






采用时间序列分析和机器学习方法处理这些数据_使用并网光伏系统故障诊断数据集来构建一个有效的故障诊断模型, 从数据加载、预处理、特征工程,有效处理并网光伏系统故障诊断数据集
假设你有下面这个数据集,,你该如何处理应对?
文章目录
并网光伏系统故障诊断数据集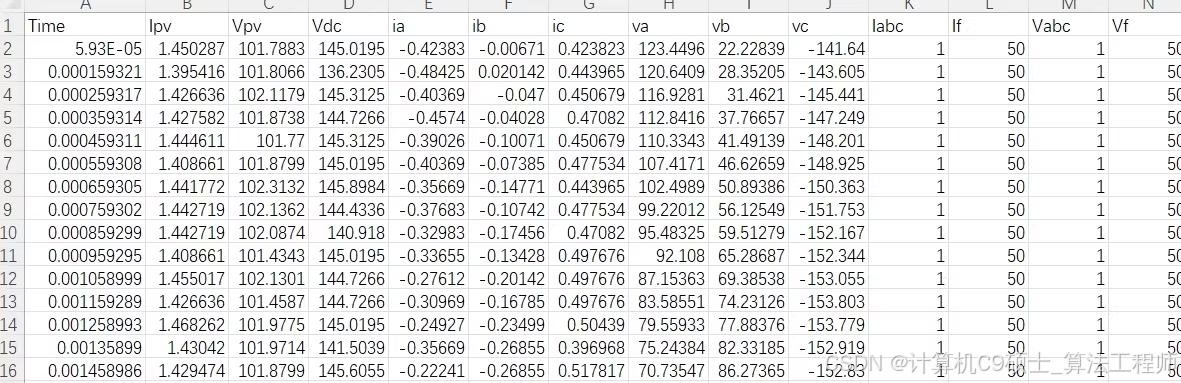
【文件目录】包含CSV_Files.zip,
F0L.mat, F0M.mat, F1L.mat, F1M.mat,
F2L.mat, F2M.mat, F3L.mat, F3M.mat,
F4L.mat, F4M.mat, F5L.mat, F5M.mat,
F6L.mat, F6M.mat, F7L.mat, F7M.mat.
即.csv格式(.zip内)和.mat格式文件各16个
以及ReadMe.pdf原作者英文介绍及通讯地址。

故障数据文件标签标记为Fxy
x∈{0, …
.7}]表示故障场景,其中0是无故障数据
y=L (有限功率模式IPPT) /M (最大功率模式MPPT)
例如F4M是MPPT模式下的故障类型F4
'0’代表无故障实验
'1’代表光伏阵列故障
'2’代表逆变器故障
'3’代表电网异常
‘4’代表反馈传感器故障
'5"6"7’代表不同严重程度的MPPT控制器故障
基于故障数据文件标签规则,那么就可以呢_更精确地处理和理解这些数据。将按照之前提到的流程指南来构建一个故障诊断模型,并特别注意如何根据新的标签规则处理和解释数据。
1. 数据加载与理解
首先,我们需要加载并理解提供的CSV文件和MAT文件的内容,同时确保我们正确地解析了故障类型标签。
import pandas as pd
import numpy as np
from scipy.io import loadmat
import os
import zipfile
# 解压缩CSV文件
with zipfile.ZipFile('path/to/CSV_Files.zip', 'r') as zip_ref:
zip_ref.extractall('extracted_csv_files')
# 加载CSV文件
csv_data = {}
for file in os.listdir('extracted_csv_files'):
if file.endswith('.csv'):
csv_data[file] = pd.read_csv(os.path.join('extracted_csv_files', file))
# 加载MAT文件
mat_files = ['F0L.mat', 'F0M.mat', 'F1L.mat', 'F1M.mat', 'F2L.mat', 'F2M.mat',
'F3L.mat', 'F3M.mat', 'F4L.mat', 'F4M.mat', 'F5L.mat', 'F5M.mat',
'F6L.mat', 'F6M.mat', 'F7L.mat', 'F7M.mat']
mat_data = {file: loadmat(f'path/to/{file}') for file in mat_files}
2. 数据预处理
合并数据
我们需要将CSV和MAT文件中的数据合并到一个包含所有相关信息的数据集中,并确保数据对齐。
def process_mat_file(mat_dict, fault_type):
# 提取MAT文件中的关键参数
data = mat_dict['data'] # 假设MAT文件中有一个名为'data'的键
time = data[:, 0]
Ipv = data[:, 1]
Vpv = data[:, 2]
Vdc = data[:, 3]
ia = data[:, 4]
ib = data[:, 5]
ic = data[:, 6]
va = data[:, 7]
vb = data[:, 8]
vc = data[:, 9]
labc = data[:, 10]
If = data[:, 11]
Vabc = data[:, 12]
Vf = data[:, 13]
# 创建DataFrame
df = pd.DataFrame({
'time': time,
'Ipv': Ipv,
'Vpv': Vpv,
'Vdc': Vdc,
'ia': ia,
'ib': ib,
'ic': ic,
'va': va,
'vb': vb,
'vc': vc,
'labc': labc,
'If': If,
'Vabc': Vabc,
'Vf': Vf,
'fault_type': [fault_type] * len(time)
})
return df
# 故障类型映射
fault_map = {
'F0': 'No Fault',
'F1': 'PV Array Fault',
'F2': 'Inverter Fault',
'F3': 'Grid Abnormality',
'F4': 'Feedback Sensor Fault',
'F5': 'MPPT Controller Fault - Mild',
'F6': 'MPPT Controller Fault - Moderate',
'F7': 'MPPT Controller Fault - Severe'
}
# 处理所有MAT文件
processed_data = []
for file, data in mat_data.items():
fault_code = file.split('.')[0] # 获取故障代码标识符
fault_type = fault_map[fault_code[:-1]] # 使用映射获取故障类型
operation_mode = 'IPPT' if fault_code[-1] == 'L' else 'MPPT' # 确定操作模式
processed_data.append(process_mat_file(data, f'{fault_type} ({operation_mode})'))
# 合并所有数据
combined_df = pd.concat(processed_data, ignore_index=True)
3. 特征工程
构造额外的特征可以帮助提高模型的表现。
- 时间特性:从时间戳中提取周期性特性。
- 滞后特征:创建过去几个时间段的测量值作为新特征。
- 滚动窗口统计:计算滚动平均、标准差等统计量。
- 故障模式编码:将故障类型转换为数值编码。
# 循环特性
combined_df['time_sin'] = np.sin(2 * np.pi * combined_df['time'] / combined_df['time'].max())
combined_df['time_cos'] = np.cos(2 * np.pi * combined_df['time'] / combined_df['time'].max())
# 滞后特征
lag_features = ['Ipv', 'Vpv', 'Vdc', 'ia', 'ib', 'ic', 'va', 'vb', 'vc', 'labc', 'If', 'Vabc', 'Vf']
for feature in lag_features:
for lag in [1, 2, 3]:
combined_df[f'{feature}_lag_{lag}'] = combined_df.groupby('fault_type')[feature].shift(lag)
# 滚动窗口统计
window_size = 10
for feature in lag_features:
combined_df[f'{feature}_rolling_mean'] = combined_df.groupby('fault_type')[feature].transform(lambda x: x.rolling(window=window_size).mean())
combined_df[f'{feature}_rolling_std'] = combined_df.groupby('fault_type')[feature].transform(lambda x: x.rolling(window=window_size).std())
# 故障模式编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
combined_df['fault_type_encoded'] = le.fit_transform(combined_df['fault_type'])
4. 模型选择与训练
我们可以使用分类算法如随机森林、支持向量机(SVM)、XGBoost等。这里我们选择使用XGBoost作为示例。
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
# 准备训练数据
features = [col for col in combined_df.columns if col not in ['time', 'fault_type']]
target = 'fault_type_encoded'
X = combined_df[features].dropna() # 移除含有NaN值的行
y = combined_df.loc[X.index, target]
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)
model.fit(X_train, y_train)
# 预测并评估模型
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
5. 模型评估与优化
评估模型性能,并尝试调整超参数或引入更多特征来提高模型的表现。
from sklearn.model_selection import GridSearchCV
# 超参数调优
param_grid = {
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 5, 7]
}
grid_search = GridSearchCV(estimator=XGBClassifier(random_state=42), param_grid=param_grid, cv=3, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_model = grid_search.best_estimator_
print("Best parameters found: ", grid_search.best_params_)
6. 测试与推理
在测试集上评估模型表现,并保存最佳模型用于后续的推理任务。
# 使用最佳模型进行预测
final_predictions = best_model.predict(X_test)
# 将预测结果反编码回原始标签
predicted_fault_types = le.inverse_transform(final_predictions)
# 保存预测结果
pd.DataFrame({'time': combined_df.loc[X_test.index, 'time'], 'predicted_fault_type': predicted_fault_types}).to_csv('predictions.csv', index=False)
7. 部署与监控
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用环境中。这可能涉及到将模型导出为ONNX格式或其他适合部署的格式,以及编写相应的API接口来接收实时数据输入并返回诊断结果。
注意事项
- 持续改进:随着新数据的积累,模型可能需要不断更新和优化。
- 解释性:为了提高模型的信任度,可以使用SHAP值或其他解释性工具来解释模型决策过程。
- 外部数据源:考虑引入更多的外部数据源,例如环境温度、光照强度等,以提高诊断准确性。
以上是针对并网光伏系统故障诊断数据集的一个完整解决方案,特别注意了你提供的故障类型标签规则。如果你有更多具体问题或需要进一步的帮助,请随时提问。希望这能帮助你顺利地开始项目!
【数据说明】故障数据文件标记为“Fxy”,其中:
x∈{0,1,…,7}表示故障场景:“0”是一个无故障的数据;“1”、…、“7”是7种类型的标签;
y∈{‘L’,'M}表示运算模式:“L”是有限功率模式(IPPT);“M”是最大功率模式(MPPT)
例如“F4M”是MPPT模式下的故障类型F4,“F1L”是IPPT模式中的故障类型F1。
涉及的光伏系统故障类型包括光伏阵列故障、逆变器故障、网络异常、反馈传感器故障以及不同严重程度的MPPT控制器故障。
其中,每个数据文件包括下列参数:
时间:以秒为单位的平均采样时间T_s=9.9989μs
Ipv:光伏阵列电流测量值
Vpv:光伏阵列电压测量值
Vdc:直流电压测量值
ia、ib、ic:三相电流测量值
va、vb、vc:三相电压测量值
labc:正序估计电流大小
If:正序估计电流频率
Vabc:正序估计电压大小
Vf:正序估计电压频率
使用并网光伏系统故障诊断数据集来构建一个有效的故障诊断模型,我们将采用时间序列分析和机器学习方法处理这些数据。,包括数据加载、预处理、特征工程、模型选择与训练、评估和部署。
1. 数据加载与理解
首先,我们需要加载并理解提供的CSV文件和MAT文件的内容。由于MAT文件是二进制格式,我们可以使用scipy.io.loadmat函数来加载它们。
import pandas as pd
import numpy as np
from scipy.io import loadmat
import os
import zipfile
# 解压缩CSV文件
with zipfile.ZipFile('path/to/CSV_Files.zip', 'r') as zip_ref:
zip_ref.extractall('extracted_csv_files')
# 加载CSV文件
csv_data = {}
for file in os.listdir('extracted_csv_files'):
if file.endswith('.csv'):
csv_data[file] = pd.read_csv(os.path.join('extracted_csv_files', file))
# 加载MAT文件
mat_files = ['F0L.mat', 'F0M.mat', 'F1L.mat', 'F1M.mat', 'F2L.mat', 'F2M.mat',
'F3L.mat', 'F3M.mat', 'F4L.mat', 'F4M.mat', 'F5L.mat', 'F5M.mat',
'F6L.mat', 'F6M.mat', 'F7L.mat', 'F7M.mat']
mat_data = {file: loadmat(f'path/to/{file}') for file in mat_files}
2. 数据预处理
合并数据
我们需要将CSV和MAT文件中的数据合并到一个包含所有相关信息的数据集中,并确保数据对齐。
def process_mat_file(mat_dict, fault_type):
# 提取MAT文件中的关键参数
data = mat_dict['data'] # 假设MAT文件中有一个名为'data'的键
time = data[:, 0]
Ipv = data[:, 1]
Vpv = data[:, 2]
Vdc = data[:, 3]
ia = data[:, 4]
ib = data[:, 5]
ic = data[:, 6]
va = data[:, 7]
vb = data[:, 8]
vc = data[:, 9]
labc = data[:, 10]
If = data[:, 11]
Vabc = data[:, 12]
Vf = data[:, 13]
# 创建DataFrame
df = pd.DataFrame({
'time': time,
'Ipv': Ipv,
'Vpv': Vpv,
'Vdc': Vdc,
'ia': ia,
'ib': ib,
'ic': ic,
'va': va,
'vb': vb,
'vc': vc,
'labc': labc,
'If': If,
'Vabc': Vabc,
'Vf': Vf,
'fault_type': [fault_type] * len(time)
})
return df
# 处理所有MAT文件
processed_data = []
for file, data in mat_data.items():
fault_type = file.split('.')[0] # 获取故障类型标识符
processed_data.append(process_mat_file(data, fault_type))
# 合并所有数据
combined_df = pd.concat(processed_data, ignore_index=True)
数据清洗
检查并处理任何缺失值或异常值。
# 检查缺失值
print(combined_df.isnull().sum())
# 根据具体情况填充或删除缺失值
combined_df.fillna(method='ffill', inplace=True) # 前向填充
3. 特征工程
构造额外的特征可以帮助提高模型的表现。
- 时间特性:从时间戳中提取周期性特性。
- 滞后特征:创建过去几个时间段的测量值作为新特征。
- 滚动窗口统计:计算滚动平均、标准差等统计量。
- 故障模式编码:将故障类型转换为数值编码。
# 循环特性
combined_df['time_sin'] = np.sin(2 * np.pi * combined_df['time'] / combined_df['time'].max())
combined_df['time_cos'] = np.cos(2 * np.pi * combined_df['time'] / combined_df['time'].max())
# 滞后特征
lag_features = ['Ipv', 'Vpv', 'Vdc', 'ia', 'ib', 'ic', 'va', 'vb', 'vc', 'labc', 'If', 'Vabc', 'Vf']
for feature in lag_features:
for lag in [1, 2, 3]:
combined_df[f'{feature}_lag_{lag}'] = combined_df.groupby('fault_type')[feature].shift(lag)
# 滚动窗口统计
window_size = 10
for feature in lag_features:
combined_df[f'{feature}_rolling_mean'] = combined_df.groupby('fault_type')[feature].transform(lambda x: x.rolling(window=window_size).mean())
combined_df[f'{feature}_rolling_std'] = combined_df.groupby('fault_type')[feature].transform(lambda x: x.rolling(window=window_size).std())
# 故障模式编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
combined_df['fault_type_encoded'] = le.fit_transform(combined_df['fault_type'])
4. 模型选择与训练
我们可以使用分类算法如随机森林、支持向量机(SVM)、XGBoost等。这里我们选择使用XGBoost作为示例。
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
# 准备训练数据
features = [col for col in combined_df.columns if col not in ['time', 'fault_type']]
target = 'fault_type_encoded'
X = combined_df[features]
y = combined_df[target]
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)
model.fit(X_train, y_train)
# 预测并评估模型
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
5. 模型评估与优化
评估模型性能,并尝试调整超参数或引入更多特征来提高模型的表现。
from sklearn.model_selection import GridSearchCV
# 超参数调优
param_grid = {
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 5, 7]
}
grid_search = GridSearchCV(estimator=XGBClassifier(random_state=42), param_grid=param_grid, cv=3, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_model = grid_search.best_estimator_
print("Best parameters found: ", grid_search.best_params_)
6. 测试与推理
在测试集上评估模型表现,并保存最佳模型用于后续的推理任务。
# 使用最佳模型进行预测
final_predictions = best_model.predict(X_test)
# 保存预测结果
pd.DataFrame({'time': combined_df.loc[X_test.index, 'time'], 'predicted_fault_type': final_predictions}).to_csv('predictions.csv', index=False)
7. 部署与监控
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用环境中。这可能涉及到将模型导出为ONNX格式或其他适合部署的格式,以及编写相应的API接口来接收实时数据输入并返回诊断结果。

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









