







主要思想:(语义+几何)
1. MaskRCNN进行语义分割,在基于每个对象都是不连续的假设基础上进行几何分割;
一种实时、对象感知、语义和动态的RGB-D SLAM 系统。
SLAM系统同时输出相机位姿和场景中运动物体位姿这个功能对于AR应用来说具有很大价值;
系统实时性还有较大问题,系统需要两块GPU(实验平台:2 * Nvidia GTX Titan X),一块做语义识别(MaskRCNN),一块用于SLAM中的几何分割和模型渲染(OpenGL)。当环境中没有运动物体时系统速度为30Hz,当有三个运动物体模型时系统性能下降至20Hz。但目前看来,是为数不多的几个能达到实时的语义SLAM。
摘要
MaskFusion可以识别、分割场景中的不同对象,并为其指定语义类标签,同时跟踪和重建这些对象,即使它们独立于相机移动。当RGB-D相机扫描杂乱的场景时,基于图像的实例级语义分割会创建语义对象腌膜,从而实现实时对象识别,并为世界地图创建对象级表示。与以前基于识别的SLAM系统不同,MaskFusion不需要识别对象的已知模型,并且可以处理多个独立的运动。
引言
MaskFusion贡献点:
(1) Mask-RCNN,强大的基于图像的实例级分割算法,可以预测80个对象类的对象类别标签。
(2) 基于几何的分割算法,根据深度和表面法线线索生成对象边缘图; 以提高对象掩码中对象边界的准确性。
(3)MaskFusion相对于以前的语义SLAM系统的额外优势在于它不需要场景是静态的,因此可以检测,跟踪和构建多个独立移动的物体。
(4)MaskFusion优于以前的动态SLAM系统的优点在于它实时地利用来自大量物体的语义信息来增强动态地图。
相关工作
动态SLAM中有两种主要方案: 非刚性表面重建和用于独立移动刚性物体的多体公式。
在第一种情况下,假设一个可变形的世界,并尽可能地进行刚性配准,而在第二种情况下,刚性对象实例被识别并稀疏或密集跟踪。这两个类别都使用基于模板或描述符的公式,这需要预先观察感兴趣的
对象以及无模板的方法。在场景的动态部分不感兴趣的情况下,将它们识别为异常值以避免优化后端中的错误是有价值的。
MaskFusion 与其他实时 SLAM 系统的属性比较。与之前的语义 SLAM 系统相比,MaskFusion 既是动态的(即使对象的运动与相机不同,它也会重建对象)和分割对象实例。与密集的非刚性重建系统不同,它可以重建整个场景并为不同的对象添加语义标签。请注意,虽然Co-Fusion可以使用语义提示来分割场景,但在这种情况下,系统不是实时的——只有Co-Fusion 的非语义版本具有实时能力。
Co-Fusion展示了根据语义标签跟踪、分割和重建对象的能力,但整个系统不具备实时能力,并且功能有限。
DynSLAM为自动驾驶应用开发了一种映射系统,能够分别重建静态环境和移动车辆。然而,整个系统不是实时的(这就是它没有出现在表 1 中的原因),并且车辆是它重建的唯一动态对象类,因此它的功能仅限于道路场景。
系统总览
1. MaskFusion框架

MaskFusion 实现了对象级别的实时密集动态 RGBD SLAM。从本质上讲,MaskFusion 是一个多模型 SLAM 系统,它为它在场景中识别的每个对象(除了背景模型)维护一个3D 表示。每个模型都被独立跟踪和融合。
多目标SLAM
跟踪:每个对象的 3D 几何图形表示为一组面元。 每个模型的六自由度姿态通过最小化能量来跟踪,该能量结合几何迭代最近点 (ICP) 误差和基于当前帧中对应点与存储的 3D 模型之间的亮度恒定性的光度成本,与 在前一帧摆姿势。为了降低计算需求并提高鲁棒性,仅单独跟踪非静态对象。 测试了两种不同的策略来确定对象是否是静态的:一种基于运动不一致性,另一种将人触摸的对象视为动态的。
MaskRCNN提供带有语义标签的对象Mask。尽管此算法提供了良好的对象掩码,但它存在两个缺点。首先,该算法不实时运行,只能以最大5Hz的频率运行。其次,对象边界并不完美-它们倾向于泄漏到背景中。
为了克服这两个缺点,基于对深度不连续性和表面法线的分析,运行了一种几何分割算法。与语义实例分割相反,几何分割实时运行并产生非常精确的对象边界。在消极的一面,基于几何的分割往往会过度分割对象。这两种分割策略的组合-在每帧基础上的几何分割和尽可能经常的语义分割-提供了两全其美,使我们能够 (1) 实时运行一个整体系统 (几何分割用于没有语义对象掩码的帧,虽然两者的组合用于具有对象掩码的帧) 和 (2) 由于几何分割而获得具有改进的对象边界的语义对象掩码。



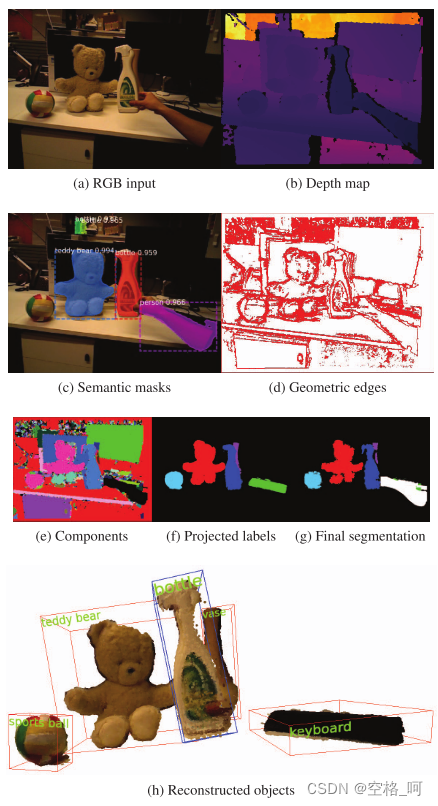
融合:通过使用对象标签将曲面与正确的模型关联,随着时间的推移,每个对象的几何体都会融合。我们的融合遵循与ElasticFusion相同的策略。
图像分割
基于以下三点问题的考虑:
(i) 当前的语义分割方法擅长检测对象,但倾向于提供不完善的对象边界。
(ii) 当前最先进的方法Mask-RCNN无法以帧速率执行。
(iii) RGBD帧中包含的信息可以实现图像的快速过分割,例如通过假设对象凸性。
我们的系统必须在并行线程中与跟踪和融合线程同时执行实例级语义分割。 然而,以不同频率同时执行两个程序需要同步策略。 我们在队列 Qf 中缓冲新帧,并将 SLAM 系统引用到队列的头部,而语义分割在队列的后面进行,如图 2a 所示。 这样,SLAM 的执行就会被语义分割的最坏情况处理时间延迟。 在我们的实验中,我们选择了 12 帧的队列长度,这涉及到大约 12 帧的延迟。 400 毫秒。 是否可以忽略此延迟取决于系统的用例。 即使存在延迟,系统仍以 30fps 的帧速率运行。 此外,由于掩码组件的执行频率较低,大多数帧无法进行语义分割,但每个帧都需要标记以融合新数据。,通过仅将无掩码帧的区域与现有模型相关联来解决此问题。

假设对象——尤其是人造对象——大部分是凸的,则可以建立快速分割方法,将边缘置于凹区域和深度不连续处。 在实践中,由于简化的前提,此类方法倾向于过度分割数据。
几何分割见:Real-Time and Scalable Incremental Segmentation on Dense SLAM
事实证明,在高度动态的场景中,或者在场景开始困难的情况下,使用上下文信息特别有用。通过能量最小化可能很难解决这些情况,而语义分割结果却显示出鲁棒性。
虽然 MaskFusion 在实现准确、稳健和通用的动态和语义 SLAM 系统方面取得了有意义的进展,但它在其解决的三个主要问题方面存在局限性:识别、重建和跟踪。 关于识别,MaskFusion 只能识别已经训练过 MaskRCNN [15] 的类(目前是 MS-COCO 数据集的 80 个类)中的对象,并且不考虑对象标签的错误分类。 其次,虽然 MaskFusion 可以通过从地图中移除一些非刚性物体(例如人类)来应对一些非刚性物体的存在,但跟踪和重建仅限于刚性物体。 第三,在没有可用的 3D 模型时跟踪几何信息很少的小物体可能会导致错误。 解决这些限制为未来的工作开辟了机会。
















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











