







目录
1: torch.utils.data.DataLoader
2:全连接层torch.nn.linear(in_features, out_features)
3:torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1)
9.optimizer.zero_grad(),loss.backward()和optimizer.step()
10.1torch.nn.AdaptiveAvgPool2d自适应平均池化
11.2.get_statistics(variable_name=None)
12.1.torch.unsqueeze(input, dim, out=None)
1: torch.utils.data.DataLoader
在训练模型时使用到此函数,用来把训练数据分成多个batch, #此函数每次抛出一个batch数据,直至把所有的数据都抛出,也就是个数据迭代器。:
2:全连接层torch.nn.linear(in_features, out_features)
in_features:输入特征维度,跟输入图像维度有关.out_features;输出特征维度
3:torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1)
参数:
in_channels:输入图像通道数,手写数字图像为1,彩色图像为3 .
out_channels:输出通道数,这个等于卷积核的数量 .
kernel_size:卷积核大小 .如果输入是一个值,比如 3 33,那么卷积核大小就是 3 × 3 3 \times 33×3 ,如果不想卷积核宽和高相等,还可以输入tuple类型数据,比如: ( 3 , 5 )
stride:步长.如果输入是一个值,比如 2 22 ,步长就是 2 × 2 2 \times 22×2 ,还可以输入元组 ( 2 , 1 ) ,表示卷积核每次向右移动 1 个步长,向下移动 2 个步长。
padding:填充,参数表示在周围补0的情况。补0的方向为上、下、左、右四个方向。如果是输入是单个值,比如1,就是在上下左右四个方向补一圈0。如果输入是元组比如 (2,1) ,表示在上下两个方向各补两行0,在左右两个方向各补一列0。
dilation:进行扩展卷积需要的参数。
groips:进行分组卷积需要的参数。
bias:偏置,布尔类型,默认为 True ,即增加一个学习的偏置项。
padding_mode:填充的模式,默认是 zero ,还可以选择 reflect 、 replicate 、 circular
import torch
import torch.nn as nn
# in_channels=16, out_channels=33, kernel_size=(3, 5)
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
print(m)
# 我们随机构造输入数据
# N=20, C_in=16, H_in=50, W_in=100
# 输入形状 (N, C, H, W)
input = torch.randn(20, 16, 50, 100)
output = m(input)
print(output.shape)
print(m.weight.shape)
print(m.bias.shape)
'''输出结果为:
Conv2d(16, 33, kernel_size=(3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
torch.Size([20, 33, 26, 100])
torch.Size([33, 16, 3, 5])
torch.Size([33])'''
4:optimizer.zero_grad()
梯度归零
5:torchvision.transform()
对图片进行处理,数据增强,数据预处理
- transforms.compose()一般用compose把多个步骤整合到一起。
- transforms.RandomRotation(45),
# 随机旋转,-45到45度之间随机选
- transforms.CenterCrop(224), # 从中心开始裁剪
- transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率
- transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
- transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
- transforms.RandomGrayscale(p=0.025), # 概率转换成灰度率,3通道就是R=G=B:
- transform.ToTensor()能够把灰度范围从0-255变换到0-1之间
- transform.Normalize()transform.Normalize()则把0-1变换到(-1,1)
import numpy as np
import cv2
import os
import torch
import math
import torchvision.transforms as transforms
from PIL import Image
'''
#1:照片
path="dream.jpg"#原图是1000*930*3
# 通道顺序B G R,0~255,格式为(H,W,C)
img_original = cv2.imread(path)
img_original = cv2.resize(img_original, (200, 200), interpolation=cv2.INTER_CUBIC)#将原图转为200*200的图,插入方式为4*4像素领域的双三次插值。
print(img_original.shape)
for i in range(10):
transform = transforms.Compose([
transforms.
transforms.RandomHorizontalFlip(p=0.5), # 水平翻转
transforms.RandomGrayscale(p=0.5), # 随机灰度
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5), # 亮度,对比度,饱和度,色相
])
#CV格式转PIL
img = Image.fromarray(cv2.cvtColor(img_original, cv2.COLOR_BGR2RGB))#照片原来是BGR改为RGB
img = transform(img)
#PIL转CV格式
img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2BGR)
cv2.imwrite(str(i)+'.jpg',img)#在当前文件夹下,依次打印照片
'''
#2:transforms.ToTensor()的操作对象有PIL格式的图像以及numpy(即cv2读取的图像也可以)这两种。对象不能是tensor格式的,因为是要转换为tensor的。
import torchvision.transforms as trans
from PIL import Image
import cv2
trans1 = trans.ToTensor()
img = Image.open('dream.jpg')
print(img.size) # w, h宽和高
img_PIL_tensor = trans1(img)
print(img_PIL_tensor.size()) # c, h, w通道,高和宽
img = cv2.imread('dream.jpg')
print(img.shape) # h, w, c通道,宽和高
img_cv2_tensor = trans1(img)
print(img_cv2_tensor.size()) # c, h, w通道,高和宽
img = np.zeros([100,200,3]) # h, w, c通道,宽和高
img_np_tensor = trans1(img)
print(img_np_tensor.size()) # c, h, w torch.Size([3, 100, 200])
'''
运行结果为:
(1000, 930)
torch.Size([3, 930, 1000])
(930, 1000, 3)
torch.Size([3, 930, 1000])
torch.Size([3, 100, 200])
'''
6:torch.size()中定义的张量大小尺寸,类型
torch.zeros(size,out=none)返回一个由标量值0填充的张量,其形状由变量参数size定义。
size:定义输出张量形状的整数序列
out (Tensor, optional):输出张量
返回类型:一个张量,其标量值为0,形状与尺寸相同。输出为零点几。
代码实例
import torch
x = torch.zeros((5, 2, 3, 4))#x=一个batch=5,通道=2,h=3,w=4的以零为填充的张量
print(x.size())#打印x的尺寸
print(x)#打印x输出结果:
torch.Size([5, 2, 3, 4])
tensor([[[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]],
[[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]],
[[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]],
[[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]],
[[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]]])torch.ones(size,dim=0/1)返回一个由标量值1填充的张量,其形状由变量参数size定义。
dim = 0,列不变(按列-将当前列所有行数据-计算),指定的是行,那就是行变,理解成:针对每一列中,所有行之间的数据比较或者求和等操作,是每一行的比较,因为行是可变的。
dim = 1,行不变(按行-将当前行所有列数据-计算),指定的是列,那就是列变,理解成:针对每一行中,所有列之间的数据比较或者求和等操作,是每一行的比较,因为行是可变的。
torch.rand(size,out=none)定义一个填充的数均匀分布,随机张量(每次输出结果不同)
size(int):整数序列,定义了输出张量的形状
out:结果张量
import torch
#rand(*size, out=None, dtype=None)
t1 = torch.rand(2,3)#定义一个2*3的张量
print(t1,t1.type())#打印这个张量,并打印张量类型输出结果:

torch.randn(size,out=none)定义一个填充的数标准正态分布,随机张量(每次输出结果不同)
#randn(size, out=None, dtype=None)语法
t1 = torch.randn(2,3)
print(t1,t1.type())输出结果:

torch.randint(low=0,higt,size,out=none,dtype=none)
torch.randint_like(input,low=0,higt,dtype=none)
#randint(low=0, high, size, out=None, dtype=None)
#randint_like(input, low=0, high, dtype=None)
#整数范围[low, high)
t1 = torch.randint(1,4,(2,3,2)) #形状写成[2,3,2]也行
t2 = torch.randint_like(t1,4)
print(t1)
print(t2)
输出结果:

torch.randperm(n,out=none,dtype=torch.int64)输出一个长张量torch,没有random.shuffle
#y = torch.randperm(n) y是把1到n这些数随机打乱得到的一个数字序列
import torch
idx = torch.randperm(3)
a = torch.Tensor(4,2)
print(a)
print(idx,idx.type())
print(a[idx])
输出结果:

7:pytorch中的拼接函数
7.1torch.cat(inputs,dim=?)
输出的是张量,把多个tensor进行直接拼接,
参数:
inputs:待连接的张量序列,可以是任意相同张量类型的python序列
dim:选择的扩维,必须在0到len(inputs[0])长度之间,沿着此维连接张量序列。
x1=torch.tensor([[11,21,31],[21,31,41]],dtype=torch.int)
print(x1.shape)
x2=torch.tensor([[12,22,32],[22,32,42]],dtype=torch.int)
print(x2.shape)
#inputs是2个形状为2*3的矩阵
inputs=[x1,x2]
print(inputs)#打印俩个矩阵
y=torch.cat(inputs,dim=0)
print(y,y.shape,y.type())#打印cat后的张量,张量的大小,类型
y=torch.cat(inputs,dim=1)
print(y,y.shape,y.type())#
y=torch.cat(inputs,dim=2)
print(y,y.shape,y.type())#打印cat后的张量,张量的大小,类型
输出结果:

7.2torch.stack(inputs,dim=?)
使用stack可以保留两个信息:[1. 序列] 和 [2. 张量矩阵] 信息,属于【扩张再拼接】的函数
参数:
inputs:待连接的张量序列,list,tuple。
dim:选择的扩维,必须在0到输出长度之间。
import torch
t1 = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
t2 = torch.tensor([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
print(torch.stack((t1,t2),dim=0).shape)
print(torch.stack((t1,t2),dim=1).shape)
print(torch.stack((t1,t2),dim=2).shape)
print(torch.stack((t1,t2),dim=3).shape)
#如果dim大于输出张量的最大长度就会报错输出结果:

torch.stack和torch.cat的区别及对比:
(dim最多包括batch_size,channel,height,width这四项,对应下标0,1,2,3)
torch.stack和torch.cat都是用于拼接的,核心不同在于使用stack后,原来的张量会增加一维,比如把两个3 * 3(二维)的tensor用torch.stack在dim0拼接,拼接后的tensor的形状是2 * 3 * 3,也就是说每个3 * 3独自成了一个channel;
x1 = torch.tensor([[1,2,3], [4,5,6]])# x1.shape = tensor.size([2,3])
x2 = torch.tensor([[7,8,9], [10,11,12]])
x = [x1, x2]
print(x1.shape)
# print(len(c), c[1].shape)
print('沿第0维进行操作:')
y1 = torch.stack(x, dim=0)
y2 = torch.cat(x, dim=0)
print('y1:', y1.shape,'\n',y1)
print('y2:', y2.shape,'\n',y2)
print('沿第1维进行操作:')
y1 = torch.stack(x, dim=1)
y2 = torch.cat(x, dim=1)
print('y1:', y1.shape,'\n',y1)
print('y2:', y2.shape,'\n',y2)
输出结果:

和cat()函数不同的是,stack()函数进行拼接的时候会新增加一个维度。
8:torch.FloatTensor()
类型转换,将list,numpy转化为tensor
以list转tensor为例:
import torch
import numpy as np
#Eg1:输入一个1*2的list
print("案例1:")
print(torch.FloatTensor([1,2]))
#输出结果:tensor([1., 2.])
#Eg2:根据torch.Size()创建一个空tensor
print("案例2:")
a = torch.tensor([[1, 2], [3, 4]])
print(torch.FloatTensor(a.size()))
print(a.shape)
'''输出结果:
tensor([[1.4013e-45, 0.0000e+00],
[0.0000e+00, 0.0000e+00]])
torch.Size([2, 2])
'''
#Eg3:将一个list转为0维的张量26(标量)
print("案例3:")
w=torch.FloatTensor([0.1435, 0.1870, 0.1692, 0.1165, 0.1949, 0.1204, 0.1728, 0.1372, 0.1620,
0.1540, 0.1987, 0.1057, 0.1482, 0.1192, 0.1590, 0.1929, 0.1158, 0.1907,
0.1345, 0.1307, 0.1665, 0.1698, 0.1797, 0.1657, 0.1520, 0.1537])
print(torch.tensor(w.size()))
print(w.shape)
'''输出结果:tensor([26])
torch.Size([26])'''
#Eg4:将一个list转为26再对数据维度进行扩充,给指定位置加上维数为1,1*26(向量)
print("案例4:")
weights = torch.FloatTensor([0.1435, 0.1870, 0.1692, 0.1165, 0.1949, 0.1204, 0.1728, 0.1372, 0.1620,
0.1540, 0.1987, 0.1057, 0.1482, 0.1192, 0.1590, 0.1929, 0.1158, 0.1907,
0.1345, 0.1307, 0.1665, 0.1698, 0.1797, 0.1657, 0.1520, 0.1537]).unsqueeze(0)
print(torch.tensor(weights.size()))
print(weights.shape)
'''输出结果:tensor([ 1, 26])
torch.Size([1, 26])'''
#eg5:np.array([2,3])和torch.tensor([2,3])的区别
print("案例5:")
x = np.array([2,3]) #array([1, 2])
print("x是:",x) #[1 2]
print("x的类型是:",type(x))
#注意:numpy中没有x.type()的用法,只能使用type(x)
y = torch.tensor([2, 3]) # tensor([1, 2])
print("y是:",y) # tensor([1, 2]),注意,这里与numpy就不一样了!
print("y的类型是:",type(y))
print("y的类型是:",y.type()) # torch.LongTensor,注意:numpy中不可以这么写,会报错!!!
'''案例5:
x是: [2 3]
x的类型是: <class 'numpy.ndarray'>
y是: tensor([2, 3])
y的类型是: <class 'torch.Tensor'>
y的类型是: torch.LongTensor'''9.optimizer.zero_grad(),loss.backward()和optimizer.step()
在用pytorch训练模型时,通常会在遍历epochs的过程中依次用到optimizer.zero_grad(),loss.backward()和optimizer.step()三个函数,如下所示:
model = MyModel()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
for epoch in range(1, epochs):
for i, (inputs, labels) in enumerate(train_loader):
output= model(inputs)
loss = criterion(output, labels)
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()这三个函数的作用是先将梯度归零(optimizer.zero_grad()),然后反向传播计算得到每个参数的梯度值(loss.backward()),最后通过梯度下降执行一步参数更新(optimizer.step())
以SGD为例,torch.optim.SGD().step()源码如下:
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
return lossstep()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。
注意:optimizer只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
10.pytorch中定义的类理解【torch.nn】
10.1torch.nn.AdaptiveAvgPool2d自适应平均池化
在一个由几个输入平面组成的输入信号上应用二维自适应平均池化。
输出的尺寸为H x W,适用于任何输入尺寸。
输出特征的数量等于输入平面的数量。
import torch
import torch.nn as nn
'''# target output size of 5x7
m = nn.AdaptiveAvgPool2d((5, 7))
input = torch.randn(1, 64, 8, 9)
output = m(input)
# target output size of 7x7 (square)
m = nn.AdaptiveAvgPool2d(7)
input = torch.randn(1, 64, 10, 9)
output = m(input)
# target output size of 10x7
m = nn.AdaptiveAvgPool2d((None, 7))
input = torch.randn(1, 64, 10, 9)
output = m(input)'''
#如果输入的特征图是3*3*3,那么经过全局平均池化后,可以调节宽高为任意尺寸(这里设置为1*1)
#对于融合网络输入和输出对不上用全局池化有很大帮助
#可通过全局平均池化调节特征图大小
#通过1*1卷积或0填充调整通道数大小
m1 = nn.AdaptiveAvgPool2d((1, 1))
input1 = torch.randn(1, 3, 3, 3)
output1 = m1(input1)
print(output1.shape)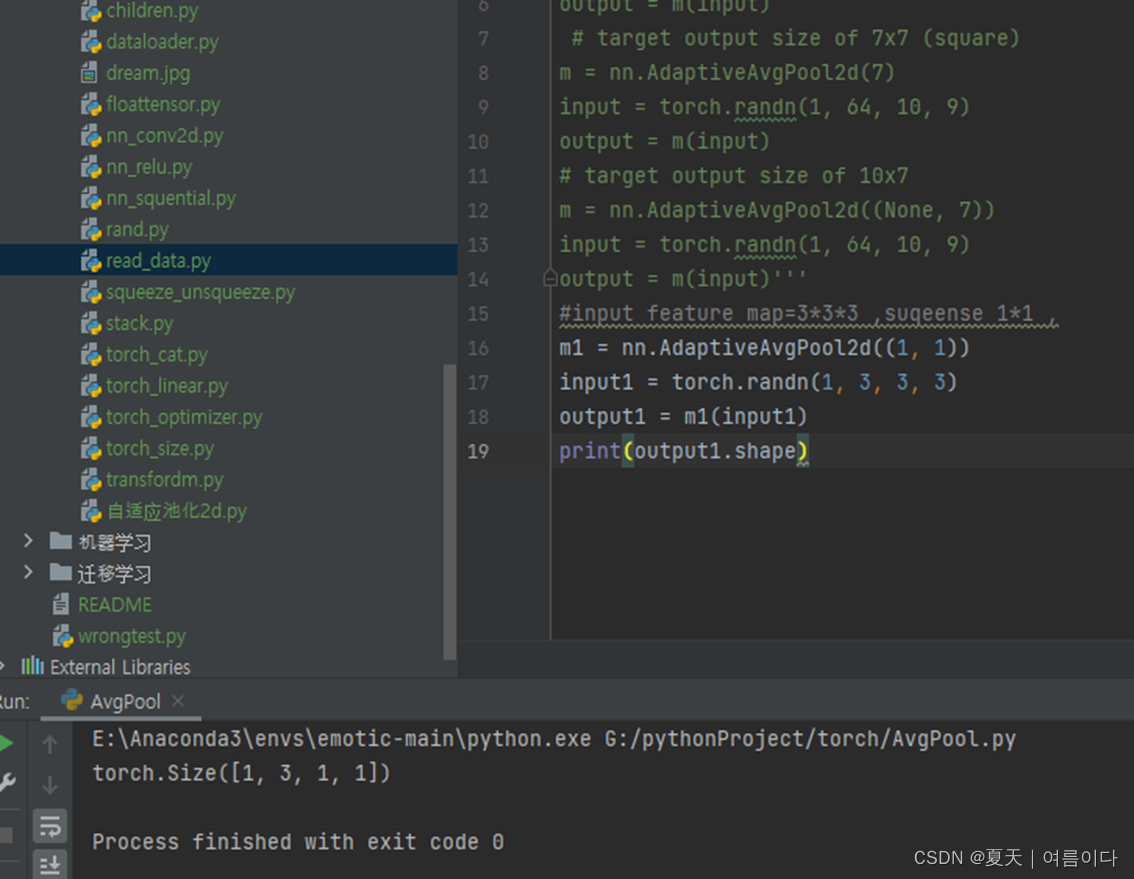
10.2 torch.nn.Linear

在神经网络中,我们一般输入都是二维的tensor矩阵(batch,input_size),但其实输入的维度是不做限制的。如果是三维的输入,会将前两维的数据先乘一起,然后在做计算,实际上还是单层神经网络的计算。这个函数就是改变最后一维,也就是数据的特征维度,通过调整output_size的尺寸来扩张或者是收缩特征。
对输入的数据进行线性变换 math:`y = xA^T + b`
参数: in_features: 每个输入样本的大小
out_features: 每个输出样本的大小
bias: 如果设置为 "False",该层将不学习加法偏置。默认:`True'`。
属性: weight:形状模块的可学习权重等
import torch
from torch import nn
#****************2维情况下矩阵相乘****************
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())
#结果torch.Size([128, 30])
'''
#举例1
m1 = nn.Linear(2, 3)
input1 = torch.randn(4, 5)
output1 = m1(input1)
print(output1.size())
#举例1结果:RuntimeError: mat1 and mat2 shapes cannot be multiplied (4x5 and 2x3) mat1和mat2的形状不能相乘(4x5和2x3)。
#所以在linear上第一个值要和输入的第二个值相同(矩阵乘法)'''
#举例2
m2 = nn.Linear(2, 3)
input2 = torch.randn(4, 2)
output2 = m2(input2)
print(output2.size())
print(output2)
#结果得到一个4*3的大小
#****************3维情况下****************
'''
#举例3
m3 = nn.Linear(3, 3)
input3 = torch.randn(3,1,1)
output3 = m3(input3)
print(output3.size())
#RuntimeError: mat1 and mat2 shapes cannot be multiplied (3x1 and 3x3)mat1和mat2的形状不能相乘(3x1 and 3x3)
'''
'''#举例4
m4 = nn.Linear(3,1)#linear(输入特征,输出特征)
input4 = torch.randn(3,1,1)
output4 = m4(input4)
print(output4.size())
#RuntimeError: mat1和mat2的形状不能相乘(3x1 and 3x1)'''
#举例5
m5 = nn.Linear(20,50)#linear(输入特征a,输出特征b)
input5 = torch.randn(4,5,50)#randn(大小c*d=4*5=20,输出e)
output5 = m5(input5)
print(output5.size())
#举例6
import torch.nn as nn
import torch
import numpy as np
X_2dim=np.array([[1,2,3,4],[2,3,45,6]]) #二维数组(2,4)
X_3dim=np.array([[[1,2,3,4],[2,3,4,6],[3,4,5,5]],[[1,1,5,6],[0,0,6,5],[3,3,5,7]]]) # 三维数组(2,3,4)
#转成tensor的形式,因为Linear要求输入是float类型,因此还需要转成float32
X2_tensor=torch.from_numpy(X_2dim.astype(np.float32))
X3_tensor=torch.from_numpy(X_3dim.astype(np.float32))
#用来改变最后数组最后一维的维度
#用来缩小或者扩展特征维度
emdeding=nn.Linear(4,3)
Y2=emdeding(X2_tensor)
Y3=emdeding(X3_tensor)
#输出
print(Y2)
print(Y3)
#Y2
tensor([[ 0.6468, 0.6430, 0.4253],
[-2.9180, -3.3393, 6.3075]], grad_fn=<AddmmBackward>)
#Y3
tensor([[[0.6468, 0.6430, 0.4253],
[1.0562, 0.8781, 0.6216],
[0.7615, 0.3500, 0.7439]],
[[1.1430, 0.6462, 0.8132],
[0.7745, 0.4598, 0.9190],
[1.4516, 0.5589, 0.8545]]], grad_fn=<AddBackward0>)
#总结:linear上的输入特征和输出特征应和输入的特征相同
#
10.3.torch.nn.gre()多层门控循环单元
语法(官网详情)
torch.nn.GRU(self, input_size, hidden_size, num_layers=1,
bias=True, batch_first=False, dropout=0.0, bidirectional=False,
device=None, dtype=None)
将多层门控循环单元 (GRU) RNN 应用于输入序列。input_size参数表示输入数据的特征数,hidden_size参数表示GRU模型的隐藏层大小,num_layers参数表示GRU模型的层数。在forward方法中,首先初始化隐藏层的状态h0,然后通过GRU层处理输入数据x,并将最后一个时刻的输出作为模型的输出。
参数如下

代码示例
import torch
import torch.nn as nn
# 假如10是特征输入大小,20是隐藏层大小,2是层数
rnn = nn.GRU(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
output, hn = rnn(input, h0)
# 输出时
print("output:",output,output.shape)
print("hn:",hn,hn.shape)
11.pytorch自中定义数据集相关
11.1.__getitem__
当一个python类中定义了__getitem__函数,则其实例对象能够通过下标来进行索引数据。
结合pytorch封装并读取batch数据
import torch
import numpy as np
from torch.utils.data import Dataset
# 创建MyDataset类
class MyDataset(Dataset):
def __init__(self, x, y):
self.data = torch.from_numpy(x).float()
self.label = torch.LongTensor(y)
def __getitem__(self, idx):
return self.data[idx], self.label[idx], idx
def __len__(self):
return len(self.data)
Train_data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
Train_label = np.array([10, 11, 12, 13])
TrainDataset = MyDataset(Train_data, Train_label) # 创建实例对象
print('len:', len(TrainDataset))
# 创建DataLoader
loader = torch.utils.data.DataLoader(
dataset=TrainDataset,
batch_size=2,
shuffle=False,
num_workers=0,
drop_last=False)
# 按batchsize打印数据
for batch_idx, (data, label, index) in enumerate(loader):
print('batch_idx:',batch_idx, '\ndata:',data, '\nlabel:',label, '\nindex:',index)
print('---------') 
11.2.get_statistics(variable_name=None)
参数
- variable_name: 可选字符串。多维栅格数据集的变量名。如果未指定变量且栅格是多维的,则将返回第一个变量的统计信息。
返回
一个字典。栅格或给定变量的统计数据。
get_statistics 方法检索栅格的统计数据。
def _get_statistics(self):
train_set = torchvision.datasets.CIFAR10(root='./cifar', train=True, download=True, transform=transforms.ToTensor())
data = torch.cat([d[0] for d in DataLoader(train_set)])
return data.mean(dim=[0, 2, 3]), data.std(dim=[0, 2, 3])12.torch中关于维度的常用函数总结
12.1.torch.unsqueeze(input, dim, out=None)
参数:
tensor (Tensor)– 输入张量dim (int)– 插入维度的索引out (Tensor, optional)– 结果张量
作用:扩展维度
返回一个新的张量,对输入的既定位置插入维度 1
- 注意: 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。(如果dim为负,则将会被转化dim+input.dim()+1)
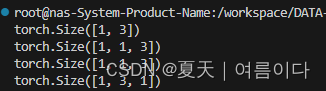
案例:定义一个一维矩阵,使用unsqueeze()函数进行扩张维度,a为矩阵名称,0,1,2,代表增加纬度位置。
import torch
a=torch.randn(1,3)
print(a.shape)
b=torch.unsqueeze(a,0)
print(b.shape)
c=torch.unsqueeze(a,1)
print(c.shape)
d=torch.unsqueeze(a,2)
print(d.shape)运行结果:
# 代码中可能见到的使用类型
# 在0维处加一维
x_tst = stn_tst.unsqueeze(0)
# 在1维处加一维
analysis_filter = torch.from_numpy(h_analysis).float().unsqueeze(1).cuda(device)
unsqueeze_和 unsqueeze 的区别
unsqueeze_ 和 unsqueeze 实现一样的功能,区别在于 unsqueeze_ 是 in_place 操作,即 unsqueeze 不会对使用 unsqueeze 的 tensor 进行改变,想要获取 unsqueeze 后的值必须赋予个新值, unsqueeze_ 则会对自己改变。
















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











