







查找表(LUT,Look-up Table)的简单理解
引入:假设有一个 4 输入(a,b,c,d) 1 输出(o) 的逻辑单元,想要了解其内部结构。
输入按照 0000-1111 去遍历,记录输出。得到真值表,运用卡诺图对其化简,得到最简 pos/sop 表达式,用门电路把结构画出来。
真值表的变化反映电路的结构变化,门/线越多,延迟越大,频率越低。也就是表格变化时,电路工作速度不确定,导致严重的时序问题(竞争冒险,亚稳定状态)。
总结:表格的不确定会引起延迟的不确定性和设计复杂的不确定性。
扩展:如果不把 a,b,c,d 当作逻辑输入量,而是作为只读存储器的地址输入,输入输出的对应关系保存到只读存储器的对应单元里去。这样无需考虑数字电路的内部门电路,而是关注于查找表结果。这就是 FPGA 的核心原理,FPGA 中没有门电路,只有查找表。
查找表的功能:实现组合逻辑电路的功能。
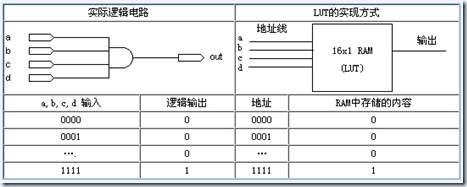
目前 FPGA 中多使用 4 输入的 LUT,所以每一个 LUT 可以看成一个有 4 位地址线的 RAM。当用户通过原理图或 HDL 语言描述了一个逻辑电路以后,PLD/FPGA 开发软件会自动计算逻辑电路的所有可能结果,并把真值表(即结果)事先写入 RAM,这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
初始向量就是输出不知道忘了多少次。。。
PS:参考文章 http://m.elecfans.com/article/772038.html

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









