







我们目前介绍过的程序使用了3种类型的对象:int、float和str。数值类型int和float是
标量类型,也就是说,这种类型的对象没有可以访问的内部结构。与之相比,我们可以认为str
是一种结构化的、非标量的类型。我们可以使用索引从字符串提取单个字符,也可以通过分片操
作获取子字符串。
本章将介绍另外4种结构化类型。其中,tuple相对简单,是str的扩展。其他3种——list、
range①和dict——则有趣得多。我们还会回到“函数”这个主题,使用几个示例演示一些使用
方法,看看如何能像其他对象类型一样对待函数。
5.1 元组
与字符串一样,元组是一些元素的不可变有序序列。与字符串的区别是,元组中的元素不一
定是字符,其中的单个元素可以是任意类型,且它们彼此之间的类型也可以不同。
tuple类型的字面量形式是位于小括号之中的由逗号隔开的一组元素。例如,我们可以输入
如下代码:
t1 = ()
t2 = (1, 'two', 3)
print(t1)
print(t2)
不出所料,print语句会输出:
()
(1, 'two', 3)
看着这个例子,你可能会很自然地认为,只包含一个元素1的元组应该写成(1)。但正如理查
德·尼克松所说:“那将是错误的。”因为小括号是用来分组表达式的,所以(1)只不过是整数1
的一种更加冗长的写法。要想表示包含1的单元素元组,我们应该写成(1,)。几乎所有Python用户都不小心漏掉过那个烦人的逗号。
可以在元组上使用重复操作。如,表达式3*('a', 2)的值就是('a', 2, 'a', 2, 'a', 2)。
与字符串一样,元组可以进行连接、索引和切片等操作。看下面的代码:
t1 = (1, 'two', 3)
t2 = (t1, 3.25)
print(t2)
print((t1 + t2))
print((t1 + t2)[3])
print((t1 + t2)[2:5])
第二个赋值语句将名称t2绑定到一个元组,这个元组中有一个绑定了名称t1的元组和一个浮
点数3.25。这是可行的,因为元组也是一个对象,和Python中的其他对象一样,所以元组可以包
含元组。因此,第一个print语句会输出:
((1, 'two', 3), 3.25)
第二个print语句输出t1和t2绑定后的值,是一个五元素元组。输出结果为:
(1, 'two', 3, (1, 'two', 3), 3.25)
下一条语句选取并输出连接后元组中的第四个元素(Python中的索引从0开始),后面的一条
语句创建并输出这个元组的一个切片,输出如下:
(1, 'two', 3)
(3, (1, 'two', 3), 3.25)
可以使用一个for语句遍历元组中的各个元素:
def intersect(t1, t2):
"""假设t1和t2是正整数
返回一个元组,包含t1和t2的公约数"""
both t1 and t2"""
result = ()
for e in t1:
if e in t2:
result += (e,)
return result
序列与多重赋值
如果你知道一个序列(元组字符串)的长度,那么可以使用Python中的多重赋值语句方便地
提取单个元素。例如,执行语句x, y = (3, 4)后,x会被绑定到3,y会被绑定到4。同样地,语
句a, b, c = 'xyz'会将a绑定到x、b绑定到y、c绑定到z。
与返回固定长度序列的函数结合使用时,这种机制会特别方便。举个例子,看下面的函
数定义:
def findExtremeDivisors(n1, n2):
"""假设n1和n2是正整数
返回一个元组,包含n1和n2的最小公约数和最大公约数,最小公约数大于1,
如果没有公约数,则返回(None, None)。"""
returns (None, None)"""
minVal, maxVal = None, None
for i in range(2, min(n1, n2) + 1):
if n1%i == 0 and n2%i == 0:
if minVal == None:
minVal = i
maxVal = i
return (minVal, maxVal)
多重赋值语句:
minDivisor, maxDivisor = findExtremeDivisors(100, 200)
会将minDivisor绑定到2,将maxDivisor绑定到100。
5.2 范围
和字符串与元组一样,范围也是不可变的。range函数会返回一个range类型的对象。正如3.2
节中的定义,range函数接受3个整数参数:start、stop和step,并返回整数数列start、start +
step、start + 2 * step、等等。如果step是个正数,那么最后一个元素就是小于stop的最大
整数start + i * step。如果step是个负数,那么最后一个元素就是大于stop的最小整数start +
i * step。如果只有2个实参,那么步长就为1。如果只有1个实参,那么这个参数就是结束值,
起始值默认为0,步长默认为1。
除了连接操作和重复操作,其他所有能够在元组上进行的操作同样适用于范围。例如,
range(10)[2:6][2]的值为4。使用==操作符比较两个range类型的对象时,如果两个范围表示同
样的整数序列,那么就返回True。例如,range(0, 7, 2) == range(0, 8, 2)的值就是True,
但range(0, 7, 2) == range(6, -1, -2)的值则是False。因为尽管这两个范围包含同样的整
数,但顺序是不一样的。
与元组类型的对象不同,range类型的对象占用的空间与其长度不成正比。因为范围是由起
始值、结束值和步长定义的,它的存储仅占用很小的一部分空间。
range最常用在for循环中,range类型的对象也可以用在所有可以使用整数序列的地方。
5.3 列表与可变性
与元组类似,列表也是值的有序序列,每个值都可以由索引进行标识。表示list类型字面量
的语法与元组很相似,区别在于列表使用的是中括号,而元组使用的是小括号。空列表写作[ ],
单元素列表不需要在闭括号前面加上那个(特别容易忘掉的)逗号。看下面的示例代码:
L = ['I did it all', 4, 'love']
for i in range(len(L)):
print(L[i])
会输出:
I did it all
4
love
中括号还可以用于表示list类型字面量、列表索引和列表切片,这个事实有时会产生一些
视觉上的混淆。例如,表达式[1, 2, 3, 4][1:3][1]的值为3,它使用了方括号的3种不同用
法。实际上,这几乎不是什么问题,因为多数时候列表都是以递增的方式建立的,很少直接书
写字面量。
列表与元组相比有一个特别重要的区别:列表是可变的,而元组和字符串是不可变的。很多
操作符可以创建可变类型的对象,也可以将变量绑定到这种类型的对象上。但不可变类型的对象
是不能被修改的,相比之下,list类型的对象在创建完成后可以被修改。
“使对象发生变化”与“将对象赋给变量”这二者之间的区别乍看上去不太明显,但如果你
不断重复“在Python中,变量仅是个名称,就是贴在对象上的标签”这句话,没准儿就顿悟了。
执行以下语句时:
Techs = ['MIT', 'Caltech']
Ivys = ['Harvard', 'Yale', 'Brown']
解释器会创建两个新列表,然后为其绑定合适的变量,如图5-1所示。
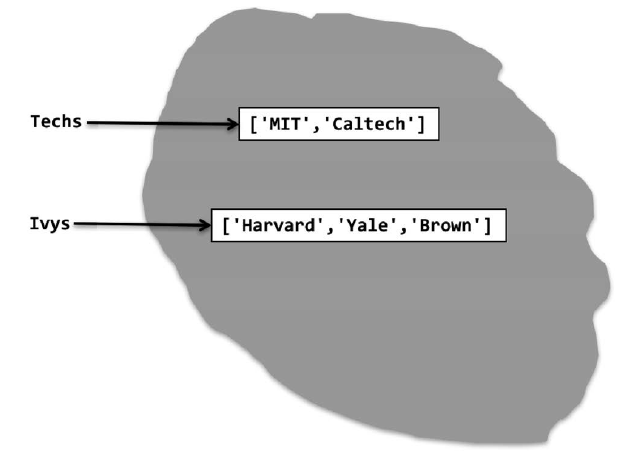
图5-1 两个列表
赋值语句:
Univs = [Techs, Ivys]
Univs1 = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
也会创建新的列表并为其绑定变量。这些列表中的元素也是列表。以下三条语句:
print('Univs =', Univs)
print('Univs1 =', Univs1)
print(Univs == Univs1)
会输出:
Univs = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
Univs1 = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
True
看上去好像Univs和Univs1被绑定到同一个值,但这个表象具有欺骗性。如图5-2所示,Univs
和Univs1被绑定到了完全不同的值。
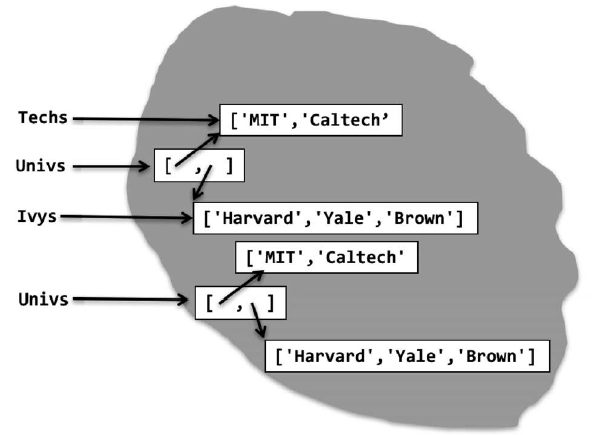
图5-2 两个列表看上去有同样的值,但实际不是
Univs和Univs1被绑定到不同的对象,可以使用Python内置函数id验证这一点,id会返回一
个对象的唯一整数标识符。可以用这个函数检测对象是否相等。运行下面的代码:
print(Univs == Univs1) #测试值是否相等
print(id(Univs) == id(Univs1)) #测试对象是否相等
print('Id of Univs =', id(Univs))
print('Id of Univs1 =', id(Univs1))
会输出:
True
False
Id of Univs = 4447805768
Id of Univs1 = 4456134408
(运行这段代码时,别指望会看到相同的唯一标识符。在Python语义中,每个对象的标识符
没有任何意义,Python仅要求任意两个对象具有不同标识符。)
请注意,图5-2中,Univs中的元素不是Techs和Ivys绑定的列表的复制,而是这些列表本身。
Univs1中的元素也是列表,与Univs中的列表包含同样元素,但不同于Univs中的那些列表。我
们可以通过以下代码确认这一点:
print('Ids of Univs[0] and Univs[1]', id(Univs[0]), id(Univs[1]))
print('Ids of Univs1[0] and Univs1[1]', id(Univs1[0]), id(Univs1[1]))
会输出:
Ids of Univs[0] and Univs[1] 4447807688 4456134664
Ids of Univs1[0] and Univs1[1] 4447805768 4447806728
为什么这一点很重要呢?因为列表是可变的。看下面的代码:
Techs.append('RPI')
append方法具有副作用。它不创建一个新列表,而是通过向列表Techs的末尾添加一个新元素——
字符串'RPI'——改变这个已有的列表。图5-3给出了执行append后的计算状态。
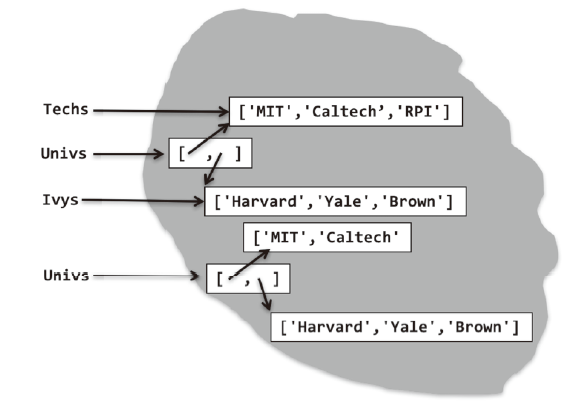
图5-3 可变性演示
Univs绑定的对象仍然包含与原来一样的两个列表,但其中一个列表的内容已经发生变化。
因此,print语句:
print('Univs =', Univs)
print('Univs1 =', Univs1)
现在会输出:
Univs = [['MIT', 'Caltech', 'RPI'], ['Harvard', 'Yale', 'Brown']]
Univs1 = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
这种情况称为对象的别名。两种不同的方式可以引用同一个列表对象。一种方式是通过变量
Techs,另一种方式是通过Univs绑定的list对象中的第一个元素。我们可以通过任意一种方式
改变这个对象,而且改变的结果对两种方式都是可见的。这非常方便,但也留下了隐患。无意形
成的别名会导致程序错误,而且这种错误非常难以捕获。
和元组一样,可以使用for语句遍历列表中的元素。例如:
for e in Univs:
print('Univs contains', e)
print(' which contains')
for u in e:
print(' ', u)
会输出:
Univs contains ['MIT', 'Caltech', 'RPI']
which contains
MIT
Caltech
RPI
Univs contains ['Harvard', 'Yale', 'Brown']
which contains
Harvard
Yale
Brown
我们将一个列表追加到另一个列表中时,如Techs.append(Ivys),会保持原来的结构。也
就是说,结果是一个包含列表的列表。如果我们不想保持原来的结构,而想将一个列表中的元素
添加到另一个列表,那么可以使用列表连接操作或extend方法。如下所示:
L1 = [1,2,3]
L2 = [4,5,6]
L3 = L1 + L2
print('L3 =', L3)
L1.extend(L2)
print('L1 =', L1)
L1.append(L2)
print('L1 =', L1)
会输出:
L3 = [1, 2, 3, 4, 5, 6]
L1 = [1, 2, 3, 4, 5, 6]
L1 = [1, 2, 3, 4, 5, 6, [4, 5, 6]]
请注意,操作符+确实没有副作用,它会创建并返回一个新的列表。相反,extend和append
都会改变L1。
图5-4给出了一些列表操作。请注意,除了count和index外,这些方法都会改变列表。
L.append(e):将对象e追加到L的末尾。
L.count(e):返回e在L中出现的次数。
L.insert(i, e):将对象e插入L中索引值为i的位置。
L.extend(L1):将L1中的项目追加到L末尾。
L.remove(e):从L中删除第一个出现的e。
L.index(e):返回e第一次出现在L中时的索引值。如果e不在L中,则抛出一
个异常(参见第7章)。
L.pop(i):删除并返回L中索引值为i的项目。如果L为空,则抛出一个异常。
如果i被省略,则i的默认值为-1,删除并返回L中的最后一个元素。
L.sort():升序排列L中的元素。
L.reverse():翻转L中的元素顺序图5-4 列表相关操作
5.3.1 克隆
我们通常应该尽量避免修改一个正在进行遍历的列表。例如,考虑以下代码:
def removeDups(L1, L2):
"""假设L1和L2是列表,
删除L2中出现的L1中的元素"""
for e1 in L1:
if e1 in L2:
L1.remove(e1)
L1 = [1,2,3,4]
L2 = [1,2,5,6]
removeDups(L1, L2)
print('L1 =', L1)
你会惊奇地发现,代码会输出:
L1 = [2, 3, 4]
在for循环中,Python使用一个内置计数器跟踪程序在列表中的位置,内部计数器在每次迭
代结束时都会增加1。当计数器的值等于列表的当前长度时,循环终止。如果循环过程中列表没
有发生改变,那么这种机制是有效的,但如果列表发生改变,就会产生出乎意料的结果。本例中,
内置计数器从0开始计数,程序发现了L1[0]在L2中,于是删除了它——将L1的长度减少到3。然
后计数器增加1,代码继续检查L1[1]的值是否在L2中。请注意,这时已经不是初始的L1[1]的值
(2)了,而是当前的L1[1]的值(3)。眼见为实,现在你清楚列表在循环时被修改会发生什么。
但弄清楚这个问题并不容易,而且发生的事情也不是我们故意为之,就像这个例子一样。
避免这种问题的方法是使用切片操作克隆①(即复制)这个列表,并使用for e1 in L1[:]
这种写法。请注意下面这种写法:
newL1 = L1
for e1 in newL1:
不能解决问题。这样不能复制L1,只能为现有列表引入一个新的名称。
在Python中,切片不是克隆列表的唯一方法。表达式list(L)会返回列表L的一份副本。如果
待复制的列表包含可变对象,而且你也想复制这些可变对象,那么可以导入标准库模块copy,然
后使用函数copy.deepcopy。
5.3.2 列表推导
列表推导式提供了一种简洁的方式,将某种操作应用到序列中的一个值上。它会创建一个新
列表,其中的每个元素都是一个序列中的值(如另一个列表中的元素)应用给定操作后的结果。
例如:
L = [x**2 for x in range(1,7)]
print(L)
会输出:
[1, 4, 9, 16, 25, 36]
列表推导中的for从句后面可以有一个或多个if语句和for语句,它们可以应用到for子句产
生的值。这些附加从句可以修改第一个for从句生成的序列中的值,并产生一个新的序列。例如,
以下代码:
mixed = [1, 2, 'a', 3, 4.0]
print([x**2 for x in mixed if type(x) == int])
对mixed中的整数求平方,然后输出[1, 4, 9]。
有些Python程序员会以非常微妙的方式使用列表推导,但这并不值得大力吹捧。请记住,其
他人可能需要阅读你的代码,而“微妙”并不总是每个人都需要的东西。
5.4 函数对象
在Python中,函数是一等对象。这意味着我们可以像对待其他类型的对象(如int或list)
一样对待函数。函数可以具有类型,例如,表达式type(abs)的值是<type 'built-in_function_
or_method'>;函数可以出现在表达式中,如作为赋值语句的右侧项或作为函数的实参;函数可
以是列表中的元素;等等。
使用函数作为实参可以实现一种名为高阶编程的编码方式,这种方式与列表结合使用非常方
便,如图5-5所示。
def applyToEach(L, f):
"""假设L是列表,f是函数
将f(e)应用到L的每个元素,并用返回值替换原来的元素"""
for i in range(len(L)):
L[i] = f(L[i])
L = [1, -2, 3.33]
print('L =', L)
print('Apply abs to each element of L.')
applyToEach(L, abs)
print('L =', L)
print('Apply int to each element of', L)
applyToEach(L, int)
print('L =', L)
print('Apply factorial to each element of', L)
applyToEach(L, factR)
print('L =', L)
print('Apply Fibonnaci to each element of', L)
applyToEach(L, fib)
print('L =', L)
图5-5 将函数应用到列表中的元素
函数applyToEach被称为高阶函数,因为它有一个参数本身就是函数。第一次调用
applyToEach时,它对L中的每个元素应用Python内置的一元函数abs,以修改L中的值。第二次
调用时,它对每个元素应用一个类型转换。第三次调用时,它使用对每个元素应用函数factR(定
义在图4-5中)的结果,替换了相应元素。第四次调用时,它使用对每个元素应用函数fib(定义
在图4-7中)的结果,替换了相应元素。这段代码最后会输出:
L = [1, -2, 3.33]
Apply abs to each element of L.
L = [1, 2, 3.33]
Apply int to each element of [1, 2, 3.33]
L = [1, 2, 3]
Apply factorial to each element of [1, 2, 3]
L = [1, 2, 6]
Apply Fibonnaci to each element of [1, 2, 6]
L = [1, 2, 13]
Python中有一个内置的高阶函数map,它的功能与图5-5中定义的applyToEach函数相似,但
适用范围更广。map函数被设计为与for循环结合使用。在map函数的最简形式中,第一个参数是
个一元函数(即只有一个参数的函数),第二个参数是有序的值集合,集合中的值可以一元函数
的参数。
在for循环中使用map函数时,它的作用类似于range函数,为循环的每次迭代返回一个值。①
这些值是对第二个参数中的每个元素应用一元函数生成的。例如,下面的代码:
for i in map(fib, [2, 6, 4]):
print(i)
会输出:
2
13
5
更一般的形式是,map的第一个参数可以是具有n个参数的函数,在这种情况下,它后面必须
跟随着n个有序集合(这些集合的长度都一样)。例如,下面的代码:
L1 = [1, 28, 36]
L2 = [2, 57, 9]
for i in map(min, L1, L2):
print(i)
会输出:
1
28
9
Python还支持创建匿名函数(即没有绑定名称的函数),这时要使用保留字lambda。Lambda
表达式的一般形式为:
lambda <sequence of variable names>: <expression>
举例来说,Lambda表达式lambda x, y: x*y会返回一个函数,这个函数的返回值为两个参
数的乘积。Lambda表达式经常用作高阶函数的实参。例如,下面的代码:
L = []
for i in map(lambda x, y: x**y, [1 ,2 ,3, 4], [3, 2, 1, 0]):
L.append(i)
print(L)
会输出[1, 4, 3, 1]。
5.5 字符串、元组、范围与列表
我们已经介绍了四种不同的序列类型:str、tuple、range和list。它们的共同之处在于,
都可以使用图5-6中描述的操作,图5-7还总结了一些其他的异同。
seq[i]:返回序列中的第i个元素。
len(sep):返回序列长度。
seq1 + seq2:返回两个序列的连接(不适用于range)。
n*seq:返回一个重复了n次seq的序列。
seq[start:end]:返回序列的一个切片。
e in seq:如果序列包含e,则返回True,否则返回False。
e not in seq:如果序列不包含e,则返回True,否则返回False。
for e in seq:遍历序列中的元素。图5-6 序列类型的通用操作

图5-7 序列类型对比
Python程序员使用列表的频率远超元组,因为列表是可变的,它们可以在计算过程中逐步构
建。例如,以下代码可以增量建立一个列表,包含另一个列表中的所有偶数:
evenElems = []
for e in L:
if e%2 == 0:
evenElems.append(e)
元组的一个优势就在于它是不可变的,所以别名对它来说不是什么问题。与列表不同,元组
作为不可变对象的另一个优势是可以作为字典中的键,5.6节将介绍字典。
因为字符串只能包含字符,所以应用范围远远小于元组和列表。但另一方面,处理字符串时
有大量内置方法可以使用,这使得完成任务非常轻松。图5-8包含了一些字符串方法的简介。请
记住,字符串是不可变的,所以这些方法都返回一个值,而不会对原字符串产生副作用。
s.count(s1):计算字符串s1在s中出现的次数。
s.find(s1):返回子字符串s1在s中第一次出现时的索引值,如果s1不在s中,则返回-1。
s.rfind(s1):功能与find相同,只是从s的末尾开始反向搜索(rfind中的r表示反向)。
s.index(s1):功能与find相同,只是如果s1不在s中,则抛出一个异常(第7章)。
s.index(s1):功能与index相同,只是从s的末尾开始。
s.lower():将s中的所有大写字母转换为小写。
s.replace(old, new):将s中出现过的所有字符串old替换为字符串new。
s.rstrip():去掉s末尾的空白字符。
s.split(d):使用d作为分隔符拆分字符串s,返回s的一个子字符串列表。例如,'David Guttag plays
basketball'.split('')的值是['David', 'Guttag', 'plays', 'basketball']。如果d被省略,则
使用任意空白字符串拆分子字符串。图5-8 一些字符串方法
split是比较重要的内置方法之一,它使用两个字符串作为参数。第二个字符串设定了一个
分隔符,将第一个参数拆分成一系列子字符串。例如:
print('My favorite professor--John G.--rocks'.split(' '))
print('My favorite professor--John G.--rocks'.split('-'))
print('My favorite professor--John G.--rocks'.split('--'))
会输出:
['My', 'favorite', 'professor--John', 'G.--rocks']
['My favorite professor', '', 'John G.', '', 'rocks']
['My favorite professor', 'John G.', 'rocks']
第二个参数是可选的,如果省略该参数,则使用任意空白字符(空格、制表符、换行符、回
车和分页符)组成的字符串拆分第一个字符串。
5.6 字典
字典(dict,dictionary的缩写)类型的对象与列表很相似,区别在于字典使用键对其中的值
进行引用,可以将字典看作一个键/值对的集合。字典类型的字面量用大括号表示,其中的元素
写法是键加冒号再加上值。例如,以下代码:
monthNumbers = {'Jan':1, 'Feb':2, 'Mar':3, 'Apr':4, 'May':5,
1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May'}
print('The third month is ' + monthNumbers[3])
dist = monthNumbers['Apr'] - monthNumbers['Jan']
print('Apr and Jan are', dist, 'months apart')
会输出:
The third month is Mar
Apr and Jan are 3 months apart dict中的项目是无序的,不能通过索引引用。这就是为什么monthNumbers[1]确定无疑地指
向键为1的项目,而不是第二个项目。
和列表一样,字典是可变的。我们可以使用以下代码增加一个项目:
monthNumbers['June'] = 6
或者改变一个项目:
monthNumbers['May'] = 'V'
字典是Python最强大的功能之一,它可以大大降低编程的难度。举例来说,在图5-9中,我们
使用字典完成了一个(相当恐怖的)程序,实现了不同语言互译。因为有行代码太长了,在一行
中放不下,所以我们使用反斜杠\,表示下一行是上一行的延续。
EtoF = {'bread':'pain', 'wine':'vin', 'with':'avec', 'I':'Je',
'eat':'mange', 'drink':'bois', 'John':'Jean',
'friends':'amis', 'and': 'et', 'of':'du','red':'rouge'}
FtoE = {'pain':'bread', 'vin':'wine', 'avec':'with', 'Je':'I',
'mange':'eat', 'bois':'drink', 'Jean':'John',
'amis':'friends', 'et':'and', 'du':'of', 'rouge':'red'}
dicts = {'English to French':EtoF, 'French to English':FtoE}
def translateWord(word, dictionary):
if word in dictionary.keys():
return dictionary[word]
elif word != '':
return '"' + word + '"'
return word
def translate(phrase, dicts, direction):
UCLetters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
LCLetters = 'abcdefghijklmnopqrstuvwxyz'
letters = UCLetters + LCLetters
dictionary = dicts[direction]
translation = ''
word = ''
for c in phrase:
if c in letters:
word = word + c
else:
translation = translation\
+ translateWord(word, dictionary) + c
word = ''
return translation + ' ' + translateWord(word, dictionary)
print translate('I drink good red wine, and eat bread.',
dicts,'English to French')
print translate('Je bois du vin rouge.',
dicts, 'French to English')图5-9 (糟糕的)文本翻译
图中的代码会输出:
Je bois "good" rouge vin, et mange pain.
I drink of wine red.
请记住字典是可变的,所以我们必须注意副作用。例如,以下代码:
FtoE['bois'] = 'wood'
Print(translate('Je bois du vin rouge.', dicts, 'French to English'))
会输出:
I wood of wine red
多数编程语言都不包含这种提供从键到值的映射关系的内置类型。然而,程序员可以使用其
他类型实现同样的功能。例如,使用其中元素为键/值对的列表就可以轻松实现字典,然后可以
编写一个简单的函数进行关联搜索,如下所示:
def keySearch(L, k):
for elem in L:
if elem[0] == k:
return elem[1]
return None
这种实现的问题在于计算效率太低。最坏情况下,程序执行一次搜索可能需要检查列表中的
每一个元素。而内置实现则非常快,它使用的技术称为散列,搜索时间几乎与字典大小无关。第
10章将介绍散列技术。
可以使用for语句遍历字典中的项目。但分配给迭代变量的值是字典键,不是键/值对。迭代
过程中没有定义键的顺序。例如,以下代码:
monthNumbers = {'Jan':1, 'Feb':2, 'Mar':3, 'Apr':4, 'May':5,
1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May'}
keys = []
for e in monthNumbers:
keys.append(str(e))
print(keys)
keys.sort()
print(keys)
可能会输出:
['Jan', 'Mar', '2', '3', '4', '5', '1', 'Feb', 'May', 'Apr']
['1', '2', '3', '4', '5', 'Apr', 'Feb', 'Jan', 'Mar', 'May']
keys方法返回一个dict_keys类型的对象。①这是view对象的一个例子。视图中没有定义视
图的顺序。视图对象是动态的,因为如果与其相关的对象发生变化,我们就可以通过视图对象察
觉到这种变化。例如:
birthStones = {'Jan':'Garnet', 'Feb':'Amethyst', 'Mar':'Acquamarine',
'Apr':'Diamond', 'May':'Emerald'}
months = birthStones.keys()
print(months)
birthStones['June'] = 'Pearl'
print(months)
可能会输出:
dict_keys(['Jan', 'Feb', 'May', 'Apr', 'Mar'])
dict_keys(['Jan', 'Mar', 'June', 'Feb', 'May', 'Apr'])
可以使用for语句遍历dict_type类型的对象,也可以使用in检测其中的成员。dict_type
类型的对象可以很容易地转换为列表,如list(months)。
并非所有对象都可以用作字典键:键必须是一个可散列类型的对象。如果一个类型具有以下
两条性质,就可以说它是“可散列的”:
具有__hash__方法,可以将一个这种类型的对象映射为一个int值,而且对于每一个对象,
由__hash__返回的值在这个对象的生命周期中是不变的;
具有__eq__方法,可以比较两个对象是否相等。
所有Python内置的不可变类型都是可散列的,而且所有Python内置的可变类型都是不可散列
的。使用元组作为字典键往往很方便,例如,如果使用(flightNumber, day)这种形式的元组表
示航空公司的航班,那么可以很轻松地使用这种元组作为字典中的键,来映射航班与到达时间之
间的关系。
与列表一样,字典也有很多非常有用的方法,包括一些删除元素的方法。我们不在此一一列
举,但在本书后面的例子中,我们会为了方便而使用一些字典方法。图5-10包含了一些最常用的
字典操作。①
len(d):返回d中项目的数量。
d.keys():返回d中所有键的视图。
d.values():返回d中所有值的视图。
k in d:如果k在d中,则返回True。
d[k]:返回d中键为k的项目。
d.get(k, v):如果k在d中,则返回d[k],否则返回v。
d[k] = v:在d中将值v与键k关联。如果已经有一个与k关联的值,则替换。
del d[k]:从d中删除键k。
for k in d:遍历d中的键。图5-10 一些常用的字典操作



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











