







 超级会员免费看
超级会员免费看
改进yolov8|Neck改进:Slim-Neck,精度参数量双改进
各位哥哥姐姐弟弟妹妹大家好,我是干饭王刘姐,主业干饭,主业2.0计算机研究生在读。
和我一起来改进yolov8变身计算机大牛吧!
本文中的论文笔记都是刘姐亲自整理,原创整理哦~
一、Slim-Neck简介
论文地址
https://arxiv.org/abs/2206.02424
代码地址
https://github.com/alanli1997/slim-neck-by-
gsconv
论文内容(原创整理)

前述
- 基于稀疏检测原理的两级检测器在小目标检测中表现较好,平均检测精度较高,但都是以牺牲速度为代价的。
- MobileNets使用大量的1 * 1密集卷积来融合独立计算的通道信息;ShuffleNets使用“通道洗牌”来实现通道信息的交互,GhostNet用“减半”SC操作来保留通道之间的交互信息。但是,1 * 1密集卷积反而占用了更多的计算资源,使用“通道洗牌”的效果仍然没有触及SC的结果,GhostNet或多或少又回到了SC的道路上,影响可能来自多个方面。
- 许多轻量级模型使用类似的思想来设计基本架构:从深度神经网络的开始到结束都只使用DSC。但是DSC的缺陷在主干中被直接放大,无论这是用于图像分类还是检测。我们认为,SC和DSC可以合作。我们注意到,仅通过混洗DSC的输出通道生成的特征图仍然是"深度方向分离的"。为了使DSC的输出尽可能接近SC,我们提出了一种新的方法——SC、DSC和混洗的混合卷积,称为GSConv。
主要贡献
- 我们介绍了一种新的轻量级卷积方法,GSConv。该方法使卷积计算的输出尽可能接近SC的输出,并降低了计算成本;
- 为自动驾驶汽车的检测器架构提供了一种设计范例–标准主干的细颈检测器;
- 验证了GSCv-Slim-Neck检测器上各种常用技巧的有效性,为该领域的研究提供了参考。
具体
- 而每次特征图的空间(宽度和高度)压缩和通道扩展都会造成部分语义信息的丢失。通道密集卷积计算最大限度地保留了每个通道之间的隐藏连接,但通道稀疏卷积完全切断了这些连接。GSConv以较低的时间复杂度尽可能多地保留这些连接。
-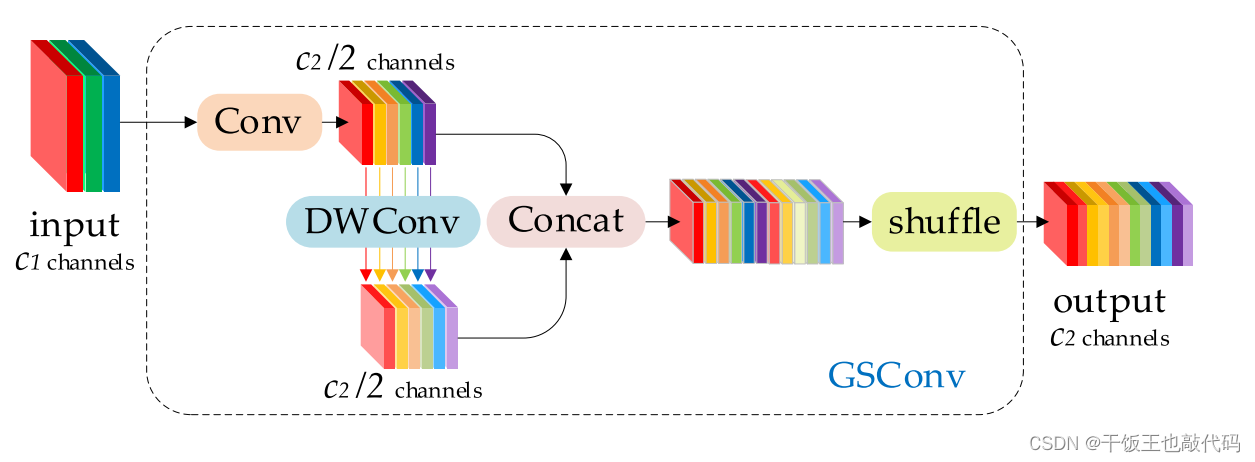
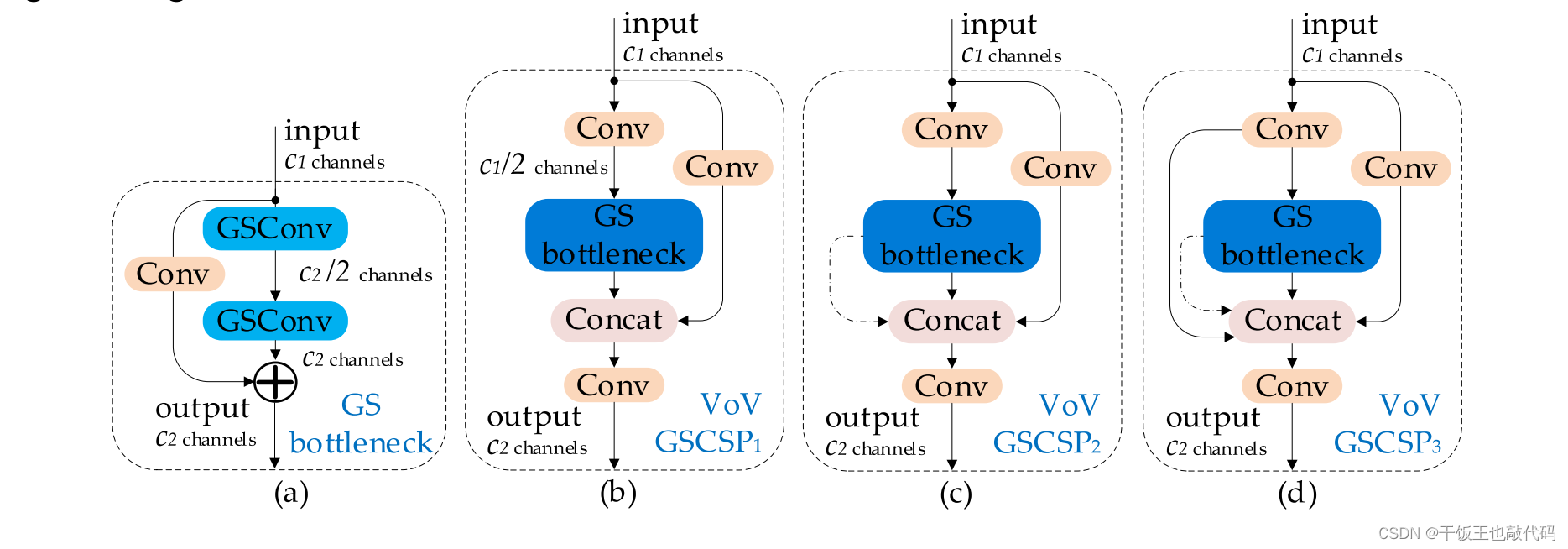
改进过程
核心代码(添加到ultralytics/nn/modules/conv.py)
class GSConv(nn.Module):
# GSConv https://github.com/AlanLi1997/slim-neck-by-gsconv
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__()
c_ = c2 // 2
self.cv1 = Conv(c1, c_, k, s, None, g, 1, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, 1 , act)
def forward(self, x):
x1 = self.cv1(x)
x2 = torch.cat((x1, self.cv2(x1)), 1)
# shuffle
# y = x2.reshape(x2.shape[0], 2, x2.shape[1] // 2, x2.shape[2], x2.shape[3])
# y = y.permute(0, 2, 1, 3, 4)
# return y.reshape(y.shape[0], -1, y.shape[3], y.shape[4])
b, n, h, w = x2.data.size()
b_n = b * n // 2
y = x2.reshape(b_n, 2, h * w)
y = y.permute(1, 0, 2)
y = y.reshape(2, -1, n // 2, h, w)
return torch.cat((y[0], y[1]), 1)
class GSConvns(GSConv):
# GSConv with a normative-shuffle https://github.com/AlanLi1997/slim-neck-by-gsconv
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__(c1, c2, k=1, s=1, g=1, act=True)
c_ = c2 // 2
self.shuf = nn.Conv2d(c_ * 2, c2, 1, 1, 0, bias=False)
def forward(self, x):
x1 = self.cv1(x)
x2 = torch.cat((x1, self.cv2(x1)), 1)
# normative-shuffle, TRT supported
return nn.ReLU(self.shuf(x2))
class GSBottleneck(nn.Module):
# GS Bottleneck https://github.com/AlanLi1997/slim-neck-by-gsconv
def __init__(self, c1, c2, k=3, s=1, e=0.5):
super().__init__()
c_ = int(c2*e)
# for lighting
self.conv_lighting = nn.Sequential(
GSConv(c1, c_, 1, 1),
GSConv(c_, c2, 3, 1, act=False))
self.shortcut = Conv(c1, c2, 1, 1, act=False)
def forward(self, x):
return self.conv_lighting(x) + self.shortcut(x)
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class VoVGSCSP(nn.Module):
# VoVGSCSP module with GSBottleneck
def __init__(self, cx, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
# self.gc1 = GSConv(c_, c_, 1, 1)
# self.gc2 = GSConv(c_, c_, 1, 1)
# self.gsb = GSBottleneck(c_, c_, 1, 1)
self.gsb = nn.Sequential(*(GSBottleneck(c_, c_, e=1.0) for _ in range(n)))
self.res = Conv(c_, c_, 3, 1, act=False)
self.cv3 = Conv(2 * c_, c2, 1) #
def forward(self, x):
x1 = self.gsb(self.cv1(x))
y = self.cv2(x)
return self.cv3(torch.cat((y, x1), dim=1))
class VoVGSCSPC(VoVGSCSP):
# cheap VoVGSCSP module with GSBottleneck
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2)
c_ = int(c2 * 0.5) # hidden channels
self.gsb = GSBottleneckC(c_, c_, 1, 1)
在ultralytics/nn/modules/conv.py中最上方“all”中引用’VoVGSCSP’, ‘VoVGSCSPC’, ‘GSConv’
ultralytics/nn/modules/init.py中
from .conv import (....,VoVGSCSP, VoVGSCSPC, GSConv)
在 ultralytics/nn/tasks.py 上方
from ultralytics.nn.modules import (....VoVGSCSP, VoVGSCSPC, GSConv)
在parse_model解析函数中添加如下代码:
if m in (..., VoVGSCSP, VoVGSCSPC,GSConv,SwinTransformer):
在ultralytics/cfg/models/v8文件夹下新建yolov8-SlimNeck.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, VoVGSCSP, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, VoVGSCSP, [256]] # 15 (P3/8-small)
- [-1, 1, GSConv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, VoVGSCSP, [512]] # 18 (P4/16-medium)
- [-1, 1, GSConv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, VoVGSCSP, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









