







源代码:https://github.com/lululxvi/deeponet/tree/master
https://arxiv.org/abs/1910.03193
复现过程:CSDN
中文翻译论文:https://www.zhihu.com/question/456570818/answer/3567077746
主要的两个文章
这里推荐一篇看过的还不错的论文解释:https://zhuanlan.zhihu.com/p/514148390
相关重要概念和有代码的案例:https://zhuanlan.zhihu.com/p/667494933
下面的内容都是根据上面两个文章和其他文章总结得出
次要文章:
其他文章:https://zhuanlan.zhihu.com/p/648901604
个人理解(个人觉得有用):
- DeepONet的原理是学习算子映射,也就是学习输入函数到输出函数的映射。
- 如何学习算子映射?基于两个子网络,也就是用于输入函数的分支网络和用于评估输出函数的位置的主干网络。(体现了函数到函数的映射)
- 为什么能通过数据学习到非线性算子?基于第4条:算子的通用逼近定理

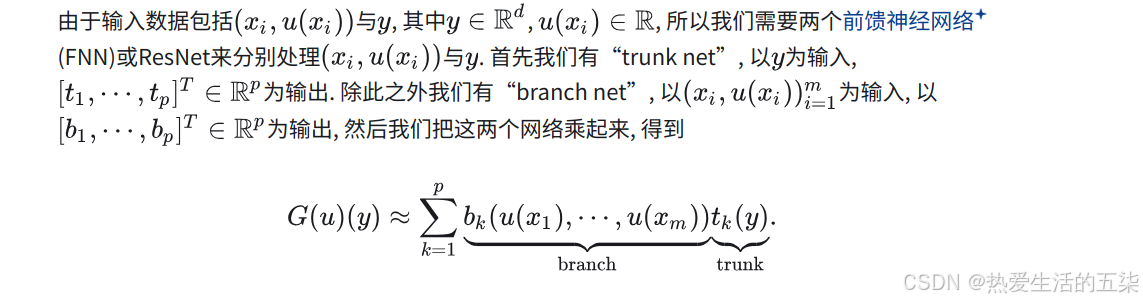
- 为什么两个子网络设计?deeponet设计两个网络(也就是于输入函数的分支网络和用于评估输出函数的位置的主干网络)输出结果的点乘,也对应了上面第4条算子的通用逼近定理中的两项的加权求和。作者提到基于两个子网络的设计显著提高了泛化能力。
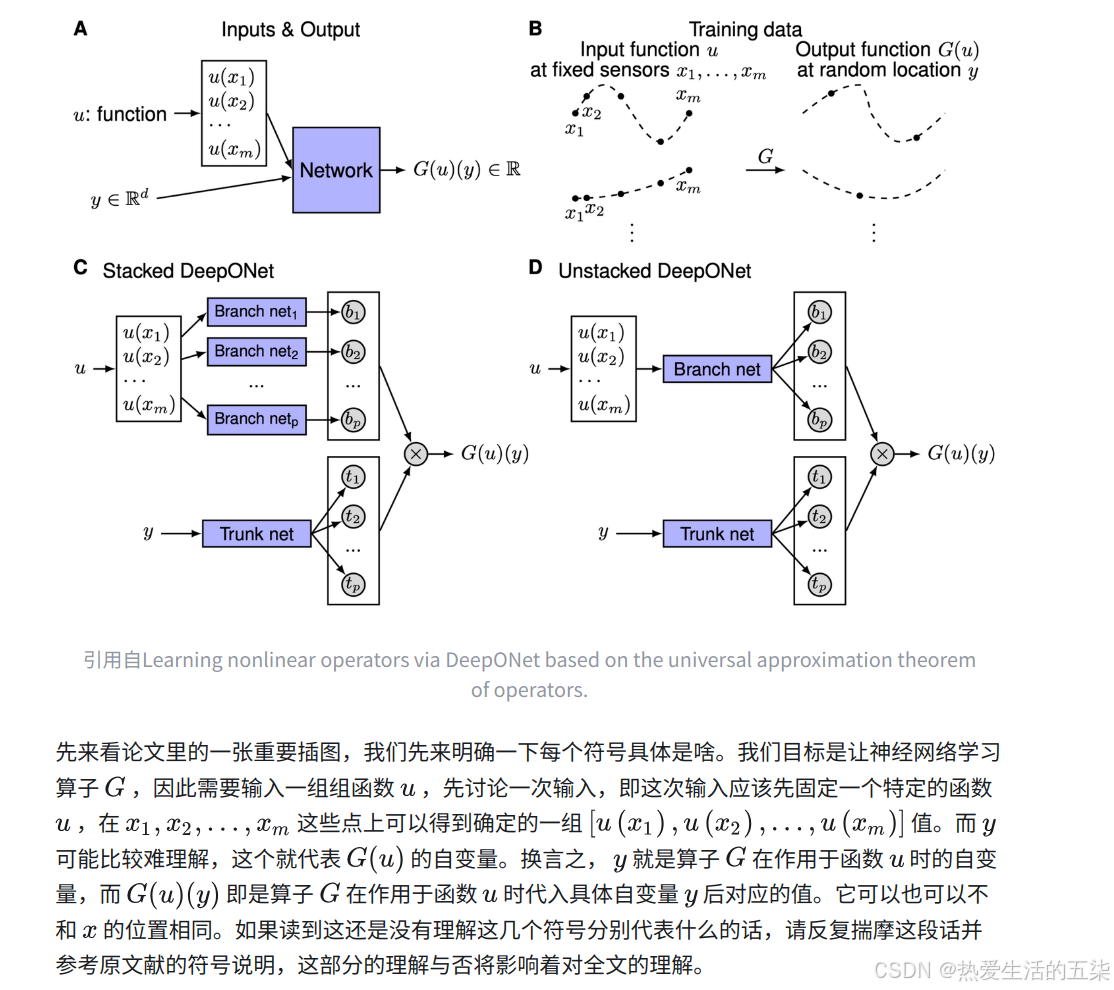
- 两个网络的输入输出?让 𝐺 是一个接受输入函数的运算符 𝑢 , 进而 𝐺(𝑢) 是对应的输出函数。对于任意一点 𝑦 在域中 𝐺(𝑢) ,输出 𝐺(𝑢)(𝑦) 是一个实数。因此,网络接受由两部分组成的输入: 𝑢 和 𝑦 ,和输出 𝐺(𝑢)(𝑦) 。虽然目标是学习以函数作为输入的运算符,但是必须离散地表示输入函数,以便可以应用网络近似。直接而简单的方法是在足够但有限的多个位置处使用函数值 {𝑥1,𝑥2,…,𝑥𝑚} ;我们将这些位置称为“传感器”(sensor).也就是将u这个函数用有限个点u(x1),u(x2)……u(xm)来近似表示。
- 神经网络的准确性可以通过将总误差分为三种主要类型来表征:近似、优化和泛化三种误差。万能逼近定理仅保证足够大的网络具有较小的逼近误差,但它们根本没有考虑优化误差和泛化误差,而优化误差和泛化误差同样重要,并且在实践中往往对总误差起主导作用。有用的网络应该易于训练,即表现出较小的优化误差,并且能够很好地泛化到未见过的数据,即表现出较小的泛化误差。为了准确有效地学习算子,我们提出了一种特定的网络架构,即深度算子网络(DeepONet),以实现更小的总误差。我们将证明 DeepONet 基于两个子网络的设计显着提高了泛化能力,即用于输入函数的分支网络和用于评估输出函数的位置的主干网络。
- 提出deeponet架构的原因:为了准确有效地学习算子,我们提出了一种特定的网络架构,即深度算子网络(DeepONet),以实现更小的总误差( 近似、优化和泛化 )。并证明 DeepONet 基于两个子网络的设计显着提高了泛化能力,即用于输入函数的分支网络和用于评估输出函数的位置的主干网络。
重要理解:
-1.DeepONet的原理是学习算子映射,也就是学习输入函数到输出函数的映射。
0.DeepONet是一种学习非线性算子的神经网络架构。它旨在从输入数据中学习一个算子(即一个映射),这个算子可以将函数映射到另一个函数
1.算子是能作用在整个向量空间上的一种映射规则,而不是作用于具体的数。
2.这里的u函数是多个u函数而不是一个u函数
3.相比于函数逼近,DeepONet这类算子学习的方法目标是解决一类问题。比如我们想解决有源的热传导方程,则给出成百上千种热源的表达函数(u)作为输入,一旦训练完成后,这个模型则可以解决这个定义域内的所有有源热传导问题。
4.如果说PINNs的目标是在用神经网络是在逼近微分方程的解,那么算子学习可以理解为目标是在逼近微分方程本身。
5.算子学习需要输入的是函数。如何取一大组(多个)函数 𝑢 能让神经网络成功学习算子 𝐺 则成了研究的重点,在DeepONet的这篇文章中,作者主要研究了两个函数空间,分别是Gaussian random field(GRF)和orthogonal (Chebyshev) polynomials。

个人理解:也就是函数随着l的取值而变化,比如x平方,x立方中的指数的取值会变化,但都是指数函数。
5.理解函数和算子(推荐)
6.从函数到算子
所以,人们想到了一种新方法,求助于“算子”。算子是一种从函数到函数的映射。
函数:数→数 ,如sinx将x在无穷区间上的数 映射到了[0,1]
算子:函数→函数
比如,正弦算子(sin)把线性函数x变成三角函数sinx,微分(求导)算子(d/dx)把三次函数x³变成二次函数3x²。

基于物理信息的 DeepONets训练步骤如下:
去掉8,9,就是deeponet的训练步骤

deeponet的相关概念:





















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











