









第一章 动机:为什么你可能关心
1.1 辛普森悖论
考虑一个纯粹假设的未来,有一种被称为COVID-27的新疾病在人类中流行。在这个纯粹假设的未来,有两种治疗方法已经被开发出来:治疗A和治疗B。治疗B比治疗A更稀缺,因此目前接受治疗A和治疗B的比例大致为73%/27%。在一个只关心最大限度地减少生命损失的国家,你有责任选择你的国家将专门使用哪种治疗方法。
你有死于COVID-27的人的百分比数据,考虑到他们被分配的治疗和他们在决定治疗时的状况。他们的病情是一个二元变量:轻度或重度。在这些数据中,16%接受A的人死亡,而19%接受B的人死亡。然而,当我们将病情较轻的人与病情较重的人分开检查时,数字顺序相反。在轻度亚群中,接受A的人中有15%死亡,而接受B的人中有10%死亡。在重度亚群中,接受A的患者中有30%死亡,而接受B的患者中有20%死亡。我们在表1.1中描述了这些百分比和相应的计数。
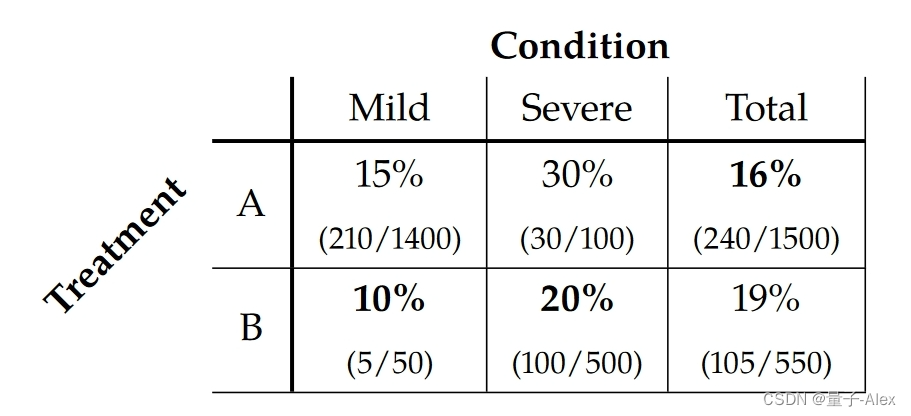
表1.1:COVID-27数据中的辛普森悖论。百分比表示各组中的死亡率。越低越好。括号中的数字是相应的计数。这种明显的悖论源于这样一种解释,即当检查整个人群时,治疗A看起来更好,但治疗B在所有亚人群中看起来更好。
明显的悖论源于这样一个事实,即在表1.1中,“总”一栏可以被解释为我们应该更喜欢治疗A,而“轻度”和“重度”一栏都可以被解释为我们应该更喜欢治疗B.事实上,答案是,如果我们知道某人的病情,我们应该给他们治疗B,如果我们不知道他们的病情,我们应该给他们治疗A。开个玩笑…这没有任何意义。所以说真的,你应该为你的国家选择什么治疗方法?
发现辛普森悖论的一个关键因素是群体中人员分配的不均匀性。接受治疗A的1500人中有1400人病情轻微,而接受治疗B的550人中有500人病情严重。因为病情较轻的人死亡的可能性较小,这意味着接受治疗A的人的总死亡率低于轻度和重度患者平均分配的总死亡率。治疗B的偏差正好相反。
治疗A或治疗B可能是正确答案,这取决于数据的因果结构。换句话说,因果关系对于解决辛普森悖论至关重要。现在,我们只给出你什么时候应该更喜欢治疗A和什么时候应该更喜欢治疗B的直觉,但这将在第4章中变得更加正式。
情景1 如果病情是治疗的原因(图1.1),治疗B在降低死亡率方面更有效。一个示例场景是医生决定对大多数病情轻微的人进行治疗。他们为病情严重的人节省了更昂贵和更有限的治疗B。因为患有严重疾病会导致一个人更有可能死亡(C→Y 图1.1),并导致一个人更有可能接受治疗B(C→T 图1.1),治疗B将与总人口中较高的死亡率相关。换句话说,治疗B与较高的死亡率相关,仅仅是因为病症是治疗和死亡率的共同原因。在这里,条件混淆了治疗对死亡率的影响。为了纠正这种混杂,我们必须检查患有相同疾病的患者治疗T和死亡率Y之间的关系。这意味着更好的治疗是在每个亚群中产生更低死亡率的治疗(表1.1中的“轻度”和“重度”栏):治疗B。
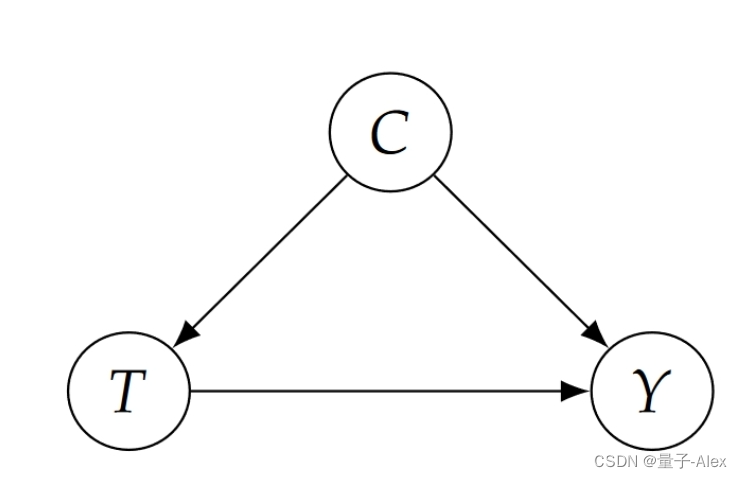
图1.1:情景1的因果结构,其中病情C是治疗T和死亡Y的常见原因。鉴于这种因果结构,治疗B是优选的。
情景2 如果治疗处方T是病情C的一个原因(图1.2),治疗A更有效。(T是指治疗的处方,而不是随后接受治疗。)一个示例场景是治疗B非常稀缺,以至于患者在接受治疗后需要等待很长时间才能接受治疗。治疗A没有这个问题。因为COVID-27患者的病情会随着时间的推移而恶化,治疗B的处方实际上会导致病情较轻的患者发展为重症,从而导致更高的死亡率。因此,即使一旦给药,治疗B比治疗A更有效(图1.2中的正效应 T→Y),由于治疗B的处方会导致更糟糕的情况(图1.2中的负效应 T→C→Y),治疗B的总体效果较差。注:因为治疗B更贵,所以开出治疗B的概率为0.27,而开出治疗A的概率为0.73;重要的是,在这种情况下,治疗处方与病情无关。
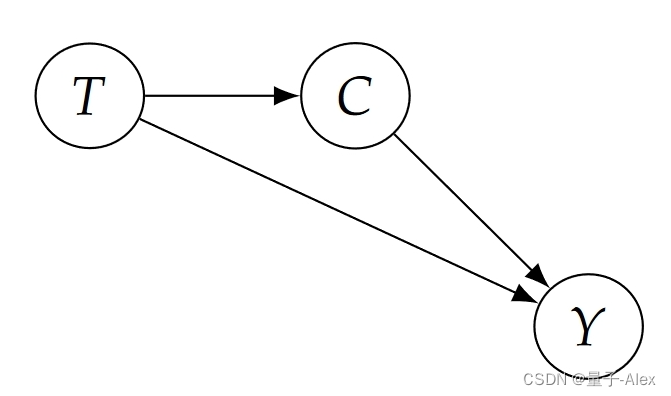
图1.2:情景2的因果结构,其中治疗T是病情C的一个原因。鉴于这种因果结构,治疗A是优选的。
总之,更有效的治疗完全取决于问题的因果结构。在情景1中,治疗B更有效,其中C是T的一个原因(图1.1)。在情景2中,治疗A更有效,其中T是C的一个原因(图1.2)。没有因果关系,辛普森悖论就无法解决。有了因果关系,根本就不是悖论。
1.2 因果推断的应用
因果推断对科学至关重要,因为我们经常想要做出因果主张,而不仅仅是关联主张。例如,如果我们在一种疾病的治疗方法之间进行选择,我们希望选择使大多数人被治愈的治疗方法,而不会引起太多不良副作用。如果我们希望强化学习算法最大化奖励,我们希望它采取导致它实现最大奖励的行动。如果我们正在研究社交媒体对心理健康的影响,我们试图了解给定心理健康结果的主要原因是什么,并根据可归因于每个原因的结果百分比对这些原因进行排序。
因果推理对于严谨的决策至关重要。例如,假设我们正在考虑实施几种不同的政策来减少温室气体排放,由于预算限制,我们必须只选择一种。如果我们想最大限度地发挥作用,我们应该进行因果分析,以确定哪项政策将导致排放量的最大减少。作为另一个例子,假设我们正在考虑几项干预措施来减少全球贫困。我们想知道哪些政策将导致最大程度的减贫。
既然我们已经讨论了辛普森悖论的一般例子以及科学和决策中的一些具体例子,我们将继续讨论因果推断与预测有何不同。
1.3 相关性并不意味着因果关系
你们中的许多人可能听说过“相关性并不意味着因果关系”这句口头禅。在本节中,我们将快速回顾这一点,并为您提供更多关于为什么会出现这种情况的直觉。
1.3.1 尼古拉斯·凯奇和泳池溺水事件
事实证明,每年因掉进游泳池而溺水的人数与尼古拉斯·凯奇每年出演的电影数量有很高的相关性[1]。这些数据的图表见图1.3。这是否意味着尼古拉斯·凯奇在他的电影中鼓励不会游泳的人跳进游泳池?或者当尼古拉斯·凯奇看到那一年发生了多少溺水事件时,他是否更有动力出演更多的电影,也许是为了防止更多的溺水?还是有其他解释?例如,也许尼古拉斯·凯奇对增加他在因果推理从业者中的受欢迎程度感兴趣,所以他回到过去,说服他过去的自己制作适量的电影,让我们看到这种相关性,但不要太接近,因为这会引起怀疑,并可能导致有人阻止他以这种方式操纵数据。我们可能永远无法确定。
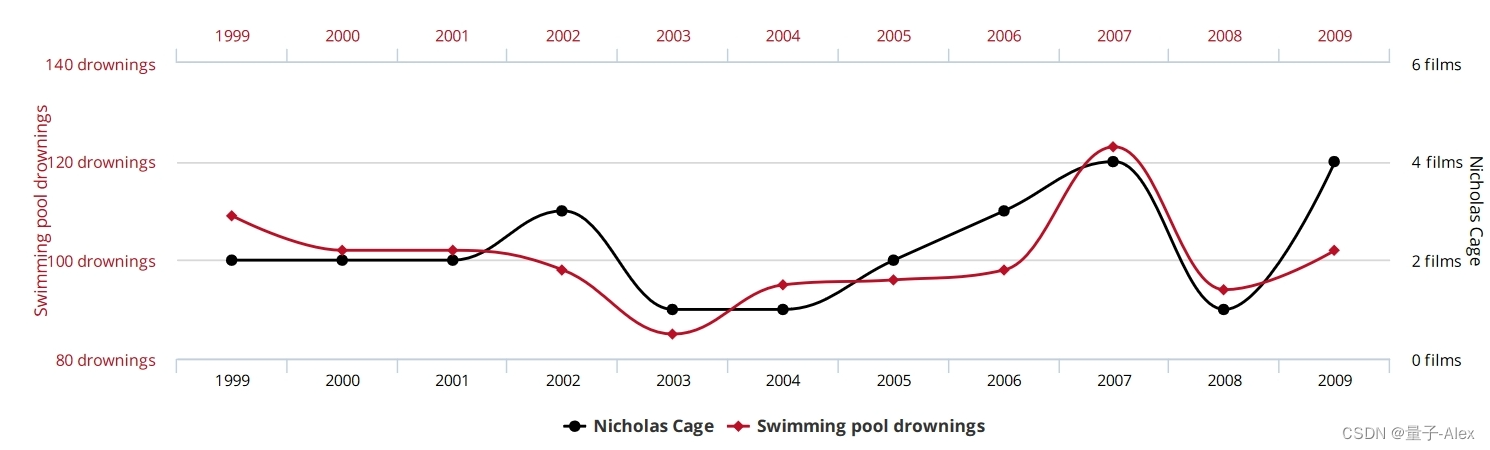
图1.3:尼古拉斯·凯奇每年出演的电影数量与每年泳池溺水事件的数量相关[1]。
当然,上一段中所有可能的解释似乎都不太可能。相反,这很可能是一种虚假的相关性,没有因果关系。我们很快就会转向更多有助于阐明虚假相关性如何出现的说明性示例。
1.3.2 为什么关联不是因果关系?
在进入下一个例子之前,让我们更精确地了解一下术语。“相关性”通常被通俗地用作统计相关性的同义词。然而,“相关性”在技术上仅是线性统计相关性的度量。从现在开始,我们将在很大程度上使用术语关联来指代统计依赖性。
因果关系不是全有或全无。对于任何给定数量的关联,不需要是“所有关联都是因果的”或“没有关联是因果的”。相反,有可能有大量的关联,而其中只有一部分是因果关系。短语“关联不是因果关系”仅仅意味着关联的数量和因果关系的数量可以不同。一定数量的关联和零因果关系是“关联不是因果关系”的特例。
假设你偶然发现一些数据,这些数据与穿鞋睡觉和醒来时头痛有关,就像一个人一样。事实证明,大多数时候,当有人穿鞋睡觉时,那个人醒来时会头疼。大多数时候,有人不穿鞋睡觉,那个人醒来时不会头疼。人们将这样的数据(带有关联)解释为穿鞋睡觉会导致人们醒来时头痛,这并不罕见,特别是如果他们正在寻找一个理由来证明不穿鞋睡觉是合理的。一个细心的记者可能会说“穿鞋睡觉与头痛有关”或“穿鞋睡觉的人醒来时头痛的风险更高”。然而,做出这样的声明的主要原因是,大多数人会将这样的声明内化为“如果我穿鞋睡觉,我可能会头疼地醒来。”
我们可以解释穿鞋睡觉和头痛是如何联系在一起的,而两者都不是另一个的原因。原来,它们都是由一个共同的原因引起的:前一天晚上喝酒。我们在图1.4中描述了这一点。您可能还会听到这种变量被称为“混杂因素”或“潜在变量”。我们将这种关联称为混杂关联,因为这种关联是由混杂因素促成的。
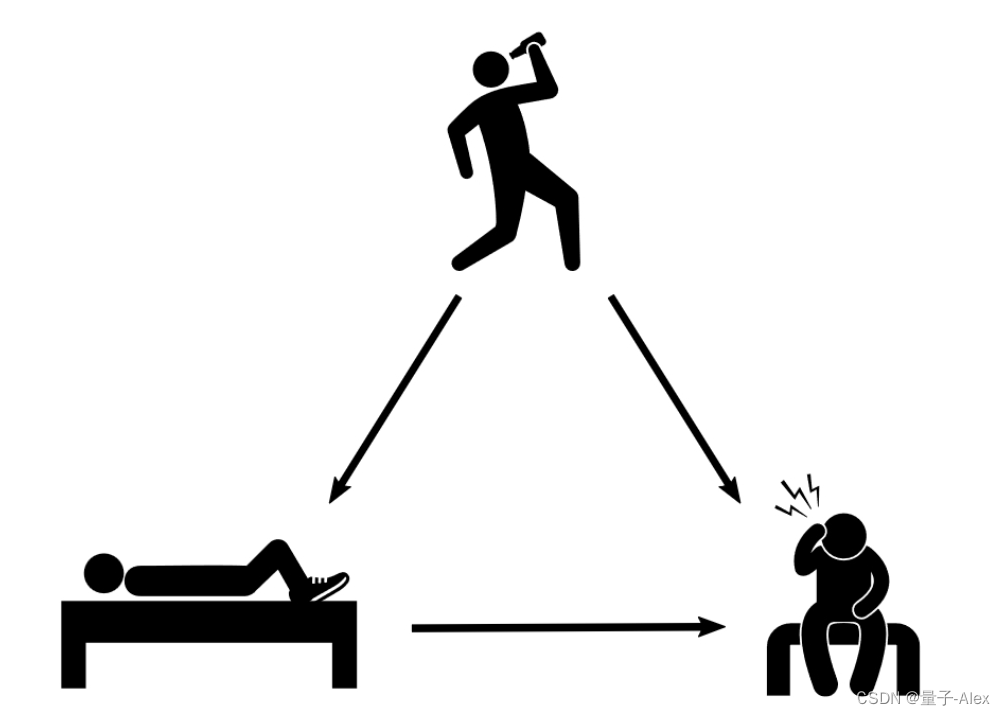
图1.4:因果结构,前一天晚上喝酒是穿鞋睡觉和醒来头痛的常见原因。
观察到的总关联可以由混杂关联和因果关联两者组成。可能是这样的情况,穿鞋睡觉确实对醒来时头痛有一些小的因果影响。那么,总关联将不仅仅是混杂关联,也不仅仅是因果关联。这将是两者的混合。例如,在图1.4中,因果关系沿着箭头从鞋子睡觉到醒来头痛。令人困惑的联想沿着从鞋子睡觉到喝酒再到头痛(醒来时头痛)的路径流动。我们将在第3章中清楚地解释这些不同类型的关联。
正如我们将在第五章中看到的,如果我们在一个对照实验中随机分配治疗,联想实际上就是因果关系。如果两者相同,那么因果推断就很容易了。传统的统计学和机器学习已经解决了因果推理,因为测量因果关系就像查看数据中的相关性和预测性能等指标一样简单。本书的很大一部分将是关于更好地理解和解决这个问题。
正如我们将在第五章看到的,如果我们在一个对照实验中随机分配治疗,关联实际上就是因果关系。
1.4 主题
这里有几个贯穿本书的主题。这些主题在很大程度上是两个不同类别的比较。当你阅读时,重要的是你要明白这本书的不同部分属于哪一类,不属于哪一类。
统计与因果 即使有无限量的数据,我们有时也无法计算一些因果量。相比之下,许多统计学都是关于解决有限样本中的不确定性。当给定无限的数据时,不存在不确定性。然而,关联,一个统计概念,不是因果关系。在因果推断方面还有更多的工作要做,即使是在从无限数据开始之后。这是激发因果推理的主要区别。我们已经在本章中做了这种区分,并将在本书中继续做这种区分。
识别与估计 因果效应的识别是因果推理所特有的。这是一个有待解决的问题,即使我们有无限的数据。然而,因果推理也与传统统计学和机器学习共享估计。我们将主要从因果效应的识别开始(在第2、4和6章中),然后再进入因果效应的估计(在第7章中)。例外情况是第2.5节和第4.6.2节,在这两节中,我们执行了完整的示例和评估,让您在早期了解整个过程的样子。
干预性与观察性 如果我们可以干预/实验,因果效应的识别相对容易。这仅仅是因为我们实际上可以采取我们想要衡量因果效应的行动,并在我们采取该行动后简单地衡量效果。观察数据变得更加复杂,因为混杂几乎总是被引入数据中。
假设 我们将非常关注我们使用什么假设来获得结果。每个假设都有自己的盒子,让人很难不注意到。清晰的假设应该使人们很容易看到对给定因果分析或因果模型的批评在哪里。希望清楚地提出假设将导致关于因果关系的更清晰的讨论。
















 3775
3775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











