







Deep Learning
Introduction


Perceptron Optimization (Neural Network)
A Perceptron:
y
=
w
T
x
+
b
y=w^Tx+b
y=wTx+b, Modify weight
w
w
w such that
y
^
\hat{y}
y^ gets ‘closer’ to
y
y
y.

- Deep learning is trying to solve one problem:
min x f ( x ) , y = f ( x ) = w T x + b \min_xf(x),y=f(x)=w^Tx+b xminf(x),y=f(x)=wTx+b - It is a linear regression problem
w = arg min w ∑ i = 1 M 1 2 ( w T x i − y i ) 2 w=\arg\min_w\sum_{i=1}^M\frac{1}{2}(w^Tx_i-y_i)^2 w=argwmini=1∑M21(wTxi−yi)2- Features x i ∈ R n x_i\in\R^n xi∈Rn
- Ground truth y i ∈ R y_i\in\R yi∈R
- Typical
A
x
=
b
Ax=b
Ax=b problem, but we can solve it by Gradient Descent
x ∗ = arg min x F ( x ) , x n + 1 = x n − γ ∇ F ( x n ) x^*=\arg\min_xF(x),x_{n+1}=x_n-\gamma\nabla{F(x_n)} x∗=argxminF(x),xn+1=xn−γ∇F(xn)- γ \gamma γ is the step size
- ∇ F ( x n ) \nabla{F(x_n)} ∇F(xn) is the gradient of F F F at x n x_n xn
Chain Rule
f ( x ) = g ( u ) , u = h ( x ) → f ′ ( x ) = g ′ ( u ) h ′ ( x ) f(x)=g(u),u=h(x)\rightarrow{f'(x)}=g'(u)h'(x) f(x)=g(u),u=h(x)→f′(x)=g′(u)h′(x)
Matrix Calculus

Denominator layout:
∂
y
∂
x
∈
R
1
×
m
,
∂
y
∂
x
=
R
n
\frac{\partial\mathbf{y}}{\partial{x}}\in\R^{1\times{m}},\frac{\partial{y}}{\partial\mathbf{x}}=\R^n
∂x∂y∈R1×m,∂x∂y=Rn
Numerator layout:
∂
y
∂
x
∈
R
m
,
∂
y
∂
x
=
R
1
×
n
\frac{\partial\mathbf{y}}{\partial{x}}\in\R^m,\frac{\partial{y}}{\partial\mathbf{x}}=\R^{1\times{n}}
∂x∂y∈Rm,∂x∂y=R1×n
x
∈
R
n
,
y
∈
R
m
,
X
∈
R
n
×
m
,
Y
∈
R
m
×
n
\mathbf{x}\in\R^n,\mathbf{y}\in\R^m,\mathbf{X}\in\R^{n\times{m}},\mathbf{Y}\in\R^{m\times{n}}
x∈Rn,y∈Rm,X∈Rn×m,Y∈Rm×n
∂
y
∂
x
=
[
∂
y
∂
x
1
∂
y
∂
x
2
⋮
∂
y
∂
x
n
]
,
∂
y
∂
x
=
[
∂
y
1
∂
x
∂
y
2
∂
x
⋯
∂
y
n
∂
x
]
\frac{\partial{y}}{\partial\mathbf{x}}= \left[\begin{array}{c} \frac{\partial{y}}{\partial{x_1}} \\ \frac{\partial{y}}{\partial{x_2}} \\ \vdots \\ \frac{\partial{y}}{\partial{x_n}} \end{array}\right], \frac{\partial\mathbf{y}}{\partial{x}}= \left[\begin{array}{cccc} \frac{\partial{y_1}}{\partial{x}} & \frac{\partial{y_2}}{\partial{x}} & \cdots & \frac{\partial{y_n}}{\partial{x}} \end{array}\right]
∂x∂y=⎣⎢⎢⎢⎢⎡∂x1∂y∂x2∂y⋮∂xn∂y⎦⎥⎥⎥⎥⎤,∂x∂y=[∂x∂y1∂x∂y2⋯∂x∂yn]
∂
y
∂
x
=
[
∂
y
1
∂
x
1
∂
y
2
∂
x
1
⋯
∂
y
m
∂
x
1
∂
y
1
∂
x
2
∂
y
2
∂
x
2
⋯
∂
y
m
∂
x
2
⋮
⋮
⋱
⋮
∂
y
1
∂
x
n
∂
y
2
∂
x
n
⋯
∂
y
m
∂
x
n
]
\frac{\partial\mathbf{y}}{\partial\mathbf{x}}= \left[\begin{array}{cccc} \frac{\partial{y_1}}{\partial{x_1}} & \frac{\partial{y_2}}{\partial{x_1}} & \cdots & \frac{\partial{y_m}}{\partial{x_1}}\\ \frac{\partial{y_1}}{\partial{x_2}} & \frac{\partial{y_2}}{\partial{x_2}} & \cdots & \frac{\partial{y_m}}{\partial{x_2}}\\ \vdots & \vdots & \ddots &\vdots\\ \frac{\partial{y_1}}{\partial{x_n}} & \frac{\partial{y_2}}{\partial{x_n}} & \cdots & \frac{\partial{y_m}}{\partial{x_n}}\\ \end{array}\right]
∂x∂y=⎣⎢⎢⎢⎢⎡∂x1∂y1∂x2∂y1⋮∂xn∂y1∂x1∂y2∂x2∂y2⋮∂xn∂y2⋯⋯⋱⋯∂x1∂ym∂x2∂ym⋮∂xn∂ym⎦⎥⎥⎥⎥⎤
∂
y
∂
X
=
[
∂
y
∂
x
11
∂
y
∂
x
12
⋯
∂
y
∂
x
1
m
∂
y
∂
x
21
∂
y
∂
x
22
⋯
∂
y
∂
x
2
m
⋮
⋮
⋱
⋮
∂
y
∂
x
n
1
∂
y
∂
x
n
2
⋯
∂
y
∂
x
n
m
]
,
∂
Y
∂
x
=
[
∂
y
11
∂
x
∂
y
21
∂
x
⋯
∂
y
m
1
∂
x
∂
y
12
∂
x
∂
y
22
∂
x
⋯
∂
y
m
2
∂
x
⋮
⋮
⋱
⋮
∂
y
1
n
∂
x
∂
y
2
n
∂
x
⋯
∂
y
m
n
∂
x
]
\frac{\partial{y}}{\partial\mathbf{X}}= \left[\begin{array}{cccc} \frac{\partial{y}}{\partial{x_{11}}} & \frac{\partial{y}}{\partial{x_{12}}} & \cdots & \frac{\partial{y}}{\partial{x_{1m}}}\\ \frac{\partial{y}}{\partial{x_{21}}} & \frac{\partial{y}}{\partial{x_{22}}} & \cdots & \frac{\partial{y}}{\partial{x_{2m}}}\\ \vdots & \vdots & \ddots &\vdots\\ \frac{\partial{y}}{\partial{x_{n1}}} & \frac{\partial{y}}{\partial{x_{n2}}} & \cdots & \frac{\partial{y}}{\partial{x_{nm}}}\\ \end{array}\right], \frac{\partial\mathbf{Y}}{\partial{x}}= \left[\begin{array}{cccc} \frac{\partial{y_{11}}}{\partial{x}} &\frac{\partial{y_{21}}}{\partial{x}} & \cdots & \frac{\partial{y_{m1}}}{\partial{x}}\\ \frac{\partial{y_{12}}}{\partial{x}} &\frac{\partial{y_{22}}}{\partial{x}} & \cdots & \frac{\partial{y_{m2}}}{\partial{x}}\\ \vdots & \vdots & \ddots &\vdots\\ \frac{\partial{y_{1n}}}{\partial{x}} &\frac{\partial{y_{2n}}}{\partial{x}} & \cdots & \frac{\partial{y_{mn}}}{\partial{x}}\\ \end{array}\right]
∂X∂y=⎣⎢⎢⎢⎢⎡∂x11∂y∂x21∂y⋮∂xn1∂y∂x12∂y∂x22∂y⋮∂xn2∂y⋯⋯⋱⋯∂x1m∂y∂x2m∂y⋮∂xnm∂y⎦⎥⎥⎥⎥⎤,∂x∂Y=⎣⎢⎢⎢⎡∂x∂y11∂x∂y12⋮∂x∂y1n∂x∂y21∂x∂y22⋮∂x∂y2n⋯⋯⋱⋯∂x∂ym1∂x∂ym2⋮∂x∂ymn⎦⎥⎥⎥⎤

Loss
Regression
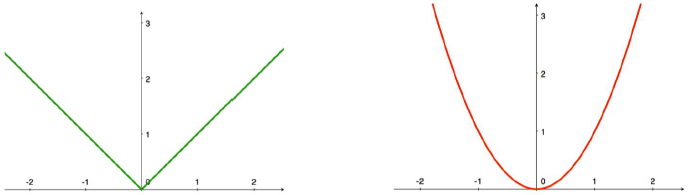
- L1 Loss:
l ( y ^ , y ) = ∣ y ^ − y ∣ l(\hat{y},y)=|\hat{y}-y| l(y^,y)=∣y^−y∣ - L2 Loss:
l ( y ^ , y ) = ( y ^ − y ) 2 l(\hat{y},y)=(\hat{y}-y)^2 l(y^,y)=(y^−y)2
Classification
- Cross Entroypy Loss ( Negative Log Softmax)
H ( p , q ) = − ∑ y i p ( y i ) log q ( y i ) ⇔ L = H ( p , q ) = − log e s i ∗ Σ j e s j , w h e r e p ( y i ∗ ) = 1 ∑ y i p ( y i ) = 1 , ∑ y i q ( y i ) = 1 H(p,q)=-\sum_{y_i}p(y_i)\log{q(y_i)}\Leftrightarrow{L}=H(p,q)=-\log\frac{e^{s_{i^*}}}{\Sigma_je^{s_j}},where\,p(y_{i^*})=1\\ \sum_{y_i}p(y_i)=1,\sum_{y_i}q(y_i)=1 H(p,q)=−yi∑p(yi)logq(yi)⇔L=H(p,q)=−logΣjesjesi∗,wherep(yi∗)=1yi∑p(yi)=1,yi∑q(yi)=1
p ( y i = 1 ) p(y_i=1) p(yi=1) is the ground-truth probability of category i i i
q ( y i = 1 ) q(y_i=1) q(yi=1) is the predicted probability of category i i i
Activation Function (Non-linear)
- Rectified Linear Unit (ReLU):
f ( x ) = { 0 , f o r x ≤ 0 x , f o r x > 0 f(x)= \left\{ \begin{array}{cc} 0,for\,x\le0\\ x,for\,x>0 \end{array} \right. f(x)={0,forx≤0x,forx>0 - Exponential Linear Unit (ELU):
f ( x ) = { α ( e x ) − 1 , f o r x ≤ 0 x , f o r x > 0 f(x)= \left\{ \begin{array}{cc} \alpha(e^x)-1,for\,x\le0\\ x,for\,x>0 \end{array} \right. f(x)={α(ex)−1,forx≤0x,forx>0
Multi-Layer Perceptron (MLP)
- A MLP with activation & ≥ 1 \ge1 ≥1 hidden layers is able to simulate ANY function f ( x ) f(x) f(x) where x x x is the input.
- Back Propagation (Gradient Descent)
- SGD OR Adam (Step Optimizer)
CNN
- Features can be extracted in a local neighborhood.
- VS MLP
- Sparse connection vs. Dense
- Weight sharing vs. Unique weights
- Local invariant vs. Local variant :
- Features should not depend on the location within the image
- Make the same prediction no matter where is the object in the image
- Output length
o
o
o
o = ⌊ n + p − k s ⌋ + 1 o=\left\lfloor\frac{n+p-k}{s}\right\rfloor+1 o=⌊sn+p−k⌋+1- kernel size k k k: unknown/trainable parameters
- Input length n n n: receptive field
- Padding p p p
- Stride s s s: Less compute & Increase receptive field
2D-CNN

Y
i
,
j
=
∑
a
=
0
k
h
−
1
∑
b
=
0
k
w
−
1
X
i
∗
s
h
+
a
,
j
∗
s
w
+
b
×
W
a
,
b
Y_{i,j}=\sum^{k_h-1}_{a=0}\sum^{k_w-1}_{b=0}X_{i*s_h+a,j*s_w+b}\times{W_{a,b}}
Yi,j=a=0∑kh−1b=0∑kw−1Xi∗sh+a,j∗sw+b×Wa,b
- Multiple features
→
\rightarrow
→ Multiple kernels & Inputs
Y l , i , j = ∑ d = 0 c i − 1 ∑ a = 0 k h − 1 ∑ b = 0 k w − 1 X d , i + a , j + b × W l , d , a , b + b l , l ∈ [ 0 , c o ) Y_{l,i,j}=\sum^{c_i-1}_{d=0}\sum^{k_h-1}_{a=0}\sum^{k_w-1}_{b=0}X_{d,i+a,j+b}\times{W_{l,d,a,b}}+b_l,l\in[0,c_o) Yl,i,j=d=0∑ci−1a=0∑kh−1b=0∑kw−1Xd,i+a,j+b×Wl,d,a,b+bl,l∈[0,co) - Parameter size c o × k h × k w c_o\times{k_h}\times{k_w} co×kh×kw
- Output shape ( c o , o h , o w ) = ( c o , ⌊ n h + p h − k h s h ⌋ + 1 , ⌊ n w + p w − k w s w ⌋ + 1 ) (c_o,o_h,o_w)=(c_o,\left\lfloor\frac{n_h+p_h-k_h}{s_h}\right\rfloor+1,\left\lfloor\frac{n_w+p_w-k_w}{s_w}\right\rfloor+1) (co,oh,ow)=(co,⌊shnh+ph−kh⌋+1,⌊swnw+pw−kw⌋+1)
- Computation cost O ( ( c o × k h × k w ) × ( o h × o w ) ) O((c_o\times{k_h}\times{k_w})\times(o_h\times{o_w})) O((co×kh×kw)×(oh×ow))
3D-CNN

- Natural extension of 2D Convolution
- Input: Each small cube contains d d d features/channels
- Kernel: Each small cube contains d d d weights
- Output: Each small cube is a scalar
Pooling (Matrix → \rightarrow →Vector)
- Aggregate information in each receptive field
- Max
- Average
- No trainable parameter
- Same padding/stride method
Deep Learning for Point Cloud

- 3D convolution
- Multi-view projection onto images + 2D convolution
- Simply run 1D/2D convolution or even MLP on point cloud (order)
VoxNet (3D convolution)1

- Content of each grid cell
- Binary
- Number of points
- Probability
- etc. (TSDF or TDF)
- Accuracy on ModelNet40: 83%
- Conv(o, k, s)
- o: number of kernels
- k: size of kernel (same for x/y/z)
- s: stride (same for x/y/z)
MVCNN (Multi-view)2

Point CNN (MLP)

- Activation function:
h W , b ( x ) = f ( W T x ) = f ( ∑ i = 1 3 w i x i + b ) = f ( w 1 x 1 + w 2 x 2 + w 3 x 3 + b ) h_W,b(x)=f(W^Tx)=f(\sum^3_{i=1}w_ix_i+b)=f(w_1x_1+w_2x_2+w_3x_3+b) hW,b(x)=f(WTx)=f(i=1∑3wixi+b)=f(w1x1+w2x2+w3x3+b) - Not Permutation Invariant
f ( w 1 x 3 + w 2 x 1 + w 3 x 2 + b ) ≠ h W , b ( x ) f(w_1x_3+w_2x_1+w_3x_2+b)\ne{h_{W,b}(x)} f(w1x3+w2x1+w3x2+b)=hW,b(x)
PointNet3

- shared MLP + max pool = PN
- T-Net is a PointNet itself
- Process each point (feature) independently n × C 1 → n × C 2 n\times{C_1}\rightarrow{n}\times{C_2} n×C1→n×C2
- Use Max/Average to pool the features
n
×
C
→
1
×
C
n\times{C}\rightarrow{1}\times{C}
n×C→1×C

- Proof – PointNet is able to simulate any function on the point cloud
∣ f ( S ) − γ ( M A X ( h ( x 1 ) , ⋯ , h ( x n ) ) ) ∣ < ϵ |f(S)-\gamma(MAX(h(x_1),\cdots,h(x_n)))|<\epsilon ∣f(S)−γ(MAX(h(x1),⋯,h(xn)))∣<ϵ- ∀ ϵ > 0 , ∃ h : R m → R m ′ , a n d γ : R n → R \forall\epsilon>0,\exists{h}:\R^m\rightarrow\R^{m'},and\gamma:\R^n\rightarrow\R ∀ϵ>0,∃h:Rm→Rm′,andγ:Rn→R, h → h\rightarrow h→ Shared MLP, γ → \gamma\rightarrow γ→ MLP for global feature
- Input points S = { x 1 , . . , x n } , x i ∈ R m , x i ∈ [ 0 , 1 ] S=\{x_1,..,x_n\},x_i\in\R^m,x_i\in[0,1] S={x1,..,xn},xi∈Rm,xi∈[0,1],Denote the space of S S S as χ \chi χ, i.e., S ∈ χ S\in\chi S∈χ
- A continuous function f : χ → R f:\chi\rightarrow\R f:χ→R
- MAX function: takes n n n vectors, give element-wise maximum
- h ( ⋅ ) h(\cdot) h(⋅) maps x i x_i xi to the some deterministic position of a huge vector, By Voxel Grid Downsampling.
- MAX ( h ( x 1 ) , ⋯ , h ( x n ) ) (h(x_1),\cdots,h(x_n)) (h(x1),⋯,h(xn)) simply builds a voxel grid representation, there will be lots of 0 elements because of empty cells in voxel grid.
-
γ
(
⋅
)
=
r
e
c
o
n
s
t
r
u
c
t
t
h
e
p
o
i
n
t
s
+
f
(
⋅
)
\gamma(\cdot)=reconstruct\,the\,points+f(\cdot)
γ(⋅)=reconstructthepoints+f(⋅)


- Critical Points Set & Upper Bound Shape


- Limitations of PointNet
- CNN has multiple, increasing receptive field
- PointNet has one receptive field – all points
Voxel Feature Encoding (VFE)

PointNet++

- In each set abstraction:
- Sampling: FPS
- Point #: N i − 1 → N i N_{i-1}\rightarrow{N_i} Ni−1→Ni
- Grouping:
- Radius Neighbors ( + random sampling)
- K Nearest Neighbors
- PointNet
- Point #: N i N_i Ni
- Channel #: C i − 1 → C i C_{i-1}\rightarrow{C_i} Ci−1→Ci
- Concatenate with coordinates so d + C i − 1 → C i d+C_{i-1}\rightarrow{C_i} d+Ci−1→Ci
- Normalize point coordinate in the group
- Centered with the Node

- Sampling: FPS
- Multi-scale grouping (MSG)
- Multiple Grouping & PointNet
- r = 0.1 r=0.1 r=0.1 grouping + PN
- r = 0.2 r=0.2 r=0.2 grouping + PN
- r = 0.4 r=0.4 r=0.4 grouping + PN
- This is compute intensive
- Concatenate the multi-scale feature vectors

- Multiple Grouping & PointNet
- Multi-resolution grouping (MRG)
- Get features from previous level (previous previous level)
- Still increase compute

- Interpolation
- Upsample the features from previous layer
- x ∈ R 3 x\in\R^3 x∈R3: point coordinates at the upsampled level, # = N 1 N_1 N1
- f ∈ R C 2 f\in\R^{C_2} f∈RC2: interpolated features
- x i ∈ R 3 x_i\in\R^3 xi∈R3: point coordinates at the previous level ( N 2 N_2 N2 points)
- w i ∈ R w_i\in\R wi∈R: reciprocal of distance d ( x , x i ) d(x,x_i) d(x,xi)
-
f
i
∈
R
C
2
f_i\in{R^{C_2}}
fi∈RC2: point features at the previous level
f ( j ) ( x ) = Σ i = 1 k w i ( x ) f i ( j ) Σ i = 1 k w i ( x ) w h e r e w i ( x ) = 1 d ( x , x i ) p , j = 1 , ⋯ , C f^{(j)}(x)=\frac{\Sigma^k_{i=1}w_i(x)f^{(j)}_i}{\Sigma^k_{i=1}w_i(x)}\quad{where}\quad{w_i(x)}=\frac{1}{d(x,x_i)^p},j=1,\cdots,C f(j)(x)=Σi=1kwi(x)Σi=1kwi(x)fi(j)wherewi(x)=d(x,xi)p1,j=1,⋯,C

- Data Augmentation
- Normalization: zero-mean & centered-with-node
- Input Point Dropout (DP)
- Gaussian Noise
- Rotation ( Less overfitting & Worse performance)















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









