







大模型(LLMs)以其卓越的性能在多个应用场景中大放异彩。然而,随着应用的深入,这些模型的推理速度问题逐渐凸显。为了解决这一挑战,推测性解码(Speculative Decoding, SPD)技术应运而生。本文深入探讨了SPD在多模态大型语言模型(MLLMs)中的应用,尤其是针对LLaVA 7B模型的优化。MLLMs通过融合视觉和文本数据,极大地丰富了模型与用户的互动,但同时也面临着自回归生成和内存带宽的瓶颈。SPD技术通过小型草稿模型预测未来标记,并由目标LLM进行快速验证,有效提升了推理效率。实验结果更是令人振奋:即便不依赖图像信息,仅利用文本数据的草稿模型也能实现与使用图像特征的模型相媲美的加速效果。这一发现不仅为MLLMs的高效推理提供了新思路,也为未来在更广泛的应用场景中利用SPD技术奠定了基础。
推测性解码(SPD)
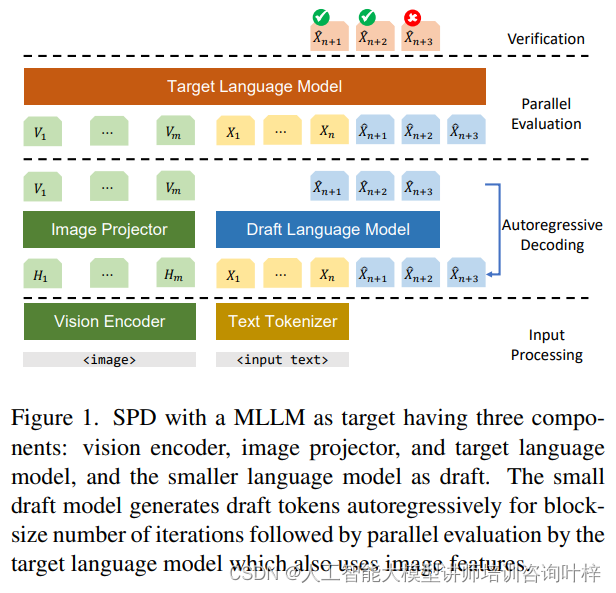
推测性解码是一种创新的解码技术,旨在加速大型语言模型(LLMs)的推理过程。在传统的自回归生成中,模型在生成每个新词时都必须等待前一个词的完成,这限制了生成速度。SPD通过使用一个小型的草稿模型来预测一系列未来的词,然后由目标大型语言模型(LLM)并行验证这些预测,从而显著提高了效率。这种方法允许模型在单个调用中评估多个候选词,而不是逐个生成,从而减少了整体的推理时间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











