







Open-Set Image Tagging with Multi-Grained Text Supervision
paper:https://arxiv.org/abs/2310.15200
code:https://github.com/xinyu1205/recognize-anything
RAM系列的第一版:Tag2Text 论文阅读请跳转:
图像标记模型Tag2Text论文详细阅读
RAM系列的第二版:RAM 论文阅读请跳转:
识别一切(RAM)论文详细阅读
此篇是RAM系列的第三版:RAM++
Abstract
在本文中,我们介绍了 Recognize Anything Plus Model(RAM++),这是一种有效利用多粒度文本监督的开放式图像标记模型。
以前的方法(如 CLIP)主要利用与图像配对的全局文本监督,导致在识别多个单独语义标签时性能不佳。 相比之下,RAM++ 将单独标签监督与全局文本监督无缝集成在一个统一的对齐框架内。这种整合不仅确保了对预定义标签类别的高效识别,还增强了对不同开放集类别的泛化能力。此外,RAM++ 还采用了大型语言模型(LLM),将语义受限的标签监督转换为更广泛的标签描述监督,从而丰富了开放集视觉描述概念的范围。
对各种图像识别基准的综合评估表明,RAM++ 在大多数方面都超过了现有的最先进(SOTA)开放式图像标记模型。具体来说,对于预定义的常用标签类别,RAM++ 在 OpenImages 和 ImageNet 上分别比 CLIP 提高了 10.2 mAP 和 15.4 mAP。对于超出预定义的开放集类别,RAM++ 在 OpenImages 上比 CLIP 和 RAM 分别提高了 5.0 mAP 和 6.4 mAP。 对于不同的人-物交互短语,RAM++ 在 HICO 基准上分别提高了 7.8 mAP 和 4.7 mAP。有关代码、数据集和预训练模型,请访问 https://github.com/xinyu1205/ recognize-anything。
1. Introduction
图像识别仍然是计算机视觉的一个基础研究领域,它要求机器根据给定图像输出各种语义内容。为此,有文本监督的视觉模型,如 CLIP [43]、ALIGN[22]和 Florence[56]利用互联网上的大规模图像文本对来学习综合视觉概念。这些模型在单标签图像分类[10]中表现出了显著的开放集识别能力,促进了它们在具有任意视觉概念的各种特定领域数据集上的应用[16, 49]。
尽管取得了这些进步,但这些模型主要依赖于全局文本监督,即直接将全局文本嵌入与相应的全局视觉特征相匹配。对于更复杂的多标签识别任务来说,这种监督方式并不理想。由于全局文本监督包含多种语义,单个标签语义的影响被大大削弱。如图 1 所示,文本 "一只狗坐在桌子旁边的沙发上 "包含了 “狗”、"沙发 "和 "桌子 "的概念。然而,它的全局嵌入却与这些单个语义存在部分分歧。
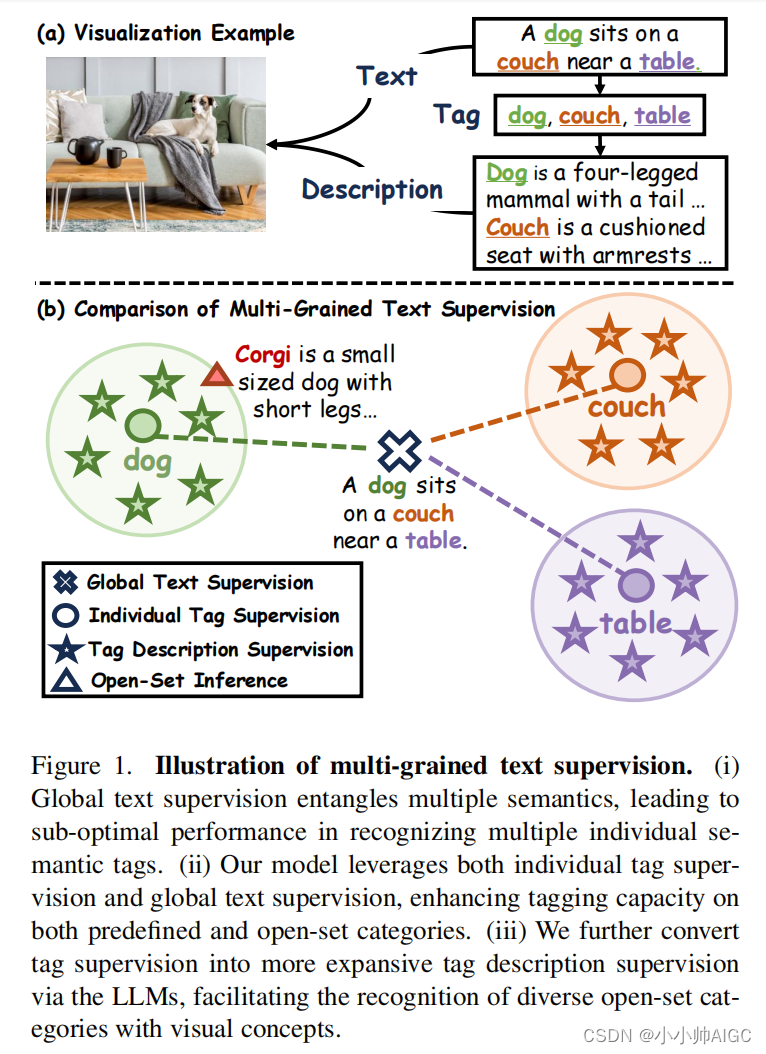
相比之下,具有单个标签监督功能的图像标签模型主要利用规模有限的人工注释图像标签[13, 28]。尽管最近的研究[20, 21, 59]利用图像-文本对大大扩展了图像标签的规模,**但图像标签模型仍然无法识别其预定义标签系统之外的标签类别。例如,将 "狗 "或 "饮料 "标签泛化为 "柯基犬 "或 "可口可乐 "等更具体的子类别就具有挑战性。**此外,"流星雨 "等众多短语类别也进一步提出了这一挑战。
针对上述局限性,我们的研究提出了一种开放集图像标记模型,利用多粒度文本监督,将全局文本监督和单个标记监督结合在一起。图像标签是从文本中自动解析出来的,提供了更精细的监督,确保了对预定义标签类别的识别能力。同时,多样化的文本监督使模型能够学习固定标签类别之外更广泛的文本语义,从而扩展了开放集类别的泛化能力。具体来说,我们将图像-标签-文本三元组纳入统一的对齐框架。多粒度文本监督通过高效的配准解码器与视觉空间特征进行交互[51]。与其他流行的对齐范式相比,我们的方法以高效率展示了卓越的标记性能。
此外,考虑到标签监督的可视化概念不足,我们通过大型语言模型(LLMs)[1, 37]将标签监督转换为更广泛的标签描述监督。大语言模型可为每个标签类别自动生成多个视觉描述。这些描述随后会通过一种新颖的自动重新加权机制整合到标签嵌入中,从而增强与相应图像特征的相关性。这种方法丰富了图像标记模型的视觉概念范围,增强了其在推理过程中将视觉描述纳入开放集识别的能力。例如,标签 "柯基犬 "可以扩展为描述性更强的 “一种体型小、腿短的狗…”,这有助于确定它在图像中的存在。
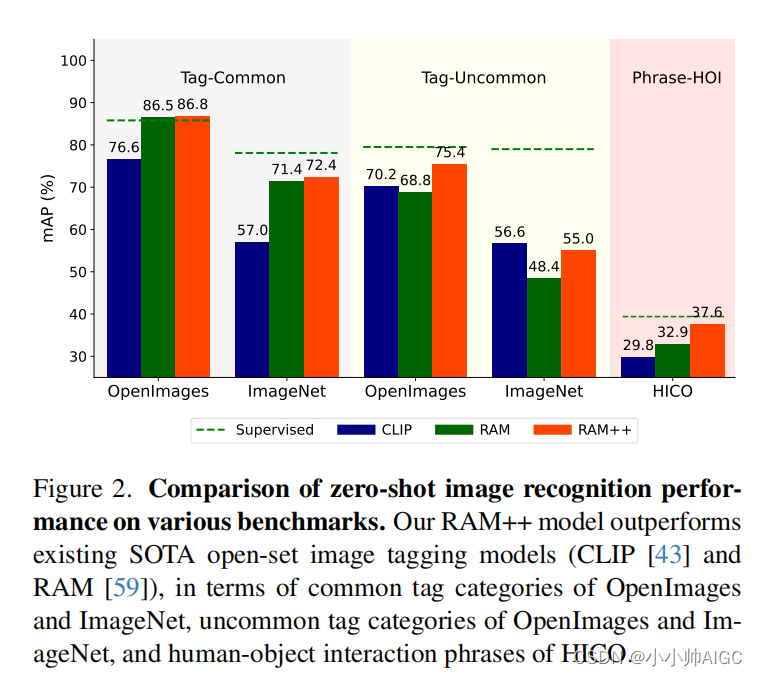
因此,在我们提出的方法基础上,我们推出了 Recognize Anything Plus Model (RAM++),这是一种开放集图像标记模型,在识别各种标记类别方面具有卓越的能力。 如图 2 所示,RAM++ 在各种基准测试中均超过了现有的 SOTA 开放集图像标记模型(CLIP [43] 和 RAM [59])。值得注意的是,在 OpenImages [25] 和 ImageNet [10] 的预定义常用类别上,RAM++ 比 CLIP 分别提高了 10.2 mAP 和 15.4 mAP。此外,与 CLIP 和 RAM 相比,RAM++ 在 OpenImages 的开放式非常见类别上也分别实现了 5.0 mAP 和 6.4 mAP 的改进。对于不同的人-物交互短语,RAM++ 在 HICO [6] 上分别比 CLIP 和 RAM 提高了 7.8 mAP 和 4.7 mAP。
我们的主要贡献可归纳如下:
- 我们在统一的对齐框架内整合了图像-标签-文本三元组,在预定义标签类别上取得了卓越的性能,并增强了对开放集类别的识别能力。
- 据我们所知,我们的工作是首次将 LLM 的知识纳入图像标签训练阶段,使模型能够在推理过程中将视觉描述概念用于开放集类别识别。综合实验证明了多粒度文本监督的有效性。
- 对 OpenImages、ImageNet 和 HICO 基准的评估表明,RAM++ 在大多数方面都超过了现有的 SOTA 开放集图像标记模型。综合实验证明了多粒度文本监督的有效性。
2. Related Works
Tag Supervision。图像标记(也称为多标签识别)涉及为图像分配多个标签。 传统方法主要依赖于有限的人工标注数据集 [8, 13, 28],导致泛化能力差。DualCoop [50] 和 MKT [17] 采用预先训练的视觉语言模型来提高开放集能力,但它们受到训练数据集规模的限制。 Tag2Text [21] 和 RAM [59] 基于图像-文本对获取大规模图像标签,在预定义类别上展示了先进的 zeroshot 能力。然而,所有这些模型都依赖于封闭语义范围的标签监督,限制了它们识别更多样化的开放标签类别的能力。我们的 RAM++ 无缝整合了多样化文本监督和标签监督,有效增强了开放集标签能力。
Text Supervision。具有文本监督功能的视觉模型可以通过视觉语言特征的对齐来识别开放集类别。CLIP[43]和 ALIGN[22]等先驱模型收集了数以百万计的图像-文本对,在单标签图像分类中表现出色[10]。然而,它们对全局文本监督的依赖,给多标签任务中的单个语义带来了挑战[59]。虽然其他研究(如 ALBEF [26] 和 BLIP [27])也采用了深度视觉语言特征融合技术,但我们的分析表明,它们在广泛类别标记任务中的效率和能力都有局限性。相比之下,RAM++ 在一个统一的对齐框架内对多个文本和单个标签进行了对齐,显示出卓越的高效标签性能。
Description Supervision。之前有几项研究证明了利用基于文本的类别描述提高图像识别性能的有效性。 然而,所有这些研究都依赖于外部自然语言数据库,如 handcraft [18, 19, 44]、Wikipedia [12, 39] 或 WordNet [4, 14, 49, 54]。随着 LLM [3, 37] 显示出强大的知识压缩能力,最近的工作将 LLM 的知识纳入 CLIP 的推理阶段,以提高性能 [9, 29, 36, 41, 45] 和可解释性 [35]。与这些方法不同,我们的工作开创性地将 LLM 知识整合到图像标记的训练过程中,自然而有效地增强了标记模型的开放集能力。
3. Approaches
3.1. Overview Framework
本节将详细介绍 RAM++,它是一种开放集图像标记模型,利用了多粒度文本监督,包括全局文本监督和单个标记描述监督。
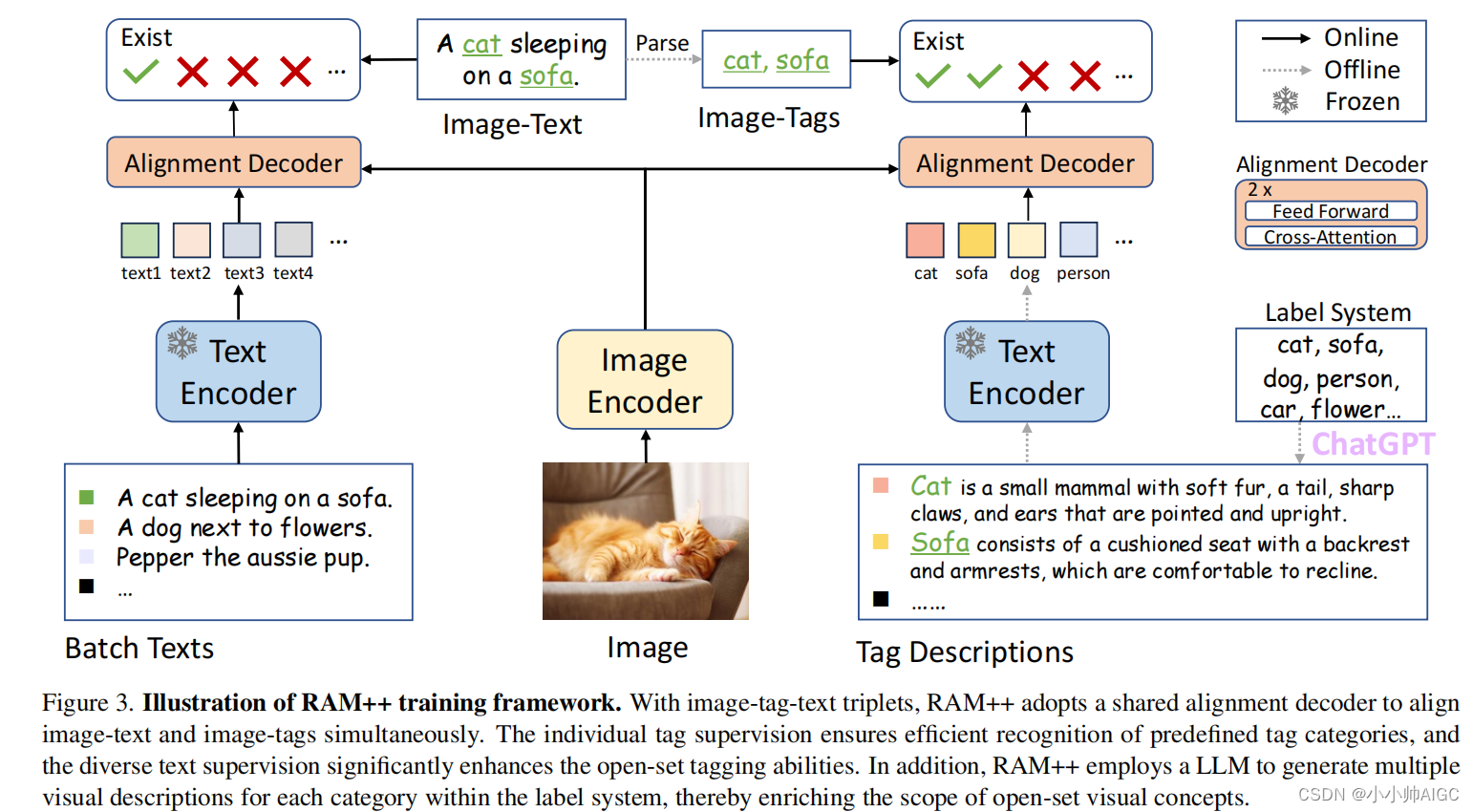
如图 3 所示,RAM++ 的架构由图像编码器、文本编码器和对齐解码器组成。
训练数据是图像-标记-文本三元组,包括图像-文本对和从文本中解析出的图像标记。
在训练过程中,输入模型的数据包括图像、可变批次文本和固定标签描述。然后,模型输出与每个图像-标记-文本对相对应的配准概率分数,并通过配准损失进行优化[46]。
3.2. Multi-Grained Text Alignment
Unified Image-Tag-Text Alignment Paradigm 统一图像-标记-文本对齐范例。对于图像-标签-文本三元组,RAM++ 采用共享配准解码器来同时配准图像-文本和图像-标签。 为清晰起见,图 3 将该框架分为两个部分。 左侧部分说明了图像-文本配准过程,即当前训练批次中的文本通过文本编码器提取全局文本嵌入。 这些文本嵌入随后通过配准解码器中的交叉注意层与图像特征配准,其中文本嵌入作为查询,图像特征作为键和值。相反,右侧部分强调的是图像标记过程,图像特征与固定的标记类别通过相同的文本编码器和对齐解码器进行交互。
对齐解码器(The alignment decoder)是一个双层注意力解码器[30, 51],每层包括一个交叉注意力层和一个前馈层。这种轻量级设计确保了涉及广泛类别的图像标记的效率。最重要的是,它消除了没有自注意层的标签嵌入之间的相互影响,从而使模型能够识别任意数量的标签类别而不影响性能。
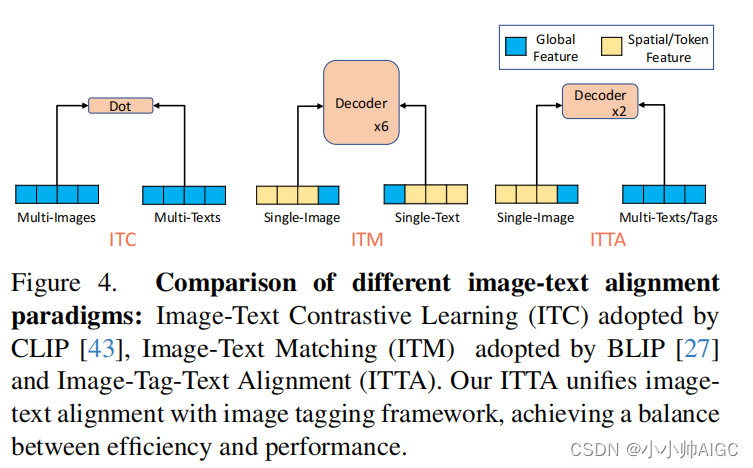
Alignment Paradigm Comparison 对齐范式比较。在图 4 中,我们将图像-标签-文本对齐(ITTA)与其他流行的对齐范式进行了比较:CLIP[43]和ALIGN[22]采用的图像-文本对比学习(ITC),以及ALBEF[26]和BLIP[27]采用的图像-文本匹配(ITM)。一方面,ITC 通过点乘法同时对多个图像和文本的全局特征进行配准,效率较高。然而,它依赖于浅层交互的全局文本监督,这给需要对多个单个标签进行局部识别的图像标记带来了挑战。另一方面,ITM 采用深度对齐解码器进行深度视觉语言特征融合。但是,它只能执行单个图像-文本对,因此在训练和推理中将图像与多个文本或标签对齐时,会产生巨大的计算成本。图 6 显示,带有 ITC 的 CLIP 和带有 ITM 的 BLIP 在图像标记任务中都表现不佳,达不到最佳性能。
因此,我们的 ITTA 解决了这些不足之处,将全局文本监督和单个标签监督结合在一起,确保了预定义和开放设置类别的稳健标签性能。此外,考虑到标签经常对应于不同的图像区域,我们采用的高效对齐解码器利用了图像空间特征而不是图像全局特征。因此,ITTA 在性能和效率之间取得了平衡,能够高效地将图像与数千个标签类别进行配准。关于不同配准范式的推理时间比较,请参见图 7。
3.3. LLM-Based Tag Description(基于 LLM 的标签描述)
另一种创新方法是基于 LLM 的标签描述,即利用 LLM 的知识将语义受限的标签监督转换为扩展的语义标签描述,从而丰富可描述的开放集视觉概念的范围。
LLM Prompt Design LLM 提示设计。要在标签系统中获得每个标签类别的描述,LLM 的提示设计至关重要。我们希望 LLM 生成的标签描述主要表现出两个特点:(i) 尽可能多样化,以覆盖更广泛的场景;(ii) 尽可能与图像特征相关,以确保高相关性。
受 [41] 的启发,我们为每个标签类别设计了以下共五个 LLM 提示:: (1) “Describe concisely what a(n) {} looks like”; (2) “How can you identify a(n) {} concisely?”; (3) “What does a(n) {} look like concisely?”; (4) “What are the identified characteristics of a(n) {}”; (5) “Please provide a concise description of the visual characteristics of* {}”.
Tag Description Generation 标签描述生成。根据所设计的 LLM 提示,我们通过调用 LLM API 自动生成每个标签类别的描述。具体来说,我们采用了 "GPT-35-turbo "模型[1],并设置了最大标记数 = 77,这与文本编码器的标记符长度相同。 为了提高 LLM 响应的多样性,我们设置了温度 = 0.99。因此,我们为每个 LLM 提示获取了 10 个独特的回复,每个类别总共有 50 个标记描述。
Automatic Re-weighting of Multiple Tag Descriptions 自动调整多个标签描述的权重。 每个类别的多个描述需要整合到一个标签嵌入中,以便进行图像标记。一种直接的策略是提示组合,即在文本表示空间中平均多个标签描述。这一策略与评估开放集标记模型的主流方法一致[41, 43]。然而,由于忽略了图像与多个候选标签描述之间的不同相似性,平均嵌入在训练过程中可能不是最优的。
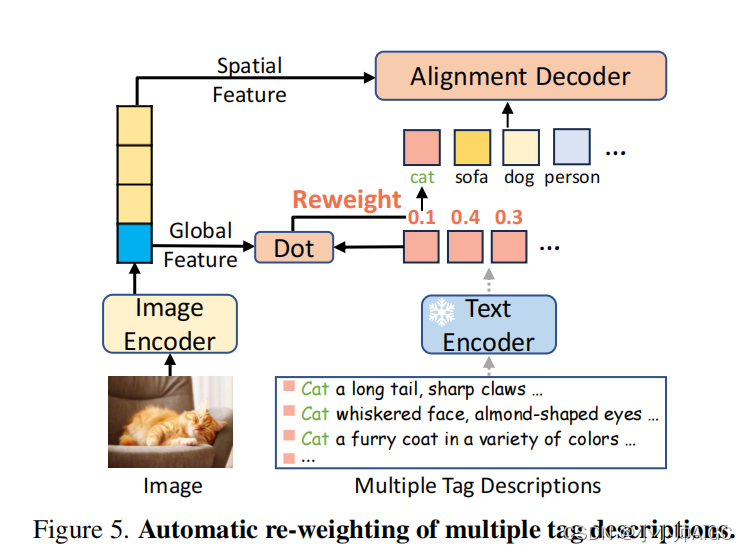
为了从多个候选标签描述中进行选择性学习,我们设计了一个自动重新加权模块来处理多个标签描述,如图 5 所示。第 i 个标签类别的概率分数计算如下: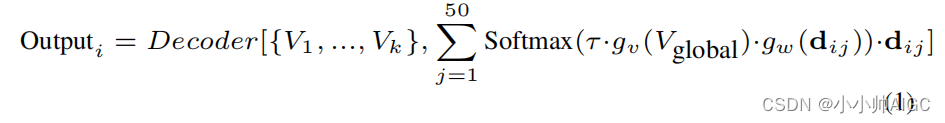
其中,Decoder 表示对齐解码器, V g l o b a l V_{global} Vglobal 指图像全局特征, { V 1 , . . . , V k } \{V_1, ..., V_k\} {V1,...,Vk} 表示图像空间特征。术语 d i j d_{ij} dij 表示第 j 个标签描述的嵌入。函数 g v g_v gv 和 g w g_w gw是将输入映射到同一维度的投影头,而 τ 是可学习的温度参数。
3.4. Online/Offline Design
我们的方法还结合了不同步骤的在线/离线设计,确保图像文本对齐和图像标记过程的无缝整合。在图像标记的情况下,标记描述的数量是固定的,但数量很大(例如,4, 500 tag × 50 des)。虽然提取所有标签描述的嵌入信息非常耗时,但可以使用现成的文本编码器离线预处理描述嵌入信息[43]。 相比之下,图像文本配准处理的是可变文本输入,由批量大小决定的输入量相对较小。因此,可以在线提取单个批次的文本嵌入,从而避免了大量的计算成本开销。
4. Experiment
4.1. Experimental Settings
Training Datasets。我们使用与 Tag2Text [21] 和 RAM [59] 相同的训练数据集。这些数据集基于开源图像-文本对数据集,包括两种设置:400 万(4M)图像数据集和 1400 万(14M)图像数据集。4M 设置包括两个人类标注的数据集(COCO [28] 和 VG [24]),以及两个网络数据集(SBU Caption [38] 和 CC-3M [48])。14M 数据集是 4M 数据集的延伸,包含了 CC-12M [5]。我们的标签系统包括文本中常用的 4585 个类别。对于 Tag2Text,图像标签是使用解析器[52]从与其配对的文本中自动提取的。对于 RAM,标签和文本都通过自动数据引擎进一步增强[59]。我们使用 RAM 数据集训练 RAM++,并在附录 F 中对 Tag2Text 数据集进行了额外的验证,以证实我们所建议方法的有效性。
Implementation Details.。我们采用在 ImageNet [10] 上预先训练好的 SwinBase [32] 作为图像编码器,并在其他比较方法中选择基础模型进行公平比较。我们利用 CLIP [43] 的现成文本编码器来提取文本和标签描述嵌入。我们采用 ASL [46] 的鲁棒对齐损失函数进行图像-文本对齐和图像标记。按照文献[21, 26, 27, 59]的方法,我们的模型在 COCO 数据集上进行了前处理后进一步微调,以提高其性能。得益于快速收敛的特性,4M 和 14M 版本的 RAM++ 分别只需要 1 天和 3 天的训练时间,使用的是 8 个 A100 GPU。
Evaluation Benchmarks。我们采用平均精确度(mAP)作为评估指标,该指标在评估多标签识别性能方面已得到广泛认可[30, 46, 47, 59]。
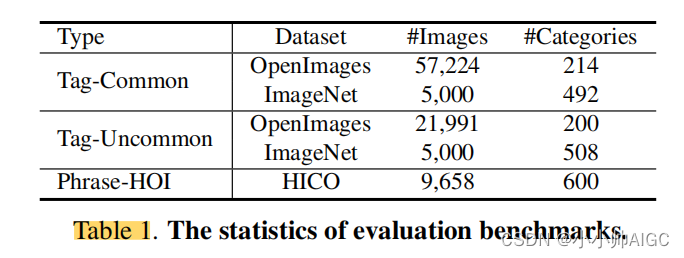
我们通过各种域外评估基准来评估图像标记功能。具体来说,我们使用了广泛使用的基准 OpenImages [25] 和 Ima-geNet [10]。鉴于 ImageNet 是单标签的,而且其测试集中存在标签缺失的情况 [2, 57],我们采用了 ImageNetMulti [2],测试集中的每幅图像都有多个标签,以获得更全面的注释。根据 RAM++ 标签系统的收录情况,这些基准的类别分为 "常见 "和 "不常见 "两类。为了对短语类别进行更多评估,我们采用了 HICO [6]基准,它是人与物体交互(HOI)方面的一个流行标准。 HICO 包含 80 个物体类别和 177 个动作类别,因此共有 600 个 "人-动作-物体 "短语组合。表 1 列出了评估基准的统计数据。值得注意的是,对于 RAM 和 RAM++,除了 Tag-Common 被视为预定义类别外,所有其他基准都是指开放集配置中的未见类别。
5. Conclusion
本文介绍了具有强大泛化能力的开放集图像标记模型 RAM++。综合评估表明,RAM++ 在大多数方面都超越了现有的 SOTA 模型。鉴于 LLM 在自然语言处理方面的革命,RAM++ 强调了整合自然语言知识可以显著增强视觉模型的能力。我们希望我们的努力能为其他工作提供一些启发。
细节理解
现有SOTA的图像识别模型分析:
1、CLIP 通过浅层交互(点积)对齐,尽管 CLIP 在单标签分类任务中表现出显著的性能,但浅层特征交互限制了其在更真实和细粒度的图像标记任务上的性能 。
2、RAM 为了识别固定标签系统之外的类别,RAM 使用现成的文本编码器来提取文本标签嵌入。然而,在没有直接文本监督的情况下,RAM 的开放集能力仅依赖于开放集标签查询和预定义类别之间的文本嵌入相似性。
RAM++ model:
对于图像-标签-文本三元组,RAM 仅执行图像标签对齐以进行图像标记。为了丰富固定标签类别之外的语义概念,除了标记框架内的图像标签对齐之外,还引入了 Image-Text 对齐
- 图像编码器:ImageNet上与训练的SwinBase
- 文本编码器:CLIP text encoder
- 对齐解码器:2层的transformer
- 损失函数:ASL(非对称损失)用于image-tag,image-text
标签提示:
为每个标签类别设计了总共5个LLM提示,如下所示:(1) “Describe concisely what a(n) {} looks like”; (2) “How can you identify a(n) {} concisely?”; (3) “What does a(n) {} look like concisely?”; (4) “What are the identifying characteristics of a(n) {}”; (5) “Please provide a concise description of the visual characteristics of {}”.
基于设计的LLM提示,通过调用LLM API自动为每个标签类别生成描述。具体来说,使用“GPT-35-turbo”模型,并设置最大标记长度 = 77,这是现成的文本编码的相同标记长度。为了促进LLM响应的多样性,设置temperature= 0.99。因此,为每个LLM提示获得了10个独特的响应,每个类别总共收集了50个标签描述。
RAM在Tag2Text的基础上删除了alignment模块,增加了CLIP进行开放词汇学习;RAM++在RAM基础上增加了图像-文本对的学习,提高了开放集检测效果。
















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









