







在本章中,你将从网上下载数据,并对这些数据进行可视化。网
上的数据多得难以置信,且大多未经过仔细检查。如果能够对这
些数据进行分析,你就能发现别人没有发现的规律和关联。
我们将访问并可视化以两种常见格式存储的数据:CSV和JSON。我
们将使用Python模块csv来处理以CSV(逗号分隔的值)格式存储
的天气数据,找出两个不同地区在一段时间内的最高温度和最低
温度。然后,我们将使用matplotlib根据下载的数据创建一个图
表,展示两个不同地区的气温变化:阿拉斯加锡特卡和加州死亡
谷。在本章的后面,我们将使用模块json来访问以JSON格式存储
的交易收盘价数据,并使用Pygal绘制图形以探索价格变化的周期
性。
阅读本章后,你将能够处理各种类型和格式的数据集,并对如何
创建复杂的图表有更深入的认识。要处理各种真实世界的数据
集,必须能够访问并可视化各种类型和格式的在线数据。
16.1 CSV文件格式
要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号
分隔的值(CSV)写入文件。这样的文件称为CSV文件。例如,下面是
一行CSV格式的天气数据:
2014-1-
5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195
这是阿拉斯加锡特卡2014年1月5日的天气数据,其中包含当天的最高
气温和最低气温,还有众多其他数据。CSV文件对人来说阅读起来比较
麻烦,但程序可轻松地提取并处理其中的值,这有助于加快数据分析
过程。
我们将首先处理少量锡特卡的CSV格式的天气数据,这些数据可在本书
的配套资源(http://www.ituring.com.cn/book/1861)中找到。请将
文件sitka_weather_07-2014.csv复制到存储本章程序的文件夹中(下
载本书的配套资源后,你就有了这个项目所需的所有文件)。
注意 这个项目使用的天气数据是从
http://www.wunderground.com/history/下载而来的。
16.1.1 分析CSV文件头
csv模块包含在Python标准库中,可用于分析CSV文件中的数据行,让
我们能够快速提取感兴趣的值。下面先来查看这个文件的第一行,其
中包含一系列有关数据的描述:
highs_lows.py
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f: ❶
reader = csv.reader(f) ❷
header_row = next(reader) ❸
print(header_row)
导入模块csv后,我们将要使用的文件的名称存储在filename中。
接下来,我们打开这个文件,并将结果文件对象存储在f中(见❶)。
然后,我们调用csv.reader(),并将前面存储的文件对象作为实参
传递给它,从而创建一个与该文件相关联的阅读器(reader)对象
(见❷)。我们将这个阅读器对象存储在reader中。
模块csv包含函数next(),调用它并将阅读器对象传递给它时,它将
返回文件中的下一行。在前面的代码中,我们只调用了next()一
次,因此得到的是文件的第一行,其中包含文件头(见❸)。我们将
返回的数据存储在header_row中。正如你看到的,header_row包
含与天气相关的文件头,指出了每行都包含哪些数据:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min
TemperatureF',
'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max
Humidity',
' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn',
' Mean Sea Level PressureIn', ' Min Sea Level PressureIn',
' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min
VisibilityMiles',
' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH',
'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一
个元素存储在列表中。文件头AKDT表示阿拉斯加时间(Alaska
Daylight Time),其位置表明每行的第一个值都是日期或时间。文件
头Max TemperatureF指出每行的第二个值都是当天的最高华氏温
度。可通过阅读其他的文件头来确定文件包含的信息类型。
注意 文件头的格式并非总是一致的,空格和单位可能出现在奇
怪的地方。这在原始数据文件中很常见,但不会带来任何问题。
16.1.2 打印文件头及其位置
为让文件头数据更容易理解,将列表中的每个文件头及其位置打印出
来:
highs_lows.py
--snip--
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
for index, column_header in enumerate(header_row): ❶
print(index, column_header)
我们对列表调用了enumerate()(见❶)来获取每个元素的索引及其
值。(请注意,我们删除了代码行print(header_row),转而显示
这个更详细的版本。)
输出如下,其中指出了每个文件头的索引:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
3 Min TemperatureF
--snip--
20 CloudCover
21 Events
22 WindDirDegrees
从中可知,日期和最高气温分别存储在第0列和第1列。为研究这些数
据,我们将处理sitka_weather_07-2014.csv中的每行数据,并提取其
中索引为0和1的值。
16.1.3 提取并读取数据
知道需要哪些列中的数据后,我们来读取一些数据。首先读取每天的
最高气温:
highs_lows.py
import csv
# 从文件中获取最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
highs = [] ❶
for row in reader: ❷
highs.append(row[1]) ❸
print(highs)
我们创建了一个名为highs的空列表(见❶),再遍历文件中余下的
各行(见❷)。阅读器对象从其停留的地方继续往下读取CSV文件,每
次都自动返回当前所处位置的下一行。由于我们已经读取了文件头
行,这个循环将从第二行开始——从这行开始包含的是实际数据。每
次执行该循环时,我们都将索引1处(第2列)的数据附加到highs末
尾(见❸)。
下面显示了highs现在存储的数据:
['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57',
'59', '57',
'61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59',
'57', '57',
'61', '59', '61', '61', '66']
我们提取了每天的最高气温,并将它们作为字符串整洁地存储在一个
列表中。
下面使用int()将这些字符串转换为数字,让matplotlib能够读取它
们:
highs_lows.py
--snip--
highs = []
for row in reader:
high = int(row[1]) ❶
highs.append(high)
print(highs)
在❶处,我们将表示气温的字符串转换成了数字,再将其附加到列表
末尾。这样,最终的列表将包含以数字表示的每日最高气温:
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61,
59, 63, 60, 57,
69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
下面来对这些数据进行可视化。
16.1.4 绘制气温图表
为可视化这些气温数据,我们首先使用matplotlib创建一个显示每日
最高气温的简单图形,如下所示:
highs_lows.py
import csv
from matplotlib import pyplot as plt
# 从文件中获取最高气温
--snip--
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(highs, c='red') ❶
# 设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24) ❷
plt.xlabel('', fontsize=16) ❸
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
我们将最高气温列表传给plot()(见❶),并传递c='red'以便将
数据点绘制为红色(红色显示最高气温,蓝色显示最低气温)。接下
来,我们设置了一些其他的格式,如字体大小和标签(见❷),这些
都在第15章介绍过。鉴于我们还没有添加日期,因此没有给x轴添加标
签,但plt.xlabel()确实修改了字体大小,让默认标签更容易看
清。图16-1显示了绘制的图表:一个简单的折线图,显示了阿拉斯加
锡特卡2014年7月每天的最高气温。
图16-1 阿拉斯加锡特卡2014年7月每日最高气温折线图
16.1.5 模块datetime
下面在图表中添加日期,使其更有用。在天气数据文件中,第一个日
期在第二行:
2014-7-1,64,56,50,53,51,48,96,83,58,30.19,--snip--
读取该数据时,获得的是一个字符串,因为我们需要想办法将字符
串'2014-7-1'转换为一个表示相应日期的对象。为创建一个表示
2014年7月1日的对象,可使用模块datetime中的方法
strptime()。我们在终端会话中看看strptime()的工作原理:
>>> from datetime import datetime
>>> first_date = datetime.strptime('2014-7-1', '%Y-%m-%d')
>>> print(first_date)
2014-07-01 00:00:00
我们首先导入了模块datetime中的datetime类,然后调用方法
strptime(),并将包含所需日期的字符串作为第一个实参。第二个
实参告诉Python如何设置日期的格式。在这个示例中,'%Y-'让
Python将字符串中第一个连字符前面的部分视为四位的年份;'%m-
'让Python将第二个连字符前面的部分视为表示月份的数字;
而'%d'让Python将字符串的最后一部分视为月份中的一天(1~31)。
方法strptime()可接受各种实参,并根据它们来决定如何解读日
期。表16-1列出了其中一些这样的实参。
表16-1 模块datetime中设置日期和时间格式的实参
实参含义
%A 星期的名称,如Monday
%B 月份名,如January
%m 用数字表示的月份(01~12)
%d 用数字表示月份中的一天(01~31)
%Y 四位的年份,如2015
%y 两位的年份,如15
%H 24小时制的小时数(00~23)
%I 12小时制的小时数(01~12)
%p am或pm
%M 分钟数(00~59)
实参含义
%S 秒数(00~61)
16.1.6 在图表中添加日期
知道如何处理CSV文件中的日期后,就可对气温图形进行改进了,即提
取日期和最高气温,并将它们传递给plot(),如下所示:
highs_lows.py
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# 从文件中获取日期和最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs = [], [] ❶
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d") ❷
dates.append(current_date)
high = int(row[1])
highs.append(high)
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red') ❸
# 设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate() ❹
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
我们创建了两个空列表,用于存储从文件中提取的日期和最高气温
(见❶)。然后,我们将包含日期信息的数据(row[0])转换为
datetime对象(见❷),并将其附加到列表dates末尾。在❸处,我
们将日期和最高气温值传递给plot()。在❹处,我们调用了
fig.autofmt_xdate()来绘制斜的日期标签,以免它们彼此重叠。
图16-2显示了改进后的图表。
图16-2 现在图表的 x 轴上有日期,含义更丰富
16.1.7 涵盖更长的时间
设置好图表后,我们来添加更多的数据,以成一幅更复杂的锡特卡天
气图。请将文件sitka_weather_2014.csv复制到存储本章程序的文件
夹中,该文件包含Weather Underground提供的整年的锡特卡天气数
据。
现在可以创建覆盖整年的天气图了:
highs_lows.py
--snip--
# 从文件中获取日期和最高气温
filename = 'sitka_weather_2014.csv' ❶
with open(filename) as f:
--snip--
# 设置图形的格式
plt.title("Daily high temperatures - 2014", fontsize=24) ❷
plt.xlabel('', fontsize=16)
--snip--
我们修改了文件名,以使用新的数据文件
sitka_weather_2014.csv(见❶);我们还修改了图表的标题,以反
映其内容的变化(见❷)。图16-3显示了生成的图形。
图16-3 一年的天气数据
16.1.8 再绘制一个数据系列
图16-3所示的改进后的图表显示了大量意义深远的数据,但我们可以
在其中再添加最低气温数据,使其更有用。为此,需要从数据文件中
提取最低气温,并将它们添加到图表中,如下所示:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], [] ❶
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3]) ❷
lows.append(low)
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red')
plt.plot(dates, lows, c='blue') ❸
# 设置图形的格式
plt.title("Daily high and low temperatures - 2014", fontsize=24) ❹
--snip--
在❶处,我们添加了空列表lows,用于存储最低气温。接下来,我们
从每行的第4列(row[3])提取每天的最低气温,并存储它们(见
❷)。在❸处,我们添加了一个对plot()的调用,以使用蓝色绘制最
低气温。最后,我们修改了标题(见❹)。图16-4显示了这样绘制出
来的图表。
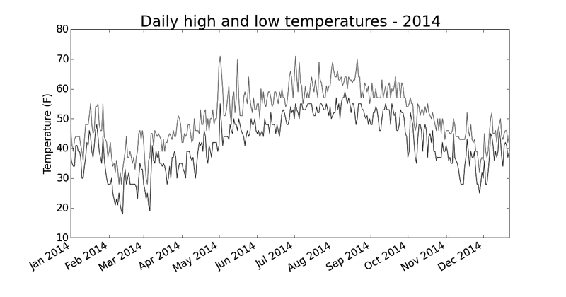
图16-4 在一个图表中包含两个数据系列
16.1.9 给图表区域着色
添加两个数据系列后,我们就可以了解每天的气温范围了。下面来给
这个图表做最后的修饰,通过着色来呈现每天的气温范围。为此,我
们将使用方法fill_between(),它接受一个 x 值系列和两个 y 值
系列,并填充两个 y 值系列之间的空间:
highs_lows.py
--snip--
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red', alpha=0.5) ❶
plt.plot(dates, lows, c='blue', alpha=0.5)
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
❷
--snip--
❶处的实参alpha指定颜色的透明度。Alpha值为0表示完全透明,
1(默认设置)表示完全不透明。通过将alpha设置为0.5,可让红色
和蓝色折线的颜色看起来更浅。
在❷处,我们向fill_between()传递了一个 x 值系列:列表
dates,还传递了两个 y 值系列:highs和lows。实参facecolor
指定了填充区域的颜色,我们还将alpha设置成了较小的值0.1,让填
充区域将两个数据系列连接起来的同时不分散观察者的注意力。图16-
5显示了最高气温和最低气温之间的区域被填充的图表。
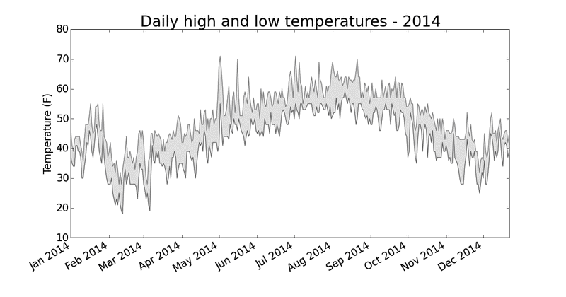
图16-5 给两个数据集之间的区域着色
通过着色,让两个数据集之间的区域显而易见。
16.1.10 错误检查
我们应该能够使用有关任何地方的天气数据来运行highs_lows.py中的
代码,但有些气象站会偶尔出现故障,未能收集部分或全部其应该收
集的数据。缺失数据可能会引发异常,如果不妥善地处理,还可能导
致程序崩溃。
例如,我们来看看生成加利福尼亚死亡谷的气温图时出现的情况。将
文件death_valley_2014.csv复制到本章程序所在的文件夹,再修改
highs_lows.py,使其生成死亡谷的气温图:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
--snip--
运行这个程序时,出现了一个错误,如下述输出的最后一行所示:
Traceback (most recent call last):
File "highs_lows.py", line 17, in <module>
high = int(row[1])
ValueError: invalid literal for int() with base 10: ''
该traceback指出,Python无法处理其中一天的最高气温,因为它无法
将空字符串(' ')转换为整数。只要看一下
death_valley_2014.csv,就能发现其中的问题:
2014-2-16,,,,,,,,,,,,,,,,,,,0.00,,,-1
其中好像没有记录2014年2月16日的数据,表示最高温度的字符串为
空。为解决这种问题,我们在从CSV文件中读取值时执行错误检查代
码,对分析数据集时可能出现的异常进行处理,如下所示:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
try: ❶
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date, 'missing data') ❷
else:
dates.append(current_date) ❸
highs.append(high)
lows.append(low)
#根据数据绘制图形
--snip--
#设置图形的格式
title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
❹
plt.title(title, fontsize=20)
--snip--
对于每一行,我们都尝试从中提取日期、最高气温和最低气温(见
❶)。只要缺失其中一项数据,Python就会引发ValueError异常,
而我们可这样处理:打印一条错误消息,指出缺失数据的日期(见
❷)。打印错误消息后,循环将接着处理下一行。如果获取特定日期
的所有数据时没有发生错误,将运行else代码块,并将数据附加到相
应列表的末尾(见❸)。鉴于我们绘图时使用的是有关另一个地方的
信息,我们修改了标题,在图表中指出了这个地方(见❹)。
如果你现在运行highs_lows.py,将发现缺失数据的日期只有一
个:
2014-02-16 missing data
图16-6显示了绘制出的图形。
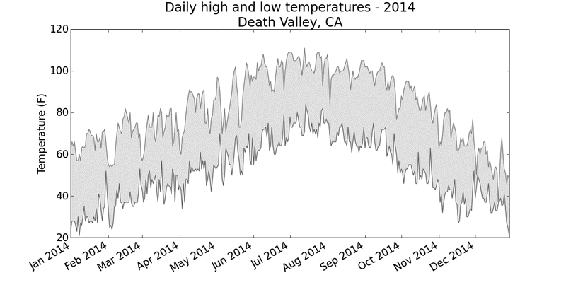
图16-6 死亡谷每日高气温和最低气温
将这个图表与锡特卡的图表对比可知,总体而言,死亡谷比阿拉斯加
东南部暖和,这可能符合预期,但这个沙漠中每天的温差也更大,从
着色区域的高度可以明显看出这一点。
使用的很多数据集都可能缺失数据、数据格式不正确或数据本身不正
确。对于这样的情形,可使用本书前半部分介绍的工具来处理。在这
里,我们使用了一个try-except-else代码块来处理数据缺失的问
题。在有些情况下,需要使用continue来跳过一些数据,或者使用
remove()或del将已提取的数据删除。可采用任何管用的方法,只
要能进行精确而有意义的可视化就好。
动手试一试
16-1 旧金山:旧金山的气温更接近于锡特卡还是死亡谷呢?请
绘制一个显示旧金山最高气温和最低气温的图表,并进行比较。
可从http://www.wunderground.com/history/下载几乎任何地方
的天气数据。为此,请输入相应的地方和日期范围,滚动到页面
底部,找到名为Comma-Delimited File的链接,再单击该链接,
将数据存储为CSV文件。
16-2 比较锡特卡和死亡谷的气温:在有关锡特卡和死亡谷的图
表中,气温刻度反映了数据范围的不同。为准确地比较锡特卡和
死亡谷的气温范围,需要在y轴上使用相同的刻度。为此,请修改
图16-5和图16-6所示图表的y 轴设置,对锡特卡和死亡谷的气温
范围进行直接比较(你也可以对任何两个地方的气温范围进行比
较)。你还可以尝试在一个图表中呈现这两个数据集。
16-3 降雨量:选择你感兴趣的任何地方,通过可视化将其降雨
量呈现出来。为此,可先只涵盖一个月的数据,确定代码正确无
误后,再使用一整年的数据来运行它。
16-4 探索:生成一些图表,对你好奇的任何地方的其他天气数
据进行研究。
16.2 制作交易收盘价走势图:JSON 格
式
在本节中 ,你将下载JSON格式的交易收盘价数据,并使用模块json
来处理它们。Pygal提供了一个适合初学者使用的绘图工具,你将使用
它来对收盘价数据进行可视化,以探索价格变化的周期性。
本节为陶俊杰根据原作编写。源代码请见本书主页
http://www.ituring.com.cn/book/1861,代码为Python 3版本,尽量支持Python 2版
本,可以在binder容器中执行jupyter notebook。——编者注
16.2.1 下载收盘价数据
收盘价数据文件位于
https://raw.githubusercontent.com/muxuezi/btc/master/btc_clos
e_2017.json。可以直接将文件btc_close_2017.json下载到本章程序
所在的文件夹中,也可以用Python 2.x 标准库中模块
urllib2(Python 3.x 版本使用的是urllib)的函数urlopen来
做,还可以通过Python的第三方模块requests(将在第17章介绍)
下载数据。
首先,我们直接下载btc_close_2017.json,看看如何着手处理这个文
件中的数据:
btc_close_2017.json
[
{
"date": "2017-01-01",
"month": "01",
"week": "52",
"weekday": "Sunday",
"close": "6928.6492"
},
--snip--
{
"date": "2017-12-12",
"month": "12",
"week": "50",
"weekday": "Tuesday",
"close": "113732.6745"
}
]
这个文件实际上就是一个很长的Python列表,其中每个元素都是一个
包含五个键的字典:统计日期、月份、周数、周几以及收盘价。由于
2017年1月1日是周日,作为2017年的第一周实在太短,因此将其计入
2016年的第52周。于是2017年的第一周是从2017年1月2日(周一)开
始的。如果用函数urlopen来下载数据,可以使用下面的代码:
btc_close_2017.py
from __future__ import (absolute_import, division,
print_function, unicode_literals)
try: ❶
# Python 2.x 版本
from urllib2 import urlopen
except ImportError:
# Python 3.x 版本
from urllib.request import urlopen
import json
json_url =
'https://raw.githubusercontent.com/muxuezi/btc/master/btc_close_20
17.json'
response = urlopen(json_url) ❷
# 读取数据
req = response.read()
# 将数据写入文件
with open('btc_close_2017_urllib.json','wb') as f: ❸
f.write(req)
# 加载json格式
file_urllib = json.loads(req) ❹
print(file_urllib)
首先导入下载文件使用的模块。这里用try/except语句(见❶)实
现兼容Python 2.x和Python 3.x代码。ImportError可以作为判断
Python 2.x 和Python 3.x 的方式:如果用Python 2.x 版本运行代
码,from urllib2 import urlopen代码就会执行;如果用
Python 3.x 版本运行代码,由于没有urllib2模块,解释器就会触
发ImportError,因此from urllib.request import
urlopen代码就会执行。条条大路通罗马,最终都会导入urlopen函
数。
然后导入模块json,以便之后能够正确地加载文件中的数据。我们的
btc_close_2017.json文件放在GitHub网站上,
urlopen(json_url)是将json_url网址传入urlopen函数(见
❷)。这行代码执行后, Python就会向GitHub的服务器发送请求。
GitHub的服务器响应请求后把btc_close_2017.json文件发送给
Python,之后用response.read()就可以读取文件数据。这时,可
以将文件数据保存到文件夹中(见❸),
btc_close_2017_urllib.json与btc_close_2017.json的内容是一样
的。最后,我们用函数json.load()(见❹)将文件内容转换成
Python能够处理的格式,与前面直接下载的文件内容一致。
函数urlopen的代码稍微复杂一些,第三方模块requests封装了许
多常用的方法,让数据下载和读取方式变得非常简单:
import requests
json_url =
'https://raw.githubusercontent.com/muxuezi/btc/master/btc_close_20
17.json'
req = requests.get(json_url) ❶
# 将数据写入文件
with open('btc_close_2017_request.json','w') as f:
f.write(req.text) ❷
file_requests = req.json() ❸
输出结果为:
{'date': '2017-01-01', 'month': '01', 'week': '52', 'weekday':
'Sunday', 'close': '6928.6492'},
{'date': '2017-01-02', 'month': '01', 'week': '1', 'weekday':
'Monday', 'close': '7070.2554'},
--snip--
{'date': '2017-12-11', 'month': '12', 'week': '50', 'weekday':
'Monday', 'close': '110642.88'},
{'date': '2017-12-12', 'month': '12', 'week': '50', 'weekday':
'Tuesday', 'close': '113732.6745'}
requests通过get方法(见❶)向GitHub服务器发送请求。GitHub服
务器响应请求后,返回的结果存储在req变量中。req.text属性可
以直接读取文件数据,返回格式是字符串(见❷),可以像之前一样
保存为文件btc_close_2017_request.json,其内容与
btc_close_2017_urllib.json是一样的。另外,直接用req.json()
(见❸)就可以将btc_close_2017.json文件的数据转换成Python列表
file_requests,与之前的file_urllib内容相同。
print(file_urllib == file_requests)
输出结果为:
True
16.2.2 提取相关的数据
下面编写一个小程序来提取btc_close_2017.json文件中的相关信息:
btc_close_2017.py
import json
# 将数据加载到一个列表中
filename = 'btc_close_2017.json'
with open(filename) as f:
btc_data = json.load(f) ❶
# 打印每一天的信息
for btc_dict in btc_data: ❷
date = btc_dict['date'] ❸
month = btc_dict['month']
week = btc_dict['week']
weekday = btc_dict['weekday']
close = btc_dict['close']
print("{} is month {} week {}, {}, the close price is {}
RMB".format(date, month, week, weekday, close))
首先导入模块json,然后将数据存储在btc_data中(见❶)。在❷
处,我们遍历了btc_data中的每个元素。每个元素都是一个字典,
包含五个键-值对,btc_dict就用来存储字典中的每个键-值对。之
后就可以取出所有键的值(见❸),并将日期、月份、周数、周几和
收盘价相关联的值分别存储到date、month、week、weekday与
close中。接下来,打印每一天的日期、月份、周数、周几和收盘
价。输出结果如下:
2017-01-01 is month 01 week 52, Sunday, the close price is
6928.6492 RMB
2017-01-02 is month 01 week 1, Monday, the close price is
7070.2554 RMB
2017-01-03 is month 01 week 1, Tuesday, the close price is
7175.1082 RMB
--snip--
2017-12-10 is month 12 week 49, Sunday, the close price is
99525.1027 RMB
2017-12-11 is month 12 week 50, Monday, the close price is
110642.88 RMB
2017-12-12 is month 12 week 50, Tuesday, the close price is
113732.6745 RMB
现在,我们已经掌握了json读取数据的方法。下面,让我们将数据转
换为Pygal能够处理的格式。
16.2.3 将字符串转换为数字值
btc_close_2017.json中的每个键和值都是字符串。为了能在后面的内
容中对交易数据进行计算,需要先将表示周数和收盘价的字符串转换
为数值。因此我们使用函数int():
btc_close_2017.py
--snip--
# 打印每一天的信息
for btc_dict in btc_data:
date = btc_dict['date']
month = int(btc_dict['month'])
week = int(btc_dict['week']) ❶
weekday = btc_dict['weekday']
close = int(btc_dict['close']) ❷
print("{} is month {} week {}, {}, the close price is {}
RMB".format(date, month, week, weekday, close))
在❶处,我们将周数的数值都转换为整数格式。将收盘价close转换
为整数时,出现了ValueError异常,如下所示:
--snip--
5 week = int(btc_dict['week']) ❶
6 weekday = btc_dict['weekday']
----> 7 close = int(btc_dict['close']) ❷
8 print("{} is month {} week {}, {}, the close price is
{} RMB".format(date, month, week, weekday, close))
ValueError: invalid literal for int() with base 10: '6928.6492'
在实际工作中,原始数据的格式经常是不统一的,此类数值类型转换
造成的ValueError异常十分普遍。这里的原因在于,Python不能直
接将包含小数点的字符串'6928.6492'转换为整数。为了消除这种
错误,需要先将字符串转换为浮点数(float),再将浮点数转换为
整数(int):
btc_close_2017.py
--snip--
# 打印每一天的信息
for btc_dict in btc_data:
date = btc_dict['date']
month = int(btc_dict['month'])
week = int(btc_dict['week'])
weekday = btc_dict['weekday']
close = int(float(btc_dict['close'])) ❶
print("{} is month {} week {}, {}, the close price is {}
RMB".format(date, month, week, weekday, close))
这里首先用函数float()将字符串转换为小数(见❶),然后再用函
数int()去掉小数部分(截尾取整),返回整数部分。现在,再次运
行代码,就不会出现异常了。打印出的收盘价信息如下:
2017-01-01 is month 1 week 52, Sunday, the close price is 6928 RMB
2017-01-02 is month 1 week 1, Monday, the close price is 7070 RMB
2017-01-03 is month 1 week 1, Tuesday, the close price is 7175 RMB
--snip--
2017-12-10 is month 12 week 49, Sunday, the close price is 99525
RMB
2017-12-11 is month 12 week 50, Monday, the close price is 110642
RMB
2017-12-12 is month 12 week 50, Tuesday, the close price is 113732
RMB
现在,收盘价都已经成功地先从字符串转换成浮点数,再从浮点数转
换成了整数。另外,我们还发现,月份中原来1~9月前面的数字0在转
换成整数之后都消失了,周数的数据也根据我们的需求转换成了整
数。有了这些数据之后,可以结合Pygal的可视化功能来探索一些有趣
的信息。
16.2.4 绘制收盘价折线图
第15章已经介绍了用Pygal绘制条形图(bar chart)的方法,也介绍
了用matplotlib绘制折线图(line chart)的方法。下面用Pygal来实
现收盘价的折线图。
绘制折线图之前,需要获取x 轴与y 轴数据,因此我们创建了几个列
表来存储数据。遍历btc_data,将转换为适当格式的数据存储到对
应的列表中。对前面的代码做一些简单的调整:
btc_close_2017.py
--snip--
# 创建5个列表,分别存储日期和收盘价
dates = []
months = []
weeks = []
weekdays = []
close = []
# 每一天的信息
for btc_dict in btc_data:
dates.append(btc_dict['date'])
months.append(int(btc_dict['month']))
weeks.append(int(btc_dict['week']))
weekdays.append(btc_dict['weekday'])
close.append(int(float(btc_dict['close'])))
有了x 轴与y 轴的数据,就可以绘制折线图了。由于数据点比较多,x
轴要显示346个日期,在有限的屏幕上会显得十分拥挤。因此我们需要
利用Pygal的配置参数,对图形进行适当的调整。代码如下:
btc_close_2017.py
--snip--
import pygal
line_chart = pygal.Line(x_label_rotation=20,
show_minor_x_labels=False) ❶
line_chart.title = '收盘价(¥)'
line_chart.x_labels = dates
N = 20 # x轴坐标每隔20天显示一次
line_chart.x_labels_major = dates[::N] ❷
line_chart.add('收盘价', close)
line_chart.render_to_file('收盘价折线图(¥).svg')
首先导入模块pygal,然后在创建Line实例时,分别设置了
x_label_rotation与show_minor_x_ labels作为初始化参数
(见❶)。x_label_rotation=20让x 轴上的日期标签顺时针旋转
20°,show_minor_x_labels=False则告诉图形不用显示所有的x
轴标签。设置了图形的标题和x 轴标签之后,我们配置
x_labels_major属性,让x 轴坐标每隔20天显示一次(见❷),这
样x 轴就不会显得非常拥挤了。最终效果如图16-7所示。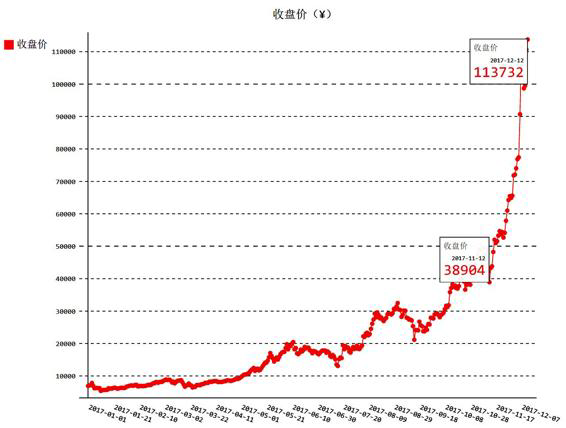
图16-7 收盘价折线图(¥)
从图中可以看出,价格从2017年11月12日到2017年12月12日快速增
长,平均每天增值约2500元人民币,图中折线简直就像火箭发射一
般,垂直升空。下面对价格做一些简单的探索。
16.2.5 时间序列特征初探
进行时间序列分析总是期望发现趋势(trend)、周期性
(seasonality)和噪声(noise),从而能够描述事实、预测未来、
做出决策。从收盘价的折线图可以看出,2017年的总体趋势是非线性
的,而且增长幅度不断增大,似乎呈指数分布。但是,我们还发现,
在每个季度末(3月、6月和9月)似乎有一些相似的波动。尽管这些波
动被增长的趋势掩盖了,不过其中也许有周期性。为了验证周期性的
假设,需要首先将非线性的趋势消除。对数变换(log
transformation)是常用的处理方法之一。让我们用Python标准库的
数学模块math来解决这个问题。math里有许多常用的数学函数,这
里用以10为底的对数函数math.log10计算收盘价,日期仍然保持不
变。这种方式称为半对数(semi-logarithmic)变换。代码如下:
btc_close_2017.py
--snip--
import pygal
import math
line_chart = pygal.Line(x_label_rotation=20,
show_minor_x_labels=False)
line_chart.title = '收盘价对数变换(¥)'
line_chart.x_labels = dates
N = 20 # x轴坐标每隔20天显示一次
line_chart.x_labels_major = dates[::N]
close_log = [math.log10(_) for _ in close] ❶
line_chart.add('log收盘价', close_log)
line_chart.render_to_file('收盘价对数变换折线图(¥).svg')
现在,用对数变换剔除非线性趋势之后,整体上涨的趋势更接近线性
增长。从图16-8中可以清晰地看出,收盘价在每个季度末似乎有显著
的周期性——3月、6月和9月都出现了剧烈的波动。那么,12月是不是
会再现这一场景呢?下面再看看收盘价的月日均值与周日均值的表
现。
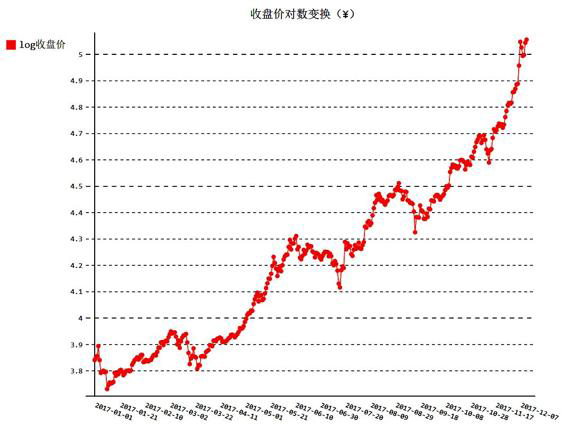
图16-8 收盘价对数变换折线图(¥)
16.2.6 收盘价均值
下面再利用btc_close_2017.json文件中的数据,绘制2017年前11个月
的日均值、前49周(2017-01-02~2017-12-10)的日均值,以及
每周中各天(Monday~Sunday)的日均值。虽然这些日均值的数值
不同,但都是一段时间的均值,计算方法是一样的。因此,可以将之
前的绘图代码封装成函数,以便重复使用。
btc_close_2017.py
--snip--
from itertools import groupby ❶
def draw_line(x_data, y_data, title, y_legend):
xy_map = []
for x, y in groupby(sorted(zip(x_data, y_data)), key=lambda _:
_[0]): ❷
y_list = [v for _, v in y]
xy_map.append([x, sum(y_list) / len(y_list)]) ❸
x_unique, y_mean = [*zip(*xy_map)] ❹
line_chart = pygal.Line()
line_chart.title = title
line_chart.x_labels = x_unique
line_chart.add(y_legend, y_mean)
line_chart.render_to_file(title+'.svg')
return line_chart
由于需要将数据按月份、周数、周几分组,再计算每组的均值,因此
我们导入Python标准库中模块itertools的函数groupby(见❶)。
然后将x 轴与y 轴的数据合并、排序,再用函数groupby分组(见
❷)。分组之后,求出每组的均值,存储到xy_map变量中(见❸)。
最后,将xy_map中存储的x 轴与y 轴数据分离(见❹),就可以像之
前那样用Pygal画图了。下面我们画出收盘价月日均值。由于2017年12
月的数据并不完整,我们只取2017年1月到11月的数据。通过dates查
找2017-12-01的索引位置,确定周数和收盘价的取数范围。代码如
下所示:
idx_month = dates.index('2017-12-01')
line_chart_month = draw_line(months[:idx_month],
close[:idx_month], '收盘价月日均值(¥)',
'月日均值')
line_chart_month
收盘价月日均值如图16-9所示。

















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











