






编者
倾向得分的全套视频,如果你有兴趣可以观看哈
由于某些研究的人群或终点,不可以进行或者无法实行随机临床试验,从临床实践环境中获得的证据是比较不同治疗方法的重要的信息来源。
不同于临床试验通过随机化来确保不同治疗组患者特征具有可比性,观察性研究必须尝试对差异(及混杂)进行调整。这通常通过总结治疗组之间患者特征差异的倾向评分(PS)来解决。
PS是根据测量的协变量,每个个体被分配接受感兴趣治疗的概率。是一个用于综合需要调整变量的分数,而综合完之后我们要用传统的方法去调整倾向性评分,常用的方法有4种,匹配、加权、调整以及分层。
而4种方法各有千秋,要说其中最强的方法,必然是倾向性评分加权法。准确的来说,应该是重叠加权(Overlap Weighting,OW)。
医学顶刊《JAMA》曾发表过一篇介绍重叠加权的统计和方法指南,题为:“Overlap Weighting A Propensity Score Method That Mimics Attributes of a Randomized Clinical Trial”。

该文章引用了Mehta等人发表在《JAMA Cardiology》(医学一区,IF=24)的一篇题为:“Association of Use of Angiotensin-Converting Enzyme Inhibitors and Angiotensin II Receptor Blockers With Testing Positive for Coronavirus Disease 2019 (COVID-19)”的重叠倾向评分加权的回顾性队列研究,详细介绍了重叠加权的优势和局限性,以及分析作者为什么使用重叠加权方法和如何解释加权后的结果,并给出一些建议。

原文PDF获取方式:本公众号回复关键词“原文” |
下面我们一起来看看重叠加权的魅力!
为什么要用重叠加权?
重叠加权(OW)是一种倾向性评分(PS)方法,旨在模拟随机临床试验(RCT)的重要属性:临床相关的目标人群、协变量均衡和精确度。
目标人群是指得出结论的患者群体;
均衡是指在治疗过程中患者特征的相似性,这是避免偏倚的重要条件;
精确度表示对治疗和相关结果之间关联的估计的确定性,更精确的估计有更窄的置信区间(CIs)和更强的统计效能。
虽然经典的PS法的逆概率加权和匹配可以调整测量特征的差异,但是这些方法在目标人群、均衡和精度方面存在潜在的局限性。
倾向性评分匹配(PSM)通过各种卡钳值配对,邻近配对等方法能把两组的目标人群很好配在一起。可是匹配却面临着有可能匹配不上以及更重要的样本量丢失这些问题,这也是为什么倾向性匹配只能应用在对照组比暴露组人群样本大很多的情况下。
经典的倾向性加权(IPTW)则不会舍弃任何一个样本,这使得它在样本量较少的研究中也能使用。但是它对治疗组的权重为1/PS,未治疗组为1/(1−PS),使得特征不充分的个体在权重分析中计算更多。IPTW有着极端值影响结果这种问题,虽然后来衍生出了IPTW trimming(截掉评分加权后的两边的极值),但这种方法却不能保证截的位置是合适的,而且样本量也减少了。
在观察性研究的数据中,治疗组的初始差异或许会很大,在这种情况下这些方法可能会改变目标人群,无法达到良好的平衡,或使精度大大降低。
但是,OW通过为每个患者分配与该患者属于相反治疗组的概率成比例的权重,克服了这些限制。具体来说:
接受治疗的患者以未接受治疗的概率(1−PS)为权重
而未接受治疗的患者以接受治疗的概率(PS)为权重。
对于极端的PS值,这些权重较小,使得PS接近于1或者0的离群值不会像IPTW那样主导结果和降低精度。而那些人群特征在两种治疗方法中都兼容的患者则相对贡献更大。由此产生的目标人群模拟了实用性随机试验的特点,即高度包容,没有从可用样本中排除任何研究参与者,但强调在临床均衡情况下对患者进行比较。
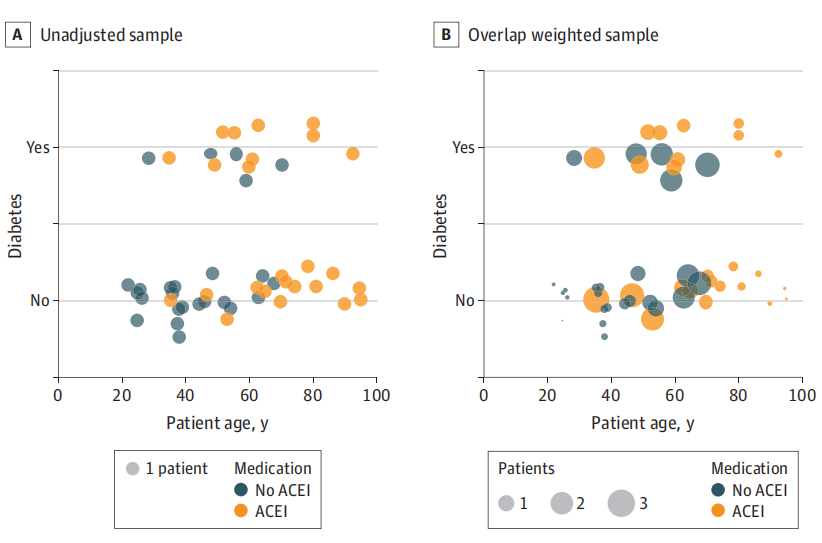
图 重叠加权对50例不同年龄、不同糖尿病状态模拟患者相对贡献的影响
气泡大小反映了每个患者对分析的相对贡献。
A,每个病人只代表他们自己。接受血管紧张素转换酶抑制剂(ACEIs)治疗的患者年龄较大,更容易患糖尿病。
B,重叠加权后,有的患者最多代表3个患者,有的患者代表少于1个患者。
此外,OW具有理想的统计性质。当通过逻辑回归估计PS时,它导致每个测量协变量的平均值精确平衡,并被证明可以优化一大类PS加权方法(包括IPTW和匹配的模拟)中治疗和结果之间估计关联的精度。如果不需要调整,重叠加权可以像随机化一样有效。
当然,OW方法也有一定的局限性。
与所有倾向性评分方法一样,OW不能对PS模型中未测量和未纳入的患者特征进行校正。从文献中识别混杂变量,尝试将其纳入分析,并识别由于未测量因素而产生的潜在偏倚是很重要的。对于两组之间患者特征初始不平衡的数据的应用,OW的结果与IPTW是相似的。当比较组初始差异很大时,重叠加权的优势最大。
为什么Mehta等人在研究中使用重叠加权?
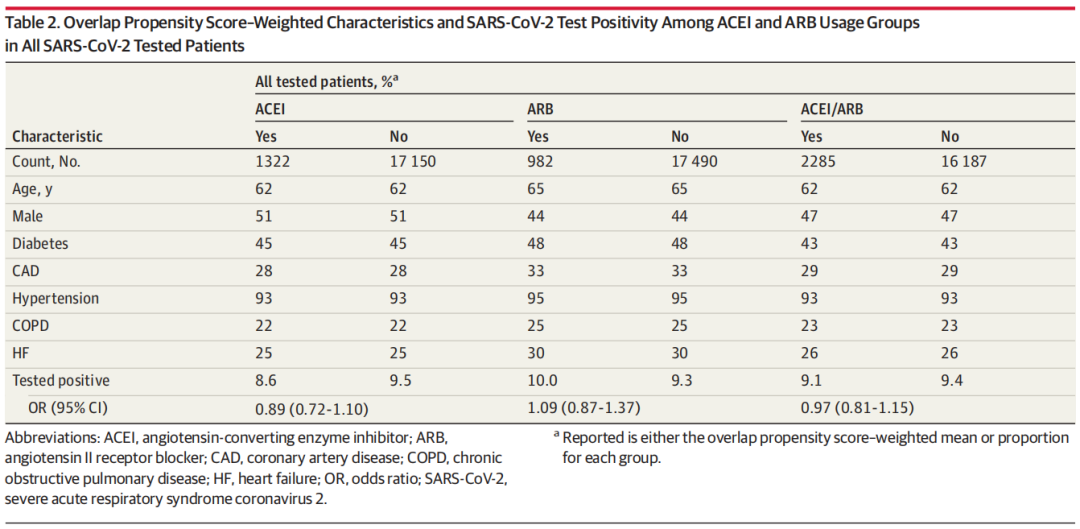
Mehta等人在2020年3月8日至2020年4月12日期间在克利夫兰诊所卫生系统接受检测的18 472名患者中,评估了血管紧张素转换酶抑制剂(ACEIs)、血管紧张素II受体阻阻剂(ARBs)或两者与严重急性呼吸综合征冠状病毒2 (SARS-CoV-2)检测阳性之间的关系(SARS-CoV-2是导致2019冠状病毒病(COVID-19)的病毒)。
在2285例接受过ACEIs/ARBs治疗的患者和16187例未接受ACEIs/ARBs治疗的患者的比较中,采用基于PS的重叠加权来调整混杂因素。结果显示,重叠倾向评分加权显示,ACEIs/ARBs使用与COVID-19检测阳性无显著关联(重叠倾向评分加权优势比:0.97;95% CI:0.81-1.15)。
Mehta等人使用重叠加权来实现良好的平衡,并将估计ACEIs/ARBs治疗与SARS-CoV-2阳性检测结果之间关联的方差最小化。通过报告接受ACEIs/ARBs组和未接受ACEIs/ arb组的重叠加权协变量均值(或比例)来证明均衡。加权后各组间无差异。
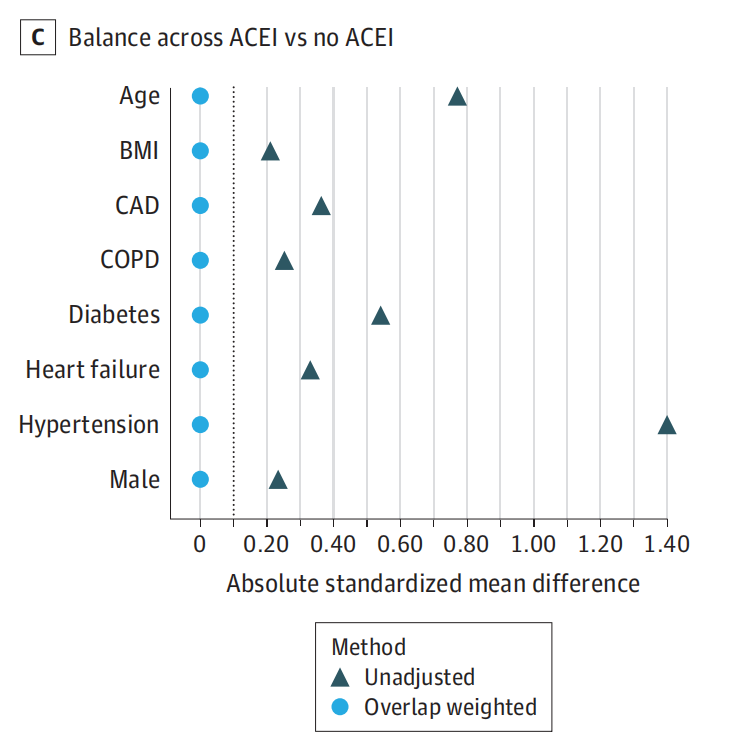
协变量列表包括与接受ACEIs/ARBs治疗相关的风险因素,以及与COVID-19检测阳性相关的危险因素。调整后的治疗比较用窄CIs进行估计,为无效结果提供了强有力的证据。
应如何解释重叠加权的结果?
重叠加权的主要研究结果可以像其他PS方法一样进行解释。
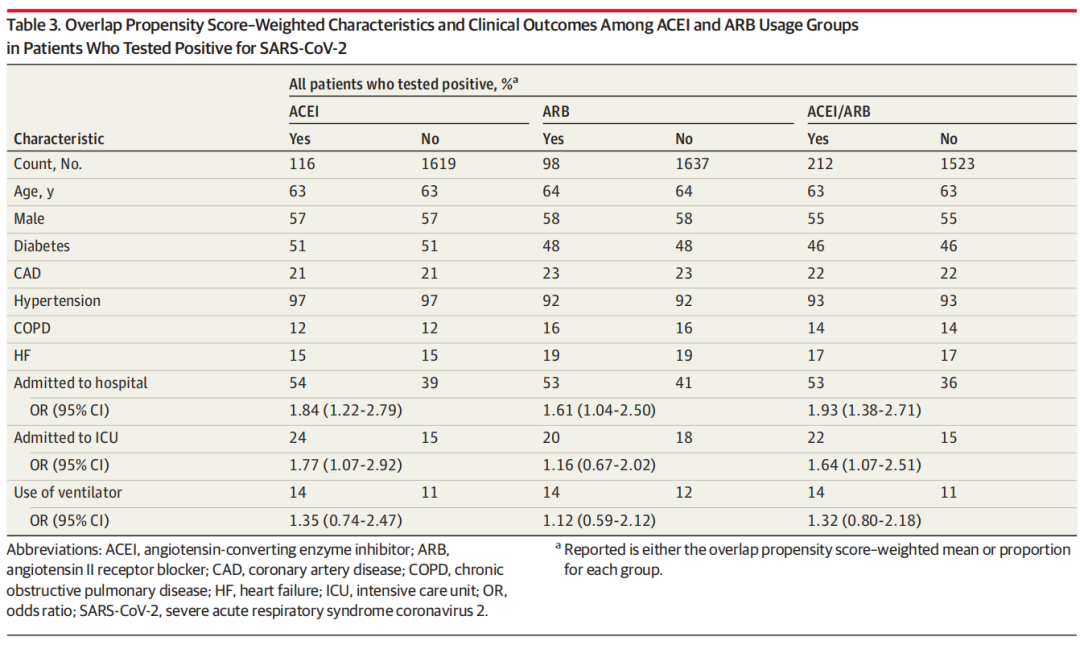
在这项研究中,调整心血管危险因素的差异后,接受ACEIs/ arb治疗的患者中,9.1%的患者检测出SARS-CoV-2阳性,而未接受ACEIs/ arb治疗的患者中,这一比例为9.4%(优势比为0.97 [95% CI, 0.81-1.15])。
对于是否接受ACEIs/ARBs治疗处于平衡的患者群体而言,这些估计值是衡量ACEIs/ARBs治疗与检测阳性之间的关系的指标,并且通过重叠加权使所有测量的协变量在治疗中是相似的。接受ACEIs/ARBs治疗的患者与未接受ACEIs/ARBs治疗的患者之间由于未测量的差异而导致的偏倚不能排除。
评估重叠加权分析结果时的注意事项
当通过logistic回归估计PS时,OW在每一个测量的协变量的平均值上创造了精确的平衡,这对减少偏倚特别重要。然而,均值平衡可能无法像上述一样,对该变量的混杂因素进行完全校正。因此,还应额外提供OW后样本的基线特征表。此表包括协变量均值、中位数、四分位间距或任何其他对理解总体有用的统计数据。
这种方法将有助于证明,在目标人群、均衡和精确性方面,OW分析是模拟随机临床试验的最佳方法。
原文PDF获取方式:本公众号回复关键词“原文” |
后记
倾向得分的全套视频,如果你有兴趣可以观看哈
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: |

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









