







随着人工智能技术的飞速发展,大型语言模型(LLM)和视觉语言模型(VLM)为我们提供了新的视角和工具,以探索和理解复杂的历史事件。在最近的研究中,一个名为“BattleAgent”的系统被开发出来,它利用这些先进的AI技术来详细仿真历史战役,模拟领导者的决策过程和普通士兵的视角。旨在解决传统历史分析中存在的一些关键问题。它通过模拟历史战役中的复杂动态交互,包括领导者决策和普通士兵视角,填补了传统叙事中对个体经历的忽视。并利用大型视觉语言模型(VLM)和多智能体系统(MAS)创建详细的仿真环境,克服了历史数据稀缺和质量限制的挑战。它还通过实时更新智能体档案和伤亡评估,提供了对战场动态的准确反映。
BattleAgent系统的应用范围广泛,它通过高度仿真的历史战役模拟,为多个领域带来了创新的应用价值。在教育领域,它提供了一个互动和沉浸式的学习平台,使学生能够更深入地理解战争的复杂性和动态变化,从而增强历史和军事策略的教学效果。在历史研究领域,该系统能够辅助研究人员通过模拟重现历史事件,探索不同决策路径及其结果,为历史分析提供新的视角和数据支持。
BattleAgent在人工智能领域也具有重要意义,它推动了大型语言模型(LLM)和视觉语言模型(VLM)在复杂场景下的应用研究,为智能体技术的发展和多模态交互的进步提供了实验平台。该系统还具有成为下一代游戏引擎的潜力,通过生成详细且逼真的环境、角色和事件,为用户提供独特的娱乐体验。
BattleAgent的核心是一个多智能体系统(MAS),它结合了大型视觉语言模型(VLM)来创建一个复杂的仿真环境。这个系统能够模拟多个智能体之间的动态交互,以及智能体与其环境之间的交互。
仿真设置
历史背景的准确性对于模拟的可信度至关重要。研究者精心选择了四场具有决定性影响的欧洲战役,这些战役不仅因其战略和战术的复杂性而闻名,也因其在历史上的重要性而被广泛研究。这四场战役分别是:
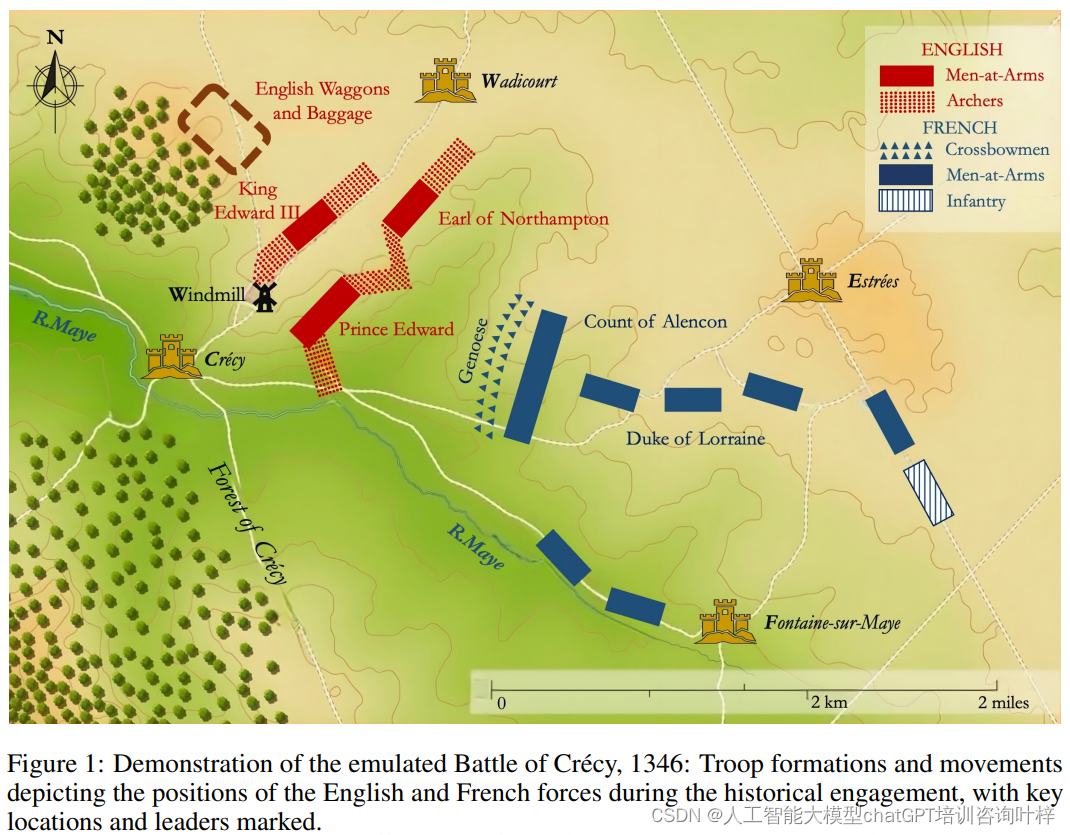
- 克雷西战役:发生在1346年,是百年战争期间的一场重要战役,以英格兰长弓手对抗法国骑士而著称。
- 阿金库尔战役:1415年的这场战役同样是百年战争期间的关键时刻,英格兰军队再次以少胜多,取得了决定性的胜利。
- 普瓦捷战役:1356年的这场战役是英法两国在法国本土的又一次交锋,以英格兰的胜利告终。
- 福尔柯克战役:这场战役发生在1298年,是苏格兰独立战争期间的一场关键战役,英格兰军队在此战役中取得了胜利。

这张图展示了克雷西战役的另一个视角,来自让·弗罗萨特(Jean Froissart)编年史的手抄本插图。它提供了历史战役的视觉呈现,可能包含了当时的军队部署、战斗场景或重要事件的描绘。
为了捕捉这些战役的复杂性,BattleAgent定义了两种类型的智能体:
- 指挥智能体:模拟历史上的军事指挥官,负责制定战略决策和指挥军队。这些智能体被赋予了历史指挥官的战术洞察力和领导风格,其决策将影响模拟冲突的整体结果。
- 士兵智能体:代表战场上的普通士兵,每个士兵智能体都配备了详尽的个人历史、心理特征和对战斗刺激的潜在反应。这些智能体的行动、受伤情况、情绪反应和心理状态将被详细记录和模拟。
智能体的行动空间是仿真中的关键组成部分,它定义了智能体在仿真中可以采取的所有可能行动。在BattleAgent中,行动空间包含51种不同的行动,这些行动被分为七个不同的类别:
- 重新定位:涉及军队或其子部分移动到不同位置的行动。
- 准备:为即将到来的攻击做准备的行动,如部署长弓手、集结部队等。
- 攻击:包括各种常见攻击策略,如小规模冲突、伏击、围攻、骑兵冲锋等。
- 防御:涉及保护、设防和创建障碍物的行动。
- 观察:集中于收集关于周围地区和敌人当前情况的信息。
- 撤退:与战略撤退相关的行动,如撤退和重组、战术撤退等。
这些行动空间的设计允许智能体在仿真中灵活地做出决策,并根据战场情况的变化采取不同的战术和策略。通过这种方式,BattleAgent系统能够模拟出历史战役中的复杂交互和决策过程,为研究者提供了一个深入分析和理解历史事件的工具。
仿真沙盒
在BattleAgent系统的仿真沙盒中,时间和空间的管理是实现历史战役仿真的关键因素。为了模拟战场上的动态变化,系统采用了时间量化的方法,将连续的时间流离散化为固定的时间间隔。在这个系统中,时间被划分为15分钟的时间段,每个时间段代表战场上的一个决策周期。在每个周期开始时,所有智能体会根据当前的战场状况和收集到的信息来决定它们的行动。
沙盒过程是一个迭代的循环,它模拟了战场上的实时决策和行动。
-
初始化环境:在仿真开始之前,沙盒会根据历史战役的地理和战术情况初始化战场环境。这包括地形特征、天气条件、军队的初始位置等。
-
观察环境:每个智能体首先观察战场环境,这包括通过视觉地图和文本描述来收集关于地形、敌我双方位置和行动的信息。这一步骤是多模态的,意味着智能体需要同时处理视觉和文本信息。
-
信息收集:智能体利用其观察结果来收集关键信息,包括敌军的规模、位置、行动意向以及战场的地理特征。这些信息对于智能体做出战略决策至关重要。
-
决策行动:基于收集到的信息,智能体会进行决策过程,选择最佳的行动方案。这些决策可能包括进攻、防御、撤退、重新定位等。
-
执行行动:一旦做出决策,智能体会执行选定的行动。这些行动会根据智能体的类型和战场情况的不同而有所差异。
-
更新状态:行动执行完毕后,沙盒会更新智能体的状态,包括位置、兵力、士气等。这些状态的变化将影响智能体在下一个时间周期的决策。
-
循环迭代:沙盒过程会重复上述步骤,每个15分钟周期结束后,根据所有智能体的行动更新战场的总体状态,然后重新开始下一个周期的观察和决策。
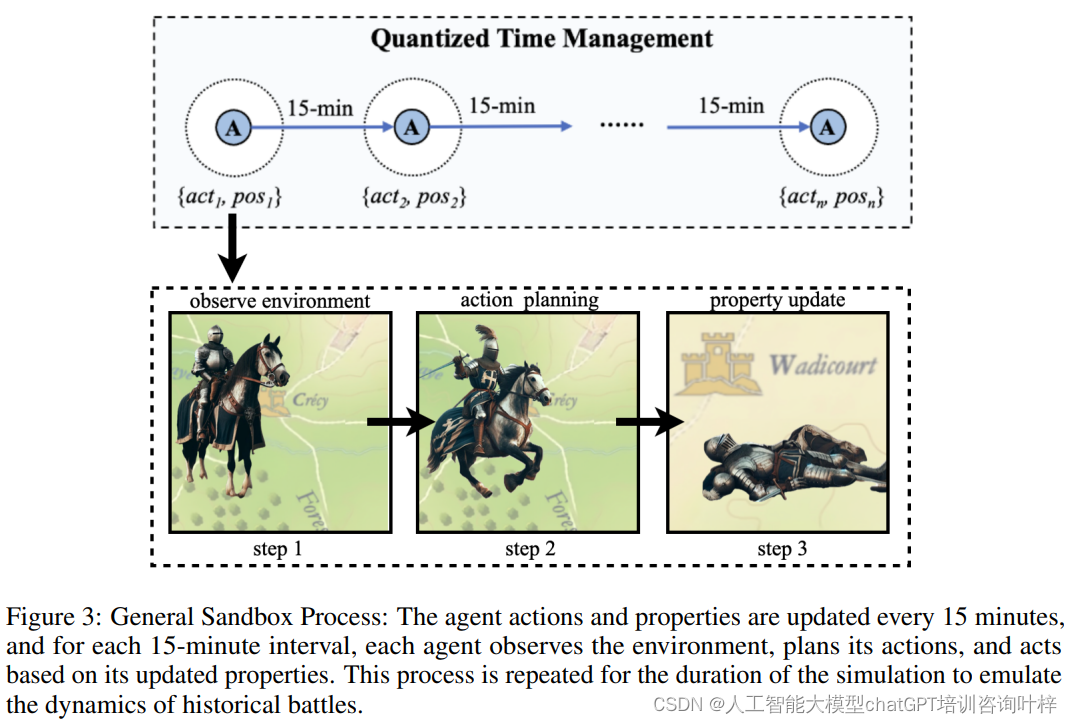
这张图概述了仿真沙盒的一般过程。它展示了仿真中智能体如何观察环境、规划行动以及根据更新的信息和不断演变的战场情况进行行动的迭代过程。
通过这种迭代的仿真沙盒过程,BattleAgent系统能够模拟出历史战役的复杂性和不确定性。智能体的决策和行动不仅受到当前战场状况的影响,还受到之前行动的影响,从而形成了一个动态的、历史依赖的仿真环境。这种方法使得仿真结果更加真实可靠,为研究者提供了深入分析历史战役的可能性。
详细仿真过程
在BattleAgent系统的详细仿真过程中,智能体的决策和行动是模拟历史战役的核心。以下是详细仿真过程的关键步骤:
-
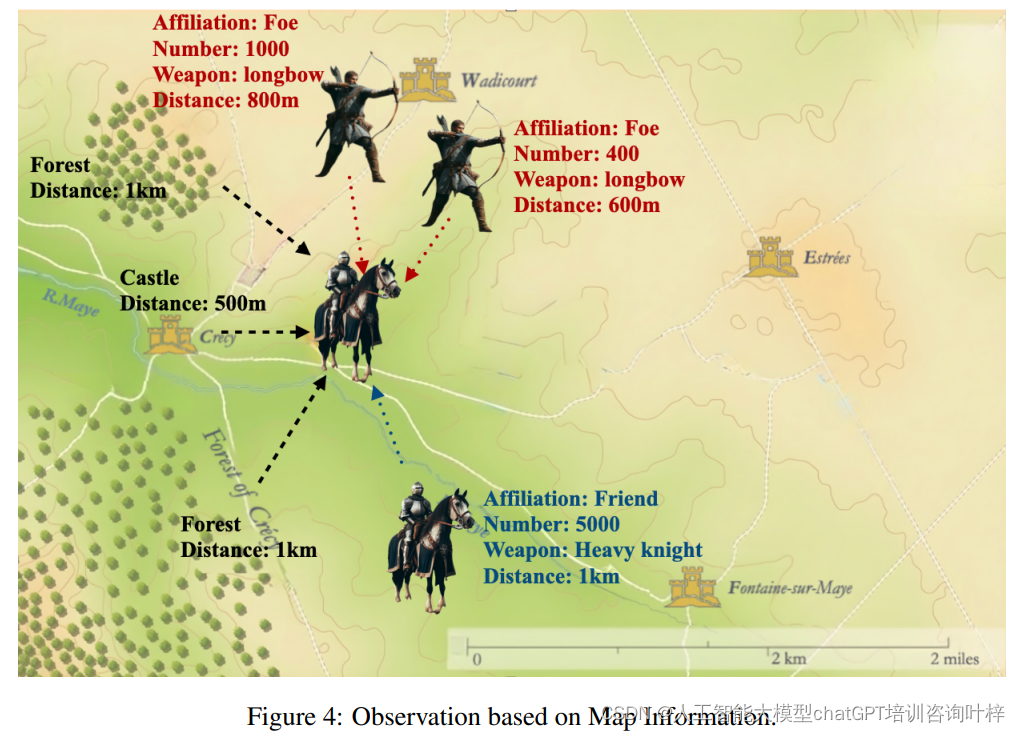
地图信息观察:智能体的观察过程是多模态的,它们通过视觉地图和文本描述来获取环境信息。视觉地图提供了战场的直观布局,包括地形、障碍物和关键地标,而文本描述则提供了更详细的地理和战术信息。这种观察方式模拟了现实世界中指挥官和士兵对战场的感知,为智能体提供了战略规划和行动决策的基础。
-
行动规划:在每个15分钟的时间周期内,智能体会根据收集到的信息和自身的目标来规划行动。行动规划包括但不限于:
- 移动:智能体会根据战场情况选择向有利位置移动,以获得战术优势或避免潜在威胁。
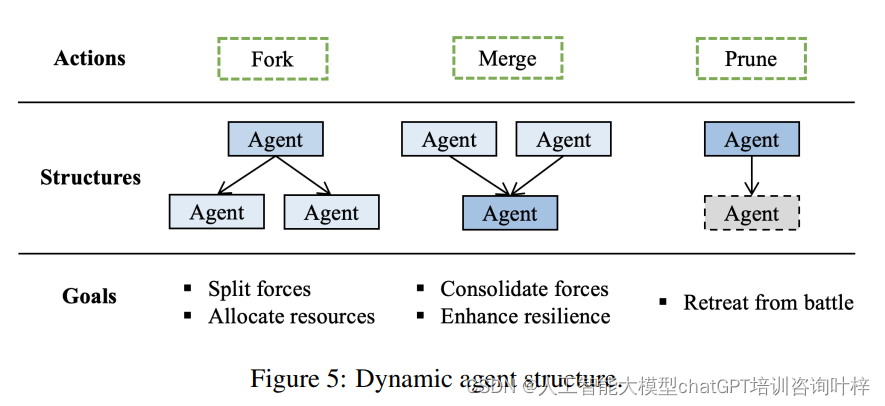
- 动态智能体结构调整:智能体会根据战场需求进行分支(fork)、合并(merge)或缩减(prune),以适应不断变化的战斗环境。
- 交互:智能体会与环境和其他智能体进行交互,这可能包括攻击敌方、防御己方位置或与友军协同作战。
-
行动执行:规划完成后,智能体会执行选定的行动。这些行动会立即影响战场状态,包括智能体的位置、兵力和其他属性。
-
伤亡评估:每当智能体执行攻击行动时,会有一个客观的评估者(通常是一个独立的AI系统)来评估双方的伤亡损失。这个评估过程考虑了多种因素,包括:
- 智能体的当前状态:包括兵力、武器类型、指挥结构和位置。
- 行动的详细描述:智能体执行的具体行动,如使用的战术和策略。
- 智能体之间的相对位置:包括它们之间的距离和周围地形的影响。
- 武器性能:使用的武器类型及其性能指标,如射程和精度。
-
智能体档案更新:执行行动并评估伤亡后,智能体的档案信息会根据最新的情况动态更新。这些信息包括:
- 兵力变化:根据伤亡评估结果调整智能体的兵力。
- 位置更新:如果智能体进行了移动,其位置信息将被更新。
- 状态变化:智能体的士气、纪律和整体战斗效能可能会根据行动结果和战场情况发生变化。
-
历史行动记录:所有智能体的行动和决策都会被记录下来,形成历史行动轨迹。这些历史数据对于智能体在未来时间周期内的决策至关重要,因为它们提供了宝贵的经验和信息。
通过这个详细仿真过程,BattleAgent系统能够模拟出历史战役的复杂性和不确定性,为研究者提供了一个深入分析和理解历史事件的平台。这种仿真不仅能够模拟战役的宏观过程,还能够捕捉到个体士兵的微观体验,为历史研究、军事战略分析和人工智能技术的发展提供了新的视角和工具。
实验
-
实验目的:实验旨在评估BattleAgent系统在模拟历史战役时的准确性和可靠性,特别是智能体在适应快速变化和不可预测的战场情况方面的表现。
-
历史战役选择:研究者选择了四场历史上的重要战役进行仿真,分别是克雷西战役、阿金库尔战役、普瓦捷战役和福尔柯克战役。这些战役因其在军事历史上的重要性和战术多样性而被选中。
-
智能体和模型选择:实验使用了三种不同的语言模型和视觉语言模型:Claude-3-opus、GPT-4-1106-preview和GPT-4-vision。每种模型都被用来模拟上述四场战役,以评估不同模型在仿真历史战役中的表现。
-
仿真执行:对于每个战役和每种模型,仿真在沙盒环境中执行五次,以考虑随机性的影响。仿真持续进行,直到双方的伤亡数字趋于稳定,或达到预设的仿真结束条件。
-
评估指标:实验的评估分为三个方面:
- 最终战斗伤亡:将仿真结果中的伤亡数字与历史记录进行对比,评估仿真的准确性。
- 智能体位置移动:通过人类分析师评估智能体在战场上的移动和动态结构,检查智能体是否能够适应战场变化并执行合理的战术。
- 智能体行动评估:同样通过人类分析师评估智能体的行动是否合理,是否符合历史战役中的实际决策。
 这个表格概述了评估仿真沙盒性能的三个关键维度,旨在通过定量比较和定性分析来全面评估仿真的准确性和有效性。通过这种方法,研究人员可以更好地理解仿真沙盒在重现历史战役方面的潜力,并识别改进仿真性能的机会。
这个表格概述了评估仿真沙盒性能的三个关键维度,旨在通过定量比较和定性分析来全面评估仿真的准确性和有效性。通过这种方法,研究人员可以更好地理解仿真沙盒在重现历史战役方面的潜力,并识别改进仿真性能的机会。
-
结果分析:仿真结束后,研究者分析了仿真结果,包括伤亡数字、智能体的移动路径和行动轨迹。这些分析帮助研究者了解智能体在仿真中的决策过程和战术执行情况。
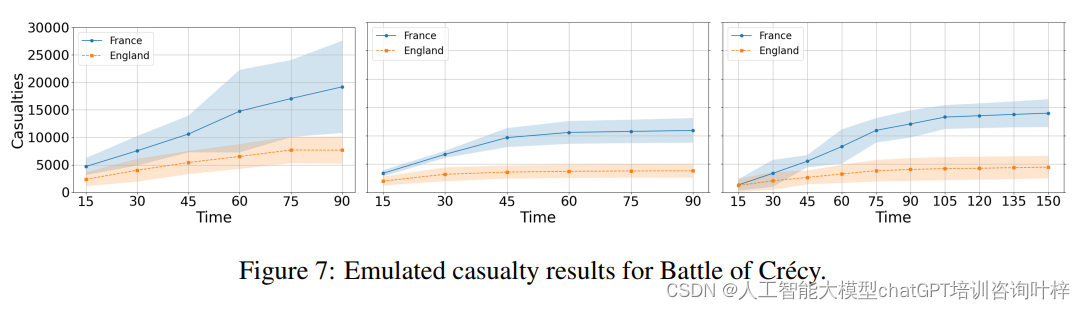 Figure 7比较了不同语言模型(Claude-3、GPT-4、GPT-4-vision)预测的伤亡数字与历史数据。每场战役的仿真结果由三种不同的基于大型语言模型(LLM)和视觉语言模型(VLM)的智能体生成:Claude-3-opus、GPT-4-1106-preview 和 GPT-4-vision。
Figure 7比较了不同语言模型(Claude-3、GPT-4、GPT-4-vision)预测的伤亡数字与历史数据。每场战役的仿真结果由三种不同的基于大型语言模型(LLM)和视觉语言模型(VLM)的智能体生成:Claude-3-opus、GPT-4-1106-preview 和 GPT-4-vision。- Claude-3:在多个战役中,Claude-3模型预测的伤亡率普遍高于GPT-4和GPT-4-vision,且预测的方差较大,表明仿真过程中存在较高程度的随机性。
- GPT-4 和 GPT-4-vision:这两个模型的预测结果相对合理,且与历史记录更为接近,方差也保持在可接受的范围内。
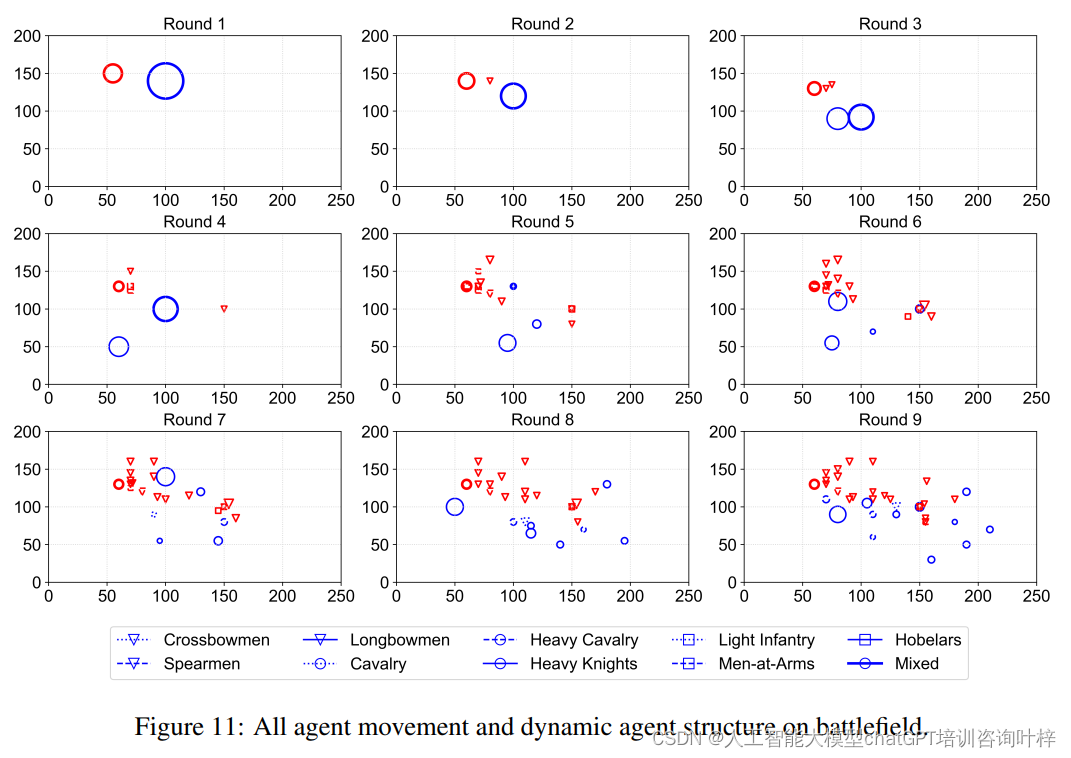
Figure 11展示了单个仿真实例中所有智能体在战场上的移动和动态智能体结构。在示例中,英国军队用红色符号表示,而法国军队用蓝色符号表示。符号的大小标准化,对应于每个智能体包含的士兵数量。
不同的线条类型可能表示不同的智能体行为或状态,例如,实线可能表示移动路径,虚线可能表示某个特定行动或状态的变化。
结果分析:
- 英国军队:英国军队的智能体可能表现出谨慎的战术,如保持安全距离、利用地形优势或执行侧翼包抄等。
- 法国军队:法国军队的智能体可能表现出更积极的战术,如频繁发动攻击,但这也可能导致较大的损失。
动态智能体结构:
- 随着仿真的进行,双方军队可能逐渐分裂成更小的团队,尤其是英国军队。这表明仿真中的智能体能够根据战场情况动态调整其组织结构。
- 例如,一些长弓手可能倾向于长时间保持与敌人的安全距离,利用长弓远程造成伤亡。随着时间的推移,法国军队士兵数量的优势可能会因为地形挑战和长弓手的有效攻击而逐渐减少。
通过这些详细的实验步骤,BattleAgent系统的实验部分不仅验证了其模拟历史战役的能力,还为未来的研究提供了宝贵的数据和见解。这些实验结果有助于进一步优化系统,提高仿真的准确性和可靠性,同时也为历史学家、军事分析师和人工智能研究者提供了新的研究工具。
本文通过BattleAgent系统,展示了如何利用大型语言模型和多智能体系统在历史战役仿真中取得突破。系统不仅重现了宏观战略决策,还捕捉了士兵个体的微观体验,为我们提供了一个全面深入的历史事件理解新视角。BattleAgent不仅为历史学家和教育工作者提供了一个强大的工具,也为人工智能在人文学科中的应用开辟了新天地。随着技术的不断进步和模型的完善,我们期待这一系统将为历史研究带来更深刻的洞见,并为人类社会的发展贡献力量。
论文链接:https://arxiv.org/abs/2404.15532



















 3361
3361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











