






在NLP和CV领域,通常通过在统一的预训练模型上进行微调,能够在各自领域的下游任务中实现SOTA(最先进)的结果。然而,在时序预测领域,由于数据量相对较少,难以训练出一个统一的预训练模型来覆盖所有时序任务。因此,时序预测算法的研究面临着较大挑战。
今天,我带来了一篇关于时序迁移学习的论文,提出了一种跨模态知识迁移的方法,将NLP中预训练的语言模型迁移到时序任务上。这一方法在多个时序任务中取得了与现有最先进模型(SOTA)相当甚至更优的性能。
接下来,我将按照论文的结构,对这篇文章的核心内容进行解读。
1. Abstract
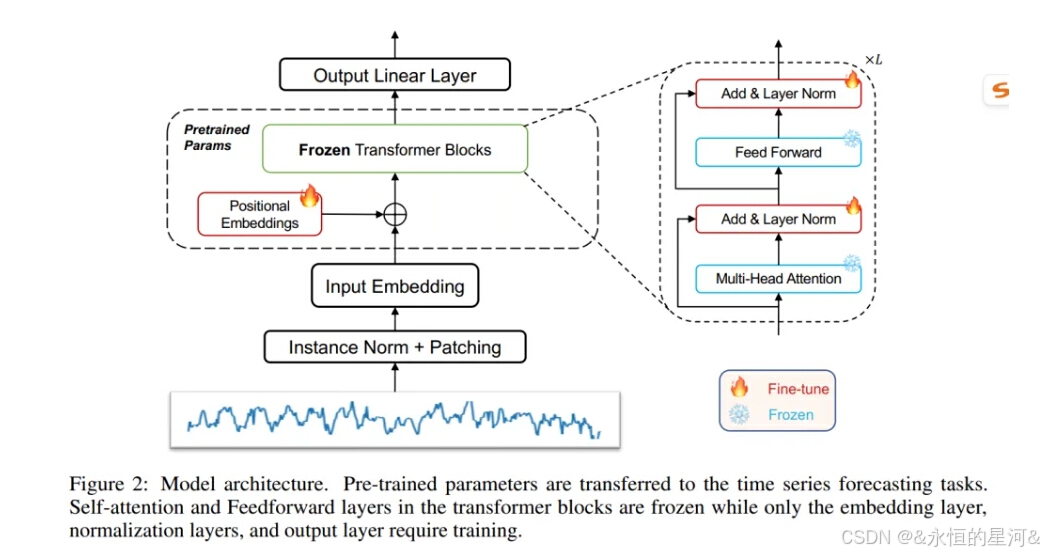
尽管在自然语言处理(NLP)和计算机视觉(CV)领域见证了预训练模型的巨大成功,但在一般时间序列分析方面的进展有限。与NLP和CV中可以使用统一模型执行不同任务不同,在每个时间序列分析任务(如分类、异常检测、预测和少样本学习)中,特定设计的方法仍然占主导地位。阻碍时间序列分析预训练模型发展的主要挑战是缺乏大量用于训练的数据。在本研究中,通过利用从数十亿个tokens中预训练的语言或计算机视觉模型来解决这一挑战。具体来说,避免改变预训练语言或图像模型中残差块的自注意力层和前馈层。这种模型被称为“冻结预训练Transformer”(Frozen Pretrained Transformer, FPT),通过在所有主要的时间序列任务上进行微调来评估其效果。本文的结果表明,在自然语言或图像上预训练的模型能够在所有主要的时间序列分析任务中表现出与现有方法相当或领先的性能,如图1所示。作者还从理论和实验上发现,自注意力模块的行为类似于主成分分析(PCA),这一观察有助于解释transformer是如何跨越领域差距的,并为理解预训练transformer的普适性提供了关键的一步。
完整文章链接:跨模态知识迁移:基于预训练语言模型的时序数据建模

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









