










摘要
推荐系统通常面临filter bubbles的问题:基于用户特征和历史交互过度推荐同类项目。过滤气泡会沿着反馈循环增长,并在不经意间缩小用户兴趣。现有的工作通常通过结合除准确性之外的目标(例如多样性和公平性)来减轻过滤器泡沫。但是,它们通常会牺牲准确性,损害模型保真度和用户体验。
更糟糕的是,用户不得不被动地接受推荐策略,并以低效且高延迟的方式影响系统,例如,不断提供反馈(例如,喜欢和不喜欢),直到系统识别出用户意图。
【补充】关于Filter bubbles:就是说,由于模型的推荐是基于过往的交互历史,所以生成的推荐被局限于某几种类别,也叫信息茧房。
这项工作提出了一种新的推荐器原型,称为 User Controllable Recommender System (UCRS),它使用户能够主动控制过滤器气泡的缓解。从功能上讲,
-
UCRS 可以在用户深陷过滤气泡时发出警报。
-
UCRS 支持四种用户控制命令,以缓解不同粒度的气泡。
-
UCRS 可以响应控制并即时调整建议。调整的关键在于阻止过时的用户表示对推荐的影响,其中包含与控制命令不一致的历史信息。因此,我们开发了一个因果增强的用户可控推理(UCI)框架,该框架可以在推理阶段根据用户控制快速修改推荐,并利用反事实推理来减轻过时用户表示的影响。
在三个数据集上的实验验证了 UCI 框架可以有效地根据用户控制推荐更多想要的项目,显示出有希望的性能:准确性和多样性
方法
1. Formulation of UCRS
模型由2个控制器,分别控制项目特征(比如电影类型)和用户特征(性别、年龄组),其中每个控制器分为粗细两个粒度。
首先,文章的符号系统:
D,R: 历史交互记录, 做出的推荐;
传统推荐系统做的事:计算
P
(
R
∣
D
)
P(R|D)
P(R∣D); 这篇文章加上了一些干预
d
o
(
C
)
do(C)
do(C),也就变成了
P
(
R
∣
D
,
d
o
(
C
)
P(R|D, do(C)
P(R∣D,do(C)
接下来以用户特征的控制器为例:
如何表示用户:
x
u
=
[
x
u
1
,
x
u
2
,
…
,
x
u
N
]
,
x
u
i
∈
(
0
,
1
)
x_u=[x_u^1, x_u^2,\dots ,x_u^N],x_u^i\in{(0,1)}
xu=[xu1,xu2,…,xuN],xui∈(0,1)
列出所有特征,比如只有性别这一特征,那么
x
u
1
x_u^1
xu1表示male,
x
u
2
x_u^2
xu2表示female, 那么
x
u
=
[
0
,
1
]
x_u=[0,1]
xu=[0,1]表示一个female user.
细粒度:
P
(
R
∣
D
,
d
o
(
C
)
,
C
=
c
u
(
+
x
^
,
α
)
P(R|D, do(C) ,C=c_u(+\hat x,\alpha)
P(R∣D,do(C),C=cu(+x^,α)
C是一个控制指令,去显示更多“其他组别”喜欢的项目,可以把c_u当作补集,
x
^
\hat x
x^是当前用户
u
u
u没有的特征(
x
u
i
=
0
x_u^i=0
xui=0),比如上述例子的male属性;
α
\alpha
α是调节强度的系数。
粗粒度:
然而,用户可能只是想减轻过滤气泡而不是喜欢其他组别的项目,一些用户可能也不知道哪个用户群有吸引力,所以加入粗粒度的控制器。比如30岁的用户可能不喜欢受到Age=30这个限制条件的推荐,所以这里 C = c u ( − x ‾ , α ) C=c_u(-\overline x,\alpha) C=cu(−x,α), x ‾ u = 1 \overline x_u=1 xu=1,即减少用户自己特征的强度。
项目方面同上
2. Instantiation of UCRS
过滤气泡检测
刚刚提到了过滤气泡,那么自然需要一个机制来检测过滤气泡。文章用了几个指标来判别:
1):覆盖范围。过滤气泡通常会降低推荐项目的多样性,因此我们采用了一个广泛采用的多样性指标:覆盖率,它计算推荐列表中项目类别的数量 。
2):隔离指数。除了基于多样性的指标外,我们还提出了隔离指数来衡量不同用户群体之间的隔离。在这里,我们针对推荐任务对其进行了修改。
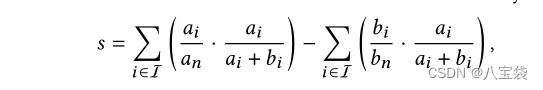
I
I
I: item set;
a
i
,
b
i
a_i,b_i
ai,bi: group
a
,
b
a,b
a,b中受到了item
i
i
i推荐的人数;
a
n
a_n
an:
∑
i
∈
I
a
i
\sum_{i\in I}a_i
∑i∈Iai
3):多数类别支配。隔离指数更适合衡量群体隔离,即用户特征(例如,年龄和性别)。至于过滤气泡,即项目特征,我们可以利用 MCD 获得历史最大项目类别在推荐列表中的比例
生成推荐的因果观点
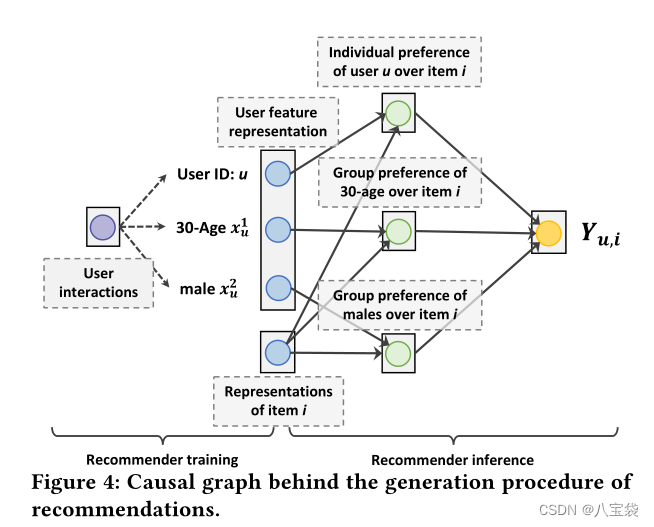
如图所示,我们通过因果图分析推荐的生成过程。具体来说,对于大多数模型(例如 FM ),推荐训练从交互中学习用户表示,包括 ID、年龄和性别的表示。此后,用户和项目 的表示用于预测用户偏好项目的概率。
具体来说,
Y
u
,
i
Y_{u,i}
Yu,i是由个体ID和多个群组特征的偏好得分融合而成,其中群组偏好由对应用户群组中的用户共享。
这里的过程比较复杂,就是说用户的ID表示和组特征的表示存在相关性,因为都是由交互信息而来,那么在进行粗粒度控制时,尽管改变/丢弃了组特征(年龄性别这种),但用户的ID编码里还混杂了有原来的特征兴趣,所以为了消除这个混杂效应(涉及因果的知识吧?),流行的方法是混杂平衡、后门/前门调整。但是由于balabala这三种方法都不可行,所以作者考虑直接减少用户id表示在预测中的影响。
那么该如何减少?假设
u
^
\hat u
u^是没有用户id的表示,这样的预测分为
Y
u
^
,
i
Y_{\hat u, i}
Yu^,i,正常含有用户id的表示(Embeddng)得到的预测分是
Y
u
,
i
Y_{u,i}
Yu,i. 可以把id的影响表示为:
Y
u
,
i
−
Y
u
^
,
i
Y_{u,i}-Y_{\hat u, i}
Yu,i−Yu^,i,因此:

用一个系数
α
\alpha
α控制,减去这个影响。
然后还有关于项目粒度的控制,如何反馈?
Y
u
,
i
′
=
Y
u
,
i
+
β
⋅
r
(
i
)
Y_{u,i}^{\prime} = Y_{u,i}+\beta \cdot r(i)
Yu,i′=Yu,i+β⋅r(i)
β
\beta
β是控制强度的系数,r(i)是:

可以看到r是个常数,相当于扩大\归零beta的大小,取决于用户是否想要更多的推荐种类。
预测
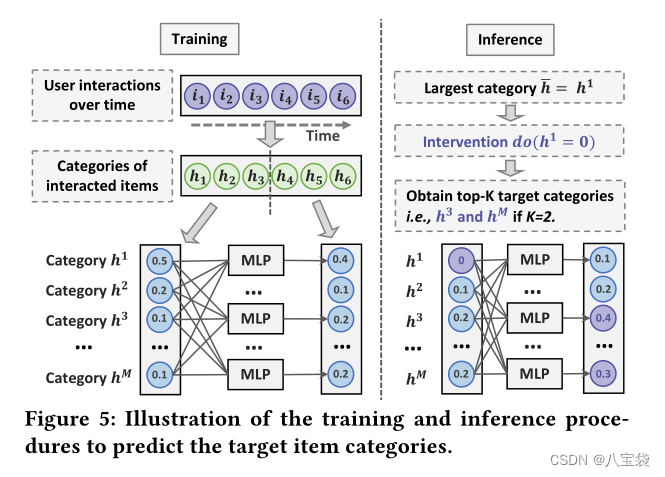
先按用户交互时间排序,然后分为两部分,这两部分分别有各自的属性分布,可以理解为前半部分和后半部分,分别是近期/以前的偏好,然后在这两个分布直接加一层MLP,目的有2个:第一,捕获临时兴趣;第二,捕获特征间的关系。















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









