








Learning Anomalies with Normality Prior for Unsupervised Video Anomaly Detection 论文阅读
文章信息:

发表于:ECCV 2024
原文链接:https://link.springer.com/chapter/10.1007/978-3-031-72658-3_10
源码:https://github.com/shyern/LANP-UVAD
Abstract.
无监督视频异常检测(UVAD)旨在在没有任何注释的情况下检测视频中的异常事件。由于异常事件稀少、多样且通常定义不明确,这一任务仍然具有挑战性。现有的UVAD方法纯粹依赖数据驱动,通过识别视频中的各种异常模式进行无监督学习。由于这些方法主要依赖特征表示和数据分布,因此只能学习与正常事件显著不同的突出异常,而忽略那些不太明显的异常。为了解决这个问题,本文采用了一种不同的方法,利用与数据无关的先验知识来处理UVAD中的正常和异常事件。我们首先提出了一种新的正常性先验,建议视频的开始和结束部分主要是正常的。然后,我们提出了正常性传播方法,通过视频片段之间的关系传播正常知识,以估计未标记片段的正常幅度。最后,基于传播的标签和一种新的损失加权方法进行无监督的异常检测学习。这些组件与正常性传播相辅相成,减轻了错误传播标签的负面影响。在ShanghaiTech和UCF-Crime基准上的大量实验表明,我们的方法具有优越的性能。代码可在 https://github.com/shyern/LANP-UVAD.git 获取。
1 Introduction
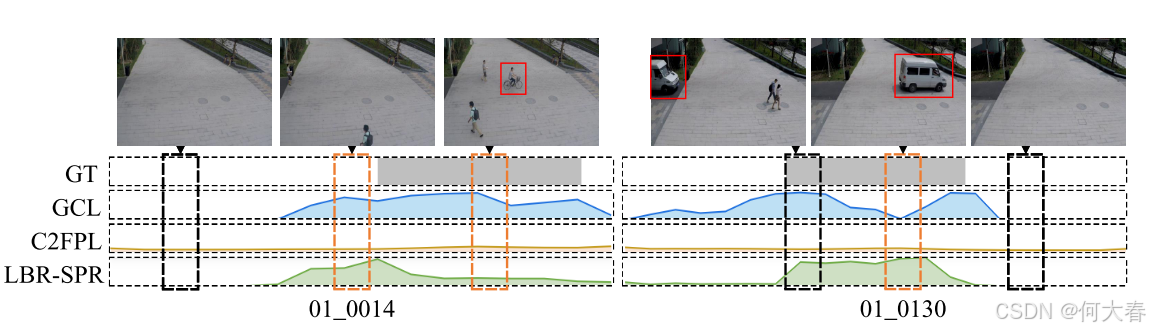
上海科技大学数据集上的两个异常视频示例 [20]。灰色条形码为真实标签。折线图是三种方法 [1, 46, 47] 的异常评分。这些橙色框中的实例很容易被错误预测。这是因为这些方法是数据驱动的,高度依赖特征表示和数据分布,往往难以捕捉到不太明显的异常。
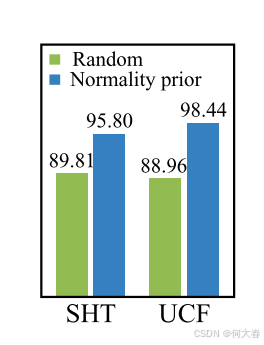
图2:由正常性先验和随机选择的正常片段的准确性。
视频异常检测旨在沿时间维度检测视频序列中的异常事件。这一任务对于智能监控 [55] 和犯罪检测 [5] 至关重要。大多数现有方法在部分监督下进行训练,需要手动注释。例如,一类方法 [23,40,41] 使用正常视频作为训练集,而弱监督方法 [5, 33, 36] 则依赖于训练过程中的视频级注释。相比之下,无监督视频异常检测(UVAD)方法 [28,37,46,47] 试图在没有任何注释的情况下检测异常。然而,这一任务仍然具有挑战性,因为UVAD中的异常事件稀少、多样且通常定义不明确。
现有的无监督视频异常检测(UVAD)方法 [1, 28, 35, 37, 38, 46, 47] 主要基于自我训练或重建。重建方法 [37, 38, 46] 通过逐步过滤出具有大重建误差的异常,从所有训练视频中学习正常模式。自我训练方法 [1, 27, 35, 47] 首先生成伪标签,然后将这些标签用作训练的监督,近期在性能上取得了最佳结果。
当前所有的无监督视频异常检测(UVAD)方法都是纯粹的数据驱动,通过识别视频中的异常模式进行无监督学习。然而,这些方法在很大程度上依赖特征表示和数据分布,往往难以捕捉到不太明显的异常。在重建方法 [37, 38, 46] 中,正常模式和异常模式很容易被自编码器记住,因此不易察觉的异常事件可能被轻易忽视。自我训练方法使用数据驱动策略生成伪标签。例如,GCL基于视频片段中的局部对比度识别异常,它们侧重于高对比度异常,这可能导致异常减弱的问题,即忽视低对比度的不太明显的异常。Al等人 [1] 通过对整个数据集进行聚类来区分正常和异常,这使得在没有预定义正常事件的情况下很难区分它们。这个挑战在图1中得到了说明,展示了之前代表性方法的结果。我们可以看到,不同方法的结果差异显著,且很容易漏掉不太明显的异常。
从本质上讲,无监督视频异常检测(UVAD)是高度不适定的。社区中仍然缺乏“异常是什么”的共同定义,单纯依赖数据来检测异常容易导致失败。我们从不同的角度解决这个问题。与以往数据驱动的方法不同,我们的思路是利用与数据无关的关于正常和异常事件的先验知识来辅助识别异常。通过在数据之外刻画正常和异常事件的特征,这种先验知识有助于解决那些无法通过纯数据驱动的方法来明确的正常和异常事件之间的模糊性,从而实现更有效的异常检测。
什么是无监督视频异常检测(UVAD)的良好先验知识?它应该既具有信息量,又具备高质量。我们受到显著性检测领域的启发 [7, 16, 17, 45]。具体而言,受到传统显著性检测方法中常用的边界先验 [7, 45] 的启发,我们引入了一种正常性先验,即视频的开始和结束部分大多是正常的。这种先验比中心先验 [14, 19] 对于异常更具鲁棒性,因为异常事件可以远离时间中心,但很少接触时间边界。我们在多个数据集上验证了正常性先验,如图2所示,结果表明,与随机选择相比,使用我们的正常性先验选择正常片段的准确性显著更高。更详细的实验讨论见第4.3节。
主要贡献概述如下:
- 与以往纯粹数据驱动的无监督视频异常检测(UVAD)方法不同,我们提出利用与数据无关的正常性先验来识别异常事件。据我们所知,这种先验在UVAD领域尚未被研究。
- 我们引入正常性传播,以有效地将正常性先验传播到未标记片段,从而生成伪标签。
- 我们基于传播的标签和一种新的损失加权方法进行无监督异常检测学习。这些方法与正常性传播相辅相成,减轻了错误传播标签的负面影响。
- 在ShanghaiTech [20] 和 UCF-Crime [33] 数据集上的大量实验表明了所提方法的有效性。
2 Related Work
关于视频异常检测(VAD)的文献非常丰富。我们主要将讨论限制在无监督视频异常检测、标签传播、自我训练和伪标签生成的方法上。
2.1 Unsupervised Video Anomaly Detection
视频异常检测(VAD)旨在检测视频序列中的异常事件。全监督方法 [18, 39] 通过精确的注释来解决这一任务。大多数现有方法在部分监督下进行训练,需要手动注释。例如,一类方法 [6, 9, 20, 22, 23, 29, 34, 40, 41, 54] 仅使用正常视频来训练检测模型,而弱监督方法 [5, 24, 25, 31–33, 36, 42, 49, 51, 55] 在训练过程中需要视频级注释。相比之下,无监督方法 [28, 37, 38, 46, 47] 尝试在没有任何手动注释的情况下检测异常,而手动注释往往劳动密集、成本高昂且易受大幅变化的影响。由于无监督视频异常检测(UVAD)中的异常事件稀少、多样且通常定义不明确,这一任务仍然具有挑战性。在当前的研究中,我们探索了无监督模式的视频异常检测。
现有的无监督视频异常检测(UVAD)方法 [28, 37, 38, 46, 47] 可以分为基于重建的方法和基于自我训练的方法。这些方法都是纯粹的数据驱动,通过识别视频中的异常模式进行无监督学习。重建方法 [37, 38, 46] 从所有训练视频中学习正常模式,通过逐步过滤出具有大重建误差的异常事件。例如,Yu等人 [46] 设计了一种新颖的自适应精细化方案,以利用重建模型去除异常。Tur等人 [37] 利用扩散模型的重建能力来检测具有较大重建误差的异常。他们 [38] 进一步采用条件扩散模型,以提高基于紧凑运动表示的检测性能。然而,由于正常模式和异常模式很容易被自编码器记住,因此它们很容易忽视不易察觉的异常事件。
基于自我训练的方法 [1, 35, 47] 最近取得了良好的性能。它们首先生成伪标签,然后使用这些伪标签作为自我监督。伪标签的生成依赖于数据驱动的策略。例如,Zaheer [47] 提出了一种生成式协作学习方法。该方法基于视频片段之间的局部对比(即连续片段之间的差异)来识别异常。它们可能较好地标记异常事件的边界,但可能会忽视内部异常。Al等人 [1] 在整个数据集上进行聚类,以检测属于较小聚类的异常。正常视频和异常视频可能出现在同一场景中,但在没有预定义正常的情况下,很难将它们分开。Thakare等人 [35] 使用 OneClassSVM 和 iForest 来寻找位于构建的超球体外的异常。然而,之前的 UVAD 方法都是数据驱动的,主要依赖特征表示和数据分布,因此容易忽视不太显著的异常。我们的想法是利用与数据无关的正常事件的先验知识来帮助识别异常。
2.2 Label propagation
标签传播的变体 [56] 已应用于各种计算机视觉任务,包括处理噪声标签的学习 [11, 26]、少样本学习 [3, 21, 30] 和半监督学习 [10, 57]。方法 [11] 针对噪声标签学习提出了一种邻居一致性正则化损失,鼓励具有相似特征表示的样本产生相似的预测。多目标插值训练(MOIT) [26] 通过邻居的预测来识别和优化噪声样本。Liu等人 [21] 在情景少样本学习中考虑了使用随机梯度下降的标签传播。对于半监督学习,Iscen等人 [10] 使用标签传播根据特征空间中的邻居为无监督数据获取标签。标签传播无法直接应用于无监督视频异常检测(UVAD),因为初始标签和相似性矩阵都是不可用的。我们提出正常性传播来解决这些挑战。一方面,我们提出与数据无关的正常性先验,以指定初始标签;另一方面,我们设计了一个时间调制的相似性矩阵,以有效地在视频中传播正常性先验。
2.3 Self-training and Pseudo labeling
自我训练是一种简单但有效的技术,广泛应用于无监督学习 [12, 13, 52, 53]、半监督学习 [10, 43] 和弱监督视频异常检测 [5, 55]。它首先初始化伪标签,然后使用模型预测的标签作为自我监督。Zhang等人 [52] 首先使用基于对比的显著性检测方法 [4, 44] 生成显著性伪标签,然后设计了一个噪声建模模块来处理显著性线索中的噪声。无监督的人体重识别方法 [53] 根据聚类结果生成伪标签,然后通过训练周期和时间集成技术对伪标签进行优化。Lee等人 [10] 使用当前网络推断无标签数据的伪标签,然后在标记和无标签数据上重新训练模型。Zhong等人 [55] 为弱监督的 VAD 提出了一个交替训练框架,根据动作分类器 [2] 为异常视频生成帧级伪标签。在本研究中,我们将自我训练作为 UVAD 的一种方法。我们的方法与之前的工作不同,提出了正常性先验,并引入正常性传播,有效地将正常性先验传播到无标签片段以生成伪标签。我们还引入了一种损失重加权策略,以增强异常检测的稳健性。
3 Method
Problem Statement.在无监督视频异常检测(UVAD)中,训练集中包含正常和异常视频,但未提供注释。假设我们有一组 N 个训练视频,每个视频被分割成一系列不重叠的片段。UVAD 的目标是学习一个片段级异常分类器 f θ ( ⋅ ) f_\theta(·) fθ(⋅),该分类器预测片段的异常评分。评分越高,表示该片段更可能是异常的。
Overview.由于之前的方法完全依赖于数据驱动,因此它们在特征表示和数据分布上存在很大依赖,通常难以捕捉到不太明显的异常。为了解决这一挑战,我们的关键思路是利用与数据无关的关于正常和异常事件的先验知识来帮助识别视频中的异常。通过描述正常和异常事件在数据之外的特征,这种先验知识有助于解决纯数据驱动的方法无法解决的正常和异常事件之间的模糊性,从而实现更有效的异常检测。图 3 展示了我们方法的概述。我们首先描述自然视频中的正常性先验,并用它来指定视频中的正常片段。然后,我们提出了正常性传播,根据时间调制的特征相似度矩阵传播正常知识,以估计无标签片段的正常程度。在传播之后,基于传播的标签和新的重加权方法进行无监督的异常检测学习。
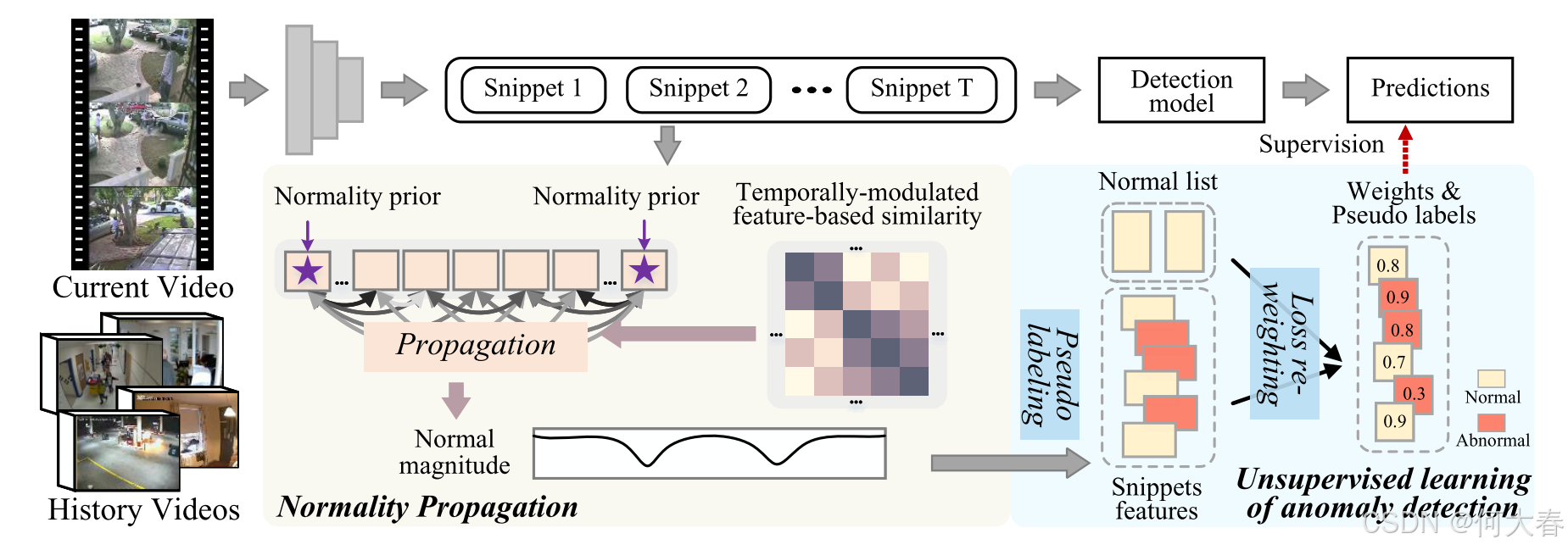
图 3:我们方法的概述。我们首先利用正常性先验来指定视频的开始和结束是正常的。然后,我们提出了一种新的正常性传播方法,基于时间调制的特征相似度传播正常信息,以估计正常程度。在此之后,我们基于传播的标签和新的损失重加权方法进行无监督的异常检测学习。
Feature Extraction.参考文献 [33, 47],我们使用固定权重的骨干网络为每个片段提取特征。形式上,我们将视频中的特征表示为 X ∈ R D × L X \in \mathbb{R}^{D \times L} X∈RD×L,其中 L L L是视频片段的数量, D D D是特征维度。
3.1 Normality Prior in Our Method
我们提出使用关于自然视频中正常事件的先验知识,即正常性先验。这样的先验在之前的方法中从未被研究过,但它可以帮助解决纯数据驱动方法所面临的挑战。
我们的正常性先验是视频的开始和结束大多数情况下是正常的。这一想法受到了传统显著性检测方法中广泛使用的边界先验 [7,16,17,45] 的启发:图像边界大多数是背景。与中心先验 [14,19] 相比,边界先验在识别异常时更具普遍性,因为异常事件可能位于时间中心远处,但很少触及时间边界。该先验在多个异常检测数据集上得到了验证,具体的统计分析见图 2,实验讨论见第 4.3 节。
3.2 Normality Propagation
正常性传播旨在有效地将正常性先验传播到未标记的片段,以生成伪标签。给定具有 L L L 个片段的一个视频的特征 X \mathbf{X} X,我们基于成对相似性在视频片段之间传播正常知识,以估计它们的正常程度 z \mathbf{z} z,这代表它们接收到的正常程度。
由于正常视频只包含正常片段,我们仅将视频的首尾片段指定为正常,而不标记任何异常片段。我们首先定义一个标签向量 y ∈ R L \mathbf{y} \in \mathbb{R}^L y∈RL,其中 y i = 1 y_i=1 yi=1 当 i = 1 i=1 i=1 或 i = L i=L i=L,否则 y i = 0 y_i=0 yi=0。显然, y \mathbf{y} y与视频片段的初始正常幅度是一致的。
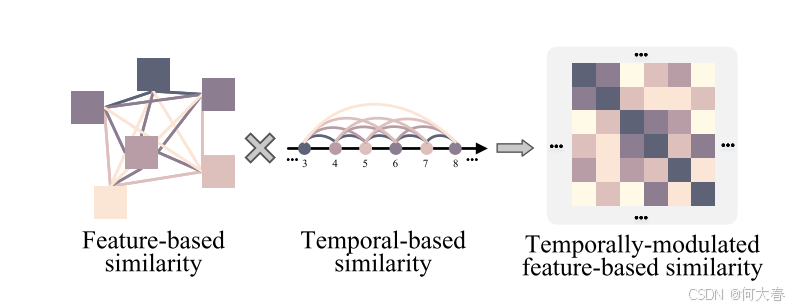
图4:时间调制的基于特征的相似性。
考虑到正常和异常事件在时间上是一致的,并且它们彼此相似,但它们之间的帧变化很大,我们提出了一种基于时间调制的特征相似性矩阵来建模成对的相似性,如图4所示。我们定义一个矩阵 W ∈ R L × L \mathbf{W} \in \mathbb{R}^{L \times L} W∈RL×L 来描述特征空间和时间域中片段的接近程度。我们通过计算片段的特征空间相似性,然后根据它们各自的时间位置进行调制,来构建 W \mathbf{W} W。具体而言,我们定义在特征空间中计算的相似性矩阵 W f \mathbf{W}^f Wf 如下:
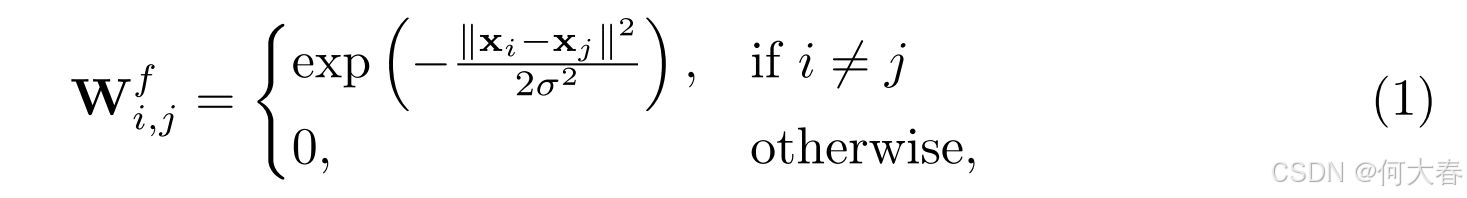
其中 x i \mathbf{x}_i xi 表示视频中第 i i i个片段的特征, σ = 0.1 \sigma=0.1 σ=0.1是一个超参数,用于控制相似性的强度。在时间空间中定义一个类似的矩阵 W t \mathbf{W}^t Wt,其元素根据时间戳计算。对于 L L L个片段,时间戳定义为 t = { 1 , 2 , ⋯ , L } \mathbf{t}=\{1,2,\cdots,L\} t={1,2,⋯,L},并且 W t \mathbf{W}^t Wt 中的每个元素计算如下:
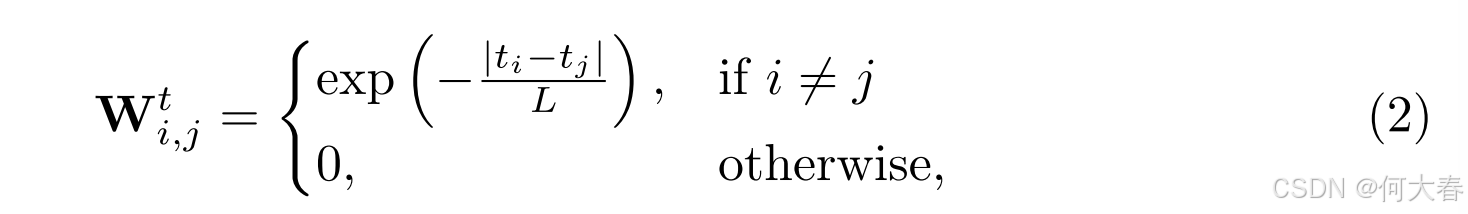
其中 t i t_i ti 表示视频中第 i i i 个片段的时间戳。然后,我们计算时间调制的特征相似性矩阵 W \mathbf{W} W 如下:
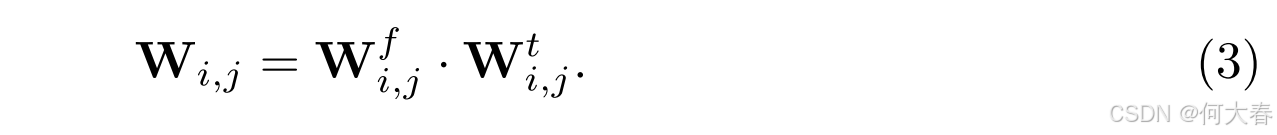
W i , j \mathbf{W}_{i,j} Wi,j 因此指定了片段 i i i 和 j j j 之间的时间加权相似性。它的对称归一化对应矩阵为 S = D − 1 / 2 W D − 1 / 2 \mathbf{S} = \mathbf{D}^{-1/2} \mathbf{W} \mathbf{D}^{-1/2} S=D−1/2WD−1/2,其中 D \mathbf{D} D 是一个对角矩阵,其 ( i , i ) (i, i) (i,i) 元素等于 W \mathbf{W} W 第 i i i 行的和。
正常性传播的目的是让每个片段迭代地将其正常知识传播给其邻居,直到达到全局稳定状态,即迭代
z
(
n
+
1
)
=
α
S
z
(
n
)
+
(
1
−
α
)
y
\mathbf{z}(n+1) = \alpha \mathbf{Sz}(n) + (1 - \alpha) \mathbf{y}
z(n+1)=αSz(n)+(1−α)y 直至收敛,其中
α
\alpha
α是一个在
(
0
,
1
)
(0, 1)
(0,1) 范围内的超参数,
n
n
n 是迭代的索引,而
z
(
0
)
=
y
\mathbf{z}(0) = \mathbf{y}
z(0)=y。该迭代过程收敛到一个简单的解:
z
∗
=
(
1
−
α
)
(
I
−
α
S
)
−
1
y
\mathbf{z}^* = (1 - \alpha)(\mathbf{I} - \alpha \mathbf{S})^{-1} \mathbf{y}
z∗=(1−α)(I−αS)−1y,这显然等价于:

其中 I \mathbf{I} I 是单位矩阵。 z ∗ \mathbf{z}^* z∗ 可以通过使用共轭梯度法高效地获得,从线性系统 ( I − α S ) z ∗ = y (\mathbf{I} - \alpha \mathbf{S}) \mathbf{z}^* = \mathbf{y} (I−αS)z∗=y 中进行求解。推导详见补充材料。
有趣的是,向量
z
∗
\mathbf{z}^*
z∗ 如公式 (4) 所定义,相当于以下目标函数的解:
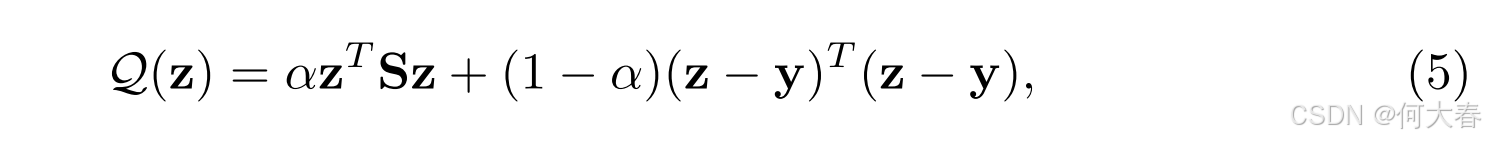
第一个项鼓励相似的片段获得相同的预测,而第二个项则尝试保持对指定正常样本的预测[56]。
视频中片段的优化正常程度 z ∗ \mathbf{z}^* z∗ 表示它们从正常性先验和邻居那里接收到的正常知识的不同程度。较高的值意味着该片段更可能是正常的,反之亦然。
Discussion.正常性先验有效地指定了正常片段。通过表征正常事件超越数据的样子,这种先验知识有助于解决重建基础方法 [37, 38, 46] 和基于全局聚类的方法 [1] 无法解决的正常与异常事件之间的模糊性。此外,正常性传播以比直接将视频片段与正常先验进行比较更有效的方式利用了正常性先验。它不仅基于标记的正常片段估计每个片段的正常程度,还考虑了它们邻居的正常程度。因此,距离指定正常片段较远的正常片段也会受到其正常邻居的影响,从而能够被正确标记。此外,之前的“异常衰减”问题也显著缓解,因为视频中的异常通常与正常事件不同。此外,正常性传播是一种迁移学习方法,易于实现,速度快,适合为 UVAD 生成伪标签。
3.3 Unsupervised Learning of Abnormal Detection
我们基于传播的标签和一种新的损失重加权方法进行无监督异常检测学习。它们与正常性传播相辅相成,能够减轻错误传播标签带来的负面影响。
Pseudo Labeling.我们基于正常性得分生成伪标签。首先生成视频级别的伪标签,然后生成片段级别的伪标签。具体而言,我们选择正常视频得分低于正常视频的 N n o r N^{nor} Nnor 个视频,其中视频得分定义为视频中片段正常性得分的标准差。由于异常视频包含正常和异常片段,因此其标准差会较大。之后,我们在异常视频中选择正常性得分低于 r% 的片段作为异常片段。最后,我们将第 i 个视频中的第 t 个片段的伪标签表述为:
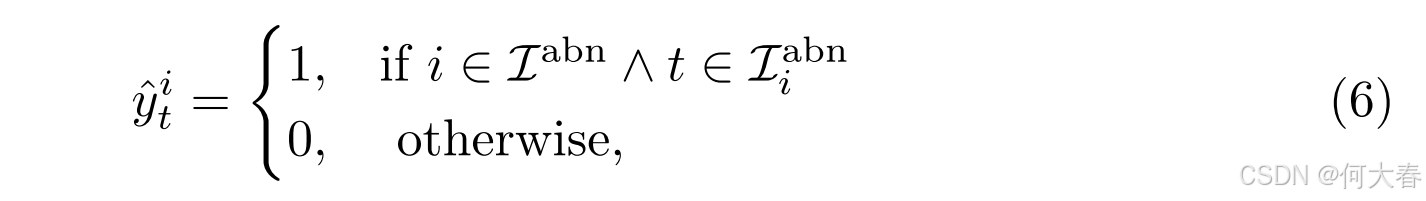
其中 I abn \mathcal{I}^{\text{abn}} Iabn 是异常视频的索引集合, I i abn \mathcal{I}_i^{\text{abn}} Iiabn 是第 i i i个视频中异常片段的索引集合。
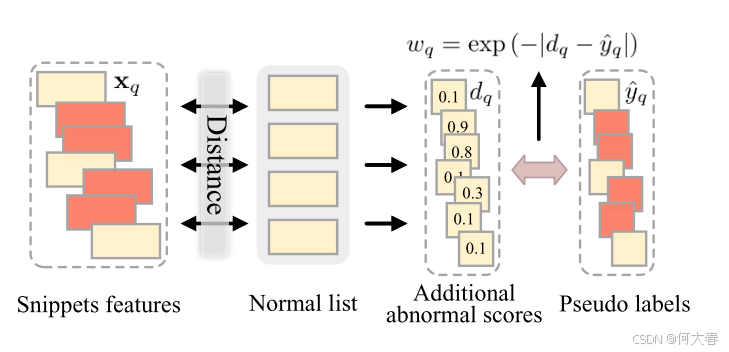
图5:损失重新加权策略。
Loss Re-weighting.由于少数视频可能不遵循正常性先验且正常性传播并不完美,我们可能会得到错误的伪标签。我们提出了一种损失重加权策略,以减轻噪声伪标签的负面影响。如图 5 \color{#c00}{5} 5 所示,我们首先选择 N hnor N^\text{hnor} Nhnor 个高置信度的正常视频,并使用每个选定视频的均值特征来构建正常列表 M = { m 0 , m 1 , ⋯ , m N hnor } \mathcal{M} = \{ \mathbf{m}_0, \mathbf{m}_1, \cdots , \mathbf{m}_{N^\text{hnor}} \} M={m0,m1,⋯,mNhnor}。然后,我们基于全局正常列表估计额外的异常分数。对于片段 x q \mathbf{x}_q xq,其额外分数定义为:
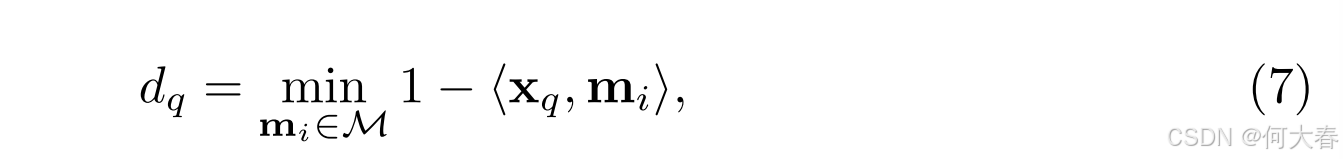
其中
⟨
⋅
,
⋅
⟩
\langle\cdot,\cdot\rangle
⟨⋅,⋅⟩ 是两个向量之间的余弦相似度。额外的异常分数估计了片段在全局视角下的异常概率。这与正常性传播生成的伪标签在局部视角上是互补的。然后,可靠性通过伪标签与额外基于正常的异常分数之间的差异来衡量。我们进一步将片段
x
q
\mathbf{x}_q
xq 的损失权重表示为:
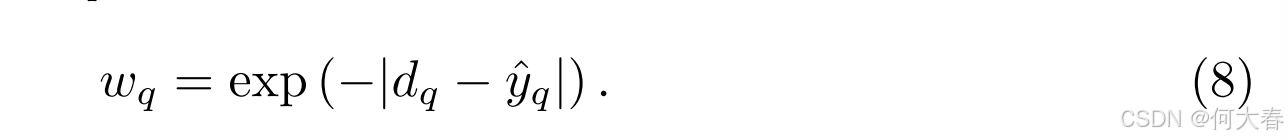
损失重加权策略对高差异的伪标签进行惩罚,以通过可靠的伪标签指导学习。
在生成伪标签及其损失权重后,我们使用加权的二元交叉熵损失来训练分类模型,具体表达为:
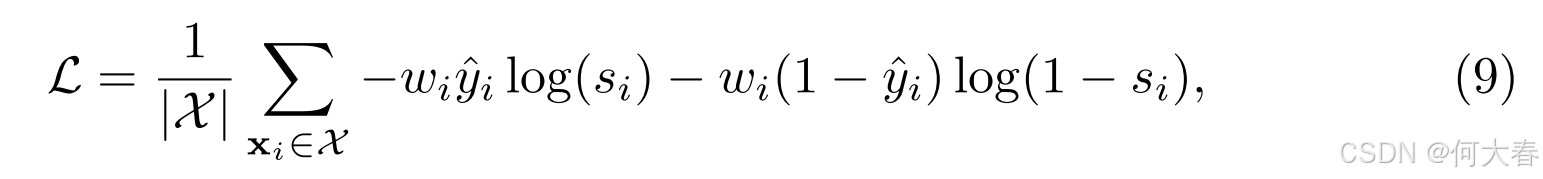
其中 X \mathcal{X} X是小批量中的视频片段集合, s i = f θ ( x i ) s_i = f_\theta(\mathbf{x}_i) si=fθ(xi) 是第 i i i个片段的异常预测。
4 Experiment
在本节中,我们首先提供实验细节,然后与现有的UVAD方法进行比较,最后研究我们方法的不同组成部分。
4.1 Experimental details
Evaluation Datasets.我们在两个流行的视频异常检测数据集上评估了我们的方法:ShanghaiTech [20]和UCF-Crime [33]。
ShanghaiTech [20]是用于视频异常检测的流行数据集。它包含437个校园监控视频(330个正常视频,107个异常视频),不同的位置和摄像头角度。最近的UVAD方法遵循[55]的数据组织,但不在训练集中使用注释。具体而言,训练集包含63个异常视频和175个正常视频,测试集包含44个异常视频和155个正常视频。
UCF-Crime [33]是一个大规模的视频异常检测数据集。它由1900个真实世界的监控视频(950个正常视频,950个异常视频)和13种不同类型的真实异常事件组成。这是一个复杂的数据集,因为视频包含不同的背景和持续时间。最近的UVAD方法遵循[33]的数据组织,但不使用训练视频标签。具体地,训练分割具有810个异常视频和800个正常视频,而测试分割具有140个异常视频和150个正常视频。
Evaluation Metrics.根据之前的工作[37,47],我们使用ROC曲线下面积(AUC)进行评估和比较。AUC值越大,表明性能越好。
Implementation Details.我们使用两个主干网络,即 ResNext3d [8] 和 I3D [2],分别提取每个片段的特征。我们的检测模型由一个时间卷积层和两个线性层组成。在训练过程中,每个小批量包含 30 个随机选择的视频,每个视频被采样为 32 个片段。我们使用 RMSprop 优化器训练模型 300 轮,学习率为 0.0001,动量为 0.6。我们将正常性传播的超参数设置为 α = 0.99,将训练集中正常视频的数量 Nnor 设置为,异常比例 r% = 40%。此外,我们将高置信度正常视频的数量 N h n o r N^{hnor} Nhnor 设置为 h ∗ N n o r h * N^{nor} h∗Nnor,其中 h h h = 0.1。
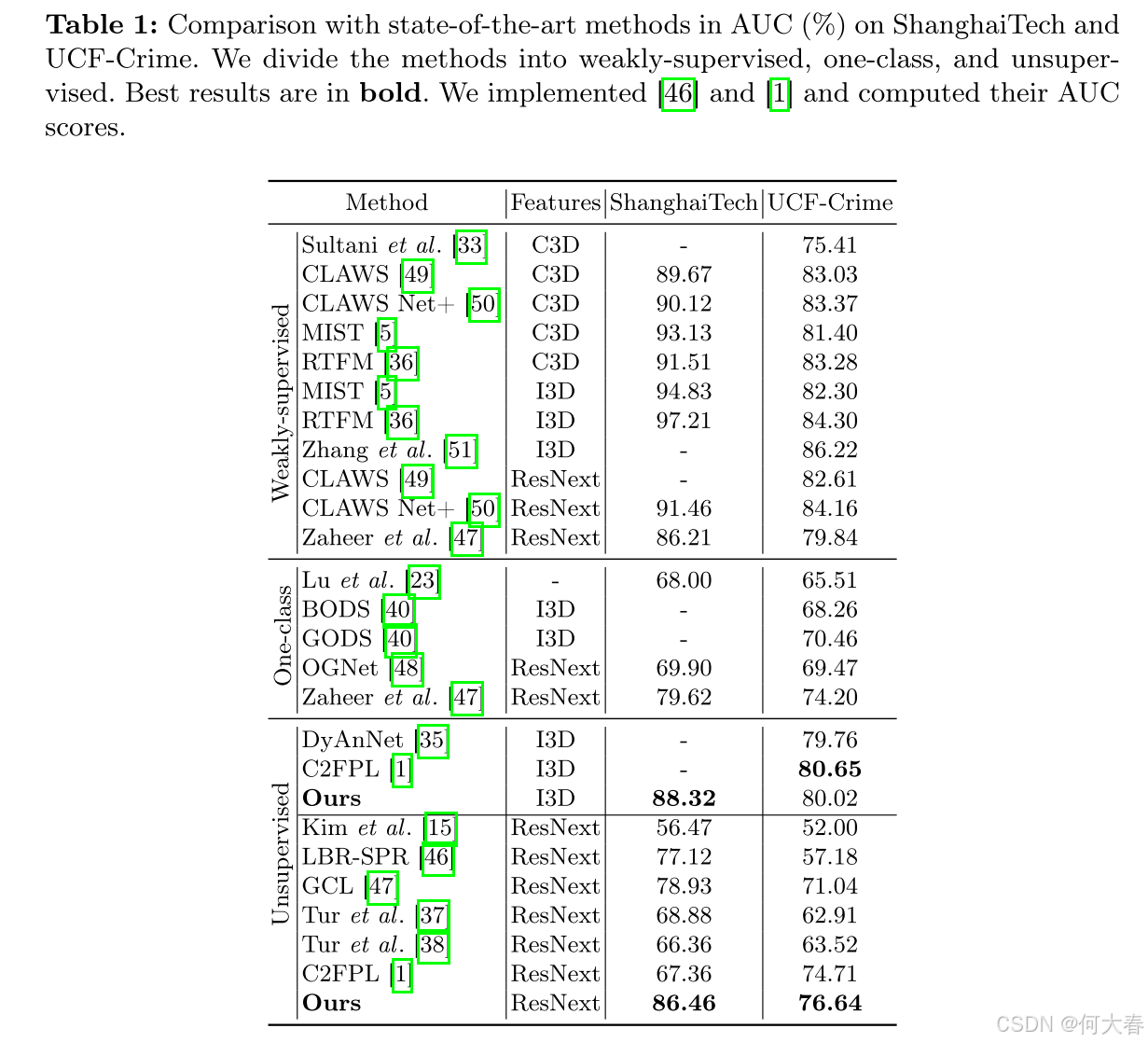
4.2 Comparison with State-of-the-art Methods
4.3 Ablation Study and Analysis
感兴趣的可以看看原文
5 Conclusion
与现有的数据驱动方法不同,本文利用与数据无关的先验知识进行无监督异常检测(UVAD)。我们首先提出了一种新的正常性先验,认为视频的开头和结尾主要是正常的。然后,我们引入正常性传播,根据视频片段之间的关系传播正常知识,以估计未标记片段的正常程度。最后,我们基于传播的标签和一种新的损失重加权方法进行异常检测的无监督学习。大量实验表明,我们的方法优于现有的最先进方法。
阅读总结
所谓的正常性先验,就是把视频的开始片段和结束片段默认为正常了,个人感觉这跟数据集还是有关系的,文章使用的数据集基本异常都不是发生在开始和结束,包括现有的异常检测数据集,大多数都如此,说这个先验与数据无关还是牵强了点。
正常性传播、损失重加权这个思想还是可以借鉴一下的。

















 3591
3591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









