__ = ["Context_Guided_Network"]
# Filter out variables, functions, and classes that other programs don't need or don't want when running cmd "from CGNet import *"
class ConvBNPReLU(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1):
"""
args:
nIn: number of input channels
nOut: number of output channels
kSize: kernel size
stride: stride rate for down-sampling. Default is 1
"""
super().__init__()
padding = int((kSize - 1) / 2)
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), bias=False)
self.bn = nn.BatchNorm2d(nOut, eps=1e-03)
self.act = nn.PReLU(nOut)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
output = self.bn(output)
output = self.act(output)
return output
class BNPReLU(nn.Module):
def __init__(self, nOut):
"""
args:
nOut: channels of output feature maps
"""
super().__init__()
self.bn = nn.BatchNorm2d(nOut, eps=1e-03)
self.act = nn.PReLU(nOut)
def forward(self, input):
"""
args:
input: input feature map
return: normalized and thresholded feature map
"""
output = self.bn(input)
output = self.act(output)
return output
class ConvBN(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1):
"""
args:
nIn: number of input channels
nOut: number of output channels
kSize: kernel size
stride: optinal stide for down-sampling
"""
super().__init__()
padding = int((kSize - 1) / 2)
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), bias=False)
self.bn = nn.BatchNorm2d(nOut, eps=1e-03)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
output = self.bn(output)
return output
class Conv(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1):
"""
args:
nIn: number of input channels
nOut: number of output channels
kSize: kernel size
stride: optional stride rate for down-sampling
"""
super().__init__()
padding = int((kSize - 1) / 2)
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), bias=False)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
return output
class ChannelWiseConv(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1):
"""
Args:
nIn: number of input channels
nOut: number of output channels, default (nIn == nOut)
kSize: kernel size
stride: optional stride rate for down-sampling
"""
super().__init__()
padding = int((kSize - 1) / 2)
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), groups=nIn,
bias=False)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
return output
class DilatedConv(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1, d=1):
"""
args:
nIn: number of input channels
nOut: number of output channels
kSize: kernel size
stride: optional stride rate for down-sampling
d: dilation rate
"""
super().__init__()
padding = int((kSize - 1) / 2) * d
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), bias=False,
dilation=d)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
return output
class ChannelWiseDilatedConv(nn.Module):
def __init__(self, nIn, nOut, kSize, stride=1, d=1):
"""
args:
nIn: number of input channels
nOut: number of output channels, default (nIn == nOut)
kSize: kernel size
stride: optional stride rate for down-sampling
d: dilation rate
"""
super().__init__()
padding = int((kSize - 1) / 2) * d
self.conv = nn.Conv2d(nIn, nOut, (kSize, kSize), stride=stride, padding=(padding, padding), groups=nIn,
bias=False, dilation=d)
def forward(self, input):
"""
args:
input: input feature map
return: transformed feature map
"""
output = self.conv(input)
return output
class FGlo(nn.Module):
"""
the FGlo class is employed to refine the joint feature of both local feature and surrounding context.
"""
def __init__(self, channel, reduction=16):
super(FGlo, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class ContextGuidedBlock_Down(nn.Module):
"""
the size of feature map divided 2, (H,W,C)---->(H/2, W/2, 2C)
"""
def __init__(self, nIn, nOut, dilation_rate=2, reduction=16):
"""
args:
nIn: the channel of input feature map
nOut: the channel of output feature map, and nOut=2*nIn
"""
super().__init__()
self.conv1x1 = ConvBNPReLU(nIn, nOut, 3, 2) # size/2, channel: nIn--->nOut
self.F_loc = ChannelWiseConv(nOut, nOut, 3, 1)
self.F_sur = ChannelWiseDilatedConv(nOut, nOut, 3, 1, dilation_rate)
self.bn = nn.BatchNorm2d(2 * nOut, eps=1e-3)
self.act = nn.PReLU(2 * nOut)
self.reduce = Conv(2 * nOut, nOut, 1, 1) # reduce dimension: 2*nOut--->nOut
self.F_glo = FGlo(nOut, reduction)
def forward(self, input):
output = self.conv1x1(input)
loc = self.F_loc(output)
sur = self.F_sur(output)
joi_feat = torch.cat([loc, sur], 1) # the joint feature
joi_feat = self.bn(joi_feat)
joi_feat = self.act(joi_feat)
joi_feat = self.reduce(joi_feat) # channel= nOut
output = self.F_glo(joi_feat) # F_glo is employed to refine the joint feature
return output
class ContextGuidedBlock(nn.Module):
def __init__(self, nIn, nOut, dilation_rate=2, reduction=16, add=True):
"""
args:
nIn: number of input channels
nOut: number of output channels,
add: if true, residual learning
"""
super().__init__()
n = int(nOut / 2)
self.conv1x1 = ConvBNPReLU(nIn, n, 1, 1) # 1x1 Conv is employed to reduce the computation
self.F_loc = ChannelWiseConv(n, n, 3, 1) # local feature
self.F_sur = ChannelWiseDilatedConv(n, n, 3, 1, dilation_rate) # surrounding context
self.bn_prelu = BNPReLU(nOut)
self.add = add
self.F_glo = FGlo(nOut, reduction)
def forward(self, input):
output = self.conv1x1(input)
loc = self.F_loc(output)
sur = self.F_sur(output)
joi_feat = torch.cat([loc, sur], 1)
joi_feat = self.bn_prelu(joi_feat)
output = self.F_glo(joi_feat) # F_glo is employed to refine the joint feature
# if residual version
if self.add:
output = input + output
return output
class InputInjection(nn.Module):
def __init__(self, downsamplingRatio):
super().__init__()
self.pool = nn.ModuleList()
for i in range(0, downsamplingRatio):
self.pool.append(nn.AvgPool2d(3, stride=2, padding=1))
def forward(self, input):
for pool in self.pool:
input = pool(input)
return input
class Context_Guided_Network(nn.Module):
"""
This class defines the proposed Context Guided Network (CGNet) in this work.
"""
def __init__(self, classes=19, M=3, N=21, dropout_flag=False):
"""
args:
classes: number of classes in the dataset. Default is 19 for the cityscapes
M: the number of blocks in stage 2
N: the number of blocks in stage 3
"""
super().__init__()
self.level1_0 = ConvBNPReLU(3, 32, 3, 2) # feature map size divided 2, 1/2
self.level1_1 = ConvBNPReLU(32, 32, 3, 1)
self.level1_2 = ConvBNPReLU(32, 32, 3, 1)
self.sample1 = InputInjection(1) # down-sample for Input Injection, factor=2
self.sample2 = InputInjection(2) # down-sample for Input Injiection, factor=4
self.b1 = BNPReLU(32 + 3)
# stage 2
self.level2_0 = ContextGuidedBlock_Down(32 + 3, 64, dilation_rate=2, reduction=8)
self.level2 = nn.ModuleList()
for i in range(0, M - 1):
self.level2.append(ContextGuidedBlock(64, 64, dilation_rate=2, reduction=8)) # CG block
self.bn_prelu_2 = BNPReLU(128 + 3)
# stage 3
self.level3_0 = ContextGuidedBlock_Down(128 + 3, 128, dilation_rate=4, reduction=16)
self.level3 = nn.ModuleList()
for i in range(0, N - 1):
self.level3.append(ContextGuidedBlock(128, 128, dilation_rate=4, reduction=16)) # CG block
self.bn_prelu_3 = BNPReLU(256)
if dropout_flag:
print("have droput layer")
self.classifier = nn.Sequential(nn.Dropout2d(0.1, False), Conv(256, classes, 1, 1))
else:
self.classifier = nn.Sequential(Conv(256, classes, 1, 1))
# init weights
for m in self.modules():
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('ConvTranspose2d') != -1:
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
m.bias.data.zero_()
def forward(self, input):
"""
args:
input: Receives the input RGB image
return: segmentation map
"""
# stage 1
output0 = self.level1_0(input)
output0 = self.level1_1(output0)
output0 = self.level1_2(output0)
inp1 = self.sample1(input)
inp2 = self.sample2(input)
# stage 2
output0_cat = self.b1(torch.cat([output0, inp1], 1))
output1_0 = self.level2_0(output0_cat) # down-sampled
for i, layer in enumerate(self.level2):
if i == 0:
output1 = layer(output1_0)
else:
output1 = layer(output1)
output1_cat = self.bn_prelu_2(torch.cat([output1, output1_0, inp2], 1))
# stage 3
output2_0 = self.level3_0(output1_cat) # down-sampled
for i, layer in enumerate(self.level3):
if i == 0:
output2 = layer(output2_0)
else:
output2 = layer(output2)
output2_cat = self.bn_prelu_3(torch.cat([output2_0, output2], 1))
# classifier
classifier = self.classifier(output2_cat)
# upsample segmenation map ---> the input image size
out = F.upsample(classifier, input.size()[2:], mode='bilinear',
align_corners=False) # Upsample score map, factor=8
return out
训练loss变化
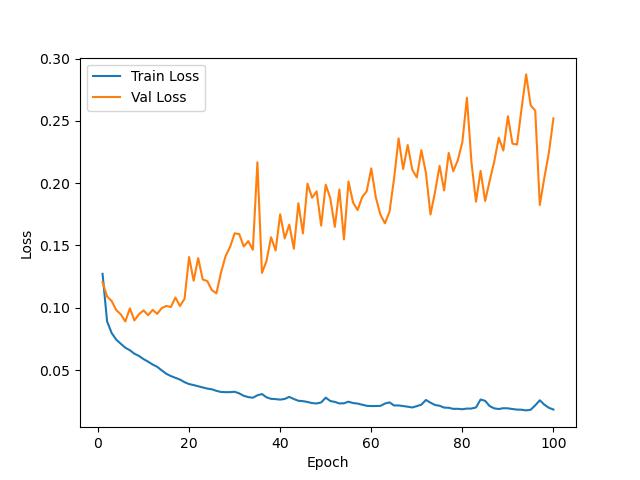
测试精度

结语
完整代码与训练结果请加入我们的星球。
「感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的」。
 加入前不要忘了领取优惠券哦!
加入前不要忘了领取优惠券哦!
往期精彩
本文由 mdnice 多平台发布
















 8304
8304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











