







Towards Balanced Alignment: Modal-Enhanced Semantic Modeling for Video Moment Retrieval 论文阅读
文章信息:
Abstract
视频片段检索(Video Moment Retrieval, VMR)的目标是在未剪辑的视频中根据给定的语言查询检索出相应的时间片段,这通常是通过构建跨模态对齐策略来实现的。然而,现有的策略往往是次优的,因为它们忽略了模态不平衡问题,即视频中固有的语义丰富性远远超过给定的有限长度句子。因此,为了实现更好的对齐,一个自然的想法是增强视频模态以过滤掉与查询无关的语义,同时增强文本模态以捕捉更多与片段相关的知识。本文提出了一种模态增强语义建模(Modal-Enhanced Semantic Modeling, MESM)新框架,通过在两个层面上增强特征来实现更平衡的对齐。首先,我们在帧-词级别通过词重建来增强视频模态。这一策略在帧级特征中强调与查询词相关的部分,同时抑制无关部分。因此,增强后的视频包含更少的冗余语义,与文本模态更加平衡。其次,我们在片段-句子级别通过从上下文句子和真实片段中学习补充知识来增强文本模态。通过将这些知识添加到查询中,文本模态因此保留了更有意义的语义,与视频模态更加平衡。
Introduction
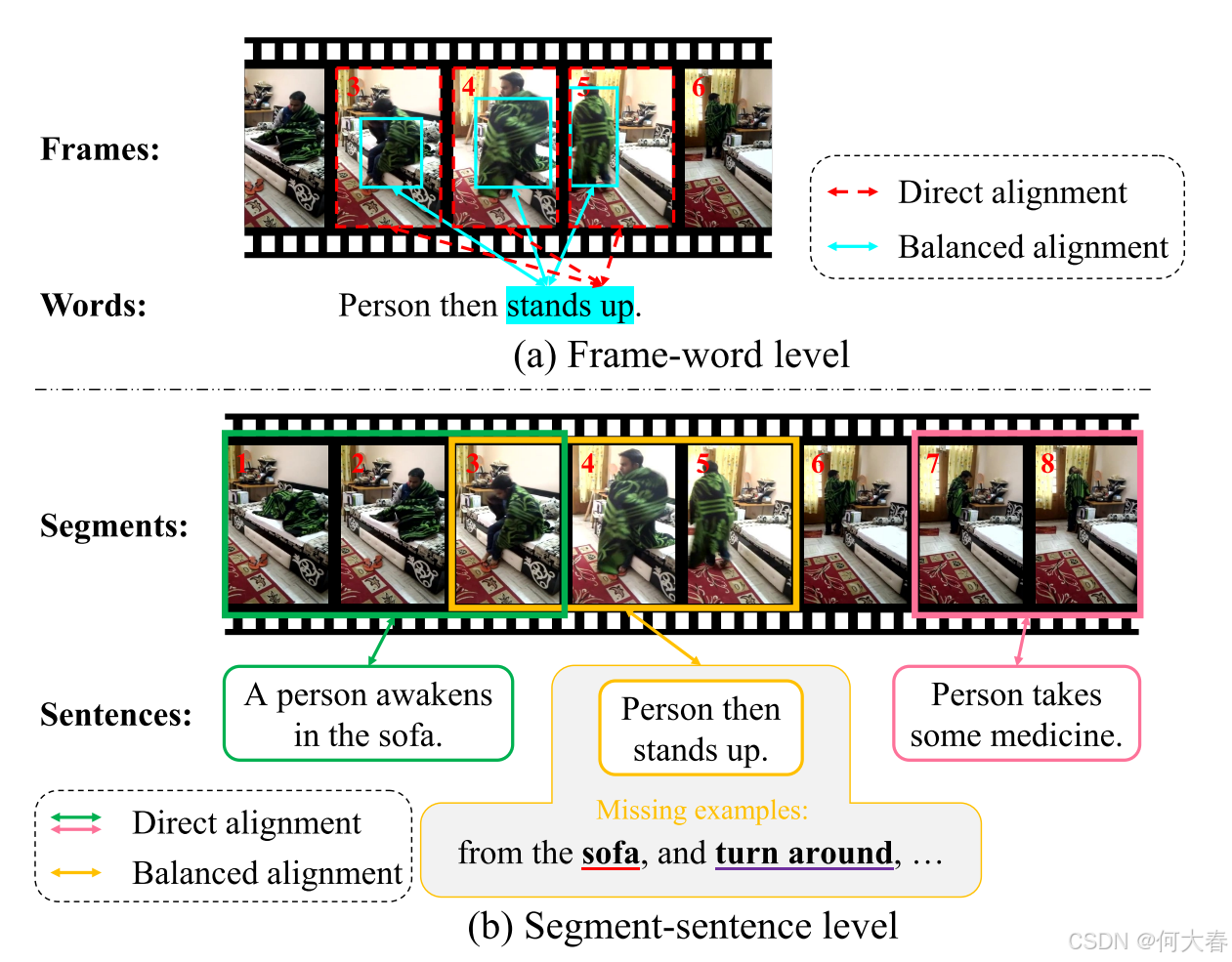
图1:我们创新性地分析了视频-文本检索(VMR)中的模态不平衡问题,并比较了现有的直接对齐和我们的平衡对齐,体现于两个层次:(a)帧-词级别,词的描述通常应该与帧内的特定部分对齐(平衡),而不是与整个帧对齐(直接);(b)段落-句子级别,段落中有些语义信息在给定句子中缺失。段落通常应该与扩展后的句子语义对齐(平衡),而不是仅与句子对齐(直接)。
视频片段检索(Video Moment Retrieval, VMR)在视频理解中是一个有意义且具有挑战性的任务。给定一个描述未剪辑视频中片段的自然语言查询,VMR 的目标是确定该片段在视频中的开始和结束时间戳(Anne Hendricks 等, 2017; Gao 等, 2017)。因此,这项任务需要对视频内容和语言查询的精确理解,以及它们之间的对齐(Li 等, 2023b)。
现有的 VMR 方法中的模态对齐主要在两个不同的层次上实现。一些先前的研究(Li, Guo 和 Wang 2021;Liu 等, 2022a)对齐帧级和词级特征,设计出高效的对齐策略,以准确地回归片段。另一类方法(Chen 和 Jiang 2019;Wang 等, 2022)生成提议,以提取片段级特征,并将其与句子级特征对齐,以识别最匹配的片段作为答案。此外,还有一些方法同时考虑帧-词级和片段-句子级对齐(Wang 等, 2021;Moon 等, 2023)。通常,这些方法首先对齐帧级和词级特征,然后对片段进行池化,以进一步对齐并进行片段检索。
尽管现有的对齐策略取得了一些成果,但它们大多数在帧-词级和片段-句子级忽略了一个关键的模态不平衡问题,导致了模态差距。在帧-词级,如图 1(a) 所示,句子中的词通常只与帧中的特定部分对齐,而不是整个帧(例如,动作“站起来”),这给理解两种模态之间的细粒度关系带来了困难。图 1(b) 展示了片段-句子级的情况。首先,片段的语义信息(例如,帧 #3 到 #5)超出了给定句子所提供的细节,而人类可以轻松推断出缺失的信息(例如,“从沙发上”)。其次,由于标注的主观性,句子本身对于 VMR 任务可能存在歧义。例如,帧 #5 捕捉到的“转身”动作在给定句子中完全没有提及。这两种情况都会对视频理解产生负面影响。总之,由于视频模态固有的语义丰富性,文本模态在两个层级上应该只与视频模态的一个子集对齐,直接与整个模态对齐会导致次优解。
为了解决这个问题,一个自然的想法是同时增强两种模态。视频模态应当增强以过滤掉与查询无关的语义,文本模态则应当增强以捕捉更多与片段相关的知识。因此,我们提出了一个新的框架,称为模态增强语义建模(Modal-Enhanced Semantic Modeling,MESM),在两个层级上对其进行增强。在帧-词级,我们通过共享权重的交叉注意机制来重构词汇,从而增强视频模态。由于词汇通常指代帧的某些部分,重构使模型对这些语义相关的部分更加敏感,并抑制不相关的部分。因此,输出的增强视频特征中冗余的语义信息更少,从而在语义上与词汇更平衡。在片段-句子级,我们通过为给定查询学习补充知识来增强文本模态。如图 1(b) 所示,语义知识的缺失通常来自视频中的给定句子(例如,红色下划线标记的“沙发”)以及视频片段场景(例如,紫色下划线标记的“转身”)。因此,我们可以通过从这两个来源学习来获取缺失的语义。我们对给定句子进行掩码并在对应片段的监督下重生成语义知识。生成的知识补充了查询,使查询的语义信息更强,因此在语义上与片段更加平衡。大量实验表明,我们的 MESM 在三个基准测试和分布外设定中达到了新的最先进性能,展现出改进的模态对齐和泛化能力。
我们论文的主要贡献如下:(1) 据我们所知,我们是首个从帧-词和片段-句子两个层级分析 VMR 中的模态不平衡问题的研究。(2) 为缓解模态不平衡问题,我们提出了一个新的框架 MESM,从两个层级建模增强的语义信息,平衡对齐以弥合模态差距。(3) 大量的实验结果证明了所提方法的有效性。
Related Work
Video Moment Retrieval. 与视频检索(Li 等,2022b)不同,视频片段检索是一个跨模态任务,强调理解视频和文本模态的能力,包括它们的对齐。通常,对齐可以分为帧-词和片段-句子两个层级。一些方法将帧级特征与词级特征对齐(Yuan、Mei 和 Zhu,2019;Zhang 等,2020a;Liu 等,2021a;Li、Guo 和 Wang,2021;Liu 等,2022a)。通常,他们设计了多种对齐策略以直接预测起始和结束时刻。其他方法则侧重于将片段级特征与句子级特征对齐(Gao 等,2017;Chen 和 Jiang,2019;Zhang 等,2020b;Wang 等,2022)。他们通常生成候选方案以获取片段级特征,并将其与句子级特征对齐以选择最佳匹配的片段。最近也有一些方法在两个层级上实现对齐(Wang 等,2021;Sun 等,2022;Moon 等,2023;Wang 等,2023a)。SMIN(Wang 等,2021)基于 2D-TAN 精心设计了多层级对齐。基于 DETR 的方法(Lei、Berg 和 Bansal,2021;Moon 等,2023;Wang 等,2023a;Li 等,2023a)通常先进行帧-词级别的对齐,然后使用可学习的候选方案对片段进行进一步交互,从而取得了良好的效果。然而,大多数这些方法忽视了模态不平衡问题,导致了模态差距。
Modality Imbalance Problem.模态不平衡问题似乎广泛存在于视频-文本表示任务中。(Ko 等,2022)指出了由于标注的模糊性导致视频和文本之间的非顺序对齐问题,并设计了一种可微弱的时间对齐方法。(Wu 等,2023)利用大型语言模型为视频生成辅助字幕,以完成视频-文本检索任务。在视频片段检索(VMR)中,模态不平衡问题同样关键,但很少有研究人员关注这一问题。(Ding 等,2021)通过生成式字幕构建了一个支持集,考虑到一些视觉实体的共存。然而,许多方法仅使用一个视频-查询对作为输入,忽略了同一视频中不同片段句子之间的因果关系,简单地将这些句子视为负样本(Wang 等,2022;Luo 等,2023)。与这些方法不同,我们利用该信息与视频模态相结合,同时增强视频和文本模态,实现更平衡的对齐,弥合模态差距。
Proposed Method
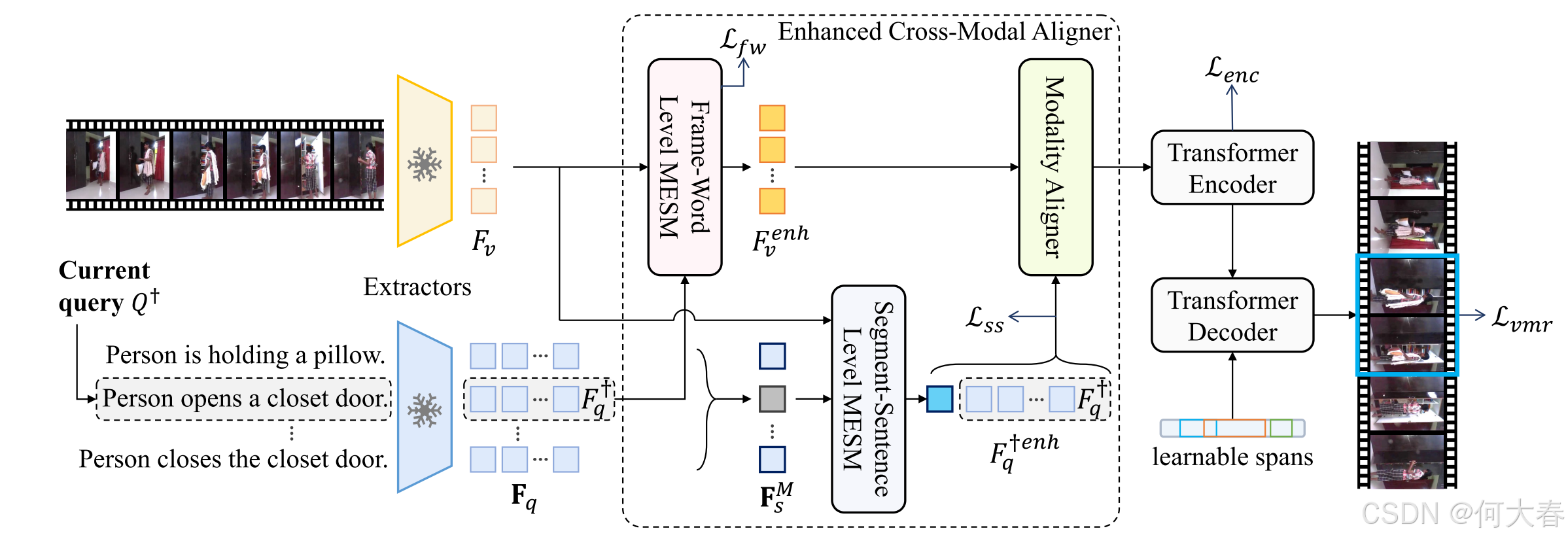
图2:我们 MESM 的概述,包括特征提取器、提出的增强跨模态对齐器(ECMA)以及一个 Transformer 编码器-解码器网络。在 ECMA 中,我们在两个层次上建模增强的语义信息,分别是帧-词级别 MESM(FW-MESM)和段落-句子级别 MESM(SS-MESM)。
Overview
Problem Formulation.:给定一个未经剪辑的视频 V = { f i } i = 1 N v V=\left\{f_i\right\}_{i=1}^{N_v} V={fi}i=1Nv 和一个语言查询 Q † = { w i † } i = 1 N w Q^\dagger = \left \{ w_i^\dagger \right \} _{i= 1}^{N_w} Q†={wi†}i=1Nw,视频片段检索 (VMR) 旨在预测一个视频片段时刻 m ^ = ( t ^ s , t ^ e ) \hat{m}=(\hat{t}_s,\hat{t}_e) m^=(t^s,t^e),使其与 Q † Q^\dagger Q† 最为相关,其中 N v N_v Nv 和 N w N_w Nw 分别表示帧数和词数, t ^ s \hat{t}_s t^s 和 t ^ e \hat{t}_e t^e 表示视频片段的预测起始和结束时间。
Pipeline.图 2 展示了所提出的 MESM 的流程,包括三个步骤。首先,使用离线的视频和文本特征提取器获得帧级和词级特征。然后,我们设计了一个增强跨模态对齐器(ECMA),以缓解模态不平衡问题,实现更平衡的对齐。最后,使用一个 Transformer 编码器-解码器网络对对齐后的特征进行编码,并从可学习的跨度中解码片段。与许多直接对齐不同模态特征的方法不同,我们在所提出的 ECMA 中通过模态增强语义建模,从帧-词和片段-句子两个层面实现平衡对齐,弥合模态差距。
Feature Extractors
特征提取器对于下游任务是必要的(Du 等,2022;Zheng 等,2023;Zhang 等,2023)。按照大多数视频和多模态检索(VMR)方法(Zhang 等,2020b;Wang 等,2023a),我们使用离线特征提取器从视频和文本的原始数据中获取预先提取的特征。通常,给定视频提取器和文本提取器,我们使用可训练的多层感知机(MLP)将提取的视频特征和文本特征映射到一个共同的空间。给定一组语言查询 Q = { Q i ∣ i = 1 , . . . , K } \mathbf{Q} = \left \{ Q^i| i=1, . . . , K\right \} Q={Qi∣i=1,...,K},属于同一视频 V V V,则映射后的视频特征和文本特征可以分别表示为 F v ∈ R L v × D F_v\in\mathbb{R}^{L_v\times D} Fv∈RLv×D 和 F q = { F q i ∈ R L w × D ∣ i = 1 , . . . , K } \mathbf{F}_q=\{F_q^i\in\mathbb{R}^{L_w\times D}|i=1,...,K\} Fq={Fqi∈RLw×D∣i=1,...,K},其中 K K K 是视频中的句子数量, D {D} D 是共同空间的维度。 L v L_v Lv 和 L w L_w Lw 是特征的长度。我们使用 F q † ∈ F q F_q^\dagger\in\mathbf{F}_q Fq†∈Fq 表示当前查询 Q † Q^\dagger Q† 的特征,用于时刻检索,因此 F v F_v Fv 和 F q † F_q^\dagger Fq† 分别是帧级和词级特征。
Enhanced Cross-Modal Aligner
本节介绍了我们提出的增强型跨模态对齐器(Enhanced Cross-Modal Aligner),该对齐器包括三个子模块:帧-词级 MESM(FW-MESM)、段落-句子级 MESM(SS-MESM)和模态对齐器(MA)。FW-MESM 在帧-词级别上增强视频模态,通过强调与查询相关的帧级特征部分并抑制不相关的部分。SS-MESM 在段落-句子级别上增强文本模态,通过生成一个补充标记,该标记来源于查询集和真实段落。鉴于 FW-MESM 和 SS-MESM 生成了增强特征来解决模态不平衡问题,我们随后实现了 MA 来实现最终的跨模态对齐。
Frame-Word Level MESM.由于词语通常指代帧中的特定部分(Ge 等,2021, 2022),我们在帧级特征上进行增强,以过滤掉冗余部分,并设计了一种基于权重共享跨注意力机制的高效语义建模策略。研究表明,权重共享自注意力可以处理来自不同模态的数据(Bao 等,2022;Wang 等,2023b),我们将其扩展到跨注意力的情境中。如图 3 所示,跨注意力的输出 F e n h v F_{enh}^v Fenhv(左分支)表示针对增强的视频特征。该增强需要获取细粒度的区分能力,以强调帧中与词语相关的部分,我们通过一个辅助的掩蔽语言建模(MLM)任务和权重共享跨注意力(右分支)来实现。一旦获得这种能力,共享权重便提供了一个桥梁来增强输出。
具体来说,我们首先将帧级特征的投影 Q = W v F v \mathscr{Q} = W^v F_v Q=WvFv 视为查询,将词级特征的投影 K = W k F q † \mathcal{K} = W^k F_q^\dagger K=WkFq† 和 V = W v F q † \mathcal{V} = W^v F_q^\dagger V=WvFq† 视为键和值,其中 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv 是线性投影矩阵。因此,输出特征 F v e n h ∈ R L v × D F_v^{enh} \in \mathbb{R}^{L_v \times D} Fvenh∈RLv×D 可以表示为:

其中
d
d
d 是查询、键和值的维度。为了增强
F
v
e
n
h
F_v^{enh}
Fvenh,我们交换输入的模态并采用掩蔽语言建模(MLM)。在 MLM 过程中,1/3 的词语被随机掩蔽。若将掩蔽后的词级特征表示为
F
q
†
m
F_q^{\dagger m}
Fq†m,模态交换后的输入为
Q
∗
=
W
q
F
q
†
m
\mathcal{Q}^* = W^q F_q^{\dagger m}
Q∗=WqFq†m(作为查询),
K
∗
=
W
k
F
v
\mathcal{K}^* = W^k F_v
K∗=WkFv 和
V
∗
=
W
v
F
v
\mathcal{V}^* = W^v F_v
V∗=WvFv(分别作为键和值),则重构后的词语特征
F
q
†
r
∈
R
L
w
×
D
F_q^{\dagger r} \in \mathbb{R}^{L_w \times D}
Fq†r∈RLw×D 可以类似于公式 1 计算。接着,通过一个全连接层和 softmax 操作得到概率分布
P
(
F
q
†
r
)
∈
R
L
w
×
N
vocab
P(F_q^{\dagger r}) \in \mathbb{R}^{L_w \times N_{\text{vocab}}}
P(Fq†r)∈RLw×Nvocab,其中
N
vocab
N_{\text{vocab}}
Nvocab 是词汇表的大小。我们使用交叉熵损失来度量重构词语与原始词语之间的相似性,其表达式为:
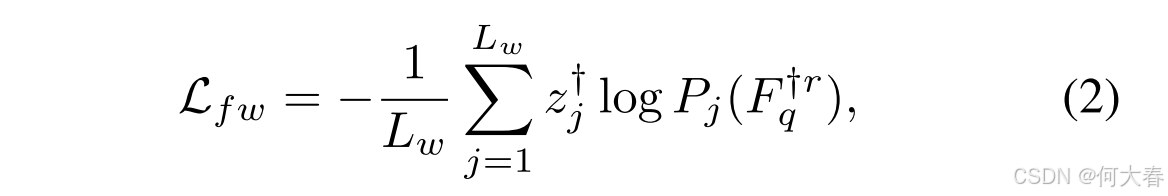
其中,
z
j
z_j
zj 是句子中第
j
j
j 个词的标签。
由于权重是共享的,从 MLM 任务中获得的能力同样适用于原始输出。因此,
F
v
e
n
h
F_v^{enh}
Fvenh 被增强以突出
F
v
F_v
Fv 中语义相关的部分,同时过滤掉不相关的部分,使其与文本模态更加平衡。
Segment-Sentence Level MESM.由于单个句子无法完全覆盖段落信息,我们在段落-句子级别上增强文本模态,通过从上下文句子和真实段落生成一个补充标记,然后将该标记连接到给定查询中。为监督补充知识的学习,我们构建了一个用于对比学习的正样本集。该正样本集收集了真实段落的现有邻域,从而进行软监督,因为这些邻域具有相似的语义信息,这部分内容将在后文介绍。
由于我们已提取出
K
K
K 个句子的词级特征
F
q
F_q
Fq,我们简单地对第
i
i
i 个句子的
F
q
i
F_q^i
Fqi 取平均,以获得句子级特征
F
s
i
=
1
L
w
∑
j
=
1
L
w
(
F
q
i
)
j
F_s^i = \frac{1}{L_w} \sum_{j=1}^{L_w} (F_q^i)_j
Fsi=Lw1∑j=1Lw(Fqi)j,因此
F
s
i
∈
R
D
F_s^i \in \mathbb{R}^D
Fsi∈RD。对于当前句子级特征
F
s
†
F_s^\dagger
Fs†,我们将其替换为一个可学习的 [MASK] 标记
F
s
†
M
∈
R
D
F_s^{\dagger M} \in \mathbb{R}^D
Fs†M∈RD,并且带有掩蔽标记的句子级特征集合可以表示为
F
s
M
=
{
F
s
1
,
.
.
.
,
F
s
†
M
,
.
.
.
,
F
s
K
}
∈
R
K
×
D
\mathbf{F}_s^M = \left \{ F_s^1, . . . , F_s^{\dagger M}, . . . , F_s^K \right \} \in \mathbb{R}^{K \times D}
FsM={Fs1,...,Fs†M,...,FsK}∈RK×D。然后在
F
s
M
\mathbf{F}_s^M
FsM(作为查询)和
F
v
F_v
Fv(作为键和值)上实现跨注意力层。跨注意力层的输出可以表示为:
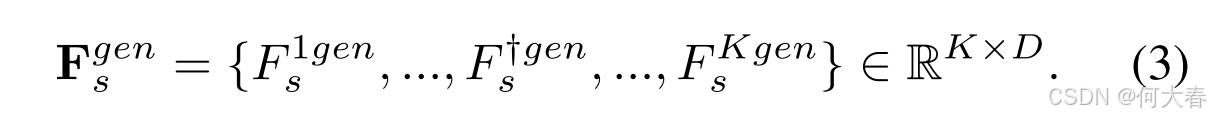
注意 F s † gen F_s^{\dagger \text{gen}} Fs†gen 是输出 F s gen F_s^{\text{gen}} Fsgen 中的一部分,我们将其提取出来作为句子的补充知识生成的标记。然后我们将生成的标记 F s † gen F_s^{\dagger \text{gen}} Fs†gen 与词级特征 F q † F_q^\dagger Fq† 连接在一起,得到增强后的词级特征 F q † enh = [ F s † gen , F q † ] ∈ R ( L w + 1 ) × D F_q^{\dagger \text{enh}} = [F_s^{\dagger \text{gen}}, F_q^\dagger] \in \mathbb{R}^{(L_w + 1) \times D} Fq†enh=[Fs†gen,Fq†]∈R(Lw+1)×D。
通过补充知识,查询与段落更加平衡。因此,我们使用段落级特征来监督 F q † enh F_q^{\dagger \text{enh}} Fq†enh,以获得与段落相关的知识。给定视频段落的真实值 ( l s , l e ) (l_s, l_e) (ls,le),其中 l s l_s ls 和 l e l_e le 表示帧级特征 F v F_v Fv 的起始和结束索引。我们取其平均值作为段落级特征 S ∈ R D S \in \mathbb{R}^D S∈RD,其公式为:
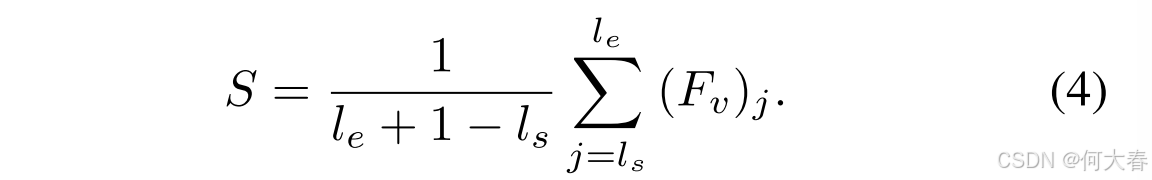
然后,我们设计了一种对比损失来监督知识学习。由于视频中可能存在一些具有相似时刻的邻近段落,我们基于段落之间的 IoU 在一个批次中构建一个正样本集 S p o s S_{pos} Spos。当两个段落的 IoU 大于 γ \gamma γ 时,我们将这些段落视为正样本,它们的对应知识应当相似。对比损失可以表示为:
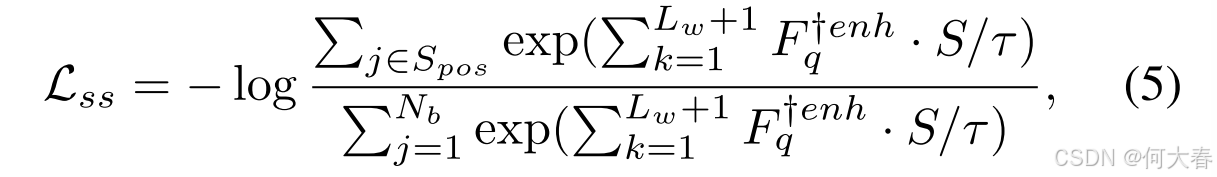
其中,
N
b
N_b
Nb 表示批次大小,
τ
\tau
τ 是温度系数。在段落级特征
S
S
S 的监督下,增强后的词级特征
F
s
†
enh
F_s^{\dagger \text{enh}}
Fs†enh 包含了整个段落内的补充语义信息,因此与视频模态更加平衡。
Modality Aligner.由于我们已经获得了增强后的帧级特征 F v enh F_v^{\text{enh}} Fvenh 和增强后的词级特征 F q † enh F_q^{\dagger \text{enh}} Fq†enh,我们
最终在 F v enh F_v^{\text{enh}} Fvenh(作为查询)和 F q † enh F_q^{\dagger \text{enh}} Fq†enh(作为键和值)之间采用跨注意力层来进行模态交互与对齐。
最终的对齐特征 F ∈ R L v × D F \in \mathbb{R}^{L_v \times D} F∈RLv×D 可以通过标准跨注意力计算得到。
Transformer Encoder-Decoder
在通过 ECMA 获得模态对齐特征 F F F 后,采用 DETR(Carion 等,2020)网络完成视频-文本检索(VMR),该网络由一个 Transformer 编码器和解码器组成。
Transformer 编码器将 F F F 编码为融合表示 F enc F_{\text{enc}} Fenc,帮助模型更好地理解序列关系。编码过程遵循标准的自注意力机制,损失可以计算为:
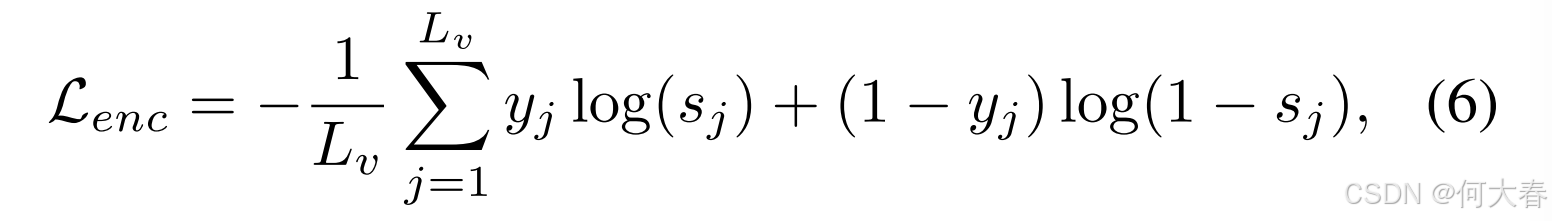
其中, s ∈ R L v s \in \mathbb{R}^{L_v} s∈RLv 是相似度向量,表示模型的注意力集中位置,且通过一个 MLP 从 F enc F_{\text{enc}} Fenc 中获得。 y ∈ R L v y \in \mathbb{R}^{L_v} y∈RLv 是相似度标签,其中如果第 j j j 帧在真实段落内,则 y j = 1 y_j = 1 yj=1,否则 y j = 0 y_j = 0 yj=0。
对于 Transformer 解码器,受到 DABDETR(Liu 等,2021b)的启发,我们
遵循 QD-DETR(Moon 等,2023)设计了可学习的跨度,用于表示中心坐标和窗口。解码器计算可学习跨度与池化特征之间的标准跨注意力,持续优化跨度的结果。
受到 (Carion 等,2020; Lei, Berg 和 Bansal,2021) 的启发,时刻检索损失由三个部分组成:
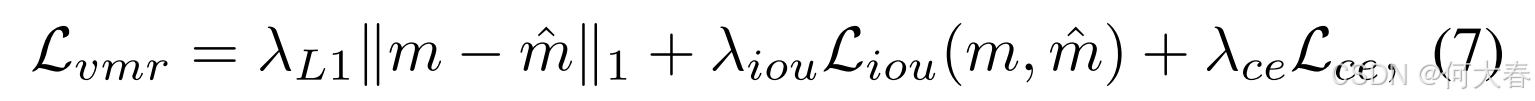
其中, m m m 和 m ^ \hat{m} m^ 分别是预测的时刻和真实时刻, λ ( L 1 , IoU , CE ) \lambda_{(L1, \text{IoU}, \text{CE})} λ(L1,IoU,CE) 是超参数, L IoU \mathcal{L}_{\text{IoU}} LIoU 是广义的 IoU 损失(Union 2019), L CE \mathcal{L}_{\text{CE}} LCE 是用于分类前景或背景的交叉熵损失(Carion 等,2020)。
因此,最终损失为:
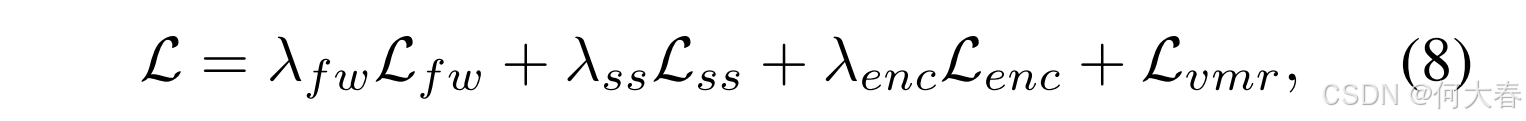
其中,
λ
f
w
\lambda_{fw}
λfw、
λ
s
s
\lambda_{ss}
λss 和
λ
e
n
c
\lambda_{enc}
λenc 是超参数。
Experiments
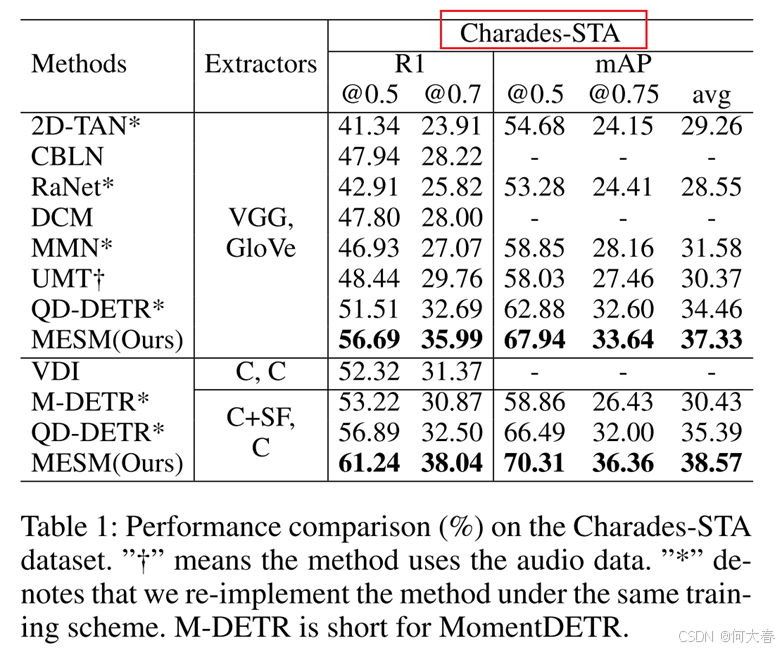
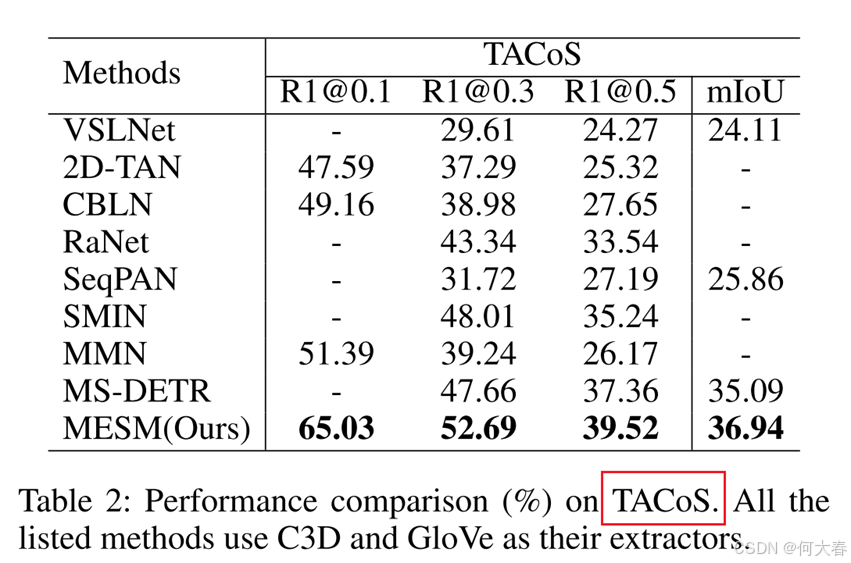
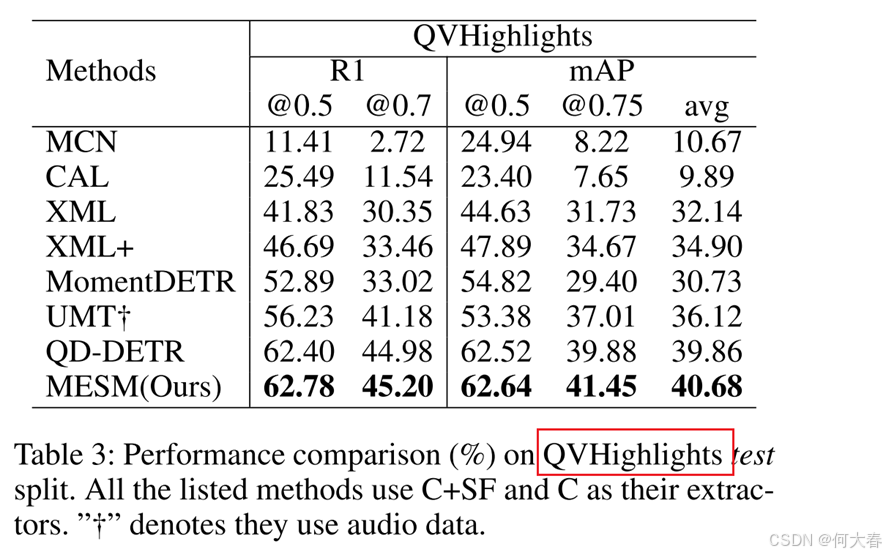
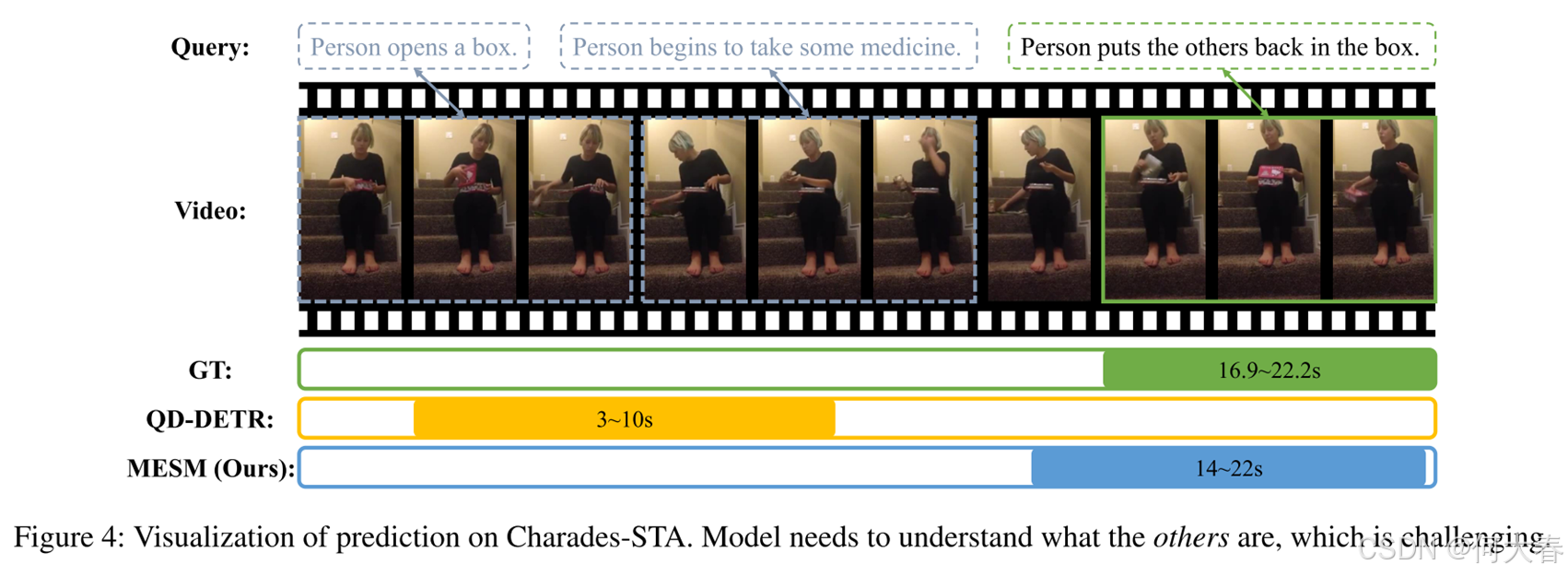
Conclusion


















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









