







最近在研究目标抓取类型的文章,执行目标需要知道目标的位姿。然后看到这篇文章,为防止遗忘,做个笔记跟大家分享下,后续可能复现这篇文章。
摘要
本文讨论了单幅RGB图像在严重遮挡或截断情况下的6DoF位姿估计问题。最近的许多研究表明,two-stage的方法:首先检测关键点,然后解决一个PnP问题的位姿估计,效果很好。然而,这些方法大多通过回归图像坐标或热图来定位一组稀疏关键点,它们对遮挡和截断非常敏感。相反,我们引入了PVNet,回归像素级的单位向量,并使用这些向量,通过RANSAC对关键点位置进行投票。这种表示方法的另一个重要特征是,它提供了关键点位置的不确定性,可以被PnP求解器进一步利用。实验表明我们的方法在LINEMOD,Occlusion LINEMOD和YCB Video数据集上优于其他方法。
1. 介绍
目标位姿估计的目的是检测目标并估计其相对于标准帧的方向(旋转)和平移。精确的位姿估计对于增强现实、自动驾驶和机器人操作等各种应用都是必不可少的。例如,快速和稳健的位姿估计是亚马逊拣选挑战的关键,机器人需要从仓库中拣选一件物体。本文重点研究了物体6DoF位姿恢复的具体设置,即3D空间中旋转和平移,从一个单一的RGB图像的对象。这个问题在很多方面都具有挑战性,包括严重遮挡下的目标检测、光线和外观的变化以及杂乱的背景对象。
传统方法表明,通过建立目标图像与目标模型之间的对应关系,可以实现位姿估计。它们依赖于手工制作的特征,这些特征对图像变化和背景杂波的鲁棒性不好。基于深度学习的方法训练端到端的神经网络,将图像作为输入,输出其相应的位姿。然而,泛化仍然是一个问题,因为这样的端到端方法学习足够的特征表示来进行位姿估计是不清楚的。
最近的一些方法使用CNNs首先回归2D关键点坐标,再使用PnP算法计算6D位姿参数。换句话说,检测的关键点坐标作为位姿估计的媒介。这些two-stage的方法效果很好,由于检测的关键点的鲁棒性好。然而,这些方法很难处理被遮挡和截断的对象,因为它们的部分关键点是不可见的。尽管CNNs可以通过记忆相似的模式来预测这些看不见的关键点,但泛化仍然是困难的。
我们认为,解决遮挡和截断需要密集的预测,即pixel-wise或patch-wise对最终输出或中间表示的估计。为此,我们提出了一个新的框架,使用像素级投票网络的6D位姿估计(PVNet)。基本思想如图1所示。PVNet不是直接回归关键点的图像坐标,而是预测表示从对象的每个像素到关键点方向的单位向量。这些方向(我理解的是这些单位向量)然后根据RANSAC为关键点位置投票。这个投票方案是由刚性物体的属性激发的,一旦我们看到一些局部部分,我们就能推断出其他部分的相对方向。
 图1所示。将6D位姿估计问题表示为一个PnP问题,需要2D和3D关键点之间的对应关系,如(d)和(e)所示。对于每个像素,我们预测单位向量指向关键点(的方向),如(b)所示,然后通过RANSAC投票定位2D关键点,如©所示。该方法对于遮挡和截断的鲁棒性很好,绿色边框代表GT位姿,和蓝色边框代表预测。
图1所示。将6D位姿估计问题表示为一个PnP问题,需要2D和3D关键点之间的对应关系,如(d)和(e)所示。对于每个像素,我们预测单位向量指向关键点(的方向),如(b)所示,然后通过RANSAC投票定位2D关键点,如©所示。该方法对于遮挡和截断的鲁棒性很好,绿色边框代表GT位姿,和蓝色边框代表预测。
我们的方法本质上是为关键点位置创建一个向量场表示。与基于坐标或热图的表示法相比,学习这种表示法使网络专注于对象的局部特征和对象部件之间的空间关系。因此,可以从可见部分推断出不可见部分的位置。此外,这个向量场表示能够表示甚至在输入图像之外的对象关键点。所有这些优点使它成为闭塞或截断对象的理想表示。Xiang等人提出类似的想法检测目标,在这我们用于定位关键点。
该方法的另一个优点是密集的输出为PnP求解器处理不准确的关键点预测提供了丰富的信息。具体来说,基于RANSAC的投票排除预测异常值,并给出每个关键点的空间概率分布。这些关键点位置的不确定性给了PnP求解器更多的自由,来识别一致的对应关系,从而预测最终的位姿。实验表明,不确定性驱动的PnP算法提高了姿态估计的精度。
我们在LINEMOD,Occlusion LINEMOD和YCB Video数据集上评估我们的方法,这些数据集广泛用于6D位姿估计。在所有的数据集上,PVNet优于现有的方法,我们还演示了PVNet在Truncation LINEMOD的新数据集上处理截断对象的能力,该数据集是通过随机剪切LINEMOD图像创建的。而且,我们的方法效率很高,在GTX 1080ti GPU上的速度为25帧,可以用作实时位姿估计。
总之,我们的方法有以下贡献:
- 提出了一种基于像素级投票网络(PVNet)的6D位姿估计新框架,该框架通过学习向量场表示来实现稳健的2D关键点定位,并自然地处理遮挡和截断问题;
- 基于PVNet的密集预测,我们提出了一种基于不确定性驱动的PnP算法,来考虑2D关键点定位的不确定性;
- 与基准数据集上的最新技术相比,我们的方法在性能上有了显著的改进(ADD:86.3% vs. 79%,在LINEMOD和OCCLUSION分别为40.8%和30.4%)。我们还创建了一个新的数据集,用于对截断的对象进行评估
2 相关工作
整体法. 对于给定的一幅图像,一些方法旨在估计物体在单镜头中的3D位置和方向。传统的方法主要依靠模板匹配技术,这些技术对杂乱的环境和外观变化非常敏感。最近,CNNs对环境变化具有显著的鲁棒性。作为先驱者,PoseNet引入了一种CNN架构,可以从单个RGB图像直接回归6D相机位姿,这是一种类似于对象位姿估计的任务。然而,由于缺乏深度信息和较大的搜索空间,直接在3D中定位对象是困难的。为了克服这一问题,PoseCNN对2D图像中的物体进行定位,并预测其深度,得到3D位置。然而,由于旋转空间的非线性使得CNNs的泛化程度较低,直接估计3D旋转也比较困难。为了避免这个问题,这些工作将旋转空间离散化,将3D旋转估计转换为分类任务。这样的离散化会产生粗糙的结果,而后细化(post-refinement)对于获得精确的6DoF位姿至关重要。
基于关键点方法. 与直接从图像中获取位姿不同,基于关键点的方法采用了two-stage的方法:首先预测物体的2D关键点,然后通过PnP算法计算2D-3D对应关系来估计姿态。与3D定位和旋转估计相比,2D关键点检测相对容易。对于纹理丰富的对象,传统的方法对局部关键点进行了鲁棒性检测,因此即使在杂乱的场景和严重的遮挡下,也能高效准确地估计出目标的姿态。然而,传统方法在很难处理低纹理物体和低分辨率图像。为了解决这个问题,最近的研究定义了一组语义关键点,并使用CNNs作为关键点检测器。[33]使用分割来识别包含对象的图像区域,并从检测到的图像区域中回归关键点。[39]使用YOLO架构来估计对象关键点。他们的网络根据低分辨率的特征图进行预测。当全局干扰发生时,如遮挡,特征图被干扰,位姿估计精度下降。在2D人体姿态估计成功的激励下,另一类方法输出关键点的像素级热图来解决遮挡问题。然而,由于热图的大小是固定的,这些方法在处理截断的对象时会有困难,这些对象的关键点可能在输入图像之外。相比之下,我们的方法使用更灵活的表示方法对2D关键点进行像素级预测,即向量场。关键点的位置是通过从方向投票来决定的,这些方向适合于截断的对象。
密集方法.在这些方法中,每个pixel或者patch都会产生一个预测,然后基于广义的霍夫投票对最终结果进行投票。[3,28]使用随机森林预测每个像素的3D物体坐标,利用几何约束产生2D-3D对应假设。为了利用强大的CNNs,[21,9]密集地采样图像补丁,并使用网络为后续的投票提取特征。但是,这些方法需要RGB-D数据。在仅存在RGB数据的情况下,[4]使用自动上下文回归框架来生成3D对象坐标的像素级分布。与稀疏关键点相比,目标坐标为位姿估计提供了密集的2D-3D对应,对遮挡具有更强的鲁棒性。由于输出空间较大,使得回归对象坐标比关键点检测更加困难。我们的方法对关键点位置进行了密集预测,它可以看作是基于关键点和密集方法的开端,结合了这两种方法的优点。
3 方法
在这篇文章中,我们为6DoF目标位姿估计提出了一个新的框架。输入一张图片,位姿估计得目的是在检测目标并在3D空间中估计他们的方向和平移。具体而言,6D位姿是由物体坐标系到相机坐标系的刚性变换(R;t),R表示3D旋转,t表示3D平移。
被这些方法所启发,我们使用two-stage的方法:首先使用CNNs检测2D目标的关键点,再使用PnP算法计算6D位姿参数。我们的创新点是一种新的2D目标关键点表示方法和修改的PnP算法。具体来说,我们的方法使用PVNet以一种类似于ransacs的方式检测2D关键点,该方法能够可靠地处理被遮挡和截断的对象。基于ransacs的投票也给出了每个关键点的空间概率分布,允许我们用不确定性驱动的PnP来估计6D位姿。
3.1 基于投票的关键点定位

图二 关键点定位概览.(a)Occlusion LINEMOD数据集的一张图片。(b)PVNet的结构。(c)指向目标关键点的pixel-wise的单位向量。(d)语义标签。(e)投票产生的关键点位置的假设。投票得分越高的假设越亮。(f)由假设估计的关键点位置的概率分布。分布的均值用红星表示,协方差矩阵用椭圆表示
图二展示了关键点定位的概览。输入一张RGB图像,PVNet预测pixel-wise对象标签和单位向量,它们表示从每个像素到每个关键点的方向。给定从属于该对象的所有像素点到某个对象关键点的方向,我们生成该关键点的2D位置假设以及通过RANSAC-based投票得到的置信度分数。基于这些假设,我们估计了每个关键点的空间概率分布的均值和协方差。
与直接从图像块中回归关键点位置不同,pixel-wise方向的预测任务迫使网络更多地关注对象的局部特征,减轻了背景杂乱的影响。这种方法的另一个优点是能够表示被遮挡或图像外部的关键点。即使一个关键点是不可见的,它也可以根据物体其他可见部分估计的方向来正确定位(刚体性质)。
更具体而言,PVNet执行2个任务:语义分割和向量场预测。对于一个像素P,PVNet输出一个与特定目标相关的语义标签,和一个表示从像素P到目标2D关键点Xk方向的单位向量Vk§。向量Vk§定义为:
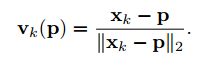
给定语义标签和单位向量,我们通过RANSAC-based投票的方法生成关键点假设。首先,利用语义标签查找目标对象的像素点pixels。然后,随机取2个pixels,对关键点Xk,取其向量的交点作为假设hk,i。重复N次,生成一系列假设 ,表示可能的关键点位置。最后,对象的所有pixels为这些假设投票,具体而言,假设hk,i的投票分数wk,i定义为:
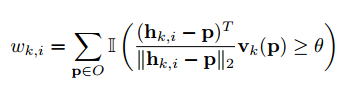
其中I表示指标函数,θ是阈值(在所有实验中为0.99), 表示pixel P属于目标O。直观上,投票得分越高,表示假设与预测方向越吻合,越有信心
所得到的假设描述了图像中一个关键点的空间概率分布。图2(e)显示了一个示例。最后,对于一个关键点Xk,均值µk和协方差Σk通过下面式子计算:
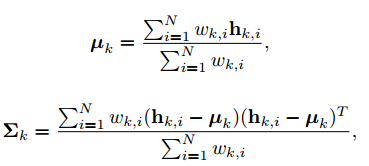
这些后续会用于不确定性驱动的PnP算法。
关键点选取。需要根据3D对象模型定义关键点(需要原始物体的3D模型?)。许多最近的方法以物体3D包围框的八个角为关键点。图3(a)显示了一个示例,这些边框角远离图像中的对象像素点,距离目标像素越远,定位误差越大,因为关键点假设是使用从目标像素开始的向量生成的。图3(b)和©分别显示了我们的PVNet生成的在物体表面上选取的一个边界框角点和一个关键点的假设。在定位过程中,物体表面上的关键点的方差通常要小得多。

图3.(a)一个3D物体模型和它对应的3D边界框。(b)由PVNet产生的关于边界框角的假设。(c)由PVNet产生的假设,用于选择物体表面上的一个关键点。表面关键点的方差越小,表明在我们的方法中,定位表面关键点比定位边界框角更容易。
因此,在我们的方法中,应该在对象表面选择关键点。同时,这些关键点应该分散在对象上,使PnP算法更加稳定。介于这2个要求,我们使用最远点采样(FPS)算法选取K个关键点。首先,我们通过添加对象中心来初始化关键点集合。然后,我们不断找物体表面的一个点,它距离当前关键点集最远,并将其添加到当前集合,直到集合的大小达到k。结果表明,该策略比使用边界框的角点会产生更好的结果。我们还使用不同数量的关键点来比较结果。考虑到准确性和效率,我们建议根据实验结果K = 8。
多个实例。我们的方法可以基于[43,31]中提出的策略处理多个实例。对于每个对象类,我们使用提出的投票方案生成对象中心及其投票分数的假设。然后,我们找出假设之间的模式,并将这些模式标记为不同实例的中心。最后,通过将像素分配给它们投票支持的最近的实例中心来获得实例掩码
3.2 不确定性驱动的PnP
给定每个对象的2D关键点位置,其6D位姿可以通过使用现成的PnP求解器来求解,例如,在许多以前的方法中使用的EPnP [24] [39,33]。然而,它们大多忽略了这样一个事实,即不同的关键点可能具有不同的置信度和不确定性模式,这是解决PnP问题时应该考虑的问题。
如3.1介绍的,我们基于投票的方法估计每个关键点的空间概率分布。考虑到估计均值µk和协方差矩阵Σk,k = 1…K,计算6D位姿(R;t)通过最小化马氏距离:
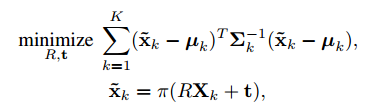
其中,Xk是关键点的3D坐标, 是Xk的2D投影,π是透视投影函数。参数R和t由EPnP[24]基于四个关键点初始化,其协方差矩阵的轨迹最小。然后,使用Levenberg-Marquardt算法求解(5)。在[11]中,作者还通过最小化近似辛普森误差来考虑特征的不确定性。在我们的方法中,我们直接最小化重投影误差
4 实施细节
假设对象有C类,每个类有K个关键点,PVNet将H×W×3图像作为输入,采用全卷积结构处理,输出表示单位向量的H×W×(K×2×C)张量和表示类概率的H×W×(C+1)张量,我们使用预训练的ResNet-18作为backbone,并做了3处改动。首先,当网络的feature map的大小为H=8×W=8时,我们不再下采样feature map,丢弃后续的pooling层;第二,为了保持感受野不变,后续的卷积层用适当的扩张卷积(dilated)替代;第三,原ResNet-18中的全连接层用卷积层替换。然后,在feature map上反复进行skip connection、convolution、upsampling,直到其size达到H×W,如图2(b)所示。通过对最终的feature map进行1×1的卷积,得到单位向量和类概率。
我们使用CUDA实现了假设生成、像素投票和密度估计。用于初始化位姿的EPnP在OpenCV中实现。为了得到最终的位姿,我们使用迭代求解器Ceres来最小化Mahalanobis距离(5)。对于对称物体,在关键点位姿存在歧义。为了消除歧义,我们在训练期间将对称对象旋转到一个规范的姿势,就像[33]建议的那样。
4.1 训练策略
我们使用在[13]中提出的平滑L1损失来学习单位向量。定义相应的损失函数为:

其中,w表示PVNet中的参数, 是预测向量, 是真实值的单位向量, 和 代表 的2个元素。对于语义标签的训练,采用softmax最大交叉熵损失法。注意,在测试期间,我们不需要将预测的向量作为单元,因为后续处理只使用向量的方向。
为了防止过拟合,我们在训练集中加入了合成图像。对于每个对象,我们渲染了10000张视点均匀采样的图像。我们使用[10]中提出的“剪切和粘贴”策略进一步合成了另外10000张图像。每个合成图像的背景是随机采样的SUN397[44]。我们还应用了在线数据扩充,包括随机裁剪、调整大小、旋转和颜色抖动。我们将初始学习率设置为0.001,每20个epoch减半一次。所有的模型都经过了200个时代的训练。
5 实验
略。
6 结论
我们提出了一种新的6DoF目标位姿估计框架,该框架由用于关键点定位的pixel-wise投票网络(PVNet)和用于最终位姿估计的不确定驱动PnP组成。结果表明,对向量场进行预测,然后对关键点定位进行RANSAC-based的投票,可以获得比直接回归关键点坐标更好的性能,特别是对于被遮挡或截断的对象。我们还证明了在解决PnP问题时考虑预测关键点位置的不确定性,进一步改进了位姿估计。我们报告了三种广泛使用的基准数据集的最新性能,并在一个新的截断对象数据集上证明了所提出方法的鲁棒性。
论文链接:https://arxiv.org/pdf/1812.11788.pdf
代码已开源,链接:https://github.com/zju3dv/pvnet
合成数据代码链接:https://github.com/zju3dv/pvnet-rendering














 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









