







之前通过debug YOLOv8 源码,了解了如何解析配置文件得到模型(YOLOV8模型配置文件加载解析代码逐行详解_yolov8模型解析-CSDN博客),现在对其如何从数据集配置文件解析出数据集并如何训练进行了细致的代码调试与探索,记录下笔记,大部分内容以截图形式呈现。其中会记录我debug时的探索心路历程,比如为什么debug没有这个模块,要到哪去找。
创建一个名为mytrain.py的文件,并在model.train函数处设置断点以进行调试。
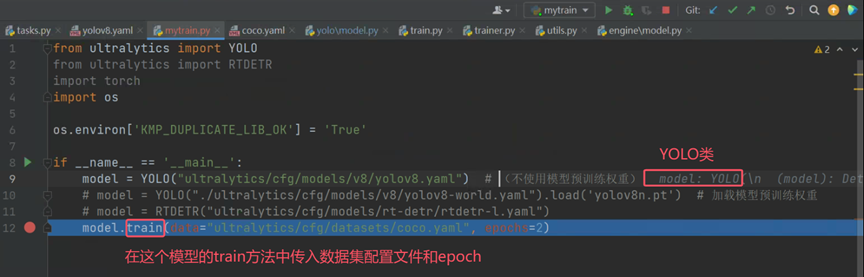
在train方法中,涉及到传入数据集配置文件的方法只有self._smart_load方法。所以数据集的加载和处理可能与这个方法有关。
点击进入_smart_load("trainer")方法,查看其内部结构。
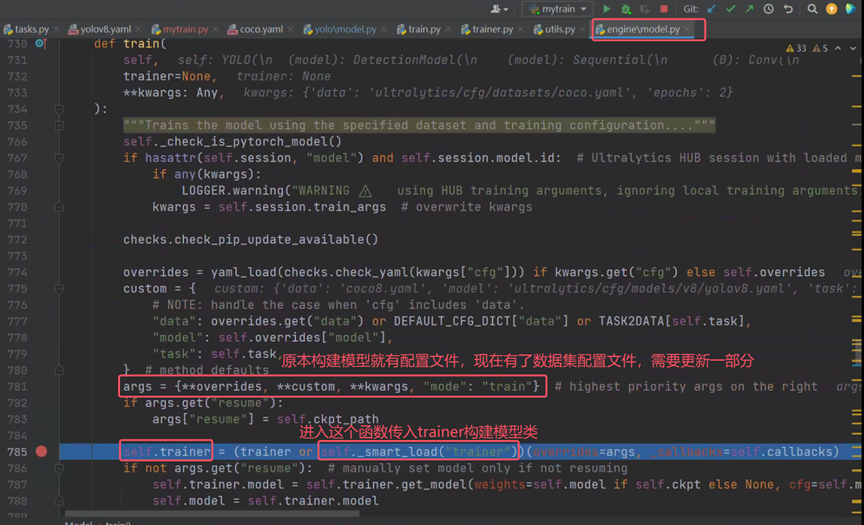
查找子类中的self.task_map定义
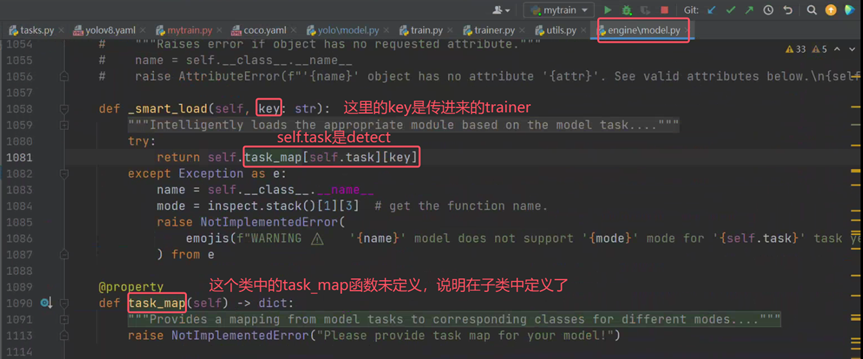
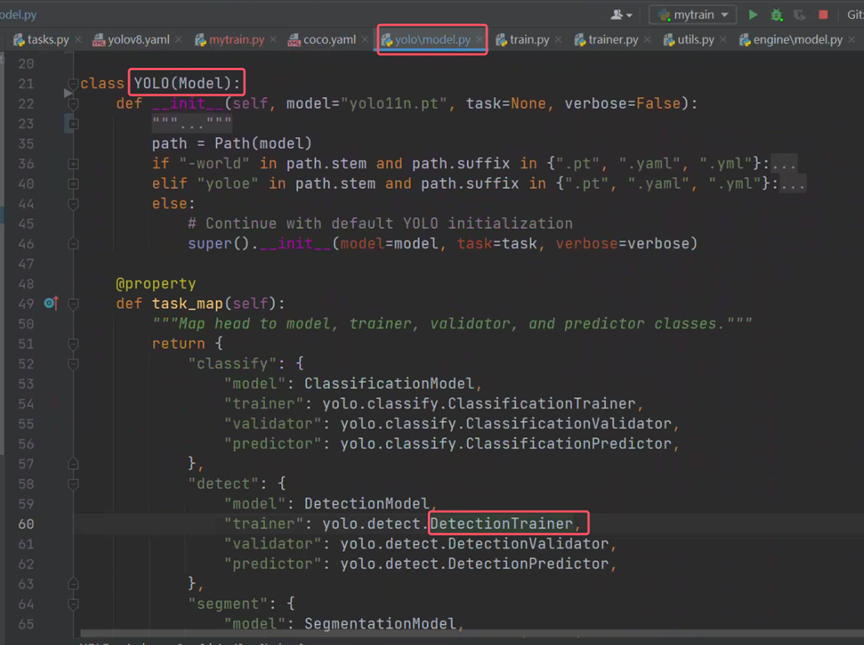
点击查看DetectionTrainer定义
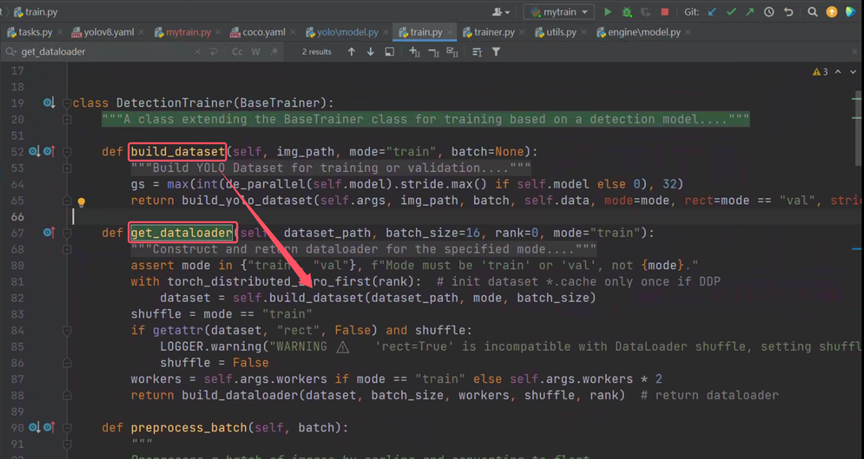
框起来的方法是处理数据集的,但是都得主动调用,然而目前只实现了模型训练的构造,并没有主动调用什么方法。
所以切换到DetectionTrainer的父类BaseTrainer中查看__init__有没有进行数据集的处理。
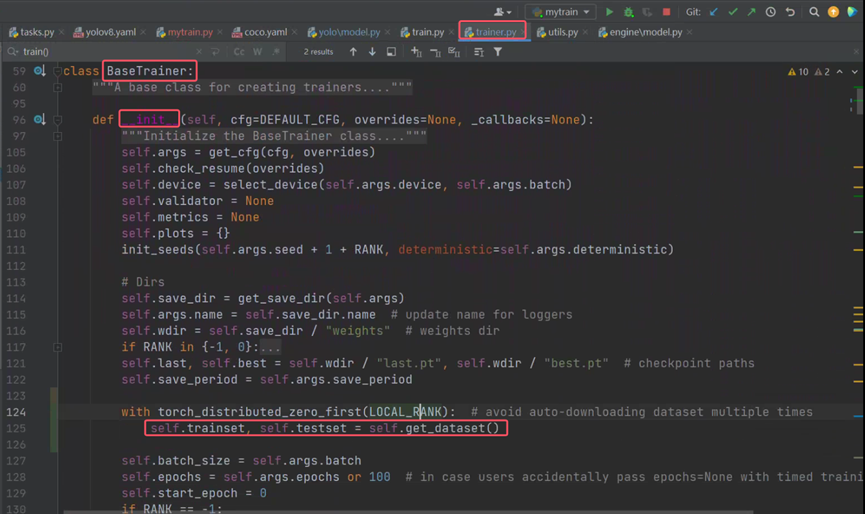
发现在基类模型训练的初始化中有个get_dataset得到了训练集和验证集,点击进去了解处理流程
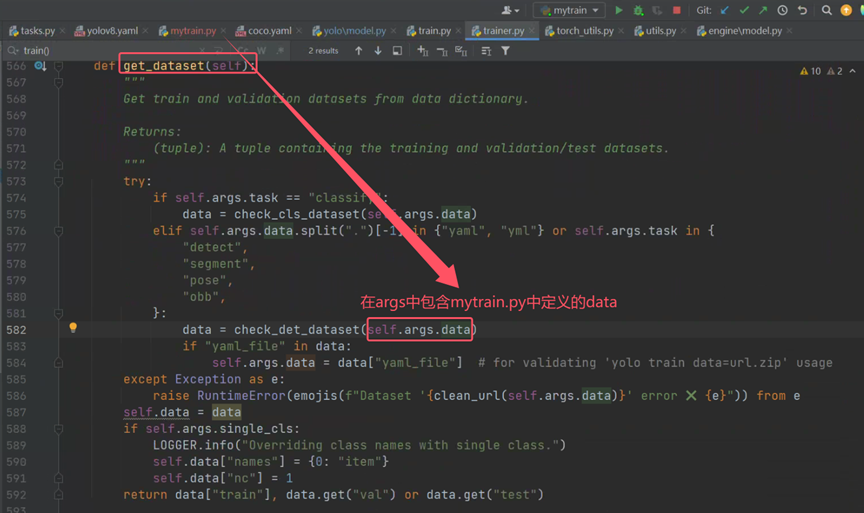
点进check_det_dataset查看代码
这段代码的主要功能是:
解析和设置数据集的路径。
检查路径是否存在,如果不存在且启用了自动下载,则尝试下载数据集。
检查并下载字体文件。
返回处理后的数据字典。
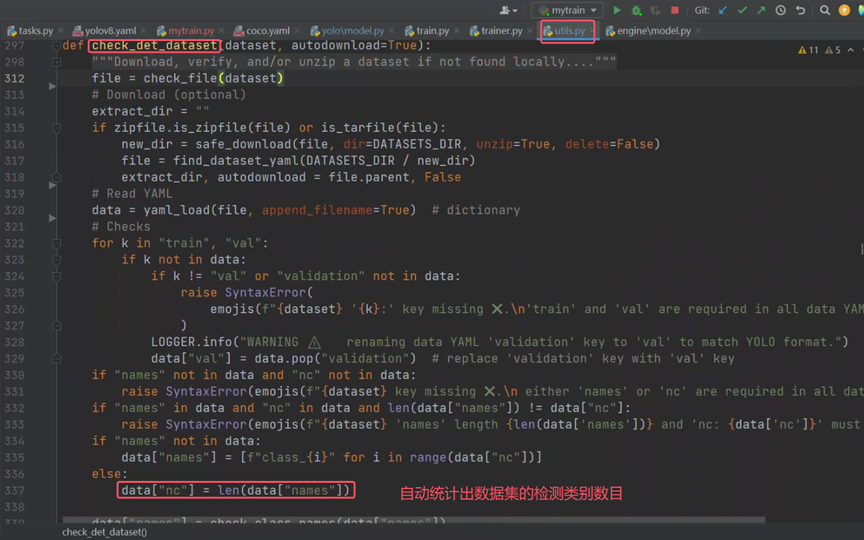
从数据集配置文件到获得数据路径的流程目前已经很清晰了。那么是如何进行数据预处理的呢?
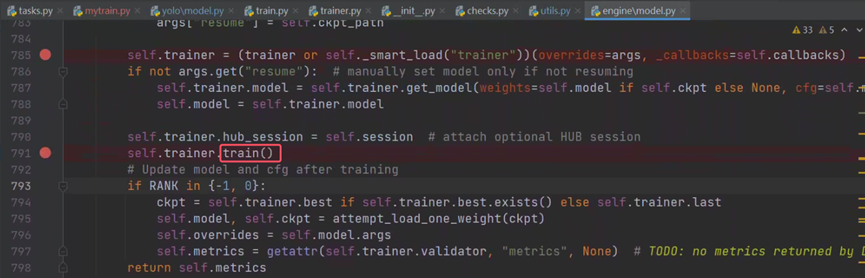
模型训练类的初始化结束也没有找到相关步骤,那么就可能不在初始化过程中进行数据预处理,回到一开始点进去的model.train(data="ultralytics/cfg/datasets/coco.yaml", epochs=2),发现在self.trainer初始化结束后调用了self.trainer.train()。
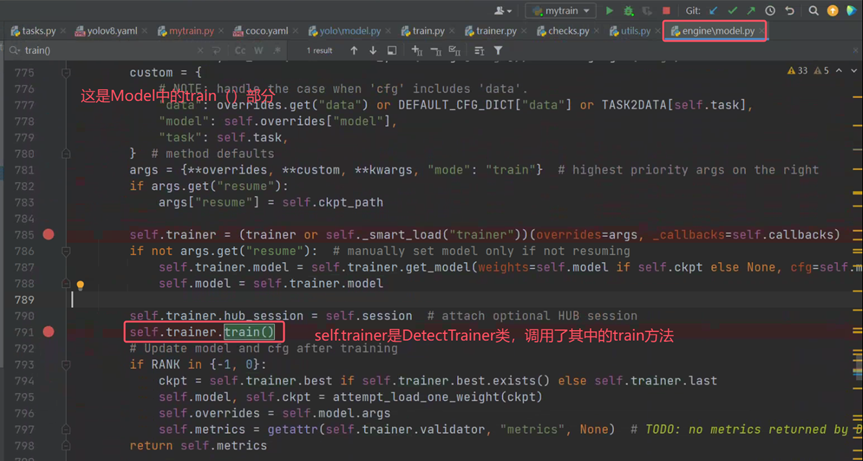
点击进train方法中查看代码,DetectionTrainer中并没有trian方法,但是父类BaseTrainer中有。
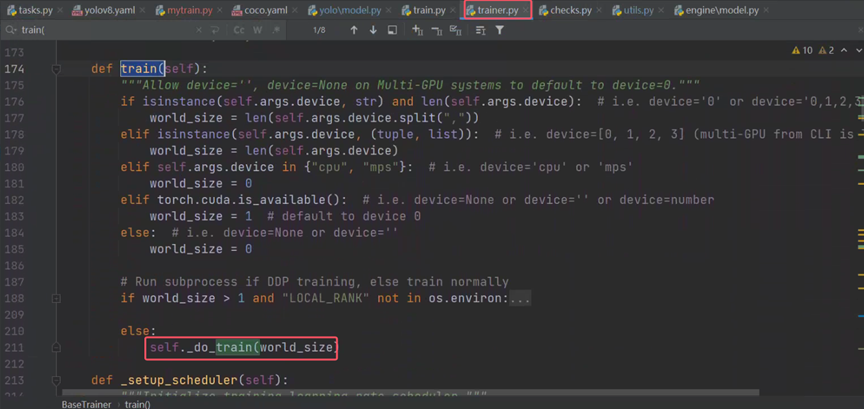
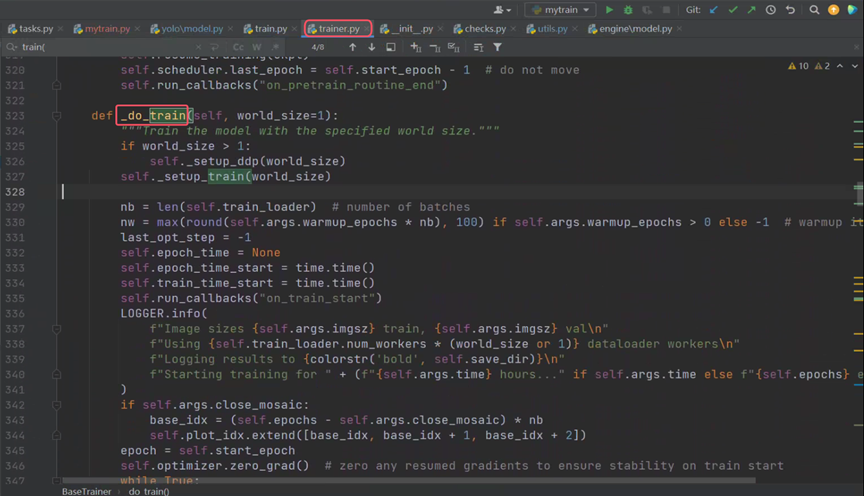
调用了_do_train,点击进去
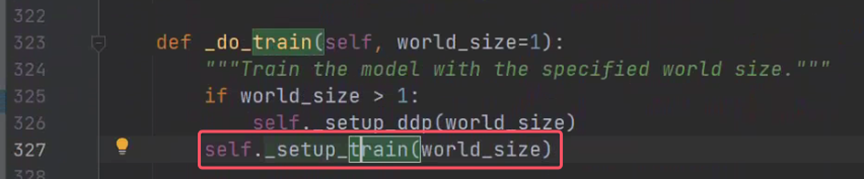
在_do_train中调用了_setup_train,点击进去
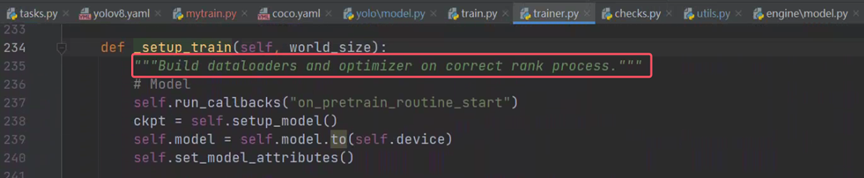
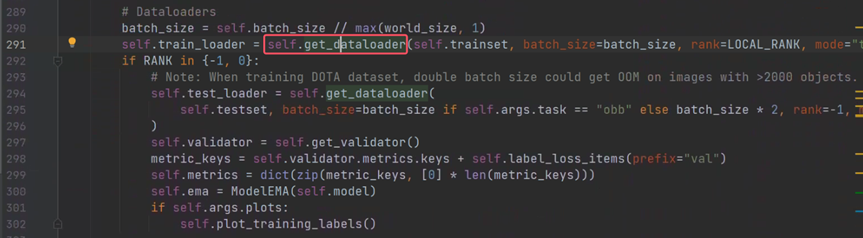
可以看到_setup_train的主要作用就是配置dataloader、优化器和进程,点进get_dataloader看一下如何进行数据增强。这里的get_dataloader是在子类中实现的。
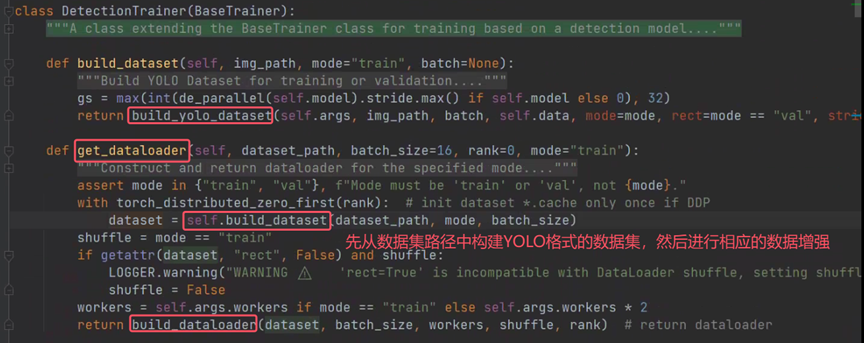
数据集的预处理到这里也比较清晰了。接下来是在训练类中怎么调用检测模型的。
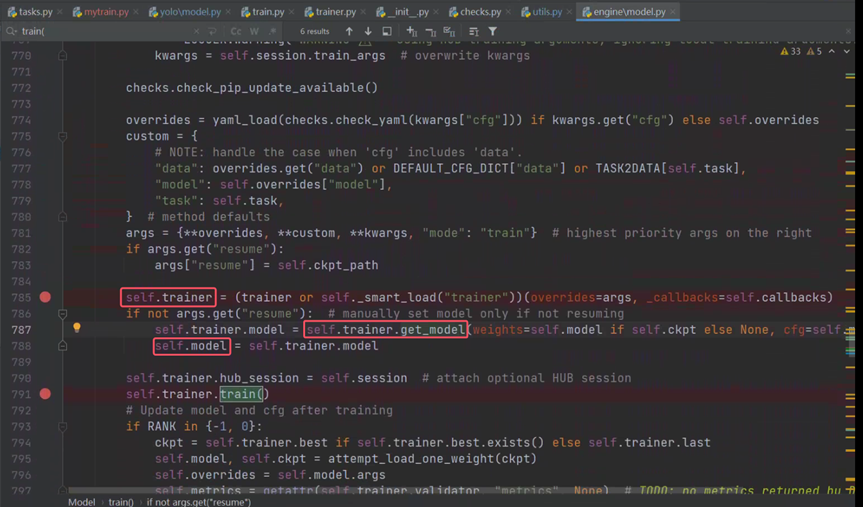
点进去self.trainer.get_model
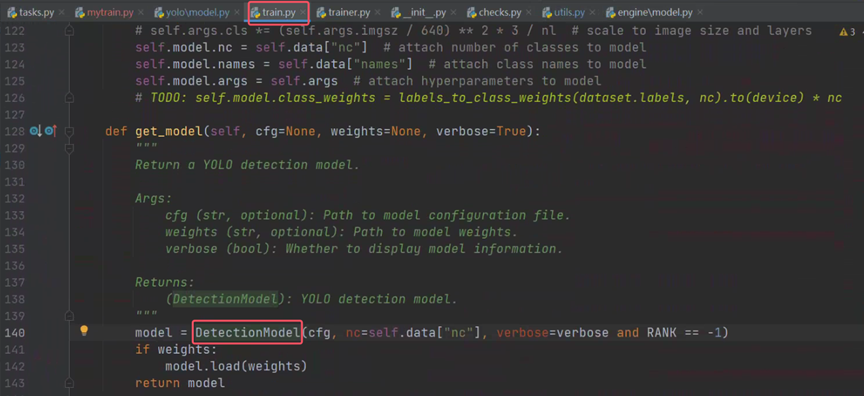
检测训练类的模型就是之前通过模型配置文件得到的检测模型,之后回到训练类开始训练。
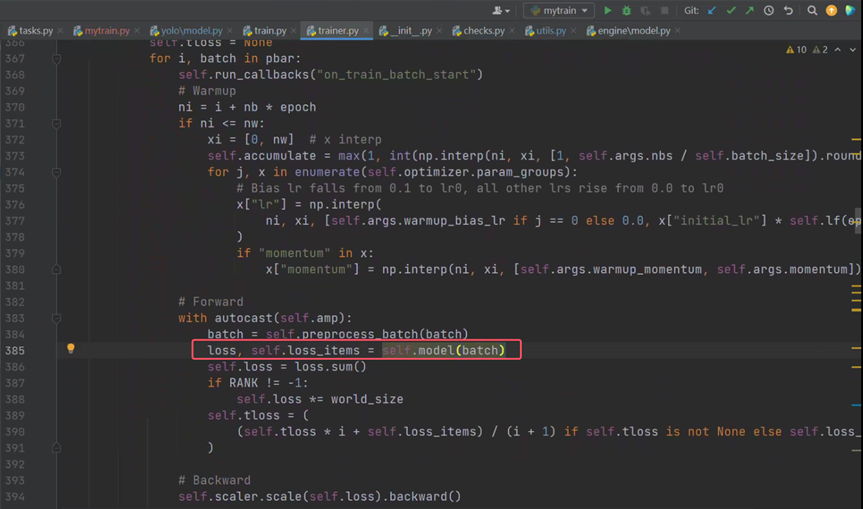
点进去通过不断寻找核心的训练过程,发现_do_train方法,调用了self.model(batch)进行前向传播。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









