







1.model.py
import torch.nn as nn
import torch.nn.functional as F
引入pytorch的两个模块
关于这两个模块的作用,可以参考下面
Pytorch官方文档
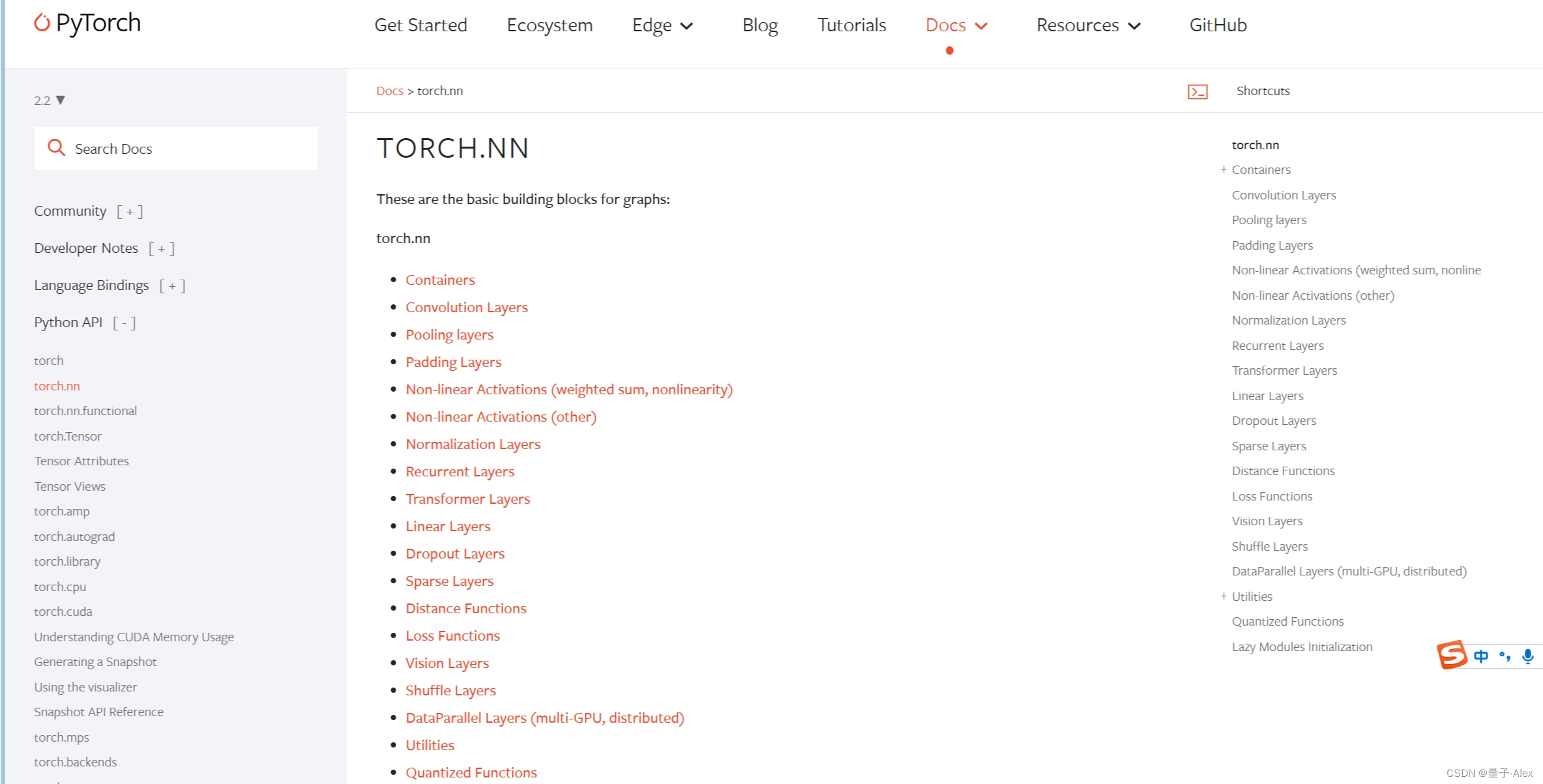
torch.nn包含了构成计算图的基本模块
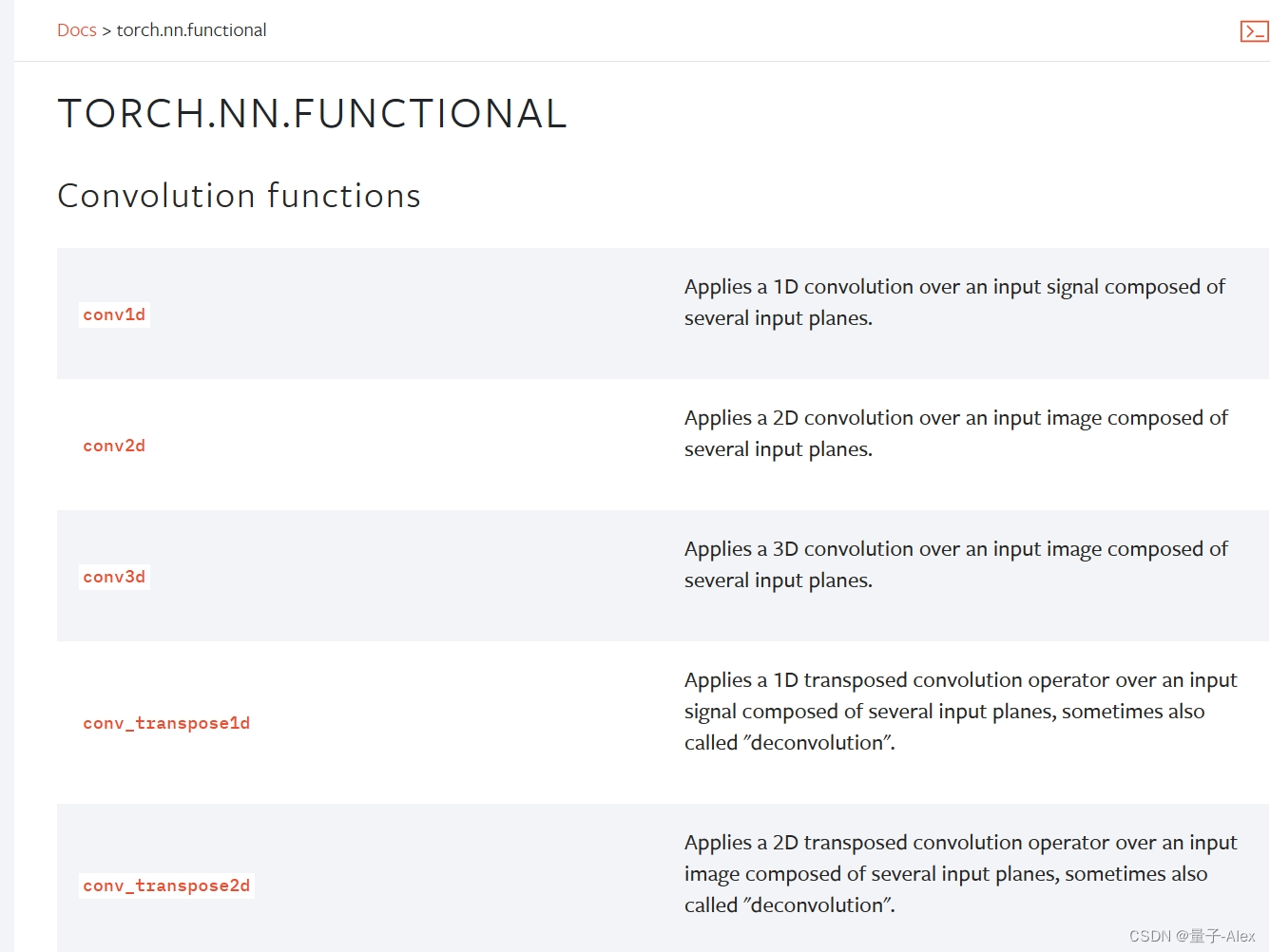



torch,nn.function包括了计算图中的各种主要函数,包括:卷积函数、池化函数、注意力机制函数、非线性激活函数、dropout函数、线性函数、距离函数、损失函数、可视化函数和多GPU分布式函数等。
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
我们构建了从torch.nn.Module类下面继承的LeNet类,这个类构建了LeNet神经网络,所有pytorch定义的神经网络模型都从nn.Module类派生。
首先def init(self):是类的初始化函数,当我们创建这个类的一个实例时,这个函数会被调用。
super(LeNet, self).init()是调用父类nn.Module的初始化函数,这是一个标准的做法,确保父类中的任何初始化都被正确的执行。
self.conv1 = nn.Conv2d(3, 16, 5)调用nn.function的二维卷积函数,定义了第一个卷积层的操作,输入的通道数是3,输出通道数16,5*5的卷积核
self.pool1 = nn.MaxPool2d(2, 2)调用了最大池化函数,定义了第一个池化层的操作,池化窗口的大小是2*2
self.conv2 = nn.Conv2d(16, 32, 5)定义了第二个卷积层的操作,输入通道数是16,因为第一个卷积层的输出通道数是16,这一层的输出通道数是32,5*5的卷积核
self.pool2 = nn.MaxPool2d(2, 2)调用了最大池化函数,定义了第二个池化层的操作,池化窗口的大小是2*2
self.fc1 = nn.Linear(3255, 120)定义了一个全连接层,输入特征是3255,这是前一层输出的特征数与卷积核大小、步长和填充的综合结果),输出特征数为120。
self.fc2 = nn.Linear(120, 84)定义另一个全连接层,输入特征数为120,输出特征数为84。
self.fc3 = nn.Linear(84, 10) 定义最后一个全连接层,输入特征数为84,输出特征数为10。这个输出特征数通常对应于分类问题的类别数(如果有10个类别的话)。
LeNet模型是一个经典的卷积神经网络结构,主要用于图像分类任务。它包括两个卷积层、两个池化层和三个全连接层。
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
这段代码定义了一个神经网络的前向传播过程。
def forward(self, x):
定义一个名为forward的方法,它描述了数据从输入到输出的前向传播过程。
x = F.relu(self.conv1(x))
输入数据x经过第一个卷积层self.conv1,然后通过ReLU激活函数。输入是33232,输出的大小为(16, 28, 28)。
x = self.pool1(x)
对上一步的输出进行最大池化操作,输出的大小变为(16, 14, 14)。
x = F.relu(self.conv2(x))
输入数据x经过第二个卷积层self.conv2,然后通过ReLU激活函数。输出的大小为(32, 10, 10)。
x = self.pool2(x)
对上一步的输出进行最大池化操作,输出的大小变为(32, 5, 5)。
x = x.view(-1, 3255)
对上一步的输出进行展平操作,即将三维数据变为二维数据。输出的大小为(-1, 3255),其中-1表示批量大小,可以自动计算。
x = F.relu(self.fc1(x))
对展平后的数据x进行全连接操作,然后通过ReLU激活函数。输出的大小为120
x = F.relu(self.fc2(x))
对上一步的输出进行全连接操作,然后通过ReLU激活函数。输出的大小为84
x = self.fc3(x)
对上一步的输出进行全连接操作,不使用激活函数。输出的大小为(10)。这通常表示有10个类别。
return x
返回最终的输出结果。
这个前向传播过程描述了数据从输入到输出的整个流程,包括卷积、池化、全连接和激活函数等操作。
















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











