










CFFNN: Cross Feature Fusion Neural Network for Collaborative Filtering
摘要
方法
1. 符号系统
U , I , Y ∈ R M × N U, I,Y\in R^{M\times N} U,I,Y∈RM×N:用户、项目、交互集合,M和N分别是用户、项目的总数.
2. 输入层
把One-hot向量化的层,很少有把这一步写出来的,用了P, Q两个投影矩阵,结果是 e u , e i e_u,e_i eu,ei. 分别代表用户、项目。
3. 特征提取层
这一层真是有点…
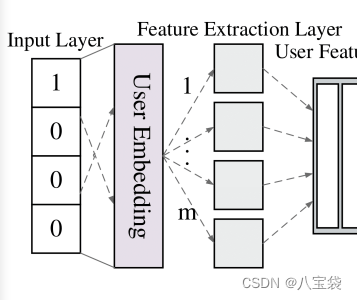
如图所示,在Embedding层后,有m个小方块,每一个小方块其实都是一个单层全连接的输出,然后Concat把m个输出拼起来,得到这一层的输出
F
u
F_u
Fu, 类似地,项目方面得到
F
i
F_i
Fi.
关于为什么不用deep网络结构而是用wide结构,作者的解释是:首先,DNN容易过拟合,难传播梯度;其次,不同数量的MLP可以捕捉不同的特征,可以提高模型性能【对这点存疑,因为毕竟是黑盒,单纯地横向拼接缺乏可解释性】。
MLP的优点:上述结构在CV中很常用,但是难点是选择合适的核尺寸,但是MLP就没有核函数的存在,所以可以用不同数量的MLP来替换核函数。
4.特征融合层
这里我觉得原文写得很乱,很不清晰,缺少一些必要说明,整个过程就如图所示吧
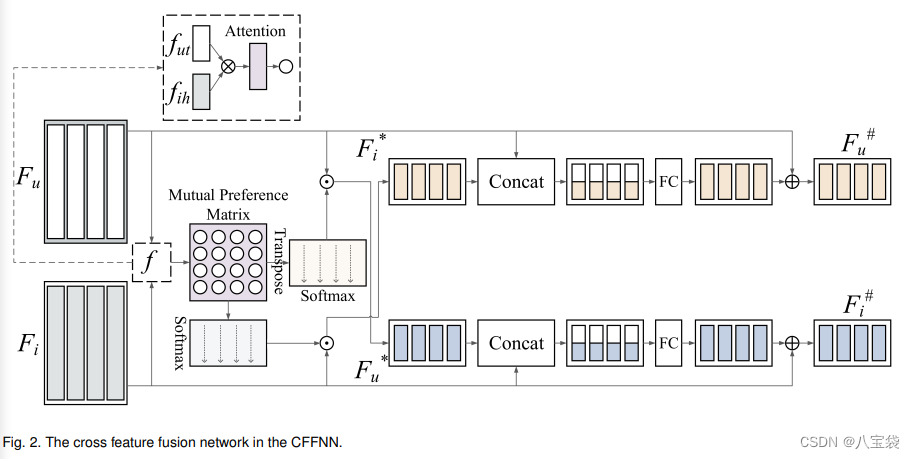
可以看到,有对矩阵横向、竖向的注意力机制、有一堆softmax,然后拼接、全连接,中间夹杂点积、对应位置相乘balabala
最后得到的是
F
i
#
,
F
u
#
F^\#_i,F^\#_u
Fi#,Fu#分别代表项目用户
5.预测层
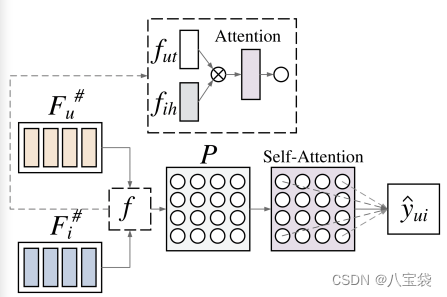
和上面差不多,注意力机制得到权重,再继续注意力

最后得到预测值
后续
后面不看了,才疏学浅,这种过于复杂的模型结构,对自己的工作没有什么启发。这篇文章的主要贡献好像是提出这种项目/用户间特征的fusion.















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









