







 本文详细介绍了时间序列模型的概念,包括平稳过程、ARIMA模型、移动平均模型、协整与误差修正模型等。通过ADF检验确定序列平稳性,并利用信息准则选择模型阶数。此外,还探讨了非平稳数据处理、协整检验方法如EG和Johansen检验,以及误差修正模型在存在协整关系时的应用。最后,文章讨论了VAR模型、Granger因果检验和GARCH模型在处理金融时间序列中的应用,展示了模型识别、估计、诊断和预测的步骤。
本文详细介绍了时间序列模型的概念,包括平稳过程、ARIMA模型、移动平均模型、协整与误差修正模型等。通过ADF检验确定序列平稳性,并利用信息准则选择模型阶数。此外,还探讨了非平稳数据处理、协整检验方法如EG和Johansen检验,以及误差修正模型在存在协整关系时的应用。最后,文章讨论了VAR模型、Granger因果检验和GARCH模型在处理金融时间序列中的应用,展示了模型识别、估计、诊断和预测的步骤。
时间序列模型
文章目录
- 时间序列模型
- 动态模型
- 一、ARIMA模型的概念
- 二、移动平均过程
- 三、自回归(AR)过程
- 四、自回归移动平均 ( A R M A ) (\mathbf{A R M A}) (ARMA) 过程
- 五、自回归单整移动平均(ARIMA)过程
- 六、AR、MA过程的相互转化
- 七、ARIMA模型的识别、估计、诊断、预测
- 补充:
- 实验一:MA模型的构建以及预测
- 实验二:AR模型的构建以及预测
- 实验三:非平稳序列 ARIMA模型 ARIMA(p,d,q)
- 八、VAR(Vector Autoregressive)模型
- 九、Granger因果检验
- 十、联立方程模型
- 十一、事件研究法
- 十二、GARCH模型(广义自回归条件异方差模型)
什么是平稳过程?
- 严平稳: 变量的分布不随时间变化而变化。(即不同时刻的随机变量的各阶矩都跟时间无关)
- 弱平稳: 均值、方差和任意滞后阶k的协方差 γ k \gamma_k γk (一阶矩和二阶矩)都不随时间变化而变化。
- 白噪声: 随机过程服从的分布不随时间改变且均值为0,方差为常数,每个观测值都和其他时刻的值不相关。(特殊的弱平稳过程)
- ACF: 序列 { Y t } \{Y_t\} {Yt} 的 j j j 阶自相关函数 A C F j ACF_j ACFj 为 j j j 阶协方差除以其方差,衡量的是 Y t Y_t Yt 和 Y t − j Y_{t-j} Yt−j 之间总的相关关系(直接相关+由于中间变量引起的间接相关)。
- PACF: j j j 阶偏自相关函数 P A C F j PACF_j PACFj 可以度量在剔除 Y t Y_t Yt 和 Y t − j Y_{t-j} Yt−j 之间的滞后项的影响之后的两者之间的相关性。
- 伪回归(Spurious Regression): 当我们将一个随机游走的时间序列数据(即非平稳的时间序列)对另一个随机游走的时间序列进行回归时,极有可能会出现极为显著的回归结果(极高的 R 2 R^2 R2 和 t t t 统计量)。而事实上,时间序列的高度相关仅仅是因为两者同时随时间有向上或向下的变动趋势,并没有真正的联系。
信息准则(information criteria)
信息准则包含两个部分:一部分是由残差平方和构成的方程,另一部分是对再增加滞后项而减少了自由度的惩罚。
-
Akaike 信息准则 A I C = log ( σ ^ 2 ) + 2 k T \quad \mathrm{AIC}=\log \left(\hat{\sigma}^{2}\right)+\frac{2 \mathrm{k}}{\mathrm{T}} AIC=log(σ^2)+T2k
-
Schwarz 信息准则 S C = log ( σ ^ 2 ) + k T log T \quad \mathrm{SC}=\log \left(\hat{\sigma}^{2}\right)+\frac{\mathrm{k}}{\mathrm{T}} \log \mathrm{T} SC=log(σ^2)+TklogT
-
Hannan-Quinn 信息准则 H Q I C = log ( σ ^ 2 ) + 2 k T log ( log T ) \quad \mathrm{HQIC}=\log \left(\hat{\sigma}^{2}\right)+\frac{2 \mathrm{k}}{\mathrm{T}} \log (\log \mathrm{T}) HQIC=log(σ^2)+T2klog(logT)
其中 σ ^ 2 \hat{\sigma}^{2} σ^2 为残差平方, k = p + q + 1 \mathrm{k}=\mathrm{p}+\mathrm{q}+1 k=p+q+1 是所有估计参数的个数,T为样本容量。
基本定义:
-
自回归过程Autoregressive model: 变量 Y Y Y 的当前值依赖于它之前若干期的值再加上一个误差项。
- Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + V t \mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\phi_{1} \mathrm{Y}_{\mathrm{t}-1}+\phi_{2} Y_{\mathrm{t}-2}+\ldots+\phi_{\mathrm{p}} Y_{\mathrm{t}-\mathrm{p}}+\mathrm{V}_{\mathrm{t}} Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+Vt
- 平稳性的条件:特征方程的根落在单位圆外。
- AP§ 过程的 PACF(偏自相关函数) 是p阶截尾的,PACF的非零个数等于p。(原因:AR模型的每个偏回归系数 ϕ t \phi_t ϕt = 相应阶数的 P A C F t PACF_t PACFt)
- AP§ 过程的 ACF 是无限拖尾的。
-
移动平均模型: 可以看作是几个白噪声过程的线性组合。
- Y t = u + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 + … + θ q ε t − q \mathrm{Y}_{\mathrm{t}}=\mathrm{u}+\varepsilon_{\mathrm{t}}+\theta_{1} \varepsilon_{\mathrm{t}-1}+\theta_{2} \varepsilon_{\mathrm{t}-2}+\ldots+\theta_{\mathrm{q}} \varepsilon_{\mathrm{t}-\mathrm{q}} Yt=u+εt+θ1εt−1+θ2εt−2+…+θqεt−q 其中 u \mathrm{u} u 为常数项。
- 天然平稳的时间序列模型。
- MA(q)过程的 ACF(自相关函数)是q阶截尾的,ACF的非零个数等于MA(q)模型的阶数。
- MA(q)过程的 PACF 是无限拖尾的。
-
AR过程和MA过程的相互转化:
- 平稳的AR§过程可以被转化为一个MA( ∞ \infin ∞)过程。
- 具有可逆的MA(q)过程可以转化为AR( ∞ \infin ∞)过程。
-
ARMA(p,q)过程
- Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + θ 1 ε t − 1 + θ 2 ε t − 2 + … + θ q ε t − q + ε t \mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\phi_{1} \mathrm{Y}_{\mathrm{t}-1}+\phi_{2} \mathrm{Y}_{\mathrm{t}-2}+\ldots+\phi_{\mathrm{p}} \mathrm{Y}_{\mathrm{t}-\mathrm{p}}+\theta_{1} \varepsilon_{\mathrm{t}-1}+\theta_{2} \varepsilon_{\mathrm{t}-2}+\ldots+\theta_{\mathrm{q}} \varepsilon_{\mathrm{t}-\mathrm{q}}+\varepsilon_{\mathrm{t}} Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+θ1εt−1+θ2εt−2+…+θqεt−q+εt
- 自相关系数和偏自相关系数都是拖尾的。
- 通过信息准则对ARMA(p,q)进行的 p,q 定阶,信息准则越小,模型预测效果越好。
-
ARIMA过程的概念
- 如果序列 { Y t } \{Y_t\} {Yt} 经过d次差分得到平稳序列 { W t } \{W_t\} {Wt} ,用ARMA(p, q)过程对 { W t } \{W_t\} {Wt} 建立模型,则 { Y t } \{Y_t\} {Yt} 为(p, d, q)阶自回归单整移动平均过程,简记为ARIMA(p,d,q)。
-
φ
(
L
)
△
d
Y
t
=
c
+
θ
(
L
)
ε
t
\varphi(\boldsymbol{L}) \triangle^{d} \boldsymbol{Y}_{\boldsymbol{t}}=\boldsymbol{c}+\boldsymbol{\theta}(\boldsymbol{L}) \boldsymbol{\varepsilon}_{\boldsymbol{t}}
φ(L)△dYt=c+θ(L)εt
经过d阶差分得到的平稳序列 △ d Y t \triangle^{d} Y_{t} △dYt 也可能单纯是一个 AR§ 或 MA(q) 过程。- 此时可以称 Y t Y_{t} Yt 为 ( p , d ) (p, d) (p,d) 阶单整自回归过程, 记为 A R I ( p , d , 0 ) \mathrm{ARI}(\mathrm{p}, \mathrm{d}, 0) ARI(p,d,0)。
- 或称 Y t Y_{t} Yt 为阶 ( d , q ) (d,q) (d,q) 阶单整移动平均过程,记为 I M A ( 0 , d , q ) \mathrm{IMA}(0,\mathrm{d}, \mathrm{q}) IMA(0,d,q)。
- ARIMA(p,d,q) 模型和 ARMA(p,q) 模型类似,但对模型进行定阶时,我们首先需要对非平稳时间序列进行一次或多次差分来确定。
-
静态预测: 在预测时如果需要用到滞后期的数据,用真实数据带入。
-
动态预测: 在预测时如果需要用到滞后期的数据,则用先前的预测数据带入。
-
ARCH(autoregressive conditional heteroscedasticity): 自回归条件异方差模型,反映了随机过程的一种特性:即 方差 随时间变化而变化(time varying) ,且具有 波动性(volatility) 和 丛集性(clustering) 。
-
内生变量: 由模型系统决定其取值的变量。
-
外生变量: 由模型系统以外的因素决定其取值的变量。
-
前定变量: 独立于变量所在方程当期和未来各期随机误差项的变量。
一、平稳性检验的具体方法
Y t = ρ Y t − 1 + u t Y_t=\rho Y_{t-1}+u_t Yt=ρYt−1+ut
u t u_t ut 为白噪声(零均值、恒定方差、非自相关)的随机误差项
通过不断迭代可以得到:
Y
t
=
ρ
T
+
1
Y
t
−
T
+
ρ
u
t
−
1
+
ρ
2
u
t
−
2
+
…
+
ρ
T
u
t
−
T
+
u
t
\begin{aligned} Y_{t}=\rho^{\mathrm{T}+1} Y_{t-\mathrm{T}}+\rho u_{t-1}+\rho^{2} u_{t-2}+\ldots+\rho^{\mathrm{T}} u_{t-\mathrm{T}}+u_{t} \end{aligned}
Yt=ρT+1Yt−T+ρut−1+ρ2ut−2+…+ρTut−T+ut
- 若 ρ < 1 \rho<1 ρ<1 ,则当 T → ∞ T \to \infty T→∞ 时, ρ T → 0 \rho^{T} \to 0 ρT→0 ,即对序列的冲击将随着时间的推移其影响逐渐减弱,此时序列是稳定的。
- 若 ρ > 1 \rho>1 ρ>1 ,则当 T → ∞ T \to \infty T→∞ 时, ρ T → ∞ \rho^{T} \to \infty ρT→∞ ,即对序列的冲击随着时间的推移其影响反而是逐渐增大的,很显然,此时序列是不稳定的。但是相关性系数不会大于1,因此这种情况不考虑。
- 若 ρ = 1 \rho=1 ρ=1 ,则当 T → ∞ T \to \infty T→∞ 时, ρ T = 1 \rho^{T}=1 ρT=1 ,即对序列的冲击随着时间的推移其影响是不变的,很显然,序列也是不稳定的。
DF检验相当于对其系数的显著性检验,所建立的零假设是:
H
0
:
ρ
=
1
\begin{aligned} H_0:\rho=1 \end{aligned}
H0:ρ=1
- 如果拒绝零假设,则称 Y t Y_t Yt 没有单位根,此时 Y t Y_t Yt 是平稳的。
- 如果不能拒绝零假设,我们就说 Y t Y_t Yt 具有单位根,此时 Y t Y_t Yt 被称为随机游走序列(random walk series)是不稳定的。
Δ Y t = ( ρ − 1 ) Y t − 1 + u t = δ Y t − 1 + u t \Delta Y_{t}=(\rho-1)Y_{t-1}+u_{t}=\delta Y_{t-1}+u_{t} ΔYt=(ρ−1)Yt−1+ut=δYt−1+ut
其中
Δ
Y
t
=
Y
t
−
Y
t
−
1
\Delta Y_{t}=Y_t-Y_{t-1}
ΔYt=Yt−Yt−1。此时的零假设变为:
H
0
:
δ
=
0
\begin{aligned} H_0:\delta=0 \end{aligned}
H0:δ=0
- 如果不能拒绝零假设,则 Δ Y t = u t \Delta Y_t=u_t ΔYt=ut 是一个平稳序列,即一阶差分后是一个平稳序列,此时我们称一阶单整过程(integrated of order 1)序列,记为 I ( 1 ) I(1) I(1) 。
- I ( 1 ) I(1) I(1) 过程在金融、经济时间序列数据中是最普遍的,而 I ( 0 ) I(0) I(0) 则表示平稳时间序列。
DF检验模型
从理论与应用的角度,DF检验的检验模型有如下的三个:
Y
t
=
(
1
+
δ
)
Y
t
−
1
+
u
t
即
Δ
Y
t
=
δ
Y
t
−
1
+
u
t
Y
t
=
β
1
+
(
1
+
δ
)
Y
t
−
1
+
u
t
即
Δ
Y
t
=
β
1
+
δ
Y
t
−
1
+
u
t
Y
t
=
β
1
+
β
2
t
+
(
1
+
δ
)
Y
t
−
1
+
u
t
即
Δ
Y
t
=
β
1
+
β
2
t
+
δ
Y
t
−
1
+
u
t
\begin{array}{l} Y_{t}=(1+\delta) Y_{t-1}+u_{t} \text { 即 } \Delta Y_{t}=\delta Y_{t-1}+u_{t}\\ Y_{t}=\beta_{1}+(1+\delta) Y_{t-1}+u_{t} \text { 即 } \Delta Y_{t}=\beta_{1}+\delta Y_{t-1}+u_{t}\\ Y_{t}=\beta_{1}+\beta_{2} t+(1+\delta) Y_{t-1}+u_{t} \text { 即 } \Delta Y_{t}=\beta_{1}+\beta_{2} t+\delta Y_{t-1}+u_{t} \end{array}
Yt=(1+δ)Yt−1+ut 即 ΔYt=δYt−1+utYt=β1+(1+δ)Yt−1+ut 即 ΔYt=β1+δYt−1+utYt=β1+β2t+(1+δ)Yt−1+ut 即 ΔYt=β1+β2t+δYt−1+ut
β
1
\beta_1
β1 :漂移项
β 2 t \beta_2t β2t:趋势项
如果误差项是自相关的,就增加
Δ
Y
t
\Delta Y_t
ΔYt 滞后项,修改如下,建立在下式基础上的DF检验又被称为增广的DF检验(augmented Dickey-Fuller,简记ADF)。
Δ
Y
t
=
β
1
+
β
2
t
+
δ
Y
t
−
1
+
α
i
∑
i
=
1
m
Δ
Y
t
−
i
+
ε
t
\begin{aligned} \Delta Y_{t}=\beta_{1}+\beta_{2} t+\delta Y_{t-1}+\alpha_{i} \sum_{i=1}^{m} \Delta Y_{t-i}+\varepsilon_{t} \end{aligned}
ΔYt=β1+β2t+δYt−1+αii=1∑mΔYt−i+εt
ADF检验模型的确定
- 可以通过考察数据图形以此来判断检验模型是否应该包含常数项(漂移项)和时间趋势项。
- 其次,我们来看如何判断滞后项数m,我们可以用以下两种常用的方法:
- 渐进 t t t 检验。该种方法是首先选择一个较大的m值,然后用 t t t 检验确定系数是否显著,如果是显著的,则选择滞后项数为m;如果不显著,则减少m直到对应的系数值是显著的。
- 信息准则。常用的信息准则有AIC信息准则、SC信息准则,一般而言,我们选择给出了最小信息准则值的m值。
ADF/PP检验模型的缺点
在小样本情况下,很难区别 ρ = 0.95 \rho=0.95 ρ=0.95 和 ρ = 1 \rho=1 ρ=1
实验
Step1:绘图

Step2:ADF



在5%的显著性水平下,p值为12.44%,大于5%,所以不拒绝原假设 H 0 : ρ = 1 H_0:\rho=1 H0:ρ=1 ,所以不能认为logSZ为平稳序列
Step3:做差分


在5%的显著性水平下,p值远小于5%,所以拒绝原假设 H 0 : ρ = 1 H_0:\rho=1 H0:ρ=1 ,所以认为SZ的变化率(差分一次后的logSZ)为平稳序列
二、非平稳性数据的处理
一般是通过差分处理来消除数据的不平稳性。即对时间序列进行差分,然后对差分序列进行回归。对于金融数据做一阶差分后,即由总量数据变为增长率,一般会平稳。但这样会让我们丢失总量数据的长期信息,而这些信息对分析问题来说又是必要的。
三、协整的概念和检验
有时虽然两个变量都是随机游走的,但它们的某个线形组合却可能是平稳的。在这种情况下,我们称这两个变量是协整的。
比如:变量 X t X_t Xt 和 Y t Y_t Yt 是随机游走的,但变量 Z t = a X t + b Y t Z_t=aX_t+bY_t Zt=aXt+bYt 可能是平稳的。在这种情况下,我们称 X t X_t Xt 和 Y t Y_t Yt 是协整的,其中 ( a , b ) (a,b) (a,b) 称为协整参数(cointegrating parameter)。
协整检验的具体方法
EG检验和CRDW检验
假如 X t X_t Xt 和 Y t Y_t Yt 都是 I ( 1 ) I(1) I(1) ,如何检验它们之间是否存在协整关系,我们可以遵循以下思路:
-
首先用OLS对协整回归方程 $y_t=\alpha+\beta x_t+\varepsilon_t $ 进行估计。
-
然后,检验残差 e t e_t et 是否是平稳的。因为如果 X t X_t Xt 和 Y t Y_t Yt 没有协整关系,那么它们的任一线性组合都是非平稳的,残差 e t e_t et 也将是非平稳的。
-
如果 X t X_t Xt 和 Y t Y_t Yt 存在协整关系,残差 e t e_t et 可能是平稳的。
AEG
检验 e t e_t et 是否平稳可以采用前文提到的单位根检验,但需要注意的是,此时的临界值不能再用(A)DF检验的临界值,而是要用恩格尔和格兰杰(Engle and Granger)提供的临界值,故这种协整检验又称为(扩展的)恩格尔格兰杰检验(简记(A)EG检验)。
CRDW
此外,也可以用协整回归的Durbin-Watson统计检验(Cointegration regression Durbin-Watson test,简记CRDW)进行。CRDW检验构造的统计量是:
W
=
∑
(
e
t
−
e
t
−
1
)
2
∑
(
e
t
)
2
对应的零假设
H
0
:
D
W
=
0
W=\frac{\sum\left(e_{t}-e_{t-1}\right)^{2}}{\sum\left(e_{t}\right)^{2}} \quad \text { 对应的零假设}H_0: \mathrm{DW}=0
W=∑(et)2∑(et−et−1)2 对应的零假设H0:DW=0
若
e
t
e_t
et 是随机游走的,则
e
t
−
e
t
−
1
e_t-e_{t-1}
et−et−1 的数学期望为0,所以Durbin-Watson统计量应接近于0,即不能拒绝零假设;如果拒绝零假设,我们就可以认为变量间存在协整关系。
缺点
-
CRDW检验对于带常数项或时间趋势加上常数项的随机游走是不适合的,因此这一检验一般仅作为大致判断是否存在协整的标准。
-
对于EG检验,它主要有如下的缺点:
- ①当一个系统中有两个以上的变量时,除非我们知道该系统中存在的协整关系的个数,否则是很难用EG法来估计和检验的。因此,一般而言,EG检验仅适用于包含两个变量、即存在单一协整关系的系统。
- ②仿真试验结果表明,即使在样本长度为100时,协整向量的OLS估计仍然是有偏的,这将会导致犯第二类错误的可能性增加,因此在小样本下EG检验结论是不可靠的。
Johansen协整检验
- ①迹检验统计量
λ
t
r
a
c
e
\lambda _{trace}
λtrace :
- 对应的零假设是: H 0 H_0 H0:协整关系个数小于等于 r 。
- 被择假设: H 1 H_1 H1:协整关系个数大于 r 。
- ②最大特征值检验统计量
λ
m
a
x
\lambda _{max}
λmax :
- 对应的零假设: H 0 H_0 H0:协整关系个数等于r;
- 相应的被择假设: H 1 H_1 H1:协整关系个数为r+1。



可以看到,在5%的显著性下,我们得到的结论是不存在协整关系。
四、误差修正模型(ECM)——存在协整关系的前提下
假设 Y t Y_t Yt 和 X t X_t Xt 之间的长期关系式为:
Y t = K X t β 1 Y_t=KX_t^{\beta_1} Yt=KXtβ1
两边取对数:
ln Y t = ln K + β 1 ln X t 或 y t = β 0 ⋆ + β 1 x t \ln Y_t=\ln K+\beta_1\ln X_t \ 或 \ y_t = \beta_0^{\star} + \beta_1x_t lnYt=lnK+β1lnXt 或 yt=β0⋆+β1xt
但是这种均衡情况在经济体系中是很少存在的。所以当y不处在均衡值的时候,等式两边就会有一个差额存在,即
y
t
−
β
0
⋆
−
β
1
x
t
\begin{aligned} y_t - \beta_0^{\star} - \beta_1x_t \end{aligned}
yt−β0⋆−β1xt
来衡量两个变量之间的偏离程度。当X、Y处于均衡的时候,这时误差值为零。
由于X和Y通常处于非均衡状态,可以建立一个包含X和Y滞后项的短期或非均衡关系,假设采取如下形式:
y
t
=
b
0
+
b
1
x
t
+
b
2
x
t
−
1
+
μ
y
t
−
1
+
ε
t
(
0
<
μ
<
1
)
\begin{aligned} y_t = b_0 + b_1x_t+b_2x_{t-1}+\mu y_{t-1} + \varepsilon_t \ \ \ \ (0<\mu <1) \end{aligned}
yt=b0+b1xt+b2xt−1+μyt−1+εt (0<μ<1)
在对上式进行估计的时候,其中的变量可能是不平稳的,不能运用OLS估计,否则将出现伪回归现象。对此,我们重新进行转化。两边分别减去:
y
t
−
1
y_{t-1}
yt−1
y
t
−
y
t
−
1
=
b
0
+
b
1
x
t
+
b
2
x
t
−
1
−
(
1
−
μ
)
y
t
−
1
+
ε
t
(
0
<
μ
<
1
)
\begin{aligned} y_t-y_{t-1} = b_0 + b_1x_t+b_2x_{t-1}-(1-\mu) y_{t-1} + \varepsilon_t \ \ \ \ (0<\mu <1) \end{aligned}
yt−yt−1=b0+b1xt+b2xt−1−(1−μ)yt−1+εt (0<μ<1)
经过一系列的推导我们可以得到:
Δ
y
t
=
b
1
Δ
x
t
−
λ
(
y
t
−
1
−
β
0
−
β
1
x
t
−
1
)
+
ε
t
β
1
=
(
b
1
+
b
2
)
/
λ
β
0
=
b
0
/
λ
\begin{aligned} \Delta y_t= b_1\Delta x_t-\lambda(y_{t-1}-\beta_0-\beta_1x_{t-1})+\varepsilon_t \ \ \ \ \beta_1=({b_1+b_2})/\lambda \ \ \ \ \beta_0=b_0/\lambda \end{aligned}
Δyt=b1Δxt−λ(yt−1−β0−β1xt−1)+εt β1=(b1+b2)/λ β0=b0/λ
Y的当前变化决定于X的变换以及前期的非均衡程度,也就是说前期的误差项对当期的Y值进行调整。
ε t − 1 = y t − 1 − β 0 − β 1 x t − 1 \varepsilon_{t-1}=y_{t-1}-\beta_0-\beta_1x_{t-1} εt−1=yt−1−β0−β1xt−1表示系统对均衡状态的偏离程度,可以称之为 “均衡误差”。
y t − 1 − β 0 − β 1 x t − 1 y_{t-1}-\beta_0-\beta_1x_{t-1} yt−1−β0−β1xt−1描述了对均衡关系偏离的一种**“长期调解”**。这样在误差修正模型中,长期调节和短期调节的过程同样被考虑进去。因而,误差修正模型的优点在于它提供了解释长期关系和短期调节的途径。
误差修正模型包含了长期和短期的信息。长期信息包含在 ε t − 1 \varepsilon_{t-1} εt−1 项里,因为 β \beta β 仍然是长期乘数,且误差项来自x和y的回归方程。短期信息一部分显示在均衡误差项中,即当y处于非均衡状态时,在下一期里会由于误差项的调整慢慢向均衡值靠拢;另一部分信息来自 Δ X t \Delta X_t ΔXt,解释变量的概括。这一项表明,当x发生变化,y也会相应的发生变化。
实验
Step1:提取残差序列
先进行回归


Step2:quick—>make equation


动态模型
一、ARIMA模型的概念
自回归单整移动平均模型(autoregressive integrated moving average models,简记为ARIMA模型)。
由因变量对它的滞后值以及随机误差项的现值和滞后值回归得到。
包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
二、移动平均过程
1.移动平均 ( M A \mathbf{M A} MA ) 过程的表示:
Y t = u + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 + … + θ q ε t − q \mathrm{Y}_{\mathrm{t}}=\mathrm{u}+\varepsilon_{\mathrm{t}}+\theta_{1} \varepsilon_{\mathrm{t}-1}+\theta_{2} \varepsilon_{\mathrm{t}-2}+\ldots+\theta_{\mathrm{q}} \varepsilon_{\mathrm{t}-\mathrm{q}} Yt=u+εt+θ1εt−1+θ2εt−2+…+θqεt−q 其中 u \mathrm{u} u 为常数项。
为白噪音过程引入滞后算子
L
L
L ,原式可以写成:
Y
t
=
u
+
∑
i
=
1
q
θ
i
L
i
ε
t
+
ε
t
\mathrm{Y}_{\mathrm{t}}=\mathrm{u}+\sum_{\mathrm{i}=1}^{\mathrm{q}} \theta_\mathrm{i} \mathrm{L}^{\mathrm{i}} \varepsilon_\mathrm{t}+\varepsilon_\mathrm{t}
Yt=u+∑i=1qθiLiεt+εt 或者
Y
t
=
u
+
θ
(
L
)
ε
t
\mathrm{Y}_{\mathrm{t}}=\mathrm{u}+\theta(\mathrm{L}) \varepsilon \mathrm{t}
Yt=u+θ(L)εt
θ
(
L
)
=
1
+
θ
1
L
+
θ
2
L
2
+
…
+
θ
q
L
q
\theta(\mathrm{L})=1+\theta_{1} \mathrm{~L}+\theta_{2} \mathrm{~L}^{2}+\ldots+\theta_{\mathrm{q}} \mathrm{L}^{\mathrm{q}}
θ(L)=1+θ1 L+θ2 L2+…+θqLq
2. M A ( q ) MA (q) MA(q) 过程的特征
-
E ( Y t ) = u \mathrm{E}\left(\mathrm{Y}_{\mathrm{t}}\right)=\mathrm{u} E(Yt)=u
-
var ( Y t ) = ( 1 + θ 1 2 + θ 2 2 + … + θ q 2 ) σ 2 \operatorname{var}\left(\mathrm{Y}_{\mathrm{t}}\right)=\left(1+\theta_{1}{ }^{2}+\theta_{2}{ }^{2}+\ldots+\theta_{\mathrm{q}}{ }^{2}\right) \sigma^{2} var(Yt)=(1+θ12+θ22+…+θq2)σ2
-
自协方差
-
当 k > q \mathrm{k}>\mathrm{q} k>q 时 γ k = 0 \gamma_{\mathrm{k}}=0 γk=0
-
当k < = q <=\mathrm{q} <=q 时 γ k = ( θ k + θ 1 θ k + 1 + θ 2 θ k + 2 + … + θ q θ q − k ) σ 2 \gamma_{\mathrm{k}}=\left(\theta_{\mathrm{k}}+\theta_{1} \theta_{\mathrm{k}+1}+\theta_{2} \theta_{\mathrm{k}+2}+\ldots+\theta_{\mathrm{q}} \theta_{\mathrm{q}-\mathrm{k}}\right) \sigma^{2} γk=(θk+θ1θk+1+θ2θk+2+…+θqθq−k)σ2
-
对于任意的,MA(q)是平稳的,且自协方差呈现出截尾的现象
三、自回归(AR)过程
1.自回归(AR)过程表示为:
Y
t
=
c
+
ϕ
1
Y
t
−
1
+
ϕ
2
Y
t
−
2
+
…
+
ϕ
p
Y
t
−
p
+
V
t
\mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\phi_{1} \mathrm{Y}_{\mathrm{t}-1}+\phi_{2} Y_{\mathrm{t}-2}+\ldots+\phi_{\mathrm{p}} Y_{\mathrm{t}-\mathrm{p}}+\mathrm{V}_{\mathrm{t}}
Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+Vt
其中为
{
v
t
}
\{\mathrm{vt}\}
{vt} 为白噪音过程 引入滞后算子,则原式可写成
ϕ
(
L
)
Y
t
=
c
+
v
t
\phi(\mathrm{L}) \mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\mathrm{v}_{\mathrm{t}} \quad
ϕ(L)Yt=c+vt 其中
ϕ
(
L
)
=
1
−
ϕ
1
L
−
ϕ
2
L
2
−
…
−
ϕ
p
L
p
\phi(\mathrm{L})=1-\phi_1\mathrm{L}-\phi_{2} \mathrm{L}^{2}-\ldots-\phi_{\mathrm{p}} \mathrm{L}^{\mathrm{p}}
ϕ(L)=1−ϕ1L−ϕ2L2−…−ϕpLp
2. A R ( p ) \mathbf{A R}(\mathbf{p}) AR(p) 过程平稳的条件
如果特征方程:
1
−
ϕ
1
Z
−
ϕ
2
Z
2
−
…
−
ϕ
p
Z
p
=
0
1-\phi_{1} Z-\phi_{2} Z^{2}-\ldots-\phi_{p} Z^{p}=0
1−ϕ1Z−ϕ2Z2−…−ϕpZp=0的根全部落在单位圆之外,则该AR§过程是平稳的。
四、自回归移动平均 ( A R M A ) (\mathbf{A R M A}) (ARMA) 过程
1.ARMA过程的形式
Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + θ 1 ε t − 1 + θ 2 ε t − 2 + … + θ q ε t − q + ε t \mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\phi_{1} \mathrm{Y}_{\mathrm{t}-1}+\phi_{2} \mathrm{Y}_{\mathrm{t}-2}+\ldots+\phi_{\mathrm{p}} \mathrm{Y}_{\mathrm{t}-\mathrm{p}}+\theta_{1} \varepsilon_{\mathrm{t}-1}+\theta_{2} \varepsilon_{\mathrm{t}-2}+\ldots+\theta_{\mathrm{q}} \varepsilon_{\mathrm{t}-\mathrm{q}}+\varepsilon_{\mathrm{t}} Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+θ1εt−1+θ2εt−2+…+θqεt−q+εt
- 其中 { ε t } \left\{\varepsilon_{\mathrm{t}}\right\} {εt} 为白噪音过程。
- 若引入滞后算子,可以写成
ϕ ( L ) Y t = c + θ ( L ) ε t \phi(\mathrm{L}) \mathrm{Y}_{\mathrm{t}}=\mathrm{c}+\theta(\mathrm{L}) \varepsilon_{\mathrm{t}} ϕ(L)Yt=c+θ(L)εt
ϕ ( L ) = 1 − ϕ 1 L − ϕ 2 L 2 − … − ϕ p L p \phi(\mathrm{L})=1-\phi_{1} \mathrm{~L}-\phi_{2} \mathrm{~L}^{2}-\ldots-\phi_{\mathrm{p}} L^{\mathrm{p}} ϕ(L)=1−ϕ1 L−ϕ2 L2−…−ϕpLp - 其中 θ ( L ) = 1 + θ 1 L + θ 2 L 2 + … + θ q L q \theta(\mathrm{L})=1+\theta_{1} \mathrm{~L}+\theta_{2} \mathrm{~L}^{2}+\ldots+\theta_{\mathrm{q}} \mathrm{L}^{\mathrm{q}} θ(L)=1+θ1 L+θ2 L2+…+θqLq
2.ARMA过程平稳性的条件
ARMA过程的平稳性取决于它的**自回归(AR)**部分。
当满足条件: 1 − ϕ 1 Z − ϕ 2 Z 2 − … − ϕ p Z p = 0 1-\phi_{1} Z-\phi_{2} Z^{2}-\ldots-\phi_{p} Z^{p}=0 1−ϕ1Z−ϕ2Z2−…−ϕpZp=0的根全部落在单位圆之外,则该AR§过程是平稳的
3. A R M A ( p , q ) \mathbf{A R M A ( p , q )} ARMA(p,q) 过程的特征
- E ( Y t ) = c 1 − ( ϕ 1 + ϕ 2 + … + ϕ p ) \mathrm{E}\left(\mathrm{Y}_{\mathrm{t}}\right)=\frac{\mathrm{c}}{1-\left(\phi_{1}+\phi_{2}+\ldots+\phi_{\mathrm{p}}\right)} E(Yt)=1−(ϕ1+ϕ2+…+ϕp)c
- ARMA ( p , q ) \operatorname{ARMA}(\mathrm{p}, \mathrm{q}) ARMA(p,q) 过程的方差和协方差
五、自回归单整移动平均(ARIMA)过程
ARIMA过程的概念
如果序列 { Y t } \{Y_t\} {Yt} 经过d次差分得到平稳序列 { W t } \{W_t\} {Wt} ,用ARMA(p, q)过程对 { W t } \{W_t\} {Wt} 建立模型,则 { Y t } \{Y_t\} {Yt} 为(p, d, q)阶自回归单整移动平均过程,简记为ARIMA(p,d,q)。
φ ( L ) △ d Y t = c + θ ( L ) ε t \varphi(\boldsymbol{L}) \triangle^{d} \boldsymbol{Y}_{\boldsymbol{t}}=\boldsymbol{c}+\boldsymbol{\theta}(\boldsymbol{L}) \boldsymbol{\varepsilon}_{\boldsymbol{t}} φ(L)△dYt=c+θ(L)εt
经过d阶差分得到的平稳序列 △ d Y t \triangle^{d} Y_{t} △dYt 也可能单纯是一个 AR§ 或 MA(q) 过程。
- 此时可以称 Y t Y_{t} Yt 为 ( p , d ) (p, d) (p,d) 阶单整自回归过程, 记为 A R I ( p , d , 0 ) \mathrm{ARI}(\mathrm{p}, \mathrm{d}, 0) ARI(p,d,0)。
- 或称 Y t Y_{t} Yt 为阶 ( d , q ) (d,q) (d,q) 阶单整移动平均过程,记为 I M A ( 0 , d , q ) \mathrm{IMA}(0,\mathrm{d}, \mathrm{q}) IMA(0,d,q)。
ARIMA(p,d,q) 模型和 ARMA(p,q) 模型类似,但对模型进行定阶时,我们首先需要对非平稳时间序列进行一次或多次差分来确定。
六、AR、MA过程的相互转化
-
结论一:平稳的 A R ( p ) AR(p) AR(p)过程可以转化为一个 M A ( ∞ ) MA(\infin) MA(∞)过程,可采用递归迭代法完成转化
-
结论二:特征方程根都落在单位圆外的 M A ( q ) MA(q) MA(q)过程具有可逆性。
-
平稳性和可逆性的概念在数学语言上是完全等价的,所不同的是,前者是对AR过程而言的,而后者是对MA过程而言的。
七、ARIMA模型的识别、估计、诊断、预测
1、ARIMA模型的识别
识别ARIMA模型的两个工具
-
自相关函数(autocorrelation function,简记为ACF);
-
偏自相关函数(partial autocorrelation function,简记为PACF)
-
以及它们各自的相关图(即ACF、PACF相对于滞后长度描图)。
MA(q):
- 在 k > q k>q k>q时,自相关系数为0,所以在ACF上表现出截尾的现象。
- 可逆的MA(q)过程可以转化为一个AR( ∞ \infin ∞)过程,MA(q)过程的偏自相关函数是拖尾的
AR§:
平稳的AR§过程可以转化为一个MA( ∞ \infin ∞)过程,AR§过程的自相关函数是拖尾现象
在 k > q k>q k>q时,偏自相关系数为0,所以在PACF上表现出截尾的现象。
2、利用自相关函数、偏自相关函数对ARIMA模型进行识别
- 通过ADF检验,或自相关函数来判断d值;
- 利用自相关函数、偏自相关函数以及它们的图形来确定p, q的值
补充:
1、预测的评价标准
-
平均预测误差平方和(mean squared error,简记 MSE )
-
平均预测误差绝对值(mean absolute error,简记 MAE )
-
Theil不相等系数:约接近于0,表示预测结果越好
U = 1 T ∑ t = 1 T ( y t s − y t α ) 2 1 T ∑ t = 1 T ( y t s ) 2 + 1 T ∑ t = 1 T ( y t α ) 2 \begin{aligned} U=\frac{\sqrt{\frac{1}{T} \sum_{t=1}^{T}\left(y_{t}^{s}-y_{t}^{\alpha}\right)^{2}}}{\sqrt{\frac{1}{T} \sum_{t=1}^{T}\left(y_{t}^{s}\right)^{2}}+\sqrt{\frac{1}{T} \sum_{t=1}^{T}\left(y_{t}^{\alpha}\right)^{2}}} \end{aligned} U=T1∑t=1T(yts)2+T1∑t=1T(ytα)2T1∑t=1T(yts−ytα)2 -
通过Theil不相等系数的变型 1 T ∑ ( y t s − y t α ) 2 = ( y ˉ s − y ˉ α ) 2 + ( σ s − σ α ) 2 + 2 ( 1 − ρ ) σ s σ α \left.\frac{1}{T} \sum (y_{t}^{s}-y_{t}^{\alpha}\right)^{2}=\left(\bar{y}^{s}-\bar{y}^{\alpha}\right)^{2}+\left(\sigma_{s}-\sigma_{\alpha}\right)^{2}+2(1-\rho) \sigma_{s} \sigma_{\alpha} T1∑(yts−ytα)2=(yˉs−yˉα)2+(σs−σα)2+2(1−ρ)σsσα
其中 y ˉ s , y ˉ α , σ s , σ α \bar{y}^{s}, \bar{y}^{\alpha}, \sigma_{s}, \sigma_{\alpha} yˉs,yˉα,σs,σα 分别是序列 y t s y_{t}^{s} yts 和 y t α y_{t}^{\alpha} ytα 的平均值和标准差, ρ \rho ρ 是它们的相关系数,即:
ρ = ( 1 σ s σ α T ) ∑ ( y t s − y ˉ s ) ( y t α − y ˉ α ) \begin{aligned} \rho=\left(\frac{1} {\sigma_{s} \sigma_{\alpha} T}\right) \sum\left(y_{t}^{s}-\bar{y}^{s}\right)\left(y_{t}^{\alpha}-\bar{y}^{\alpha}\right) \end{aligned} ρ=(σsσαT1)∑(yts−yˉs)(ytα−yˉα) -
U M , U S , U C U^M,U^S,U^C UM,US,UC 分别称为U的偏误比例,方差比例,协方差比例。它们是将模型误差按特征来源分解的有效方法(注意: U M + U S + U C = 1 U^M+U^S+U^C=1 UM+US+UC=1)
- 偏误比例 U M U^M UM 表示系统误差,因为它度量的是模拟序列与实际序列之间的偏离程度。
- 方差比例 U S U^S US 表示的是模型中的变量重复其实际变化程度的能力。
- 协方差比例 U C U^C UC 度量的是非系统误差,即反映的是考虑了与平均值的离差之后剩下的误差。
- 理想的不相等比例的分布是 U M = U S = 0 U C = 1 U^M=U^S=0\quad U^C=1 UM=US=0UC=1
-
U M = ( y ˉ s − y ˉ α ) 2 ( 1 / T ) ∑ ( y t s − y t α ) 2 U S = ( σ s − σ α ) 2 ( 1 / T ) ∑ ( y t s − y t α ) 2 U C = 2 ( 1 − ρ ) σ s σ α ( 1 / T ) ∑ ( y t s − y t α ) 2 \begin{gathered} U^{M}=\frac{\left(\bar{y}^{s}-\bar{y}^{\alpha}\right)^{2}}{(1 / T) \sum\left(y_{t}^{s}-y_{t}^{\alpha}\right)^{2}} \\ U^{S}=\frac{\left(\sigma_{s}-\sigma_{\alpha}\right)^{2}}{(1 / T) \sum\left(y_{t}^{s}-y_{t}^{\alpha}\right)^{2}} \\ U^{C}=\frac{2(1-\rho) \sigma_{s} \sigma_{\alpha}}{(1 / T) \sum\left(y_{t}^{s}-y_{t}^{\alpha}\right)^{2}} \end{gathered} UM=(1/T)∑(yts−ytα)2(yˉs−yˉα)2US=(1/T)∑(yts−ytα)2(σs−σα)2UC=(1/T)∑(yts−ytα)22(1−ρ)σsσα
实验一:MA模型的构建以及预测
Step1:Graph

Step2:Correlation



Step3:建立模型
假设是MA(1)模型。



Step4:判断模型的好坏


可以看到Q统计量为14.980,p值为0.724,在显著性水平为5%的情况下,不能拒绝原假设,因此可以认为模型较好地拟合了数据。
预测





实验二:AR模型的构建以及预测
Step1:Graph


Step2:建立模型
明显的AR(1)模型


Step3:判断模型好坏

Step4:预测
数据拓展





实验三:非平稳序列 ARIMA模型 ARIMA(p,d,q)

是明显的非平稳序列。



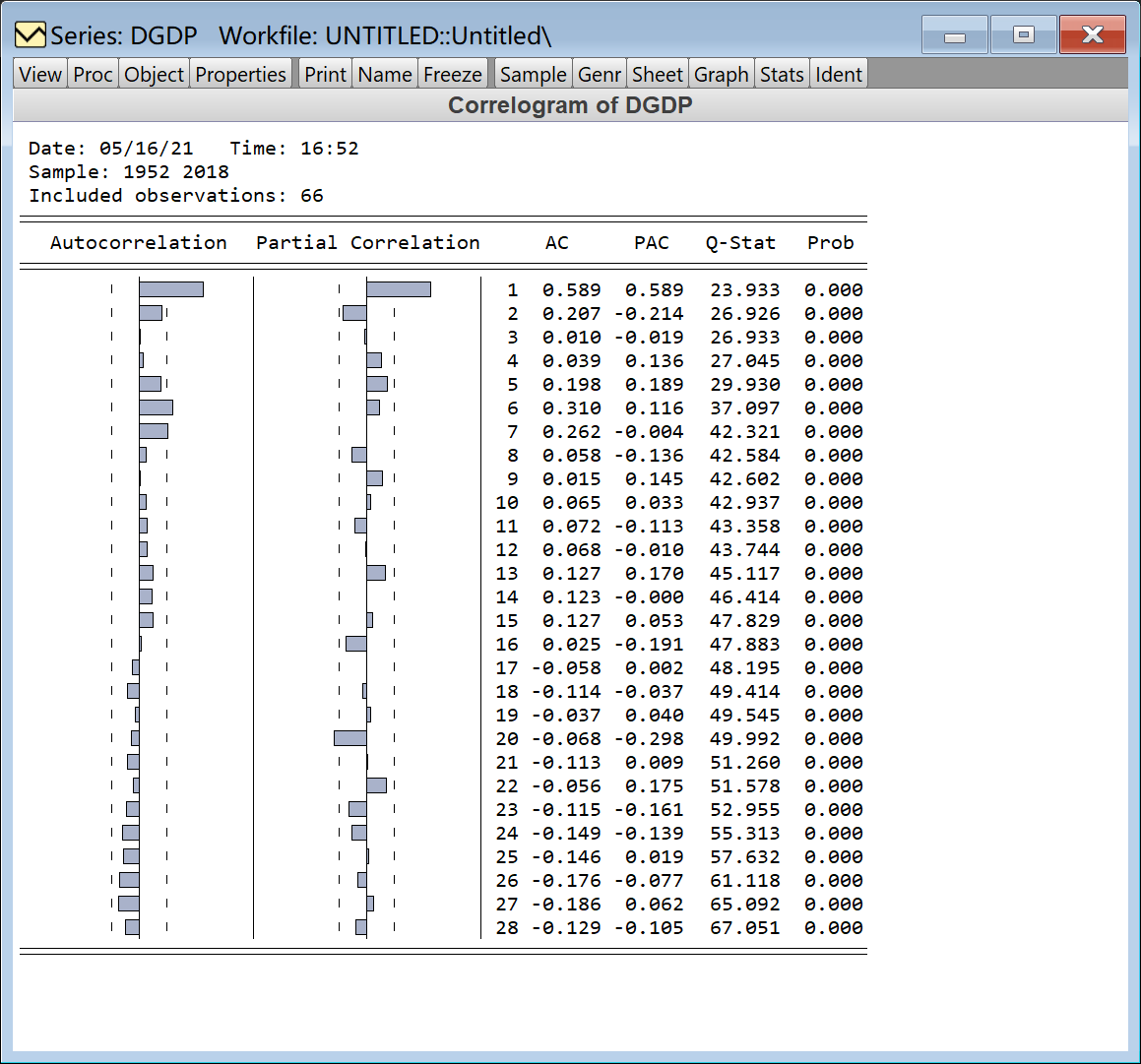
ARMA(7,7)





八、VAR(Vector Autoregressive)模型
一、概述
VAR模型通常用来估计联合内生变量的动态关系。是用模型中所有当期变量对所有变量的若干期滞后变量进行自回归来实现。在VAR模型中也可以加入趋势项、季节虚拟变量、外生变量等,从而来增加模型的解释力度。
- 所有的变量都被看作内生变量
- 初始对模型系数不施加任何约束
- 每个方差的解释变量都一样即所有解释变量的若干滞后期
比如 VAR(3):
Y
t
=
α
1
+
ϕ
11
Y
t
−
1
+
…
+
ϕ
1
p
Y
t
−
p
+
β
11
X
t
−
1
+
…
+
β
1
p
X
t
−
p
+
δ
11
Z
t
−
1
+
…
+
δ
1
p
Z
t
−
p
+
e
1
t
X
t
=
α
1
+
ϕ
21
Y
t
−
1
+
…
+
ϕ
2
p
Y
t
−
p
+
β
21
X
t
−
1
+
…
+
β
2
p
X
t
−
p
+
δ
21
Z
t
−
1
+
…
+
δ
2
p
Z
t
−
p
+
e
2
t
Z
t
=
α
1
+
ϕ
31
Y
t
−
1
+
…
+
ϕ
3
p
Y
t
−
p
+
β
31
X
t
−
1
+
…
+
β
3
p
X
t
−
p
+
δ
31
Z
t
−
1
+
…
+
δ
3
p
Z
t
−
p
+
e
3
t
\begin{aligned} &Y_{t}=\alpha_{1}+\phi_{11} Y_{t-1}+\ldots+\phi_{1 p} Y_{t-p}+\beta_{11} X_{t-1}+\ldots+\beta_{1 p} X_{t-p}+\delta_{11} Z_{t-1}+\ldots+\delta_{1 p} Z_{t-p}+e_{1 t} \\ &X_{t}=\alpha_{1}+\phi_{21} Y_{t-1}+\ldots+\phi_{2 p} Y_{t-p}+\beta_{21} X_{t-1}+\ldots+\beta_{2 p} X_{t-p}+\delta_{21} Z_{t-1}+\ldots+\delta_{2 p} Z_{t-p}+e_{2 t} \\ &Z_{t}=\alpha_{1}+\phi_{31} Y_{t-1}+\ldots+\phi_{3 p} Y_{t-p}+\beta_{31} X_{t-1}+\ldots+\beta_{3 p} X_{t-p}+\delta_{31} Z_{t-1}+\ldots+\delta_{3 p} Z_{t-p}+e_{3 t} \end{aligned}
Yt=α1+ϕ11Yt−1+…+ϕ1pYt−p+β11Xt−1+…+β1pXt−p+δ11Zt−1+…+δ1pZt−p+e1tXt=α1+ϕ21Yt−1+…+ϕ2pYt−p+β21Xt−1+…+β2pXt−p+δ21Zt−1+…+δ2pZt−p+e2tZt=α1+ϕ31Yt−1+…+ϕ3pYt−p+β31Xt−1+…+β3pXt−p+δ31Zt−1+…+δ3pZt−p+e3t
二、VAR模型的优缺点
优点
-
不需要区分哪些是内生哪些是外生变量。
-
VAR模型中允许变量不仅受到自身滞后变量的影响,而且还受到其它变量滞后变量的影响。
-
传统的VAR中右边没有当期变量,因此它的估计相对较为容易。
-
相对传统的结构化模型,VAR模型更容易预测。
缺点
-
VAR 模型是缺乏理论依据的,导致 VAR 模型很少用于理论分析以及政策建议,因为无法确认 VAR 模型中系数的意义。
-
难以确定 VAR 模型中解释变量的滞后长度。
-
过多的参数。
-
传统的VAR模型要求每一序列都是平稳的,而实际的金融经济数据序列往往是不平稳的。
三、滞后阶数的确定
**滞后阶数的确定:**在信息获取与自由度减少之间取得最优解
- 似然比检验法:
L
R
=
T
[
log
∣
Σ
^
∣
−
log
∣
Σ
^
μ
∣
]
LR=T\left[\log |\hat{\Sigma}|-\log \left|\hat{\Sigma}_{\mu}\right|\right]
LR=T[log∣Σ^∣−log∣∣∣Σ^μ∣∣∣] (服从自由度为m的卡方分布)
LR检验法就是比较不同滞后期对应的似然函数值,考察滞后期的增大是否会导致 VAR 系统对应的似然函数出现显著性增大,直到滞后项 p 的增加不会使得似然函数显著性增大为止,而此时的 p 为最优的滞后阶数。 - 信息准则法
四、脉冲响应和方差分解
**1、脉冲响应函数(Impulse Response):**指系统对其中某一个变量的一个随机冲击所做出的反应以及这种反应会持续多久。
2、预测方差分解(Variance Decompositions):是一种判断经济序列变量间动态相关性的重要方法。它实质上是将系统的预测均方误差分解为系统中各变量冲击所作的贡献。
五、实操
Step1:构建VAR模型



Step2:脉冲响应



解释:第一行为联邦基金利率对联邦基金利率,失业率和通货膨胀率的冲击效果。联邦基金利率短期内会降低失业率,长期造成通货膨胀率的上升。
红线是上下的置信区间,只有红线高于零轴才是有效的冲击。
Step3:方差分解



**解释:**第一行为联邦基金利率作为响应变量的情况。对联邦利率向前一个季度的预测,其预测方差完全来自其自身,即使向前做十个季度的预测,也有70.6%的预测方差来自其本身。

观察残差图,可以看到拟合效果较好
九、Granger因果检验
1、Granger因果关系和因果关系的差别:
- Granger因果关系:表达的一种可预测性,即如果A事件对于预测B事件是有用的,则A是B的Granger原因。
- 因果关系:表达的是一种逻辑上的顺序,通过逻辑思考得到的A是B发生的原因才是真正的因果关系。
2、Granger因果检验的步骤
基本思想:对于经济变量X和Y,若X的变化引起了Y的变化,X的变化应当在Y的变化之前。
Y
t
=
∑
i
=
1
m
α
i
Y
t
−
i
+
∑
i
=
1
m
β
i
X
t
−
i
+
ε
t
(
Y t=\sum_{i=1}^{m} \alpha_{i} Y_{t-i}+\sum_{i=1}^{m} \beta_{i} X_{t-i}+\varepsilon_{t}(
Yt=∑i=1mαiYt−i+∑i=1mβiXt−i+εt( 有约束回归
)
)
)
Y
t
=
∑
i
=
1
m
α
i
Y
t
−
i
+
ε
t
Y t=\sum_{i=1}^{m} \alpha_{i} Y_{t-i}+\varepsilon_{t}
Yt=∑i=1mαiYt−i+εt (无约束回归)
H
0
:
β
1
=
β
2
=
⋯
β
s
=
0
H_{0}: \beta_{1}=\beta_{2}=\cdots \beta_{s}=0
H0:β1=β2=⋯βs=0
若拒绝原假设,则得到 X 是引起 Y 变化的 Granger 原因, Y 是 X 的 Granger 结果,最后对不同滞后阶数M进行检验,以保证结果的稳健性。
3、注意事项
- 计量经济学上的相关关系并不是因果关系。
- Granger因果关系是计量学上的一个概念,指时间序列之间的领先与滞后关系,只是时间上的因果关系,重在影响方向的确认,而非完全的因果关系。
- Granger检验的核心思想:对于经济变量X和Y,若X的变化引起了Y的变化,X的变化应当在Y的变化之前。
- Granger因果检验的步骤:先检验X是否是引起Y变化的原因,再检验Y是否是引起X变化的原因,最终得出结论。
4、实操: M 2 M_2 M2 与 GDP关系的Granger因果检验
Step1:构建模型



Step2:分析(滞后2阶和滞后3阶)


**解释:**消费增长率是收入增长率的Granger原因,收入增长率不是消费增长率的Granger原因。消费增长率有助于预测收入增长率,而收入增长率不能帮助预测消费增长率。
十、联立方程模型
对于大多数金融、经济现象而言,许多变量之间存在的是交错的双向或多向因果关系,单向的因果关系是没有多大的意义的。例如货币需求的变化会影响均衡利率水平,而利率水平的变化也会影响货币需求。为了描述变量之间的多向因果关系,就需要建立由多个相互联系的单方程组成的多方程模型,即联立方程模型 (simultaneous equation model)。
举例:
-
通货膨胀率方程:
i n f l a t i o n t = α 0 + α 1 r e t u r n s t + α 2 d c r e d i t t + α 3 d p r o d t + α 4 d m o n e y t + u 1 t inflation_{t}=\alpha_{0}+\alpha_{1}returns_{t}+\alpha_{2}dcredit_{t}+\alpha_{3}dprod_{t}+\alpha_{4}dmoney_{t}+u_{1 t} inflationt=α0+α1returnst+α2dcreditt+α3dprodt+α4dmoneyt+u1t
- CPI对数变化率
- 标普500指数对数变化率
- 消费信贷增量
- 工业生产指数增量
- 货币供给增量
-
股票收益率方程
r e t u r n s t = β 0 + β 1 d p r o d t + β 2 d s p r e a d t + β 3 i n f l a t i o n t + β 4 r t e r m t + u 2 t returns_{t}=\beta_{0}+\beta_{1}dprod_{t}+\beta_{2}dspread_{t}+\beta_{3}inflation_{t}+\beta_{4}rterm_{t}+u_{2 t} returnst=β0+β1dprodt+β2dspreadt+β3inflationt+β4rtermt+u2t
- dspread:风险溢价增量
- rterm:期限溢价增量
1、工具变量法
工具变量法的基本思想是:用适当的工具变量代替结构方程中作为解释变量的内生变量,从而降低解释变量与随机误差项之间的相关程度,再利用普通最小二乘法进行估计。
什么是工具变量?与内生变量高度相关,但是与误差项无关的变量。
工具变量法的关键是工具变量的选取。
2、两阶段最小二乘法的基本思想
两阶段最小二乘法的基本思想是:
(1)将结构式方程转换为简化式方程,并利用简化式方程求出内生变量的拟合值。
i
n
f
l
a
t
i
o
n
t
=
γ
0
+
γ
1
d
c
r
e
d
i
t
t
+
γ
2
d
p
r
o
d
t
+
γ
3
d
m
o
n
e
y
t
+
γ
4
d
s
p
r
e
a
d
t
+
γ
5
r
t
e
r
m
t
inflation_{t}=\gamma_{0}+\gamma_{1}dcredit_{t}+\gamma_{2}dprod_{t}+\gamma_{3}dmoney_{t}+\gamma_{4}dspread_{t}+\gamma_{5}rterm_{t}
inflationt=γ0+γ1dcreditt+γ2dprodt+γ3dmoneyt+γ4dspreadt+γ5rtermt
r
e
t
u
r
n
s
t
=
δ
0
+
δ
1
d
c
r
e
d
i
t
t
+
δ
2
d
p
r
o
d
t
+
δ
3
d
m
o
n
e
y
t
+
δ
4
d
s
p
r
e
a
d
t
+
δ
5
r
t
e
r
m
t
returns_{t}=\delta_{0}+\delta_{1}dcredit_{t}+\delta_{2}dprod_{t}+\delta_{3}dmoney_{t}+\delta_{4}dspread_{t}+\delta_{5}rterm_{t}
returnst=δ0+δ1dcreditt+δ2dprodt+δ3dmoneyt+δ4dspreadt+δ5rtermt
(2)将原结构方程右边的内生变量替换为相应的拟合值,并对替换后的结构方程分别运用普通最小二乘法估计参数。
i
n
f
l
a
t
i
o
n
t
=
α
0
+
α
1
r
e
t
u
r
n
s
^
t
+
α
2
d
c
r
e
d
i
t
t
+
α
3
d
p
r
o
d
t
+
α
4
d
m
o
n
e
y
t
+
u
1
t
inflation_{t}=\alpha_{0}+\alpha_{1}\hat{returns}_{t}+\alpha_{2}dcredit_{t}+\alpha_{3}dprod_{t}+\alpha_{4}dmoney_{t}+u_{1t}
inflationt=α0+α1returns^t+α2dcreditt+α3dprodt+α4dmoneyt+u1t
r
e
t
u
r
n
s
t
=
β
0
+
β
1
d
p
r
o
d
t
+
β
2
d
s
p
r
e
a
d
t
+
β
3
i
n
f
l
a
t
i
o
n
^
t
+
β
4
r
t
e
r
m
t
+
u
2
t
returns_{t}=\beta_{0}+\beta_{1}dprod_{t}+\beta_{2}dspread_{t}+\beta_{3}\hat{inflation}_{t}+\beta_{4}rterm_{t}+u_{2t}
returnst=β0+β1dprodt+β2dspreadt+β3inflation^t+β4rtermt+u2t
3、识别规则
-
阶条件
令G表示模型中结构方程的个数,如果某方程中所不含的内生变量和前定变量的个数为G-1,则该方程是恰好识别的;若大于G-1,则该方程是过度识别的;若小于G-1,则该方程是不可识别的。 -
秩条件
对于一个由G个方程组成的联立方程模型中的某个结构方程而言,如果模型中其他方程所含而该方程不含的诸变量的系数矩阵的秩为G-1,则该结构方程是可识别的,若秩小于G-1,则该结构方程是不可识别。
4、实操




此为通货膨胀方程:

十一、事件研究法
定义: 事件研究法是一种针对某项经济事件给资产价格、波动率、成交量等造成的 影响程度 和 持续时间 进行度量以及检验的统计学方法。
特点:
- 逻辑清晰,事件的发生直接可观测。
- 用超额收益来测度某段时间内,事件对于价格产生的影响。
1、研究步骤
五大步骤: 事件定义、样本选择、正常收益率的计算、估计超额收益率、实证结果分析




2、其他方法

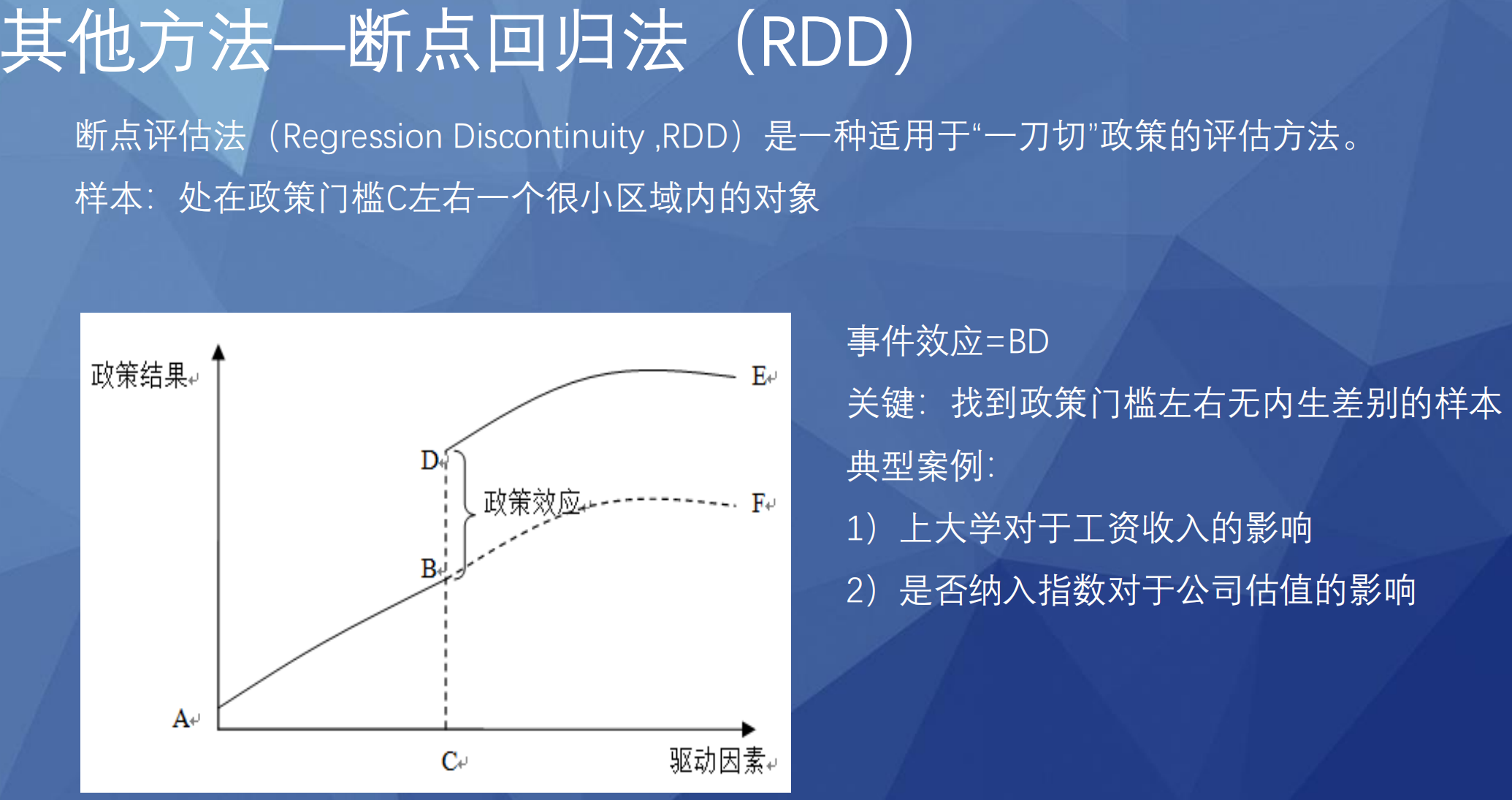
十二、GARCH模型(广义自回归条件异方差模型)
ARCH(autoregressive conditional heteroscedasticity):自回归条件异方差模型,反映了随机过程的一种特性:即方差随时间变化而变化,且具有波动性和丛集性。
许多金融时间序列它并没有恒定的均值,大多数时间序列呈现出阶段性的相对平稳的同时,往往伴随着剧烈的波动性,具有尖峰厚尾、波动聚集以及杠杆效应的特征。
- 尖峰厚尾:
- 金融资产收益呈现厚尾(即极端情况出现的概率高于正态分布的预测,比如出人意料的 “黑天鹅事件”)
- 在均值处呈现过度波峰(即尖峰:实际分布中,靠近均值的样本更多,偏离正态分布)
- 波动聚集:金融市场波动往往呈现集聚倾向,即当期波动与往期波动存在正相关关系。
- 杠杆效应: 价格大幅度下降后往往会出现同样幅度价格上升的倾向。
1、ARCH模型
核心思想:残差项的条件方差依赖于它的前期值的大小
ARCH§模型,其定义由均值方程和条件方程给出:
y
t
=
β
x
t
+
ε
t
h
t
=
var
(
ε
t
∣
Ω
t
−
1
)
=
α
0
+
α
1
ε
t
−
1
2
+
α
2
ε
t
−
2
2
+
⋅
⋅
⋅
+
α
p
ε
t
−
p
2
\begin{gathered} \mathrm{y}_{t}=\beta \mathrm{x}_{t}+\varepsilon_{t} \\ h_{t}=\operatorname{var}\left(\varepsilon_{t} \mid \Omega_{t-1}\right)=\alpha_{0}+\alpha_{1} \varepsilon_{t-1}^{2}+\alpha_{2} \varepsilon_{t-2}^{2}+···+\alpha_{p} \varepsilon_{t-p}^{2} \end{gathered}
yt=βxt+εtht=var(εt∣Ωt−1)=α0+α1εt−12+α2εt−22+⋅⋅⋅+αpεt−p2
其中,
Ω
t
−
1
\Omega_{t-1}
Ωt−1 表示 t-1 时刻所有可得信息的集合,
h
t
h_t
ht 为条件方差。
2、GARCH模型
在标准的GARCH(1,1)模型中
y
t
=
β
x
t
+
ε
t
h
t
=
var
(
ε
t
∣
Ω
t
−
1
)
=
α
0
+
α
1
ε
t
−
1
2
+
β
1
h
t
−
1
\begin{gathered} \mathrm{y}_{t}=\beta \mathrm{x}_{t}+\varepsilon_{t} \\ h_{t}=\operatorname{var}\left(\varepsilon_{t} \mid \Omega_{t-1}\right)=\alpha_{0}+\alpha_{1} \varepsilon_{t-1}^{2}+\beta_{1} h_{t-1} \end{gathered}
yt=βxt+εtht=var(εt∣Ωt−1)=α0+α1εt−12+β1ht−1
进一步拓展,可以得到高阶GARCH(p,q)模型。高阶GARCH模型可以包含多个ARCH项和GARCH项,其条件方差表示为
h
t
=
var
(
ε
t
∣
Ω
t
−
1
)
=
α
0
+
∑
i
=
1
q
α
i
ε
t
−
i
2
+
∑
j
=
1
p
β
j
h
t
−
j
α
0
>
0
,
α
i
⩾
0
,
β
j
⩾
0
\begin{aligned} &h_{t}=\operatorname{var}\left(\varepsilon_{t} \mid \Omega_{t-1}\right)=\alpha_{0}+\sum_{i=1}^{q} \alpha_{i} \varepsilon_{t-i}^{2}+\sum_{j=1}^{p} \beta_{j} h_{t-j} \\ &\alpha_{0}>0, \quad \alpha_{i} \geqslant 0, \quad \beta_{j} \geqslant 0 \end{aligned}
ht=var(εt∣Ωt−1)=α0+i=1∑qαiεt−i2+j=1∑pβjht−jα0>0,αi⩾0,βj⩾0
- q: ARCH项的阶数
- p: 自回归GARCH项的阶数
3、GARCH-M(1,1)模型
GARCH-M(1,1)模型如下:
y
t
=
λ
h
t
+
β
x
t
+
ε
t
h
t
=
α
0
+
λ
1
h
t
−
1
+
α
1
ε
t
−
1
2
\begin{gathered} \mathrm{y}_{t}=\lambda h_{t}+\beta \mathrm{x}_{t}+\varepsilon_{t} \\ h_{t}=\alpha_{0}+\lambda_{1} h_{t-1}+\alpha_{1} \varepsilon_{t-1}^{2} \end{gathered}
yt=λht+βxt+εtht=α0+λ1ht−1+α1εt−12
λ
\lambda
λ 表示市场的相对风险厌恶,当风险
(
(
( 波动性 ) 增加,收益要求增加时,方程中对应的条件方差的系数
λ
>
0
\lambda>0
λ>0;当风险增加,收益要求减少 时,对应的条件方差系数
λ
<
0
\lambda<0
λ<0 。
一般而言,金融市场中 λ > 0 \lambda>0 λ>0 ,越大表示越为厌恶风险,要求更高的风险补偿。
4、拓展的GARCH模型(波动率不对称性)
- 非对称GARCH模型
- TGARCH模型(阈值GARCH模型) w ≠ 0 w\ne0 w=0 冲击的影响是非对称的, w > 0 w>0 w>0 具有杠杆效应,坏影响更大
- EGARCH模型(指数GARCH模型) λ ≠ 0 \lambda\ne0 λ=0 冲击的影响是非对称的, λ < 0 \lambda<0 λ<0 具有杠杆效应,坏影响更大 观察C4
- 单整GARCH模型
- IGARCH模型(单整GARCH模型)
5、实操
实验一:沪深股市收益率的波动性分析
Step1:绘直方图





可以发现RSH和RSZ序列都呈现明显的尖峰厚尾的特征。
Step2:平稳性检验



拒绝存在单位根的原假设,所以RSH序列是平稳的。
Step3:自相关系数的检验


存在严重的波动聚集现象,进行ARCH建模
Step4:ARCH_LM检验



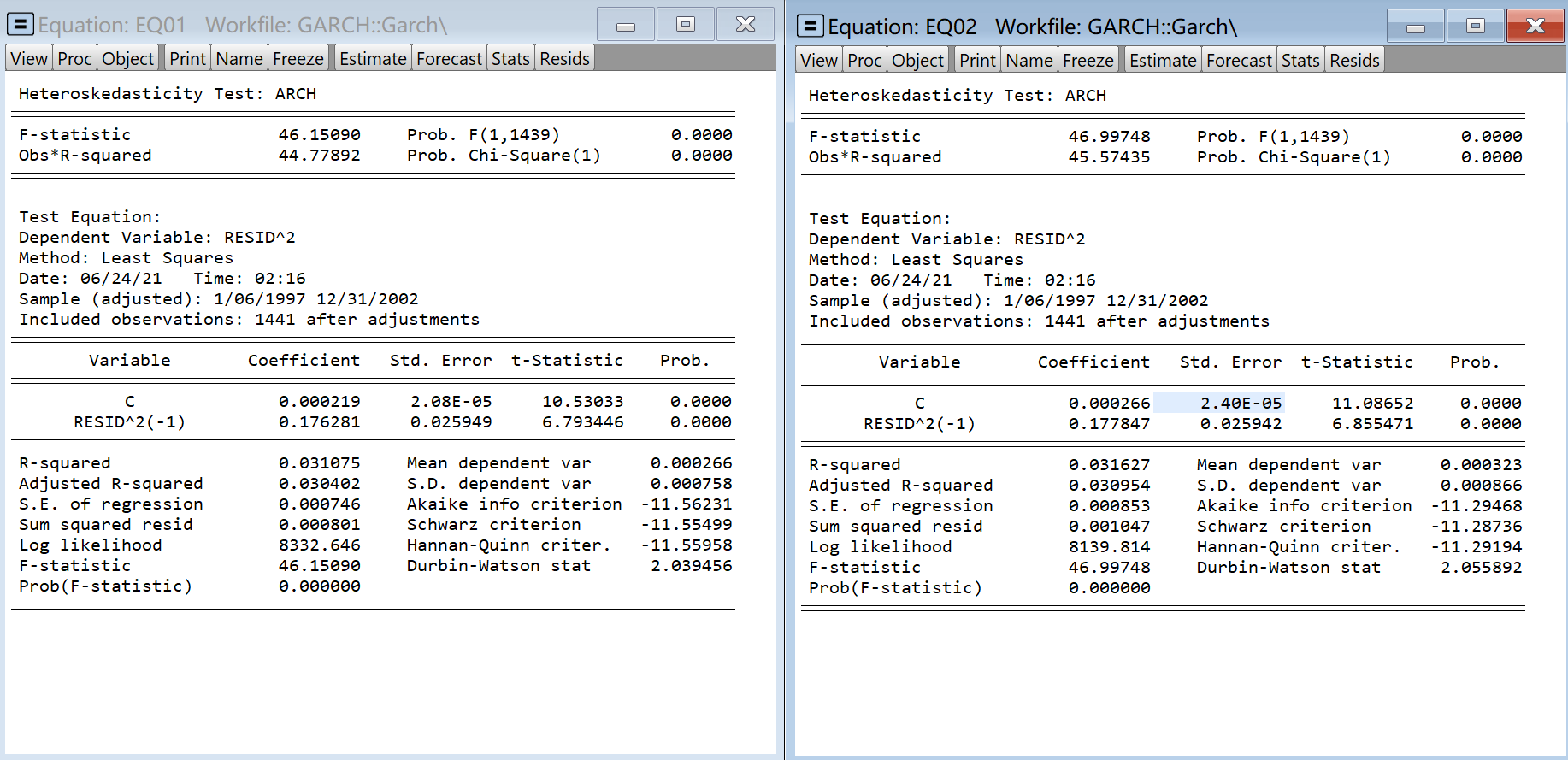
可以看到两序列的残差平方可以解释下一期的残差平方,具有显著的ARCH效应,可以进行波动率建模。
Step5:GARCH

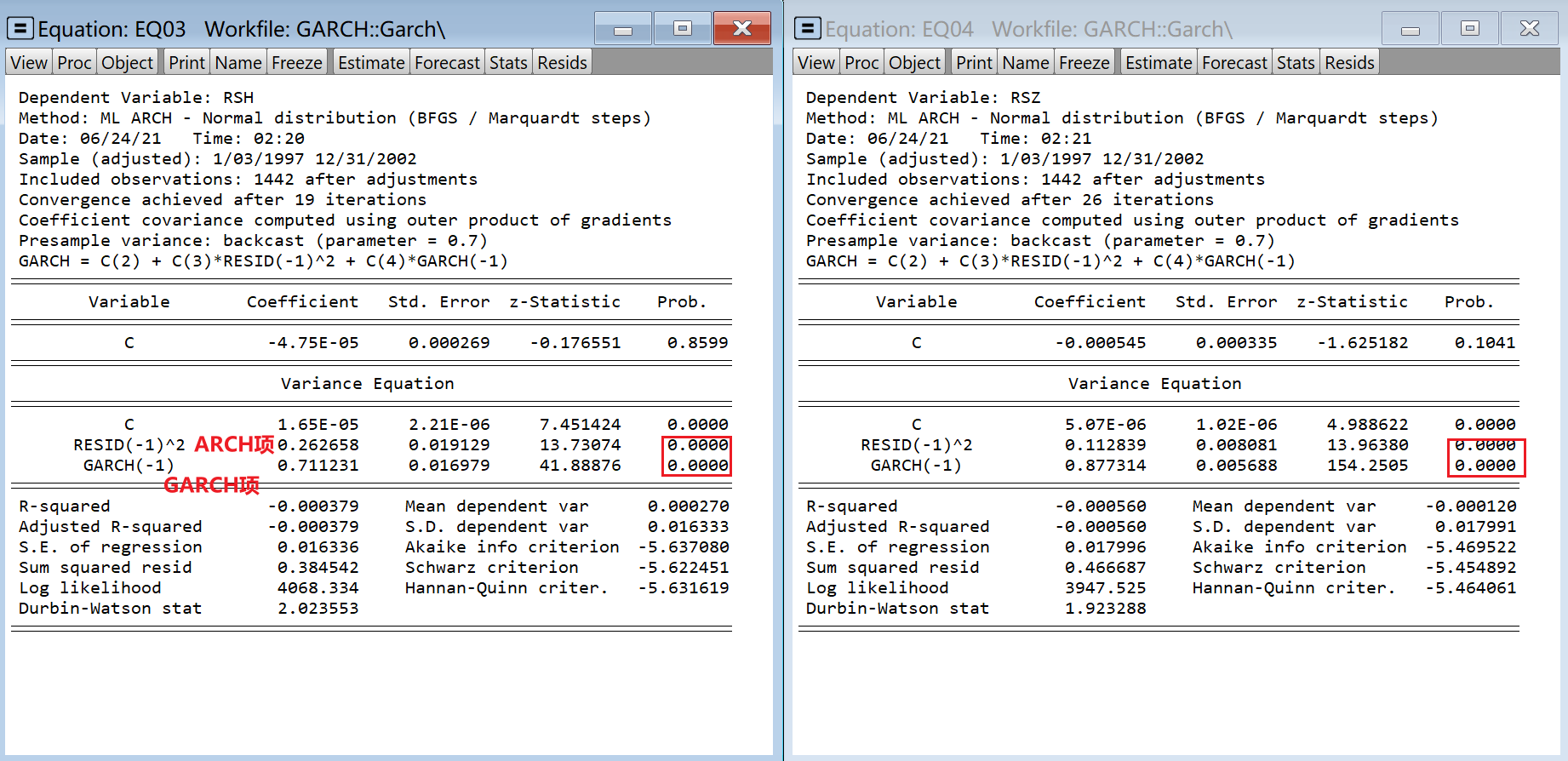
ARCH项和GARCH项的系数都是高度显著的,表明收益率序列具有显著的波动聚集性。沪深两市中,ARCH项和GARCH项系数之和小于1,因此GARCH(1,1) 过程是平稳的,其条件方差表现出均值回复特性,即过去的波动对未来的影响是逐渐衰减的。
Step6:GARCH-M(1,1)


存在正的风险溢价
实验二:方差平方和的非对称性比较
利用TGARCH和EGARCH模型即可。
实验三:沪深股市收益波动溢出效应的研究分析
Step1:对收益率进行利用Granger因果检验

Step2:构建GARCH Variance

 Step6:GARCH-M(1,1)
Step6:GARCH-M(1,1)
存在正的风险溢价
实验二:方差平方和的非对称性比较
利用TGARCH和EGARCH模型即可。
实验三:沪深股市收益波动溢出效应的研究分析
Step1:对收益率进行利用Granger因果检验
Step2:构建GARCH Variance


















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











