







 阿里新发布的Qwen1.5-32B语言模型在保持与大模型类似能力的同时,内存占用更小、推理速度更快。在基础和聊天评估中,32B模型表现出色,尤其适合对效率和成本敏感的用户。推荐使用Ollama框架本地部署或在线体验。
阿里新发布的Qwen1.5-32B语言模型在保持与大模型类似能力的同时,内存占用更小、推理速度更快。在基础和聊天评估中,32B模型表现出色,尤其适合对效率和成本敏感的用户。推荐使用Ollama框架本地部署或在线体验。
简介
开源社区长期以来一直在寻求一种能在性能、效率和内存占用之间达到理想平衡的模型。尽管出现了诸如Qwen1.5-72B和DBRX这样的SOTA模型,但这些模型持续面临诸如内存消耗巨大、推理速度缓慢以及显著的微调成本等问题。当前,参数量约30B的模型往往在这方面被看好,得到很多用户的青睐。顺应这一趋势,阿里推出Qwen1.5语言模型系列的最新成员:Qwen1.5-32B和Qwen1.5-32B-Chat。

效果
Qwen1.5-32B 是 Qwen1.5 语言模型系列的最新成员,除了模型大小外,其在模型架构上除了GQA几乎无其他差异。GQA能让该模型在模型服务时具有更高的推理效率潜力。
以下对比展示了其与参数量约为30B或更大的当前最优(SOTA)模型在基础能力评估、chat评估以及多语言评估方面的性能。以下是对于基础语言模型能力的评估结果:
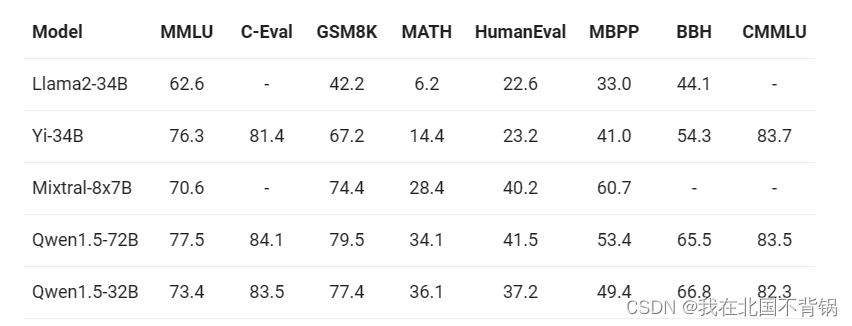
阿里Qwen-1.5-32B模型在多种任务上展现出颇具竞争力的表现,涵盖MMLU、GSM8K、HumanEval以及BBH等。相较于72B参数模型,Qwen1.5-32B虽在性能上有轻微下降,但在多数任务中仍优于其他30B级别模型,如Llama2-34B和Mixtral-8x7B。
在Chat模型的评估上,遵循Qwen1.5的评估方案,对它们在MT-Bench与Alpaca-Eval 2.0上的表现进行了测试。具体结果如下:
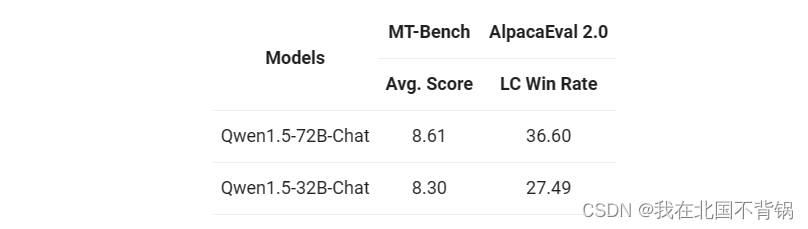
值得注意的是,Qwen1.5-32B-Chat的得分超过8分,且Qwen1.5-32B-Chat与Qwen1.5-72B-Chat之间的差距相对较小。这一结果表明,对于需要更高效、更经济实惠的应用解决方案的用户而言,32B模型是一个可行的选择。
本地使用
Qwen-1.5-32B模型使用与其他参数模型类似,这里推荐使用Ollama框架。
ollama run qwen:32b
在线体验
https://huggingface.co/spaces/Qwen/Qwen1.5-32B-Chat-demo

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









