






目录
简介
在人工智能的快速发展中,指令微调(Instruction Tuning)成为了提升大型语言模型(LLM)能力的重要手段。与传统的训练方式不同,微调更多聚焦于在现有模型的基础上进行适应性调整,使其能够更好地执行特定任务或响应用户的指令。
本文将带领大家一起深入了解指令微调的概念与实践方法,尤其是针对LLama2-Alpaca模型的微调实现。我们将从数据准备到微调代码的实现,再到如何使用SwanLab来查看微调的进展与结果,全面解析指令微调的整个过程。
链接资料
作者信息:竹梦如烟 邮箱:wind.340171@gmail.com
代码链接:github
模型链接:modelscope/huggingface
数据集链接:modelscope/huggingface
实验结果链接:swanlab(原域名可能会出现访问异常,可通过临时域名临时域名访问网站,期间swanlab安装包和实验跟踪可正常使用。预计2-10个工作日完成备案迁移。)
SwanLab官方文档:
用户指南,可以快速上手SwanLab:🚀快速开始 | SwanLab官方文档
应用案例:入门实验 | SwanLab官方文档

微调的概念
1、微调和训练的差别
首先我们需要了解什么是训练?为什么需要训练?训练和微调在概念有何区别?什么时候需要训练,什么时候需要微调?结果分别是什么样子的?这些问题。
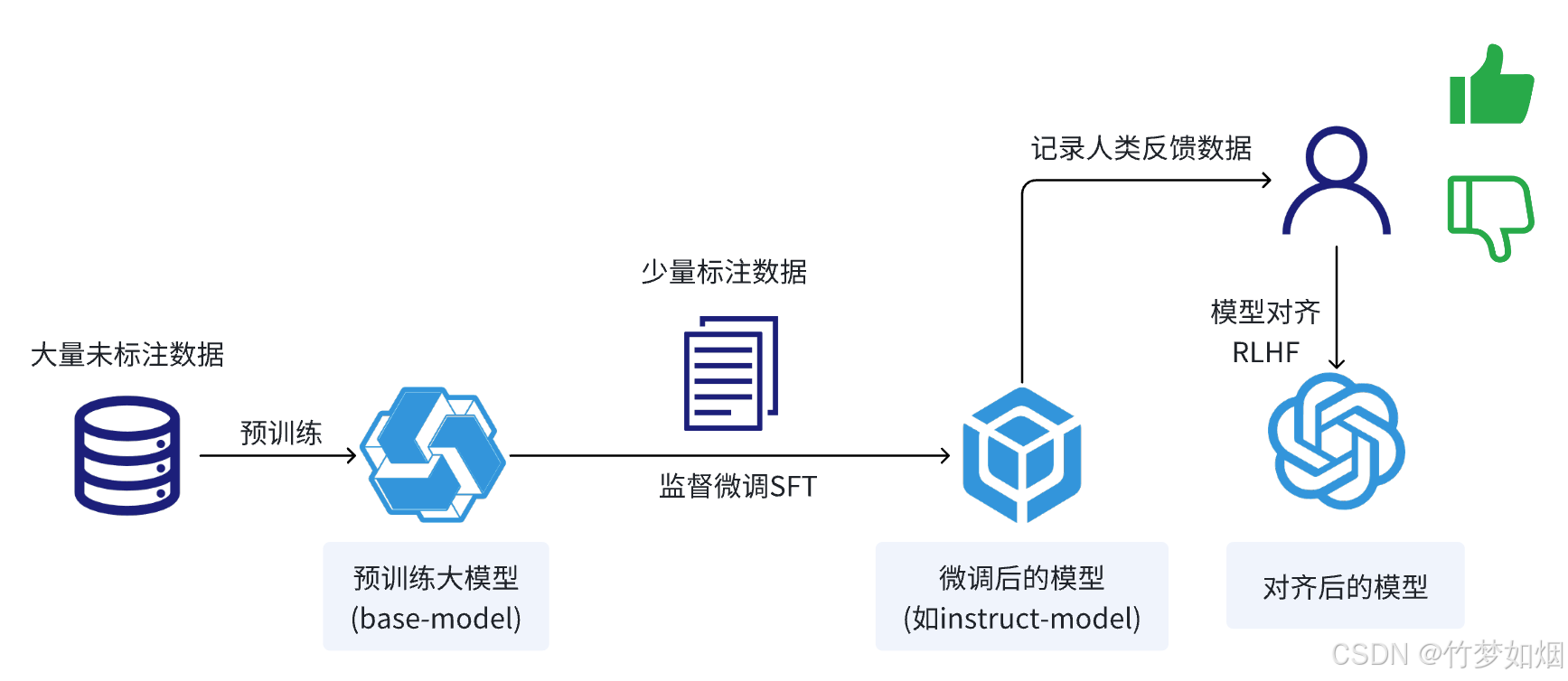
简单来说,大模型通常有两个阶段,预训练、微调。
其中预训练是使用大量未标注数据训练模型以学习通用知识,
微调是在预训练模型的基础上使用少量标注数据训练模型使得模型能够适应特定的下游任务。
最后需要使用预训练或者微调后的模型来进行推理,对提出的问题作出回答。
整体过程如下图所示:
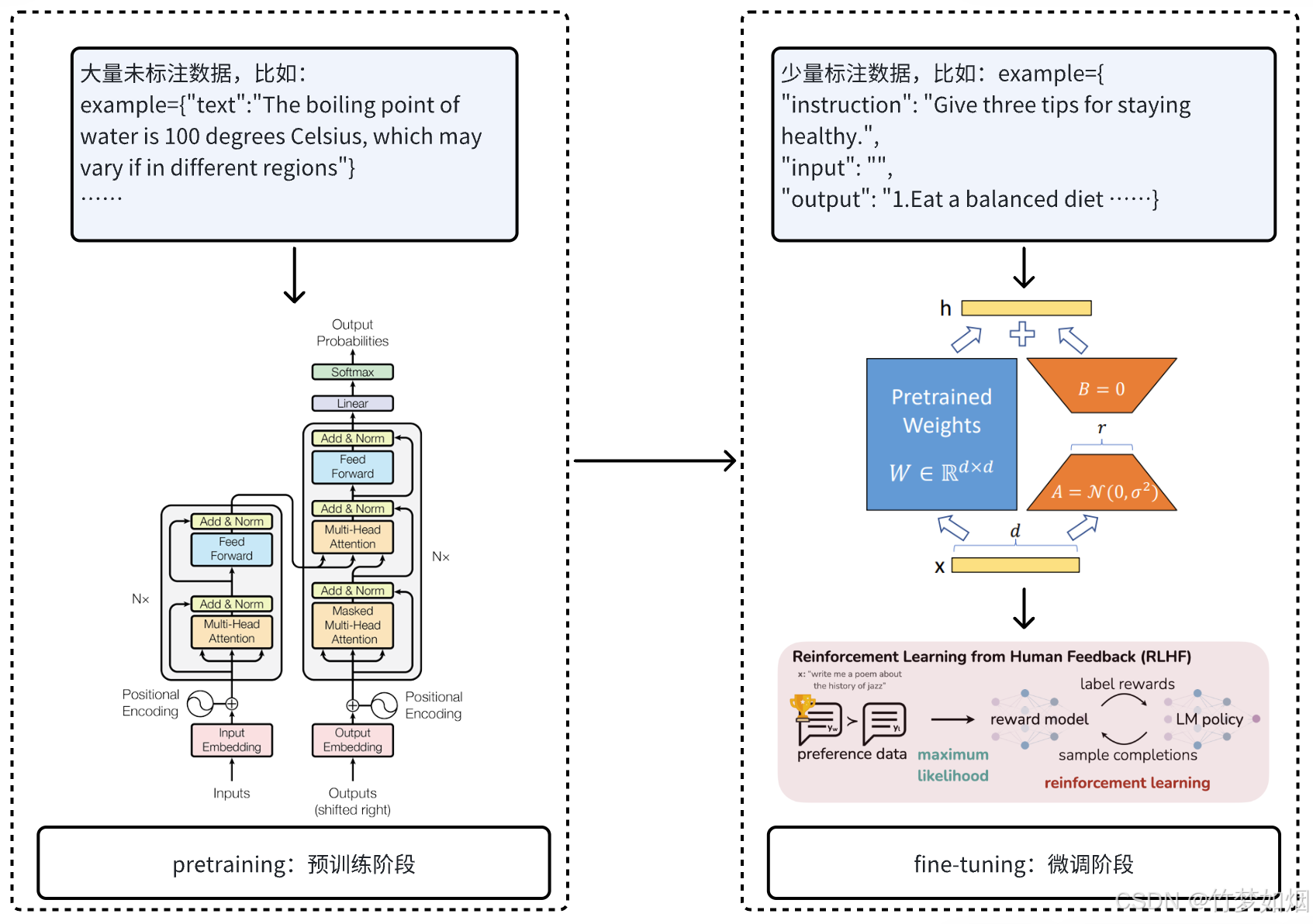
下面是详细介绍。
训练
训练是什么?我们何时需要对模型进行训练?
训练是指利用数据集对机器学习或深度学习模型进行学习的过程,其目的是让模型能够从输入的数据中提取有用信息,并尽可能地做出准确的预测。在训练过程中,模型会不断调整其内部参数(例如神经网络中的权重和偏置),以减少预测结果和实际结果之间的差异。整个训练过程可以分为以下几个关键步骤:
1、前向传播: 模型根据当前的参数对输入数据进行处理并生成预测结果。可以把这一过程看作是模型对输入信息的理解和初步响应。
2、损失计算: 之后,模型会计算预测结果与实际目标值之间的差距,通常通过损失函数来衡量这种差距。损失值越小,说明模型的预测越接近真实结果。
3、反向传播: 基于损失计算的结果,模型会执行反向传播过程,计算出每个参数的梯度(即损失对每个参数的影响程度)。这些梯度帮助模型知道如何调整参数,才能减少预测误差。
4、参数更新: 最后,模型会根据计算出的梯度使用梯度下降法或其他优化算法来调整其参数,从而使预测结果更加准确。这个调整过程会反复进行,直到损失达到一个理想的低点。
训练的核心目标是让模型通过大量的数据交互学习到潜在的规律和模式,从而能够在面对全新、未见过的数据时,依然做出准确的预测或决策。因此我们通常是在构建好模型架构之后就会使用大量数据集来对模型进行训练,使其能够学习其特征。
预训练
那么我们经常遇到一个概念,是预训练,那么预训练又是什么,为什么大模型需要预训练?
大模型预训练是指通过大规模无标注数据训练模型,使其能够学习到通用的知识和语言规律,为下游任务提供良好的基础。
预训练的主要目的:让模型在没有具体任务标签的情况下,通过自监督学习从大量文本数据中提取语言特征和结构,从而能够在后续的微调阶段以较少的标注数据快速适应并完成特定任务。
预训练数据的特点:
- 规模庞大且具有广泛的多样性。预训练数据通常包含大量的文本,涵盖了新闻、书籍、网页、社交媒体等各种领域,具有丰富的语法结构和上下文信息。
- 这些数据是无监督的,即不依赖人工标注,通过模型自身从文本中学习语言的结构和规律。无监督学习的优势在于其能够捕捉到语言中潜在的共性和普遍规律,这些规律对于多个任务都具有广泛适用性。
预训练模型的效果十分显著。与传统的从零开始训练的模型相比,预训练模型在应用中通常表现出更强的泛化能力,能够在多个不同的任务中获得良好的结果。由于预训练过程中模型已经通过大量数据学习了语言的基础知识,它可以迅速适应新的任务,仅需在较小规模的任务特定数据上进行微调,从而显著提高了训练效率和性能。此外,预训练模型能在处理未知数据时表现出较强的鲁棒性,避免了过拟合的问题。
预训练的过程通常分为几个步骤。
- 首先是数据准备阶段,收集和清洗大量的文本数据,确保数据的多样性和广泛性。
- 接着,选择合适的模型架构,如基于Transformer的BERT或GPT,这些模型能够高效地捕捉到文本的上下文关系。
- 接下来是训练阶段,在这一阶段,模型通过自监督学习任务进行训练。例如,BERT使用的是掩蔽语言模型任务,通过预测被遮蔽的词汇,学习语言的内部结构;GPT则使用自回归语言建模任务,学习生成流畅的文本。
总的来说,大模型的预训练通过大规模数据的学习,使得模型在多个领域和任务中都能展现出较高的准确性和适应性,可以为后续的模型的微调奠定良好的基础。
微调
微调(Fine-tuning)是指在预训练模型的基础上,利用特定任务的数据进行进一步训练,以便使模型更好地适应特定应用场景。与预训练阶段使用的大规模无监督数据不同,微调通常依赖于较小的、有标签的数据集,这些数据集与目标任务密切相关,例如情感分析、命名实体识别、机器翻译等。
微调显著提高了预训练模型在特定任务上的表现。通过微调,模型能够进一步学习到任务相关的特征,从而在处理目标任务时,展现出更高的精度和鲁棒性。微调不仅可以提升模型的预测能力,还能减少训练时间,因为预训练阶段已经为模型提供了丰富的知识基础。总的来说,微调是提升大模型在实际应用中性能的关键步骤。
微调与预训练的区别
1、首先是模型效果不同,比如llama2-7B的模型,每经过任何微调的预训练模型,在回答一些问题的时候更倾向于文本生成,而不是回答问题,如下所示(例子中使用的是alpaca-cleaned-huggingface):
question:What are the three primary colors?
answer:What are primary, secondary, and tertiary colors in art?
而如果使用指令微调数据集对模型进行微调,微调后的结果就能够实现针对问题给出相应的回答了,如下所示:
question:What are the three primary colors?
answer:Hopefully, the answer to this question is that the primary colours are red, blue and yellow.The three colours from the basis for all other colours. Mixing two colours together can result in a variety of shades, but the original three remain the same. For example, mixing red and blue can create a purple, and mixing yellow and red can produce an orange.
2、其次就是二者需要的数据量不同,比如LLaMA2-7B模型在预训练阶段使用了2万亿个token的数据,而指令微调如果要实现上面的效果仅需要50k条数据即可。下图是llama2-7B预训练使用的token数量。
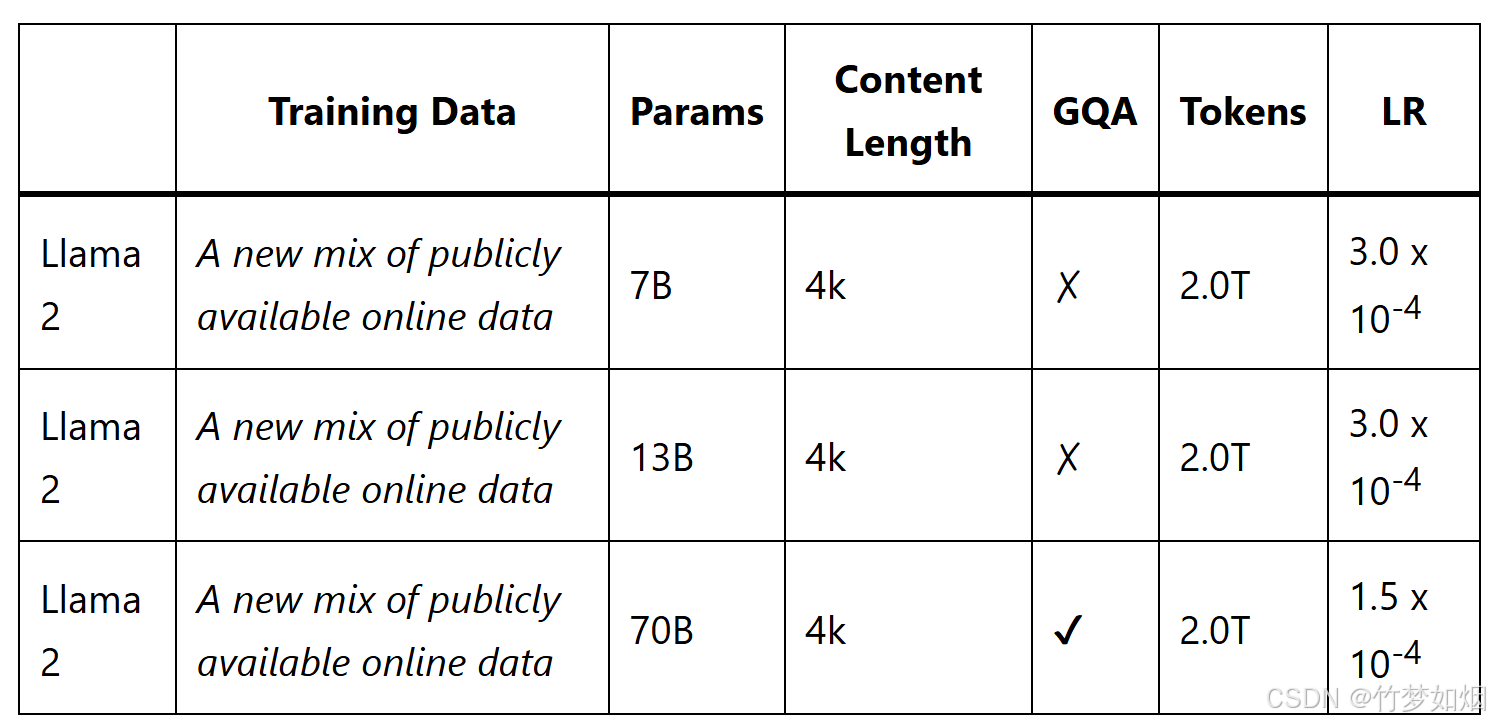
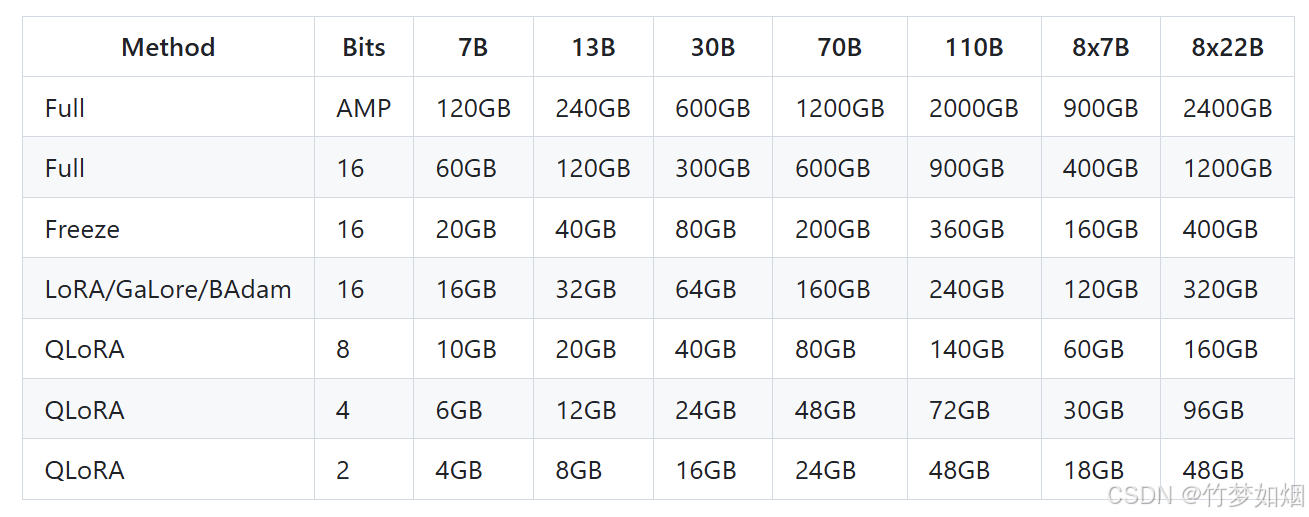
3、然后,两者对于训练资源的需求也不同,微调包含全参量微调以及部分参数微调,一般地使用部分参数微调方法就能实现大多数下游任务,而部分参数微调对资源的需求也比较低,下图是llama-factory官方提供的模型参数量与微调方式需要的显存数据统计:
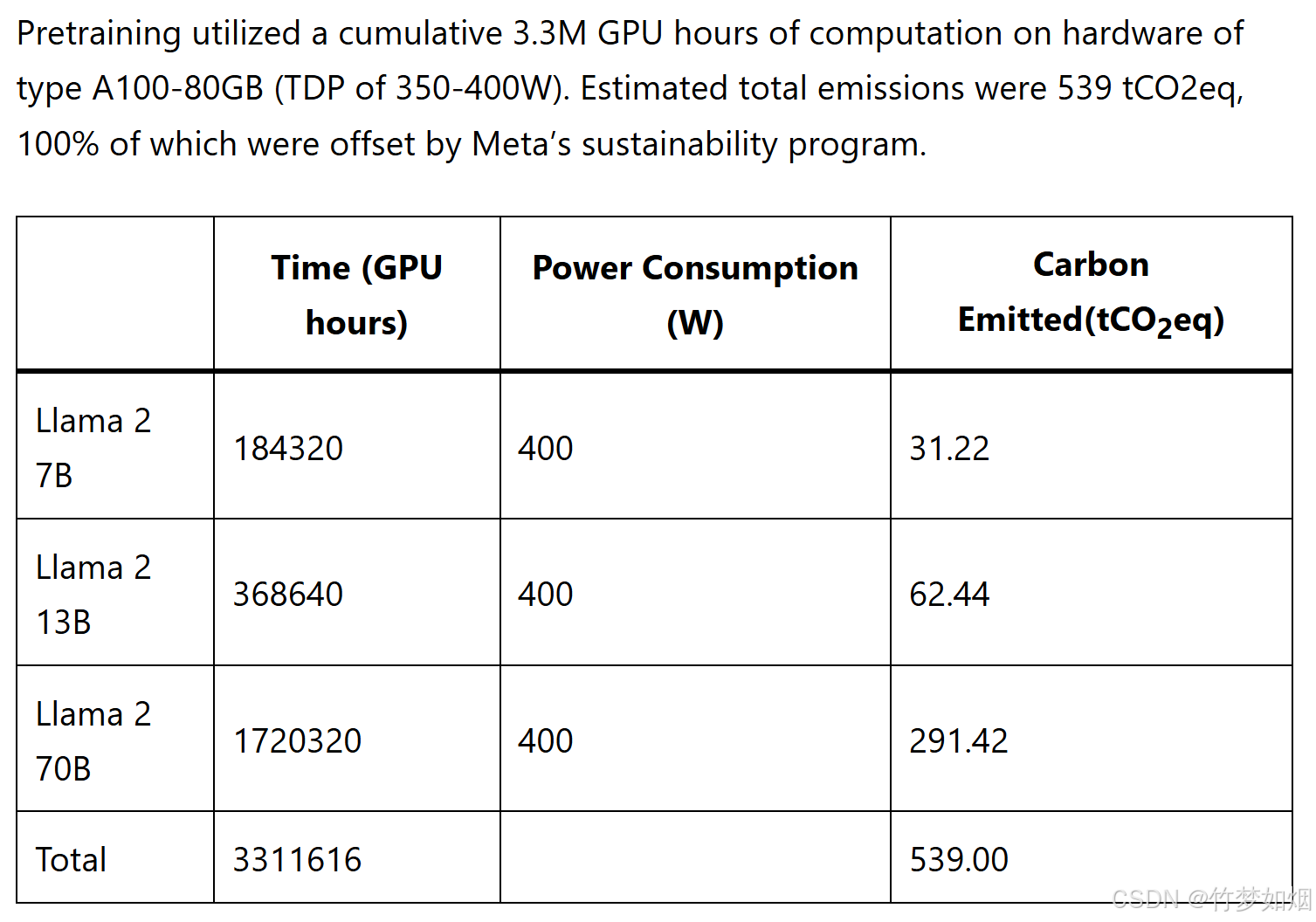
而预训练过程通常较长,并且计算资源需求较大,因为需要在大规模的无监督数据上进行训练。下图是预训练模型对于资源的消耗:
2、微调方法
首先我们根据微调目标将微调划分为监督微调(SFT)以及人类反馈强化学习(RLHF)。
监督微调(SFT)
是微调的一种形式,强调在有监督的环境下进行,旨在利用任务特定的标注数据进一步调整预训练模型。通过使用已标注的输入输出对,模型在预训练基础上学习如何在特定任务中提供准确的预测或决策。监督微调的目标是使模型能够在特定任务上表现更好,通常通过最小化模型输出与实际标签之间的误差来实现。
通过微调,模型可以从通用的预训练知识中提取出任务相关的信息,从而在特定任务(如文本分类、命名实体识别等)上提高准确性和适应性。
监督微调的优点在于训练过程简单且效果显著,但它依赖于大量高质量的标注数据,这可能是其限制之一。
人类反馈强化学习(RLHF)
是一种通过人类反馈来优化模型行为的强化学习方法。在RLHF中,模型的学习不仅依赖于传统的奖励信号,还通过人类提供的反馈(如评分、偏好排序等)来指导学习过程。与传统强化学习不同,RLHF不依赖于明确的环境奖励,而是通过人类对模型输出的评估来提供训练信号。
RLHF的目标是使模型在复杂或主观任务中生成更加符合人类期望的输出,例如生成对话、文本创作等。通过这种方法,模型可以逐渐优化其行为,以更好地适应人类需求、提升任务的质量和安全性。
RLHF的效果在于能提高模型的生成质量,尤其是在缺乏明确标签的数据场景中。它能够帮助模型避免一些潜在的安全问题,如生成不恰当或有害内容,并确保模型输出与人类期望一致。尽管其训练过程较为复杂,但在提高模型的可用性和伦理性方面具有显著优势。
二者关系具体如下图所示:
本文主要学习SFT监督微调部分。
SFT
总的来说,按照微调需要的参数量来说,SFT主要分为两种,分别为全量参数微调和参数高效微调。
- 全量参数微调(Full Fine-tuning,FFT):对预训练模型的所有参数进行更新,训练速度较慢,消耗机器资源较多;
- 参数高效微调(Parameter-Efficient Fine-Tuning,PEFT):只对部分参数进行更新,训练速度快,消耗机器资源少。
由于全量参数微调对资源的要求较高,具体数值在上面已经给出,llama-factory官网也有具体数值,因此本文只讨论参数高效微调部分。
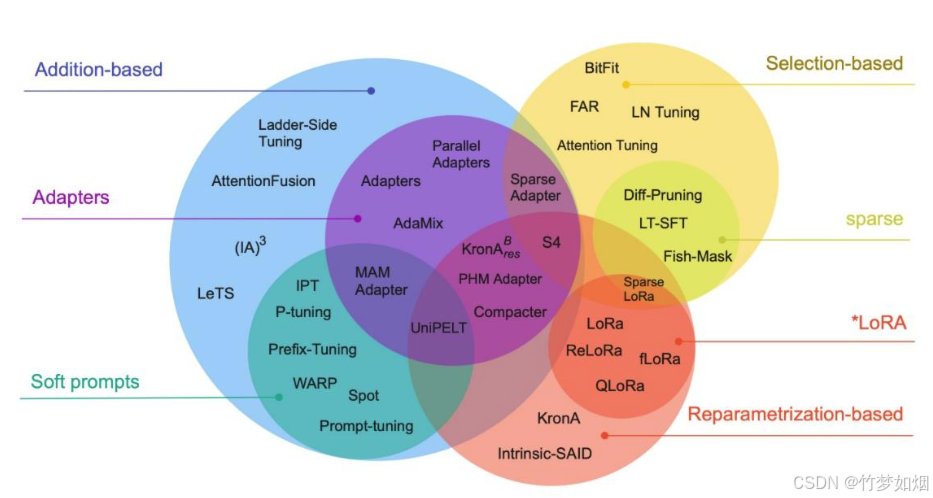
参数高效微调只对模型中的少量参数进行更新,极大地减少了计算和资源的消耗,同时还能在特定任务上保证模型的表现和性能。以下是几种常见的参数高效微调方法的分类说明:
参数高效微调种类:
-
LoRA(Low-Rank Adaptation)
LoRA 是一种通过低秩矩阵分解来高效微调的技术。在这种方法中,模型的权重矩阵被分解为低秩矩阵,只对这些低秩矩阵进行优化。这样做的好处是减少了需要调整的参数量,并且在保持原有模型结构不变的前提下,能够快速适应特定任务。LoRA 被广泛应用于 NLP 和计算机视觉领域,特别适用于资源受限的场景。 -
Adapters(适配器)
适配器是指在预训练模型的某些层之间插入小型的神经网络模块,这些模块用于处理特定任务的调整。在微调过程中,只有这些适配器模块的参数被训练,而预训练模型的其他参数保持不变。这样可以大幅降低微调所需的计算资源,同时保证模型的灵活性和迁移能力。 -
Prompt-tuning
Prompt-tuning 是通过调整模型输入的提示(prompt)来优化模型的输出。这种方法无需修改模型参数,仅通过设计或微调特定的输入提示语来引导模型进行特定任务的响应。这对于需要处理大量多样化任务的情况非常有效,且计算开销较低。
下图展示了各类参数高效微调方法及其所属的类别:
llama2-alpaca指令微调代码复现
1、准备数据
下载数据
本文使用的数据集是alpaca英文指令数据集,huggingface和魔搭社区都可以下载,下载代码如下:
from datasets import load_dataset
# huggingface保存到缓存文件夹(默认是./cache)
dataset = load_dataset("yahma/alpaca-cleaned")
# huggingface保存到本地文件夹
save_path = "/your/save/path"
dataset = load_dataset("yahma/alpaca-cleaned", cache_dir=save_path)
from modelscope.msdatasets import MsDataset
# modelscope保存到缓存文件夹(默认是./cache)
ds = MsDataset.load("AI-ModelScope/alpaca-gpt4-data-en")
# modelscope保存到本地文件夹
save_path = "/your/save/path"
model_dir = MsDataset.load("AI-ModelScope/alpaca-gpt4-data-en", cache_dir=save_path)
print(model_dir)在下载数据集的时候需要注意,有些数据集可能包含训练集和测试集、验证集,如下所示:
比如比较经典的clue数据集:
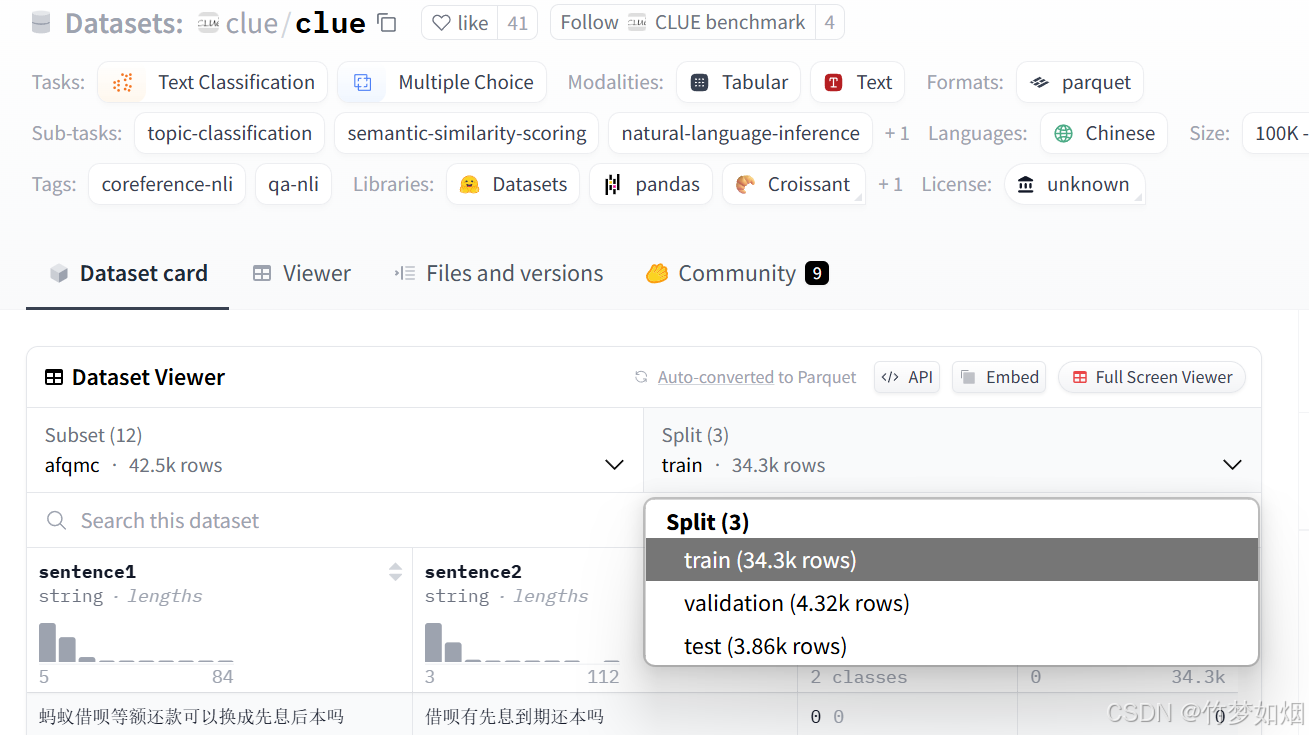
如果直接下载数据集,结果如下:
from datasets import load_dataset
datasets = load_dataset('clue/clue',"afqmc")
print(datasets)
"""
DatasetDict({
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3861
})
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 34334
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 4316
})
})
"""如果仅需要训练集部分,需要在代码里添加split:
train_datasets = load_dataset('clue/clue',"afqmc",split="train")
print(train_datasets)
"""
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 34334
})
"""
整理数据格式
其实可以直接使用上述内容下载下来的数据集,但是这里后面训练的时候为了方便,因此对数据集进行了格式预处理,希望数据集以jsonl文件保存,格式如下:
{"instruction": "Give three tips for staying healthy.", "input": "", "output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."}
每行数据需要包含instruction、input、output三块内容,这里预处理代码如下:
import json
from tqdm import tqdm
def aplaca_jsonl(train_data, output_jsonl):
# 通过 tqdm 为循环添加进度条
with open(output_jsonl, 'w', encoding='utf-8') as f:
for i in tqdm(range(len(train_data['instruction'])), desc="Saving to JSONL", unit="record"):
instruction = train_data['instruction'][i]
inputs = train_data['input'][i]
outputs = train_data['output'][i]
if instruction == None:
instruction = ""
if inputs == None:
inputs = ""
if outputs == None:
outputs = ""
record = {
"instruction": instruction,
"input": inputs,
"output": outputs
}
f.write(json.dumps(record, ensure_ascii=False) + '\n')
print(f"数据已成功保存为 {output_jsonl}")之所以有这一步是因为不是所有数据集都是alpaca格式上传到huggingface上的,因此下载的数据集不能保证所有的可以直接使用,因此有一个预处理阶段,将数据集调整成一个格式,之后的训练代码就不需要加以修改。
2、微调代码
环境配置
在运行代码前,需要先配置环境,具体环境配置如下:
- GPU:lora微调不需要太多显存,7B模型14G就足够,qlora更少,10G左右就足够
- Python:>=3.8
torch(神经网络训练框架,本文用于GPU加速):
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
-----------------------------------------------------------------------------------------------------------------------
transformers(Hugging Face提供的一个开源库,用于处理自然语言处理任务,尤其是基于预训练模型进行微调和推理。):
pip intsall transfomers -i https://pypi.tuna.tsinghua.edu.cn/simple
-----------------------------------------------------------------------------------------------------------------------
datasets(旨在简化数据集的管理、加载、处理和共享。它为机器学习和自然语言处理任务提供了一个统一的接口,可以轻松地访问和处理大量的标准数据集,尤其适用于大规模训练和评估模型。):
pip intsall datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
-----------------------------------------------------------------------------------------------------------------------
peft(帮助用户更高效地微调大规模预训练模型,专注于通过参数高效的方式进行微调,从而减少计算资源的消耗和存储开销,同时仍然能够获得良好的模型性能。):
pip intsall peft -i https://pypi.tuna.tsinghua.edu.cn/simple
-----------------------------------------------------------------------------------------------------------------------
bitsandbytes(主要通过低精度计算和量化技术来减小模型的存储占用,提高计算效率。):
pip intsall bitsandbytes -i https://pypi.tuna.tsinghua.edu.cn/simple
-----------------------------------------------------------------------------------------------------------------------
swanlab(开源AI训练过程可视化工具):
pip intsall -U swanlab -i https://pypi.tuna.tsinghua.edu.cn/simple
具体实践代码我会用10个部分来讲解,步骤分别是:
1、加载模型+分词器
2、处理数据集
3、设置lora参数
4、设置训练参数
5、设置SwanLab可视化工具
6、设置训练器参数+训练
7、保存模型
8、合并模型权重
9、推理结果
10、分布式训练代码
1、加载模型+分词器
from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq
import torch
# 加载模型
model_path = "./model/LLM-Research/llama-2-7b"
model_kwargs = {
"torch_dtype": torch.float16,
"use_cache": True,
}
model = AutoModelForCausalLM.from_pretrained(model_path, **model_kwargs)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False) # use_fast=False禁用快速分词器,使用默认的 Python 实现的分词器。虽然这种方式的速度较慢,但它的功能更为全面,支持更复杂的情况和功能。2、处理数据集
下面这段代码是用于准备和处理自然语言处理任务中序列到序列(Seq2Seq)模型训练数据的流程。
读取数据集
首先,我们需要先读取数据集:
import pandas as pd
from datasets import Dataset
data_path = "./data/alpaca_en_52k.jsonl"
data = pd.read_json(data_path, lines=True)
train_ds = Dataset.from_pandas(data)
"""
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 52002
})
"""然后为了方便后续的训练,我们需要将数据集按照固定格式封装。
数据映射
数据映射是一种数据变换或者数据预处理的操作,目的是对数据进行处理、转换或者格式化,以满足模型训练的要求。具体思考过程如下:
1、文本转换成tokens格式
我们现实中的各种数据都是中文、英文……等等,但是这些内容其实是模型不能够直接理解的字符或者词汇,原因是因为深度学习模型(包括语言模型)是基于数值计算的,它们通过大量的数学运算来学习数据之间的模式,而这些运算是针对数字的。因此,输入文本必须转换为数值(数字或向量)的形式,这里是将文本转换成tokens形式。具体如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "./model/LLM-Research/llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path)
inputs = "I like apples and bananas"
print(tokenizer(inputs,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
))inputs="I like apples and bananas"
input_ids=[306, 763, 623, 793, 322, 9892, 16397]
inputs和input_ids不一定是一一对应的,这涉及 tokenization 过程中的分词和编码方式,有可能会出现将一个完整的词拆成多个词转换成tokens的情况,分词器可能将 apples 和 bananas 分解为多个 token(例如 ["ap", "ples"] 和 ["ban", "anas"]),这些 token 会被映射到不同的 token IDs,这样做有下面几个优点:
-
处理未登录词(OOV): 通过子词分词,模型能够处理词汇表中没有的单词。这意味着即使一个词没有出现在训练数据中,模型也能通过它的子词或字符部分进行处理,从而避免了无法处理的新词。
-
更高的词汇表效率: 使用子词而非完整的单词可以显著减少词汇表的大小。例如,英语中可能有成千上万的单词,但如果用子词分词技术,可以用更少的 token 代表更丰富的语言内容。模型可以根据需要组合这些子词来表示各种单词。
-
更好的泛化能力: 子词分词允许模型学习词的组成部分(例如词根、前缀、后缀等),从而提高了模型在新词、拼写错误或低频词汇上的泛化能力。
-
提高训练效率: 如果模型将所有的词汇都视为独立的 token,那么它的词汇表将变得非常庞大,这会增加模型的存储需求和计算负担。通过将词汇分解成子词,模型能够减少词汇表的规模,同时保持对语言细节的处理能力。
2、训练数据格式
通常在大模型训练时,特别是指令微调(Instruction Tuning)的任务中,input_ids、attention_mask,labels 是用来训练模型的三个重要组件。它们分别扮演不同的角色,确保训练过程顺利进行并能够有效地调整模型的行为。下面是每个组件的解释和为什么需要它们:
- input_ids:是输入文本的编码形式,通常是一个整数列表,每个整数表示一个词或子词的ID,映射到一个特定的词汇表中的元素。在训练过程中,模型需要知道输入文本是什么,以便进行处理和生成预测。
- attention_mask:是一个指示哪些位置在计算时需要被关注的标记,它通常是一个与输入序列相同长度的二进制向量。值为1的地方表示该位置的token需要被模型关注,而值为0的地方表示该位置的token在计算时应该被忽略。
- labels:是模型学习的目标输出,它告诉模型应该在每个时间步生成什么内容。在训练生成式任务时,
labels是模型的目标,通常是模型预测的目标文本。为了让模型学会生成输出,它需要知道正确的答案。
具体如下所示:
data = {
"input": "请写一篇简短的文章。",
"output": "人工智能是当今科技领域最为重要的发展之一。"
}
input_ids = [123, 456, 789, 1011, 2022, 3033, 4044, 5055]
attention_mask = [1, 1, 1, 1, 1, 1, 1, 1]
labels = [-100, -100, -100, -100, 2022, 3033, 4044, 5055]前半部分是input内容,后半部分是output内容。
3、数据格式化处理
上述已经讲清楚数据预处理的每一步了,接下来就是数据格式化处理操作,具体代码如下:
def process_data(data: dict, tokenizer, max_seq_length):
input_ids, attention_mask, labels = [], [], []
# 指令微调的数据
instruction_text = data['instruction']
human_text = data["input"]
assistant_text = data["output"]
input_text = f"<<SYS>>\n{instruction_text}\n<</SYS>>\n\n[INST]{human_text}[/INST]"
input_tokenizer = tokenizer(
input_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
output_tokenizer = tokenizer(
assistant_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
input_ids += (
input_tokenizer["input_ids"] + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
attention_mask += input_tokenizer["attention_mask"] + output_tokenizer["attention_mask"] + [1]
labels += ([-100] * len(input_tokenizer["input_ids"]) + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
if len(input_ids) > max_seq_length: # 做一个截断
input_ids = input_ids[:max_seq_length]
attention_mask = attention_mask[:max_seq_length]
labels = labels[:max_seq_length]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
train_dataset = train_ds.map(process_data,
fn_kwargs={"tokenizer": tokenizer, "max_seq_length": 2048},
remove_columns=train_ds.column_names)注意:
input_text = f"<<SYS>>\n{instruction_text}\n<</SYS>>\n\n[INST]{human_text}[/INST]"
这里可能会根据每个模型的不同做修改,如果不按照每个模型对应的格式训练,而是按照自己编写的格式进行训练,结果可能会出现由于max_length比较大使得回答停不下来,一直生成句子。
那么该如何确定训练文本格式?其实在每一个模型的tokenizer_config文件中已经给出模板(llama3之后的模型有模板,之前的有些模型可能会有)
比如qwen2.5的模板如下:

而llama2-7B在文件里其实没有明确给出

但是具体格式可以从LLaMA-Factory得到:

数据整理
这一步主要作用是训练提供批处理数据时的数据整理(collation),特别是在文本生成任务中,它帮助将不同长度的序列(如输入和输出文本)统一成批次,并进行必要的填充、格式化和转换。
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True, return_tensors="pt")- padding:确保每个批次中的所有序列都具有相同的长度。
-
return_tensors="pt":返回的格式是 PyTorch 张量,这意味着整理后的数据将能够直接用于 PyTorch 模型进行训练。
3、设置lora参数
LoRA(Low-Rank Adaptation)是一种用于深度学习模型微调的技术,特别适用于预训练大模型。它的核心思想是通过低秩矩阵的方式对模型参数进行高效的调整,从而在不大量修改原有预训练参数的情况下,能够显著提升模型在特定任务上的表现。LoRA的主要优点在于其较低的计算开销和存储需求,尤其适用于大规模预训练模型的微调。
Lora原理:
LoRA的工作原理是通过在预训练模型的权重矩阵中引入低秩适配器来实现高效的微调,通过以下步骤降低了计算和存储的成本:
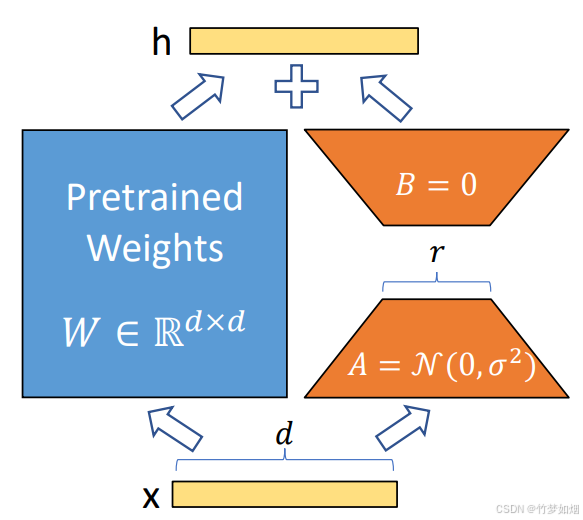
1、低秩矩阵分解: LoRA提出了一种通过低秩矩阵分解来适配模型的新方法。假设模型的某个权重矩阵为 W,在LoRA中,我们将其分解为两个低秩矩阵 A和 B,即:
其中,A 和 B 是学习的低秩矩阵,维度远小于原始权重矩阵。通过这种分解,LoRA只需要调整 A 和 B,而不是更新整个大规模的权重矩阵 W。
2、适配器插入: LoRA会将低秩适配器插入到模型的特定层中,通常是Transformer模型中的注意力层或前馈网络层。这些适配器在训练过程中被优化,以便让预训练模型适应新的任务,而不需要修改原有的网络结构。
3、冻结预训练权重: LoRA的另一个重要特点是冻结预训练模型的大部分权重,仅更新新增的低秩适配器。这意味着预训练阶段的模型参数可以保持不变,减少了微调时的参数更新量,从而提高了训练效率。
代码:
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=['up_proj', 'gate_proj', 'q_proj', 'o_proj', 'down_proj', 'v_proj', 'k_proj'],
task_type=TaskType.CAUSAL_LM,
inference_mode=False # 训练模式
)注意:
target_modules参数指定了 LoRA 要应用的模型层。在 LoRA 中,我们将低秩适配器插入到指定的层中,以提高微调效率。
比如llama2-7B的模型:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
我们在选择需要微调的模型层的时候尽量还是要选择注意力层,也就是上述模型中self_attn部分,因为调整注意力层可以有效的适应特定任务,尤其是在需要细粒度信息处理的任务中,注意力层的微调通常能显著提升性能。
当然也可以同时选择注意力层self_attn和前馈网络层MLP,虽然会增加一部分计算开销,但是也能有效地提高任务性能。
4、设置训练参数
代码如下:
from transformers import TrainingArguments
import os
# 输出地址
output_dir="./output/llama2-7b-alpaca-zh-51k"
# 配置训练参数
train_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
logging_steps=1,
num_train_epochs=3,
save_steps=5000,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to=None,
seed=42,
optim="adamw_torch",
fp16=True,
bf16=False,
remove_unused_columns=False,
)-
output_dir:指定训练结果(模型权重、日志文件、检查点等)保存的目录。
-
per_device_train_batch_size:每个设备(如每个 GPU)上的训练批次大小。这个大小决定了每次梯度更新时处理的数据量。
-
gradient_accumulation_steps:梯度累积的步骤数。这个参数的作用是在多次前向传播和反向传播后再进行一次梯度更新(即累积梯度),以减小显存的需求。比如设置为 8,意味着每积累 8 个小批次后才会更新一次梯度。
-
logging_steps:每多少个训练步骤记录一次日志(如训练损失、学习率等)。例如设置为 1,意味着每个训练步骤都会记录一次。
-
num_train_epochs:训练的总轮数,即整个训练数据集会被训练多少遍。
-
save_steps:每经过多少步保存一次模型检查点。检查点保存了当前模型的权重,可以用于恢复训练或进行评估。
-
learning_rate:训练的学习率。学习率决定了模型每次参数更新的步幅大小。设置合适的学习率对于模型的训练非常重要。
-
save_on_each_node:是否在每个节点上都保存检查点。在分布式训练中,每个设备(节点)都会保存自己的检查点,如果设置为
True,则每个节点都会单独保存。 -
gradient_checkpointing:是否启用梯度检查点(gradient checkpointing)。启用该功能后,模型在前向传播时会保存一些中间结果(而不是全部),以减少显存的消耗。
-
report_to:指定报告训练指标的方式,可以是
wandb或tensorboard等。如果设置为None,则不会报告任何训练指标。这里本文使用swanlab,设置其为None,后续直接使用callback。 -
seed:用于设置随机数生成器的种子。设置固定的种子可以确保训练的结果具有可重复性。
-
optim:指定优化器。
-
fp16:是否启用 16 位浮点数(半精度训练)。使用 FP16 可以显著减少显存占用并提高训练速度,适用于支持的硬件(如 NVIDIA A100 和 V100 等)。
-
bf16:是否启用 BFloat16(BFP16)训练。这是一种浮点数格式,常用于 Google TPUs,适用于某些任务和硬件,可以提供较高的性能。
-
remove_unused_columns:是否删除数据集中的未使用列。对于某些任务,训练数据集可能包含多余的列,设置为
True会自动删除它们,以减少内存消耗。
5、设置可视化工具SwanLab

SwanLab(原域名可能会出现访问异常,可通过临时域名临时域名访问网站,期间swanlab安装包和实验跟踪可正常使用。预计2-10个工作日完成备案迁移。)是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:
1、基于一个名为swanlab的python库
2、可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果
3、能够自动记录logging、系统硬件、环境配置(如用了什么型号的显卡、Python版本是多少等等)
4、同时可以完全离线运行,在完全内网环境下也可使用
如果想要快速入门,请参考以下文档链接:
代码如下:
from swanlab.integration.transformers import SwanLabCallback
swanlab_config = {
"dataset": data_path,
"peft":"lora"
}
swanlab_callback = SwanLabCallback(
project="finetune",
experiment_name="llama2-7b-alpaca-51k",
description="使用alpaca的所有数据来指令微调",
workspace=None,
config=swanlab_config,
)6、设置训练器参数+训练
在微调Transformer模型时,使用Trainer类来封装数据和训练参数是至关重要的。Trainer不仅简化了训练流程,还允许我们自定义训练参数,包括但不限于学习率、批次大小、训练轮次等。通过Trainer,我们可以轻松地将这些参数和其他训练参数一起配置,以实现高效且定制化的模型微调。
这里我们需要以下这些参数,包括模型、训练参数、训练数据、处理数据批次的工具、还有可视化工具
from peft import get_peft_model
from transformers import Trainer
# 用于确保模型的词嵌入层参与训练
model.enable_input_require_grads()
# 应用 PEFT 配置到模型
model = get_peft_model(model,lora_config)
model.print_trainable_parameters()
# 配置训练器
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
data_collator=data_collator,
callbacks=[swanlab_callback],
)
# 启动训练
trainer.train()这里在使用 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)技术时,通常需要通过 get_peft_model 来设置模型。PEFT 是一种用于微调大规模预训练模型的技术,它的目标是减少需要更新的参数量,同时保持模型的性能。这种方法特别适用于大模型(如 GPT、BERT等),可以在有限的计算资源下实现快速高效的微调。
7、保存模型
from os.path import join
final_save_path = join(output_dir)
trainer.save_model(final_save_path)这里保存了模型的权重、配置文件和词汇表,确保你可以在之后重新加载并使用该模型进行推理或继续训练。模型的优化器状态、学习率调度器等其他信息如果需要保存,则需要显式调用其他相关方法,如 trainer.save_state()。
final_save_path = join(output_dir)
trainer.save_state()
trainer.save_model(final_save_path)8、合并模型权重
保存下来的仅仅是模型的权重信息以及配置文件等,是不能直接使用的,需要与原模型进行合并操作,代码如下:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import os
import shutil
# 保证原始模型的各个文件不遗漏保存到merge_path中
def copy_files_not_in_B(A_path, B_path):
if not os.path.exists(A_path):
raise FileNotFoundError(f"The directory {A_path} does not exist.")
if not os.path.exists(B_path):
os.makedirs(B_path)
# 获取路径A中所有非权重文件
files_in_A = os.listdir(A_path)
files_in_A = set([file for file in files_in_A if not (".bin" in file or "safetensors" in file)])
files_in_B = set(os.listdir(B_path))
# 找到所有A中存在但B中不存在的文件
files_to_copy = files_in_A - files_in_B
# 将文件或文件夹复制到B路径下
for file in files_to_copy:
src_path = os.path.join(A_path, file)
dst_path = os.path.join(B_path, file)
if os.path.isdir(src_path):
# 复制目录及其内容
shutil.copytree(src_path, dst_path)
else:
# 复制文件
shutil.copy2(src_path, dst_path)
def merge_lora_to_base_model(model_name_or_path,adapter_name_or_path,save_path):
# 如果文件夹不存在,就创建
if not os.path.exists(save_path):
os.makedirs(save_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True,)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto"
)
# 加载保存的 Adapter
model = PeftModel.from_pretrained(model, adapter_name_or_path, device_map="auto",trust_remote_code=True)
# 将 Adapter 合并到基础模型中
merged_model = model.merge_and_unload() # PEFT 的方法将 Adapter 权重合并到基础模型
# 保存合并后的模型
tokenizer.save_pretrained(save_path)
merged_model.save_pretrained(save_path, safe_serialization=False)
copy_files_not_in_B(model_name_or_path, save_path)
print(f"合并后的模型已保存至: {save_path}")这样保存下来的模型如下图所示:
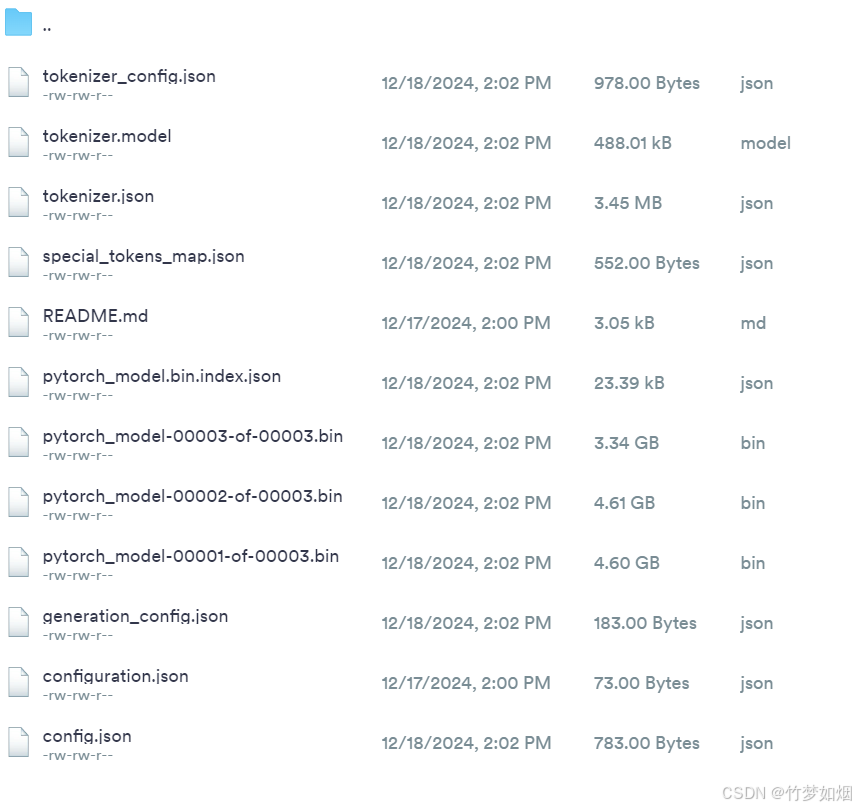
此时一个完整的微调过程才就此结束。
9、推理结果
我们将合并好的模型进行推理操作,可以查看其结果是否符合我们的预期,推理代码一般在模型上传的同时也已经写好了,比如qwen模型推理模板:
然后llama2-7B我们前面说过本来没有chat_template的,但是推理代码都大同小异,这里直接文本生成并且解码即可,代码如下:
def llama_inference(model_path: str, prompt: str):
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="cuda:0")
# 将输入文本转换为模型的输入格式
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 推理过程
with torch.no_grad():
# 生成输出,调整参数以控制生成长度
output = model.generate(
inputs['input_ids'],
max_length=2048, # 设置最大生成长度
num_return_sequences=1, # 生成一个序列
no_repeat_ngram_size=2, # 防止重复的n-gram
top_p=0.95, # nucleus sampling
temperature=0.7 # 控制输出的随机性
)
# 解码并打印生成的文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text然后我们来看看预训练模型和微调后的模型的区别:
base-model:
input:Describe a time when you had to make a difficult decision.
output:And explain why it was difficult for you.
finetune-model:
input:Describe a time when you had to make a difficult decision.
output:I had a tough decision to choose between two job offers. I had been offered a position at a large company, with a decent salary and benefits, but it was a very rigid and structured environment. On the other hand, I was also offered the opportunity to start my own business and be my boss. Even though it seemed like a risk, it also had the potential to be more rewarding. After much deliberation,I decided to take the risk and start the business.
可以明显看到微调后的模型对问题的回答更加全面,预训练模型更像是直接生成后面的文案,而微调后的模型更像是回答问题了。
然后我们再看一个例子:
base-model:
input:What does DNA stand for?
output:Why is DNA called DNA? What is the full form of DNA and what does it mean? Find out here.DNA stands for deoxyribonucleic acid. It is a nucleic molecule found in the nucleus of every cell of an organism. DNA is made up of four building blocks: Adenine, Thymine (T), Guanine and Cytosine. The letters are often referred to by their initials, A, T, G and c, in that order. In DNA, the A’s and T’switch places with each other, as do the G’ and Cs. So, AT and GC are the two strands of the double helix structure of a DNA molecules. However, DNA does not exist as a double stranded molecular structure. Instead, it exists as two single stressed molecles that wind around each other in a spiral shape. This structure is called a ‘double helical structure’ because it looks like a twisted ladder. A ladde has two sides. One is on the inside and the other is outside. Inside the ladle is one side and outside it is another side. Similarly, on DNA’S moleculr ladler, one strad is inside while the another is out. Since this structure resembles a ladeler, scientists named it the ‘ladeler’ structure, or the helic structure for short.
finetune-model:
input:What does DNA stand for?
output:DNA stands for Deoxyribonucleic acid. DNA is the hereditary material of living organisms that contains the genetic instructions for the development and functioning of an organism. It is composed of two strands coiled around each other to form a double helix. The strand consists of phosphate and deoxynucletotide bases.
由于我设置了文本最大长度为2048,可以看到预训练模型感觉要填满最大长度的文本,而微调后的模型中规中矩的回答,到结尾处就自动停止回复了。
这里我们也可以使用gradio来查看结果,可以更加方便,代码如下:
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
TOTAL_GPU_NUMS = 4
TOKENIZE_PATH = "./model/LLM-Research/llama-2-7b"
MODEL_LIST = {
"office-llama2-7b": "model/LLM-Research/llama-2-7b", # 官方模型
"alpaca_llama2-7b_lora": "./output/llama2-7b-alpaca-en-52k-epoch-3-merge-model", # cot微调
}
model_names = list(MODEL_LIST.keys()) # Ensure this is a list to easily index
# 推理函数
def llama_inference(model_path: str, prompt: str, device: str):
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device)
# 将输入文本转换为模型的输入格式
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 推理过程
with torch.no_grad():
# 生成输出,调整参数以控制生成长度
output = model.generate(
inputs['input_ids'],
max_length=2048, # 设置最大生成长度
num_return_sequences=1, # 生成一个序列
no_repeat_ngram_size=2, # 防止重复的n-gram
top_p=0.95, # nucleus sampling
temperature=0.7 # 控制输出的随机性
)
# 解码并打印生成的文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text
# 更新 generate_response 函数,使用 llama_inference 进行推理
def generate_response(instruct_text, input_text):
prompt = instruct_text+input_text
# 获取所有模型的输出,指定每个模型使用不同的 GPU
outputs = [
llama_inference(MODEL_LIST[model_name], prompt, device=f"cuda:{i % TOTAL_GPU_NUMS}")
for i, model_name in enumerate(model_names)
]
return tuple(outputs)
# 创建 Gradio 界面
demo = gr.Interface(
fn=generate_response, # 函数名
inputs=[
gr.Textbox(label="instruction"),
gr.Textbox(label="input"),
], # 输入文本框
outputs=[gr.Textbox(label=model_name) for model_name in model_names],
)
if __name__ == "__main__":
demo.launch(share=True)
结果如下:
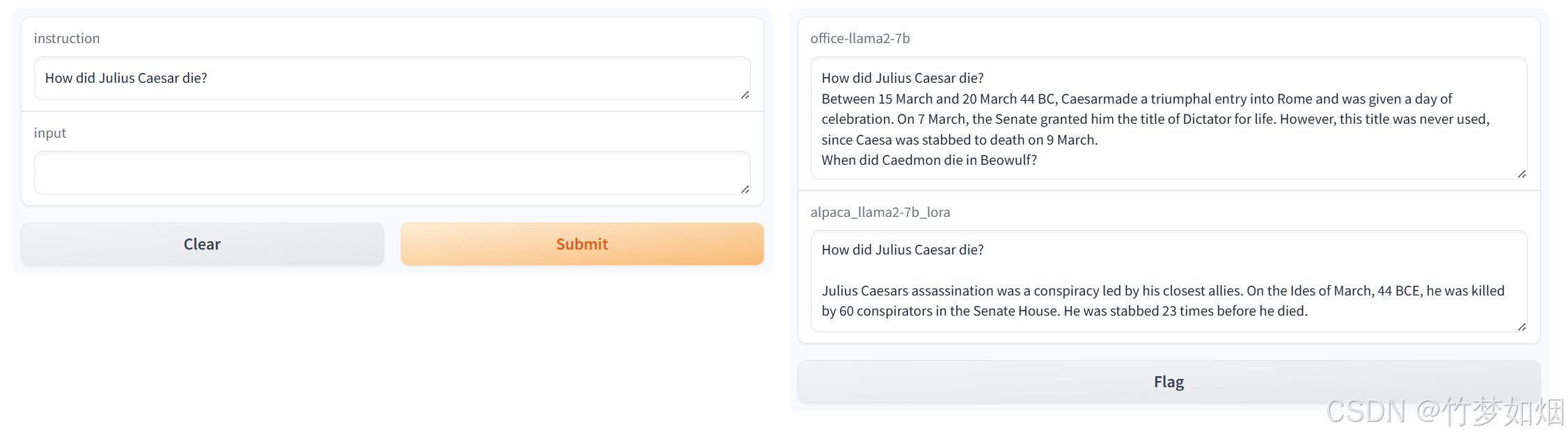
10、分布式训练代码
由于一块卡跑的时间过于漫长,跑完三个epoch要10+小时,所以可以采取分布式训练,具体代码如下:
import argparse
from os.path import join
import pandas as pd
from datasets import Dataset
from loguru import logger
from transformers import (
TrainingArguments,
AutoModelForCausalLM,
Trainer,
DataCollatorForSeq2Seq,
AutoTokenizer,
)
import torch
from peft import LoraConfig, get_peft_model, TaskType
from swanlab.integration.transformers import SwanLabCallback
import bitsandbytes as bnb
from torch import nn
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
import os
import json
# 配置参数
def configuration_parameter():
parser = argparse.ArgumentParser(description="LoRA fine-tuning for deepseek model")
# 模型路径相关参数
parser.add_argument("--model_name_or_path", type=str, default="LLM-Research/llama-2-7b",
help="Path to the model directory downloaded locally")
parser.add_argument("--output_dir", type=str,
default="output",
help="Directory to save the fine-tuned model and checkpoints")
# 数据集路径
parser.add_argument("--train_file", type=str, default="./data/alpaca_en_52k.jsonl",
help="Path to the training data file in JSONL format")
# 训练超参数
parser.add_argument("--num_train_epochs", type=int, default=3,
help="Number of training epochs")
parser.add_argument("--per_device_train_batch_size", type=int, default=2,
help="Batch size per device during training")
parser.add_argument("--gradient_accumulation_steps", type=int, default=8,
help="Number of updates steps to accumulate before performing a backward/update pass")
parser.add_argument("--learning_rate", type=float, default=2e-4,
help="Learning rate for the optimizer")
parser.add_argument("--max_seq_length", type=int, default=2048,
help="Maximum sequence length for the input")
parser.add_argument("--logging_steps", type=int, default=1,
help="Number of steps between logging metrics")
parser.add_argument("--save_steps", type=int, default=5000,
help="Number of steps between saving checkpoints")
parser.add_argument("--save_total_limit", type=int, default=1,
help="Maximum number of checkpoints to keep")
parser.add_argument("--lr_scheduler_type", type=str, default="constant_with_warmup",
help="Type of learning rate scheduler")
parser.add_argument("--warmup_steps", type=int, default=0,
help="Number of warmup steps for learning rate scheduler")
# LoRA 特定参数
parser.add_argument("--lora_rank", type=int, default=16,
help="Rank of LoRA matrices")
parser.add_argument("--lora_alpha", type=int, default=32,
help="Alpha parameter for LoRA")
parser.add_argument("--lora_dropout", type=float, default=0.05,
help="Dropout rate for LoRA")
# 分布式训练参数
parser.add_argument("--local_rank", type=int, default=int(os.environ.get("LOCAL_RANK", -1)),
help="Local rank for distributed training")
parser.add_argument("--distributed", type=bool, default=True, help="Enable distributed training")
# 额外优化和硬件相关参数
parser.add_argument("--gradient_checkpointing", type=bool, default=True,
help="Enable gradient checkpointing to save memory")
parser.add_argument("--optim", type=str, default="adamw_torch",
help="Optimizer to use during training")
parser.add_argument("--train_mode", type=str, default="lora",
help="lora or qlora")
parser.add_argument("--seed", type=int, default=42,
help="Random seed for reproducibility")
parser.add_argument("--fp16", type=bool, default=True,
help="Use mixed precision (FP16) training")
parser.add_argument("--report_to", type=str, default=None,
help="Reporting tool for logging (e.g., tensorboard)")
parser.add_argument("--dataloader_num_workers", type=int, default=0,
help="Number of workers for data loading")
parser.add_argument("--save_strategy", type=str, default="epoch",
help="Strategy for saving checkpoints ('steps', 'epoch')")
parser.add_argument("--weight_decay", type=float, default=0,
help="Weight decay for the optimizer")
parser.add_argument("--max_grad_norm", type=float, default=1,
help="Maximum gradient norm for clipping")
parser.add_argument("--remove_unused_columns", type=bool, default=True,
help="Remove unused columns from the dataset")
args = parser.parse_args()
return args
def find_all_linear_names(model, train_mode):
"""
找出所有全连接层,为所有全连接添加adapter
"""
assert train_mode in ['lora', 'qlora']
cls = bnb.nn.Linear4bit if train_mode == 'qlora' else nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16-bit
lora_module_names.remove('lm_head')
lora_module_names = list(lora_module_names)
logger.info(f'LoRA target module names: {lora_module_names}')
return lora_module_names
def setup_distributed(args):
"""初始化分布式环境"""
if args.distributed:
if args.local_rank == -1:
raise ValueError("未正确初始化 local_rank,请确保通过分布式启动脚本传递参数,例如 torchrun。")
# 初始化分布式进程组
dist.init_process_group(backend="nccl")
torch.cuda.set_device(args.local_rank)
print(f"分布式训练已启用,Local rank: {args.local_rank}")
else:
print("未启用分布式训练,单线程模式。")
# 加载模型
def load_model(args, train_dataset, data_collator):
# 初始化分布式环境
setup_distributed(args)
# 自动分配设备
# 加载模型
model_kwargs = {
"trust_remote_code": True,
"torch_dtype": torch.float16 if args.fp16 else torch.bfloat16,
"use_cache": False if args.gradient_checkpointing else True,
"device_map": "auto" if not args.distributed else None,
}
model = AutoModelForCausalLM.from_pretrained(args.model_name_or_path, **model_kwargs)
# 用于确保模型的词嵌入层参与训练
model.enable_input_require_grads()
# 将模型移动到正确设备
if args.distributed:
model.to(args.local_rank)
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
# 哪些模块需要注入Lora参数
target_modules = find_all_linear_names(model.module if isinstance(model, DDP) else model, args.train_mode)
# lora参数设置
config = LoraConfig(
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
bias="none",
target_modules=target_modules,
task_type=TaskType.CAUSAL_LM,
inference_mode=False
)
use_bfloat16 = torch.cuda.is_bf16_supported() # 检查设备是否支持 bf16
# 配置训练参数
train_args = TrainingArguments(
output_dir=args.output_dir,
per_device_train_batch_size=args.per_device_train_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
logging_steps=args.logging_steps,
num_train_epochs=args.num_train_epochs,
save_steps=args.save_steps,
learning_rate=args.learning_rate,
save_on_each_node=True,
gradient_checkpointing=args.gradient_checkpointing,
report_to=args.report_to,
seed=args.seed,
optim=args.optim,
local_rank=args.local_rank if args.distributed else -1,
ddp_find_unused_parameters=False, # 分布式参数检查优化
fp16=args.fp16,
bf16=not args.fp16 and use_bfloat16,
remove_unused_columns=False
)
# 应用 PEFT 配置到模型
model = get_peft_model(model.module if isinstance(model, DDP) else model, config) # 确保传递的是原始模型
model.print_trainable_parameters()
# 创建一个字典来存储模型参数和设备信息
device_info = {}
# 获取模型中每个参数的设备信息
for name, param in model.named_parameters():
device_info[name] = str(param.device) # 将设备信息转为字符串
# 将设备信息写入 JSON 文件
with open('model_device_info.json', 'w') as f:
json.dump(device_info, f, indent=4)
### 展示平台
swanlab_config = {
"lora_rank": args.lora_rank,
"lora_alpha": args.lora_alpha,
"lora_dropout": args.lora_dropout,
}
swanlab_callback = SwanLabCallback(
project="finetune",
experiment_name="llama2-7b-alpaca-en-51k",
description="使用中文数据集实验",
workspace=None,
config=swanlab_config,
)
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
data_collator=data_collator,
callbacks=[swanlab_callback],
)
return trainer
# 处理数据
def process_data(data: dict, tokenizer, max_seq_length):
input_ids, attention_mask, labels = [], [], []
# 指令微调的数据
instruction_text = data['instruction']
human_text = data["input"]
assistant_text = data["output"]
input_text = f"<<SYS>>\n{instruction_text}\n<</SYS>>\n\n[INST]{human_text}[/INST]"
input_tokenizer = tokenizer(
input_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
output_tokenizer = tokenizer(
assistant_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
input_ids += (
input_tokenizer["input_ids"] + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
attention_mask += input_tokenizer["attention_mask"] + output_tokenizer["attention_mask"] + [1]
labels += ([-100] * len(input_tokenizer["input_ids"]) + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
if len(input_ids) > max_seq_length: # 做一个截断
input_ids = input_ids[:max_seq_length]
attention_mask = attention_mask[:max_seq_length]
labels = labels[:max_seq_length]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# 训练部分
def main():
args = configuration_parameter()
print("*****************加载分词器*************************")
# 加载分词器
model_path = args.model_name_or_path
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
print("*****************处理数据*************************")
# 处理数据
# 获得数据
data = pd.read_json(args.train_file, lines=True)
train_ds = Dataset.from_pandas(data)
train_dataset = train_ds.map(process_data,
fn_kwargs={"tokenizer": tokenizer, "max_seq_length": args.max_seq_length},
remove_columns=train_ds.column_names)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True, return_tensors="pt")
print(train_dataset, data_collator)
# 加载模型
print("*****************训练*************************")
trainer = load_model(args, train_dataset, data_collator)
trainer.train()
# 训练
final_save_path = join(args.output_dir)
trainer.save_model(final_save_path)
if __name__ == "__main__":
main()
在命令行运行如下代码:
torchrun --nproc_per_node=4 finetune.py 出现下图所示意味着训练正常运行。
3、SwanLab查看微调进展与结果
如果你还没有SwanLab账号,请在 官网 免费注册。
如果是第一次使用,需要先登录,打开命令行,输入:
swanlab login当你看到如下提示时:
swanlab: Logging into swanlab cloud.
swanlab: You can find your API key at: https://swanlab.cn/settings
swanlab: Paste an API key from your profile and hit enter, or press 'CTRL-C' to quit:在用户设置页面复制您的 API Key,粘贴后按下回车,即可完成登录。之后无需再次登录。
如果你的计算机不太支持
swanlab login的登录方式,也可以使用python脚本登录:
import swanlab
swanlab.login(api_key="你的API Key")
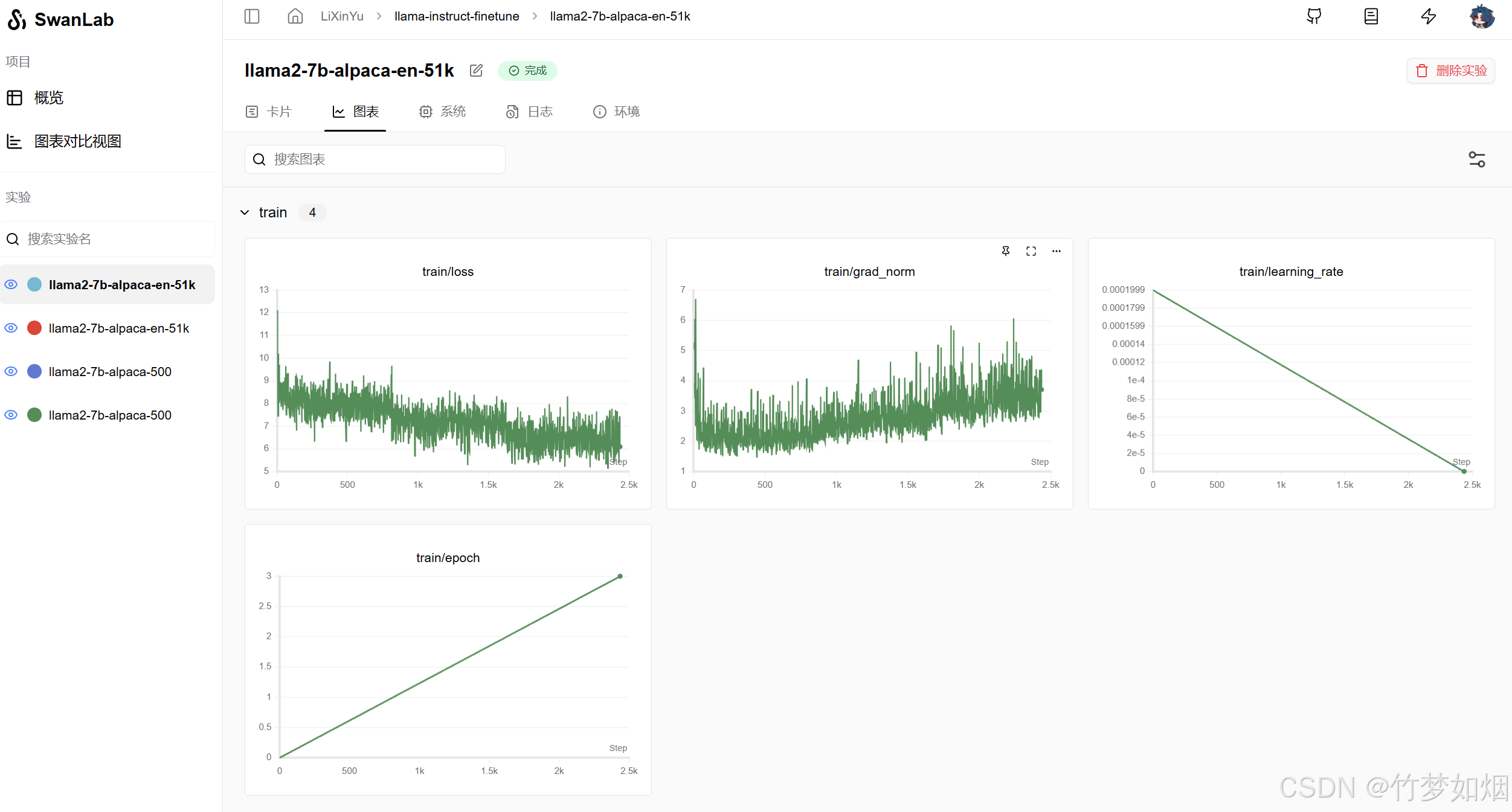
然后我们就直接可以查看我们的实验进度了,这是我的实验过程:llama-instruct-finetune
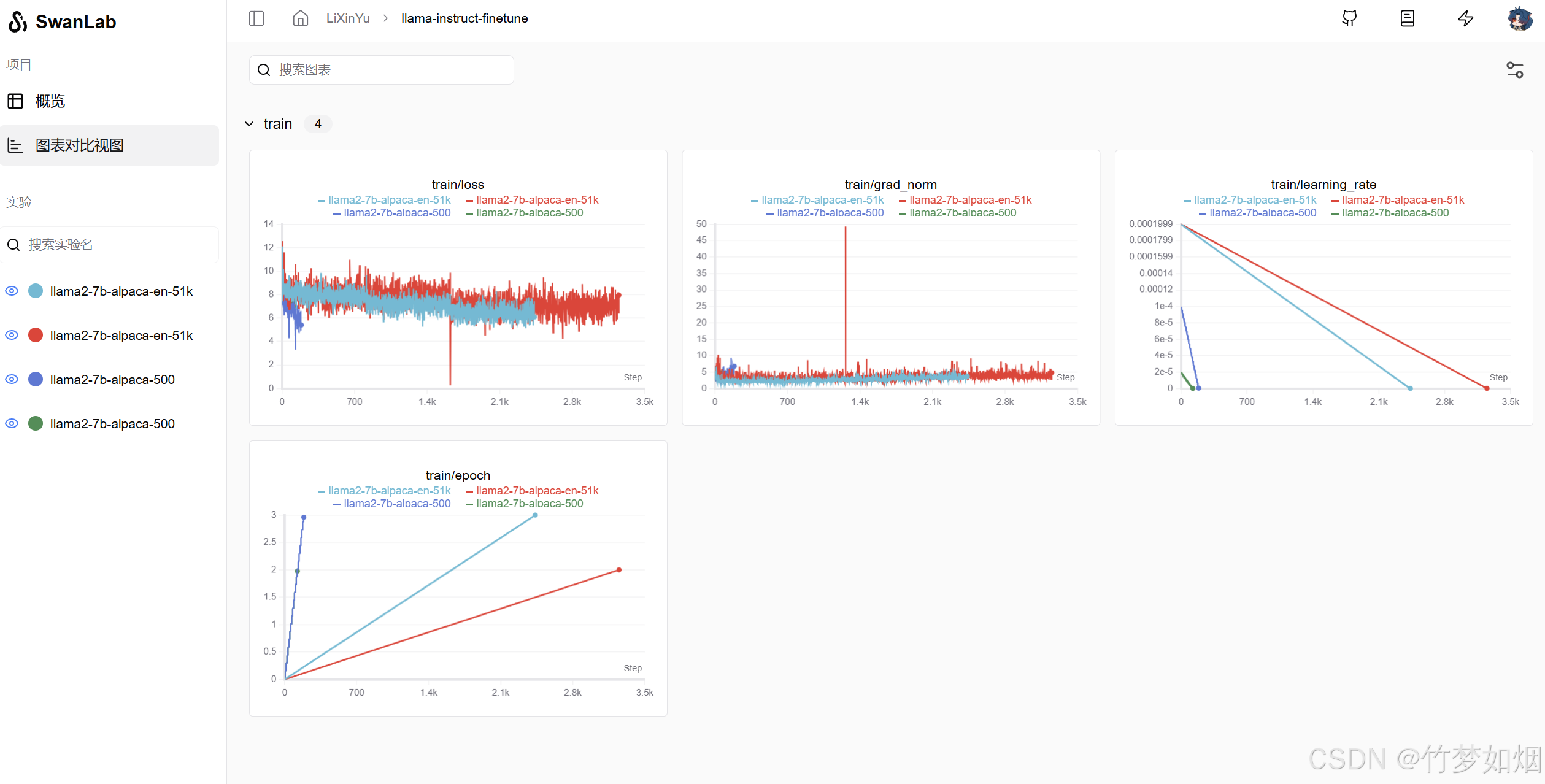
我们也可以通过图标对比试图来查看不同实验参数下的实验的过程
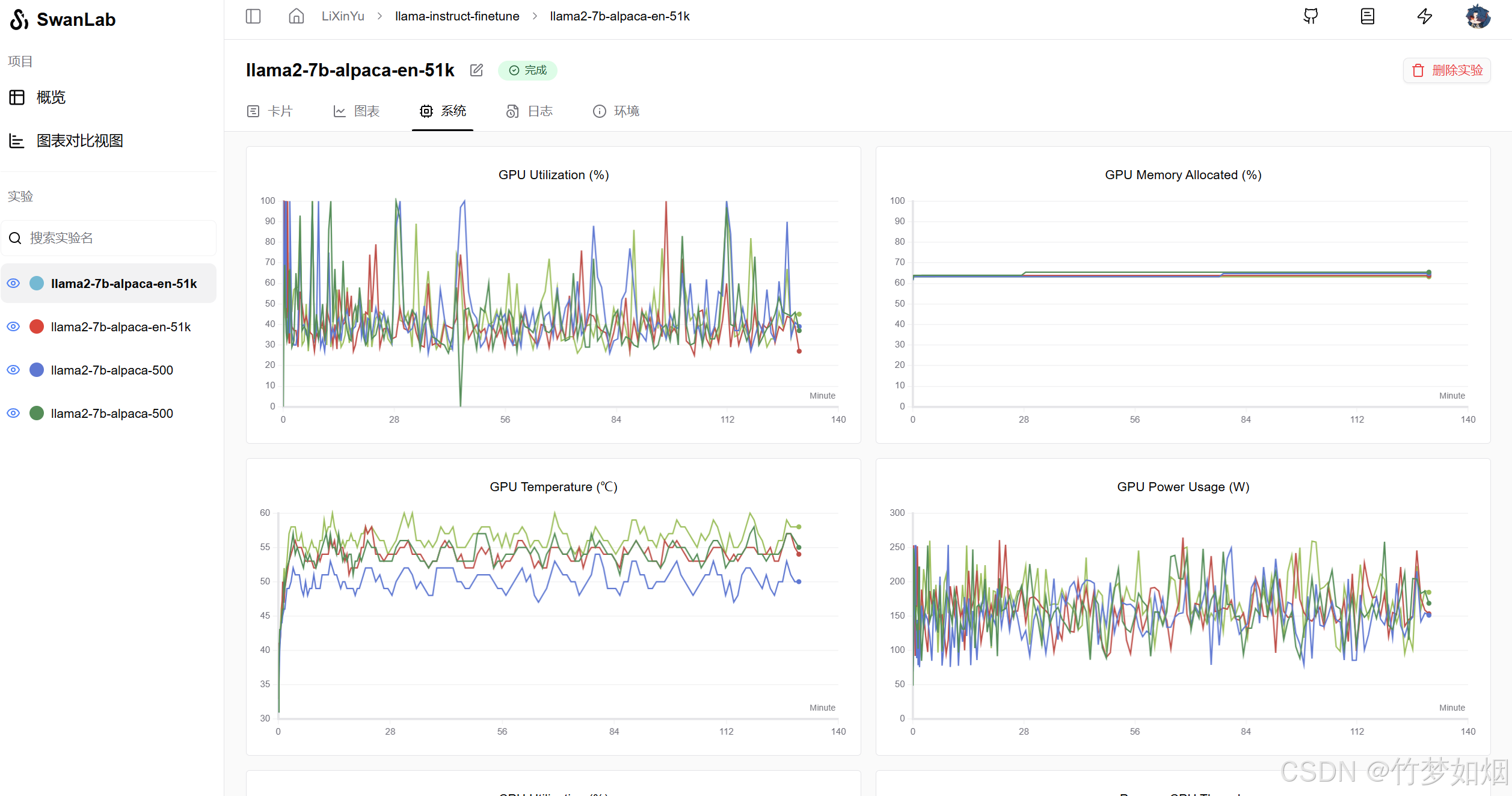
而SwanLab也增加了新的功能,可以查看我们的硬件设施,可以实时监控,我们可以根据我们设备的信息去思考为何会出现这些波动
参考文献
文章:
6000字长文告诉你:大模型「训练」与「微调」概念详解_模型微调和训练的区别-CSDN博客
DeepSeek-llm-7B-Chat微调教程(使用SwanLab可视化工具)_7b全参微调-CSDN博客
Qwen2大模型微调入门实战-命名实体识别(NER)任务 - 知乎
论文:
Pre-Trained Language Models and Their Applications
Adapting vs. Pre-Training Language Models for Historical Languages
Instruction Pre-Training: Language Models are Supervised Multitask Learners
LORA: LOW-RANK ADAPTATION OF LARGE LAN GUAGE MODELS
LLAMA-ADAPTER: EFFICIENT FINE-TUNING OF LARGE LANGUAGE MOD ELS WITH ZERO-INITIALIZED ATTENTION
Instruction Tuning for Large Language Models: A Survey
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Parameter-efficient fine-tuning of large-scale pre-trained language models
Evaluating Instruction-Tuned Large Language Models on Code Comprehension and Generation
When scaling meets llm finetuning: The effect of data, model and finetuning method

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









