







 本文详细综述了多视角表征学习,包括对齐和融合两种策略。对齐方法通过特征对齐捕捉不同视角间的关系,如基于距离、相似性和相关性的对齐。融合方法则结合各视角的特征为统一表示。文章讨论了典型相关分析、深度学习的应用,以及在处理多视角数据的挑战。此外,文中还分析了多视角表征学习在图像+文本、音频+视频等场景的应用,为该领域的研究提供了综合指导。
本文详细综述了多视角表征学习,包括对齐和融合两种策略。对齐方法通过特征对齐捕捉不同视角间的关系,如基于距离、相似性和相关性的对齐。融合方法则结合各视角的特征为统一表示。文章讨论了典型相关分析、深度学习的应用,以及在处理多视角数据的挑战。此外,文中还分析了多视角表征学习在图像+文本、音频+视频等场景的应用,为该领域的研究提供了综合指导。
文章目录
0 概述
0.1 题目
多视角表征学习综述 (A survey of multi-view representation learning)
0.2 背景
近年来,多视角表征学习已成为机器学习和数据挖掘领域的冉冉新星。
0.3 目标
介绍两种类型的多视角表征学习:
1)多视角表征对齐 (multi-view representation alignment);
2)多视角表征融合 (multi-view representation fusion)。
0.4 要点
1)回顾多视角表征对齐方法中的代表性方法及相关理论,例如基于相关性的方法,包括典型相关分析 (canonical correlation analysis, CCA)及其扩展;
2)研究多视角表征融合的进展,例如从传统方法 (包括多模态主题学习、多视图稀疏编码和多视图潜在空间马尔可夫网络) 到基于神经网络的方法 (包括多模态自动编码器、多视图卷积神经网络和多模态循环神经网络);
3)研究多视角表征学习的几个重要应用。
0.5 Bib
@article{Li:2018:18631883,
author = {Ying Ming Li and Ming Yang and Zhong Fei Zhang},
title = {A survey of multi-view representation learning},
journal = {{IEEE} Transactions on Knowledge and Data Engineering},
year = {2018},
pages = {1863--1883},
volume = {31},
number = {10}
}
1 引入
1.1 应用场景
多视角表征学习立足于多视角数据,习得其包含有用信息的表征,并用于训练预测模型。多视角数据可以对应于很多现实应用,如图1,其处理对象被描述为基础信息下的多模型度量,例如图像+文本、音频+视频、音频+发音、语言的不同文本;或同一数据来源下的综合视角,单词+上下文、时间序列+时间戳、网页文本+超链接。通常而言,不同视角下的数据包含互补信息,这使得相较于单视角,多视角表征学习可以习得更多的知识。由于机器学习方法的性能高度依赖于数据表征的表达能力,多视角表征学习还是很吃香滴。

1.2 典型相关分析
典型相关分析 (canonical correlation analysis, CCA) 及其核扩展是多视角表征学习的早期研究,随后大量的变体产生并用于特定的任务上的性能提升。然而,尽管CCA在两个或更多的变量之间的关系上建模有奇效,它在捕捉多视角数据上的高级别关联还是不太行的。对此,受到深度神经网络的熏陶,深度CCA被提出来解决这个问题,其首先在较低层习得多个特定视图的表征,再在较高层学习出这个表征的耦合表示。但但但但是,在多视角数据之间习得好的关联还是保留了一些开放问题。2016 年,多视图表征学习研讨会与第 33 届机器学习国际会议一起举办,以进更好地理解杂七杂八的方法和特定应用中的挑战。后续则开展了更多的研究,诸如传统方法和基于网络的方法,如要点所说。
1.3 方法类型
基于广泛的研究分析,我们将多视角表征学习分为两类:
1)多视角表征对齐 (multi-view representation alignment):通过特征对齐来捕捉不同视角间的关系;
2)多视角表征融合 (multi-view representation fusion):融合不同视角下习得的单独特征为统一融合表征。
两个策略的共同之处都是探索多个视角间的互补信息以全面表示数据。
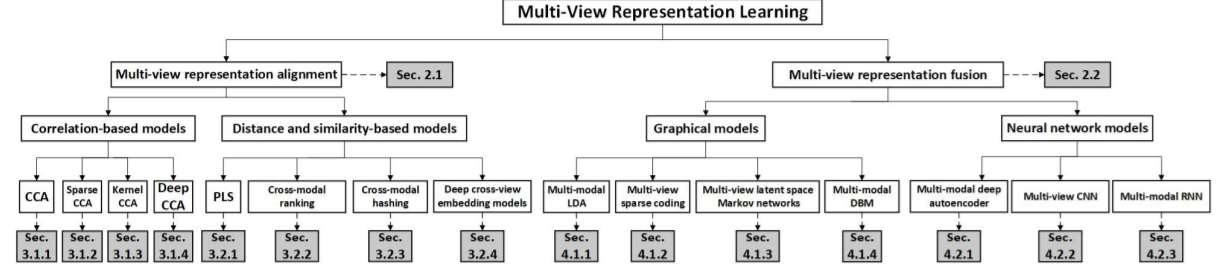
因此,我们回顾了多视角表征学习的几个类别,如图2:
1)多视角表征对齐:包括距离方法、相似性方法、相关性方法,其基本思想是使用映射函数处理每个视图的数据,然后将学习到的单独表征用一定的约束进行正则化,以形成多视图对齐空间;
2)多视角表征融合:分为概率图形和神经网络两种,它们的根本区别则在于学习模型的分层架构是被解释为概率图模型还是计算网络。
1.4 本文目标
回顾多视角表征学习的关键理论和突出特征,以提供该领域下的综合知识、指导特定领域的研究并启发未来的研究。
1.5 与其他综述的主要区别
1)本文着重于多视角表征学习,而非以往的多视角学习的全面介绍;
2)提供了关于传统到神经网络表征学习的更综合的分析;
3)已有的多视角学习综述有以下两种:
a)分为协同训练、多核学习、子空间学习并介绍;
b)回顾CCA、协同训练、泛化误差分析。
我们则基于对多视角表征学习的理解将其分为对齐与融合两种方式。
特别地,协同训练侧重于多视图的决策级别融合,其在每个视图上训练单独的学习器,并迫使学习器的决策在相同的验证样本上相似。
由于本综述主要集中在特征级多视图学习,因此没有研究协同训练相关的算法。
1.6 挑战
挑战多了去了,例如:
1)带噪声或缺失值的低质量数据;
2)多视角嵌入建模的对象不合适;
3)不同视角间的意见分歧。
不过有人已经去做这个了

他们主要处理以下问题:
1)什么样的对象适合多视角表征学习?
2)什么样的深度学习框架适合?
3)具有结构化输入或输出时嵌入函数咋个搞?
4)不同类型的多视角表征学习有嘛联系?
对这些问题的解答很依赖于当前任务和多视角数据所包含的信息,因此有必要和已有的方法深入交流一下。所以捏,我们来给大家多视角学习中的一些干货,方便在对应任务时选取合适的模型。
2 好好摆一下多视角表征学习的分类
多视角表征学习通过关联数据的多个视角来学习其相应表征,以提升模型性能。然而,如果学习到的表征与多视角数据的统计特征不符,则可能适得其反。以演讲识别中的音频即视觉信息为例,困难在于难以将将原始像素与音频波形联系,而两个视图的数据在中级表示之间具有相关性,例如音素和视位。本研究专注于中级表征的多视图联合学习 (multi-view joint learning of mid-level representations),其引入一个嵌入来对特定视图进行建模,然后联合优化所有嵌入以利用多个视图的信息。通过仔细研究已有多视角表征学习,我们将其分为两类,如图3。

2.1 多视角表征对齐
假设已有给定数据的两个视角
X
X
X和
Y
Y
Y,多视角表征对齐被表示为:
f
(
x
;
W
f
)
↔
f
(
y
;
W
g
)
(1)
\tag{1} f(x; W_f)\leftrightarrow f(y;W_g)
f(x;Wf)↔f(y;Wg)(1)其中每个视角都有相应的嵌入函数
f
f
f或者
g
g
g用于将其在特定约束下从原始空间转换到多视角对齐空间、
↔
\leftrightarrow
↔表示对齐操作。
2.1.1 基于距离对齐
第
i
i
i对表征
x
i
x_i
xi和
y
i
y_i
yi的距离对齐被制定为:
m
i
n
θ
∥
f
(
x
i
;
W
f
)
−
f
(
y
i
;
W
g
)
∥
2
2
(2)
\tag{2} min_\theta\|f(x_i; W_f)-f(y_i;W_g)\|_2^2
minθ∥f(xi;Wf)−f(yi;Wg)∥22(2) 一些兄台加了对齐约束,做了不少研究,比如跨模式因子分析 (cross-modal factor analysis, CFA),他想找到能够最小化下式的正交变换矩阵
W
x
W_x
Wx和
W
y
W_y
Wy:
min
W
x
,
W
y
∥
x
i
T
W
x
−
y
i
T
W
y
∥
2
2
+
r
x
(
W
x
)
+
r
y
(
W
y
)
(3)
\tag{3} \min_{W_x,W_y} \|x_i^\text{T}W_x-y_i^\text{T}W_y\|_2^2+r_x(W_x)+r_y(W_y)
Wx,Wymin∥xiTWx−yiTWy∥22+rx(Wx)+ry(Wy)(3) 其中
r
x
(
⋅
)
r_x(\cdot)
rx(⋅)和
r
y
(
⋅
)
r_y(\cdot)
ry(⋅)表示正则项。
此外,基于距离的对齐方法还用在多视角深度表示学习上。例如通信自动编码器 (correspondence autoen-code) 在选择的编码层中加入距离约束,以此建立两个表征之间的通信,其任意输入对上的损失函数定义为:
L
=
λ
x
∥
x
i
−
x
^
i
∥
2
2
+
λ
y
∥
y
i
−
y
^
i
∥
2
2
+
∥
f
c
(
x
i
;
W
f
)
−
g
c
(
y
i
;
W
g
)
∥
2
2
(4)
\tag{4} L=\lambda_x\|x_i-\hat{x}_i\|_2^2+\lambda_y\|y_i-\hat{y}_i\|_2^2+\|f^c(x_i;W_f)-g^c(y_i;W_g)\|_2^2
L=λx∥xi−x^i∥22+λy∥yi−y^i∥22+∥fc(xi;Wf)−gc(yi;Wg)∥22(4)其中
g
c
(
x
i
;
W
f
)
g^c(x_i;W_f)
gc(xi;Wf)和
g
c
(
y
i
;
W
g
)
g^c(y_i;W_g)
gc(yi;Wg)表示相应编码层。
2.1.2 基于相似性对齐
这是一个用于习得对齐空间的流行方式。例如深度视觉语义嵌入模型 (deep visual-semantic embedding model)希冀视觉嵌入输出和正确标签表征之间的点积相似度高于视觉输出和其他随机选择的文本概念之间的相似性:
∑
j
≠
l
max
(
0
,
m
−
S
(
t
l
,
v
i
m
g
)
+
S
(
t
j
,
v
i
m
g
)
)
(5)
\tag{5} \sum_{j\neq l}\max(0, m-S(t_l,v_{img})+S(t_j,v_{img}))
j=l∑max(0,m−S(tl,vimg)+S(tj,vimg))(5)其中
v
i
m
g
v_{img}
vimg表示图像的深度嵌入向量、
t
l
t_l
tl是文本标签的嵌入向量、
t
j
t_j
tj是其他文本的嵌入向量、
S
(
⋅
)
S(\cdot)
S(⋅)是两个向量之间的相似性度量。
2.1.3 基于相关性对齐

















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









