







现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2023年6月2日
论文:arxiv.org/pdf/2306.01567v1.pdf![]() https://arxiv.org/pdf/2306.01567v1.pdf
https://arxiv.org/pdf/2306.01567v1.pdf
2. 摘要
SAM尽管使用了11亿个掩码进行训练,但SAM的掩码预测质量在许多情况下都存在不足,特别是在处理结构复杂的物体时。因此提出HQ-SAM,保持SAM原有的提示设计,使SAM具备准确分割任何目标的能力,可以在保持zero-shot能力的同时产生更高质量的掩码。
HQ-SAM重用并保留了SAM的预训练模型权重,同时只引入了最小的额外参数和计算。设计了一个可学习的高质量输出Token,并注入到SAM的掩码解码器中,负责预测高质量的掩码。而不是只应用它的掩码解码器功能,HQ-SAM还融合了早期和后期的ViT功能,以改善掩码细节。
为了训练引入的可学习参数,通过将现有的6个图像数据集与高精度的掩码注释合并而成,组成了新的数据集称为HQSeg-44K,包含44,000个极细粒度的图像掩码注释,涵盖了1000多个不同的语义类。由于规模较小的数据集和最小的集成架构,HQ-SAM可以在8个RTX 3090 gpu上仅需4小时即可完成训练。
为了验证HQ-SAM的有效性,进行了广泛的定量和定性实验分析。将HQ-SAM与SAM在不同下游任务的9个不同分割数据集上进行比较,其中7个数据集采用zero-shot传输协议,包括COCO、UVO、LVIS、HQ- ytvis、BIG、COIFT和HR-SOD。
3. 前言
SAM存在两个关键问题:1)粗糙的掩模边界,甚至经常忽略薄目标结构的分割。2)预测不正确,mask破损,或在具有挑战性的情况下出现重大错误。这通常与SAM误解薄目标结构有关,例如下图中最右边一栏中的风筝线。3)SAM提出的SA-1B数据集会带来巨大的成本影响,并且无法实现我们工作中所追求的高质量掩码,且只包含自动生成的掩码标签,缺少对复杂结构对象的非常准确的人工标注。
如下图所示,为预测的SAM和HQ-SAM的掩码情况,将相同的框或几个点作为输入提示。

二、HQ-SAM模型结构
直接对SAM解码器进行微调或引入新的解码器模块会严重降低一般的zero-shot分割性能。HQ-SAM直接通过重用SAM的图像编码器和掩码解码器来预测新的高质量掩码,在SAM中引入两个新的关键组件,即High-Quality Output Token和Global-local Feature Fusion,实现了高质量的掩码预测。为了保持SAM的零射击能力,轻量级HQ输出Token重用SAM的掩码解码器,并生成新的MLP层。在训练过程中,当我们对预训练的SAM模型参数进行固定时,在HQ-SAM中只有少数可学习的参数是可训练的。为了清晰起见,这里省略了提示编码器。具体流程如下图所示。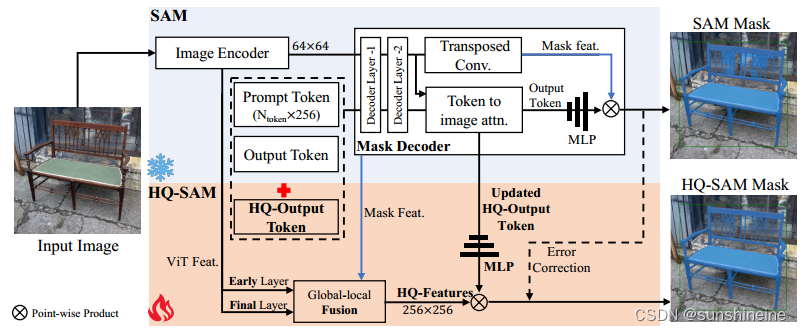
1. High-Quality Output Token
前言:SAM的原始掩码解码器设计中,采用Output Token(输出令牌)进行掩码预测,预测动态MLP(多层感知机)权重,然后与Mask features(掩码特征)进行逐点积。HQ-Output Token不是只重用SAM的掩码解码器功能,而是在一个精炼的功能集上运行,以实现准确的掩码细节。在训练期间,冻结了整个预训练的SAM参数,同时只更新HQ-Output Token,其相关的三层MLP和一个小的特征融合块。
HQ-SAM整体流程:则设计了一个可学习的HQ-Output Token,它与原始的提示Token和输出Token一起输入到SAM的掩码解码器,经过两层解码器,HQ-Output Token使用每个解码器层中其他Token共享的逐点MLP,在每个注意力层中,HQ-Output Token首先与其他Token进行自注意力,然后进行Token到图像和图像到Token的注意力,更新特征形成Updated HQ-Output Token。Updated HQ-Output Token可以访问全局图像上下文、提示Token的关键几何/类型信息以及其他Output Token的隐藏掩码信息。最后,添加了一个新的三层MLP(掩码预测层),从Updated HQ-Output Token生成动态卷积核,然后与融合的HQ-Features进行空间逐点积,以获得高质量的掩码生成。只允许HQ-Output Token及其相关的三层MLP被训练来纠正SAM的Output Token的掩码错误,以预测高质量的分割掩码。
高效token学习的三个主要优点:
1)引入忽略不计的参数,但显著提高了SAM掩码质量,节省HQ-SAM训练时间和数据效率;
2)学习到的token和MLP层不会过度拟合来掩盖特定数据集的标注偏差,从而保持SAM在新图像上强大的zero-shot分割能力,不会发生灾难性的知识遗忘。
3)带有可学习参数的提示符旨在帮助下游任务更好地进行上下文优化,与现有的基于提示或微调的工作不同,更关注SAM对高质量分割的最小适应。
2. Global-local Feature Fusion
非常精确的分割还要求输入图像特征具有丰富的全局语义上下文和局部边界细节。将SAM的掩码解码器的Mask Features与ViT编码器的早期和后期特征映射融合在一起,首先通过转置卷积将早期层和后期层ViT编码器特征上采样到空间大小256×256。然后,经过简单的卷积处理,以元素的方式总结了这三种类型的特征,同时使用了全局语义上下文和局部细粒度特征,最终得到HQ-Features。这种全局-局部特征融合是简单而有效的,产生了保留细节的分割结果,内存占用和计算负担很小。
3. HQ-SAM的训练和推理
3.1 数据集构建
现有的高质量分割大多是针对特定的分割任务进行训练,在一个封闭的世界范例中。然而,基于CRF的细分是坚持低级颜色边界,没有充分利用高级语义上下文,不能解决大的分割错误。而一些基于细化的工作采用单独的深度网络进行级联迭代细化,容易出现过拟合。学习准确的分割需要一个具有复杂和详细几何形状的不同对象的准确掩码注释的数据集,因此,提出了HQSeg-44K数据集。由于标注困难,HQSeg-44K对现有的6个图像数据集DIS、ThinObject-5K、FSS-1000、ECSSD、MSRA10K、DUT-OMRON进行了极细粒度的掩码标注,每个数据集平均包含7.5万个掩码标签,总共包含44,000个极细粒度的图像掩码注释。为了使HQ-SAM具有鲁棒性和可泛化性,HQSeg-44K包含1000多个不同的语义类。
3.2 HQ-SAM训练
在训练过程中,固定预训练的SAM模型的模型参数,可学习的参数仅包括HQ-Output Token,其相关的三层MLP和用于HQ-Features融合的三个简单卷积。采样混合类型的提示来训练HQ-SAM,包括边界框、随机采样点和粗掩码输入。通过在GT掩模的边界区域加入随机高斯噪声来生成这些退化的掩码。为了推广到不同的对象尺度,我们使用了大规模抖动。在8个Nvidia GeForce RTX 3090 gpu上进行训练,使用0.001的学习率,训练了12个epoch,在10个epoch后学习率下降,总批大小为32个,训练16.6K次迭代需要4小时。
3.3 HQ-SAM推理
遵循相同的SAM推理管道,但使用HQ-Output Token的掩码预测作为高质量的掩码预测。在推理过程中,将SAM掩码(通过Output Token)和我们的预测掩码(通过HQ-Output Token)的预测对数相加,以对空间分辨率256×256进行掩码校正。然后将校正后的掩码上采样到原始分辨率1024 ×1024作为输出。
3.4 SAM与HQ-SAM的训练与推理
如下表所示,为基于ViT-L的SAM与HQ-SAM的训练和推理比较。
HQ-SAM给SAM带来的额外计算负担可以忽略不计,模型参数增加不到0.5%,速度达到原来的96%。SAM-L在128个A100 gpu上进行了18万次迭代训练。HQ-SAM产生了更好的分割质量,并且训练快速且价格合理,基于SAM-L,只需要在8个RTX3090 gpu上训练HQ-SAM4小时。
三、实验流程
为了全面评估HQ-SAM的分割性能,在广泛的数据集上进行了实验,包括四个极细粒度的分割数据集:DIS、ThinObject-5K、COIFT和HR-SOD[。此外,还对各种基于图像/视频的分割任务在零镜头设置下的流行和具有挑战性的基准进行了实验,如COCO, UVO, LVIS, HQ-YTVIS和BIG。为了准确量化掩码质量的改善,不仅采用标准掩码AP或掩码mIoU,还采用边界指标mBIoU和边界APB。还通过将UVO和LVIS上的默认扩张比从0.02调整到0.01来评估更严格的APstrict B。为了对四种细粒度分割数据集进行评价,还报告了其中的平均边界和掩码IoU。对于HQ-YTVIS的视频实例分割评价,我们同时使用了Tube Boundary APB和Tube Mask APM。
补充实验:首先介绍了HQ-SAM的额外实验分析,包括在图像和视频基准上与SAM进行更多的zero-shot转移比较,如YTVIS和DAVIS。然后,描述了方法实现的更多细节,包括训练和推理。后提供了用于训练HQ-SAM的构建HQSeg-44K数据集的进一步细节。并展示了HQ-SAM和SAM在COCO、DIS-test、hrsod、NDD20、DAVIS和YTVIS上的广泛视觉结果比较。
这篇论文的实验部分是我目前看到内容最多最杂乱的,只能泛泛的概括一下,具体怎么做的实在总结不出来了,就算总结出来大家也懒得看,非常非常感兴趣的同学自己去膜拜吧
















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









